GoLang函数栈的使用详细讲解
目录
- 函数栈帧
- 寄存器
函数栈帧
我们的代码会被编译成机器指令并写入到可执行文件,当程序执行时,可执行文件被加载到内存,这些机器指令会被存储到虚拟地址空间中的代码段,在代码段内部,指令是低地址向高地址堆积的。堆区存储的是需要程序员手动alloc并free的空间,需要自己来控制。
虚拟内存空间是对存储器的一层抽象,是为了更好的来管理存储器,虚拟内存和存储器之间存在映射关系。
如果在一个函数中调用了另外一个函数,编译器就会对应生成一条call指令,当call指令被执行时,就会跳转到被调用函数入口处开始执行,而每个函数的最后都有一条ret指令,负责在函数结束后跳回到调用处继续执行。
call 指令做了两件事,将下一条指令的地址入栈,这就是IP寄存器中存储的值,第二,跳转到被调用函数入口处执行。
函数执行时需要有足够的内存空间用来存储参数,局部变量,返回值,这块空间对应的就是栈,栈区是从高地址向低地址生长的,且先进后出。分配给函数的栈空间被称为函数栈帧。
C语言中,每个栈帧对应着一个未运行完的函数。栈帧中保存了该函数的返回地址和局部变量。


寄存器
ESP寄存器:ESP即 Extended stack pointer 的缩写,直译过来就是扩展的栈指针寄存器。SP是16位的,ESP是32位的,RSP是64位的,存放的都是栈顶地址。
EBP寄存器:EBP即 Extended base pointer 的缩写,直译过来就是扩展的基址指针寄存器。该指针总是指向当前栈帧的底部。
IP寄存器:指令指针,它指向代码段中的地址,是一个16位专用寄存器,它指向当前需要取出的指令字节,也就是下一个将要执行的指令在代码段中的地址。
eax:累加(Accumulator)寄存器,常用于函数返回值
ebx:基址(Base)寄存器,以它为基址访问内存
ecx:计数器(Counter)寄存器,常用作字符串和循环操作中的计数器
edx:数据(Data)寄存器,常用于乘除法和I/O指针
esi:源地址寄存器
edi:目的地址寄存器
esp:堆栈指针
ebp:栈指针寄存器
当然,以上功能并未限制寄存器的使用,特殊情况为了效率也可作其他用途。
这八个寄存器低16位分别有一个引用别名 ax, bx, cx, dx, bp, si, di, sp,
其中 ax, bx, cx, dx, 的高8位又引用至 ah, bh, ch, dh,低八位引用至 al, bl, cl, dl
在 64-bit 模式下,有16个通用寄存器,但是这16个寄存器是兼容32位模式的,
32位方式下寄存器名分别为 eax, ebx, ecx, edx, edi, esi, ebp, esp, r8d – r15d.
在64位模式下,他们被扩展为 rax, rbx, rcx, rdx, rdi, rsi, rbp, rsp, r8 – r15.
其中 r8 – r15 这八个寄存器是64-bit模式下新加入的寄存器。
我们看到CPU在执行代码段中的指令,而这当中又伴随着内存的分配,于是在函数栈帧上就会有相应的变化。
int add(int a, int b)
{
int c = 4;
c = a + b;
return c;
}
int main()
{
int a = 1;
int b = 2;
int sum = 3;
sum = add(a, b);
return 0;
}
生成的汇编代码的方式
1、使用 gcc + objdump
gcc -save-temps -fverbose-asm -g -o b testasm.c
objdump -S --disassemble b > b.objdump
2、使用第三方网站来生成,进入 https://godbolt.org/,选择语言为C,编译器为x86-64 gcc 12.2,粘贴进你的代码,就能看到汇编代码,如下
add:
push rbp
mov rbp, rsp
mov DWORD PTR [rbp-20], edi
mov DWORD PTR [rbp-24], esi
mov DWORD PTR [rbp-4], 4
mov edx, DWORD PTR [rbp-20]
mov eax, DWORD PTR [rbp-24]
add eax, edx
mov DWORD PTR [rbp-4], eax
mov eax, DWORD PTR [rbp-4]
pop rbp
ret
main:
push rbp
mov rbp, rsp
sub rsp, 16
mov DWORD PTR [rbp-4], 1
mov DWORD PTR [rbp-8], 2
mov DWORD PTR [rbp-12], 3
mov edx, DWORD PTR [rbp-8]
mov eax, DWORD PTR [rbp-4]
mov esi, edx
mov edi, eax
call add
mov DWORD PTR [rbp-12], eax
mov eax, 0
leave
ret
从main开始解读
// 此时rbp存储的还是上一层函数(调用者)的栈基地址,将rbp的值入栈保存起来,因为main函数也是被其他函 // 数调用的,运行完main之后还得回到那个函数体中去。这里的地址指的是指令的地址,是代码段中的位置。 // push指令会使rsp下移。 push rbp // 此时rbp存储的还是上一个函数的基地址,而rsp则已经游走到了main函数这里,mov指令将rsp中存储的地址传递 // 给rbp,也就意味着执行完之后rbp和rsp都处于main函数的开始位置,称为初始化操作。 mov rbp, rsp // rsp下移16,就是分配栈空间 sub rsp, 16

// DWORD 为双字,即四个字节,PTR为指针的意思,此句意为在rbp向下偏移4个字节的这段栈内存中存储0 // a mov DWORD PTR [rbp-4], 1 // b mov DWORD PTR [rbp-8], 2 // sum mov DWORD PTR [rbp-12], 3 // 将参数从右到左,依次存起来,此处存到了 edx和eax,并拷贝了一份到esi和edi。 mov edx, DWORD PTR [rbp-8]` mov eax, DWORD PTR [rbp-4]` mov esi, edx` mov edi, eax`
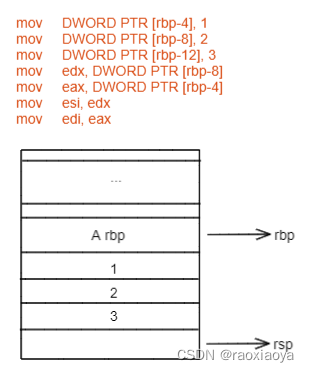
// 执行call指令
// 注意,call会使CPU跳入到add的栈帧中去,那么执行完之后,我们需要跳回到被调用处继续向下执行,由
// 最前面的push指令我们已经把调用者的栈基存了下来,可是我们还要精确到具体是回到哪个指令,这就是call
// 指令的额外工作,它会先将IP入栈(push ip),因为IP中存的就是下一条指令(mov DWORD PTR [rbp-12], eax)
// 的地址,然后再去跳转(jmp),将add函数的第一条指令写入IP,此后就进入add函数栈帧。
call add

// cpu执行完运算后会将结果存储在寄存器中,至于它会把结果存储在那个寄存器,这个由编译器编译出的指令 // 决定的,由add函数的指令来看,它选择了eax // rbp-12 为sum的位置,这条指令将eax寄存器的值赋值给sum mov DWORD PTR [rbp-12], eax // 将eax置0,也就是main的返回值 mov eax, 0 // 意为 mov rsp, rbp 和 pop rbp 的组合 // 此时rbp为main函数的栈基,rsp为main函数的末尾了,将rbp赋值给rsp,于是它们都指向main函数的栈基,上 // 面解释过,rbp寄存器存储的地址指向的栈上的空间存储的还是一个地址,此地址指向调用者的栈基, // pop rbp 将栈顶rsp的数据送入rbp,就意味着之后就回到了调用者的栈帧了,同时pop会伴随着rsp的上移, // 于是rsp来到了EIP的位置。 leave // 相当于 pop ip // 此函数执行完需要跳回到调用者并继续执行下一条指令,由于call的时候已经将下一条指令的地址入栈了,所以 // 此处值需要将其弹出即可。 ret
到此这篇关于GoLang函数栈的使用详细讲解的文章就介绍到这了,更多相关Go函数栈内容请搜索我们以前的文章或继续浏览下面的相关文章希望大家以后多多支持我们!
相关推荐
-
一文带你熟悉Go语言中函数的使用
目录 函数 函数的声明 Go 函数支持变长参数 匿名函数 闭包 init 函数 函数参数详解 形式参数与实际参数 值传递 函数是一种数据类型 小结 函数 函数的英文单词是 Function,这个单词还有着功能的意思.在 Go 语言中,函数是实现某一特定功能的代码块.函数代表着某个功能,可以在同一个地方多次使用,也可以在不同地方使用.因此使用函数,可以提高代码的复用性,减少代码的冗余. 函数的声明 通过案例了解函数的声明有哪几部分: 定义一个函数,实现两个数相加的功能,并将相加之后的结果返回. f
-
GoLang函数栈的使用详细讲解
目录 函数栈帧 寄存器 函数栈帧 我们的代码会被编译成机器指令并写入到可执行文件,当程序执行时,可执行文件被加载到内存,这些机器指令会被存储到虚拟地址空间中的代码段,在代码段内部,指令是低地址向高地址堆积的.堆区存储的是需要程序员手动alloc并free的空间,需要自己来控制. 虚拟内存空间是对存储器的一层抽象,是为了更好的来管理存储器,虚拟内存和存储器之间存在映射关系. 如果在一个函数中调用了另外一个函数,编译器就会对应生成一条call指令,当call指令被执行时,就会跳转到被调用函数入口处开
-

Golang表示枚举类型的详细讲解
枚举,是一种重要的数据类型,由一组键值对组成,通常用来在编程语言中充当常量的标识符.在主流行编程语言如 c. java 等,都有原生支持.在 go 中,大家却找不到 enum 或者其它直接用来声明枚举类型的关键字.从熟悉其它编程语言的开发者转用 go 编程,刚开始会比较难接受这种情况.其实,如果你看到如何在 go 中表示枚举类型时,可能会感受到 go 语言设计者对简洁性.问题考虑的深度,是一般资浅工程师无法比拟的. 其实,在 go 语言设计者的眼里,enum 本质是常量,为什么要多余一个关键字呢
-
Golang设计模式之原型模式详细讲解
目录 原型模式 概念示例 原型模式 原型是一种创建型设计模式, 使你能够复制对象, 甚至是复杂对象, 而又无需使代码依赖它们所属的类. 所有的原型类都必须有一个通用的接口, 使得即使在对象所属的具体类未知的情况下也能复制对象. 原型对象可以生成自身的完整副本, 因为相同类的对象可以相互访问对方的私有成员变量. 概念示例 让我们尝试通过基于操作系统文件系统的示例来理解原型模式. 操作系统的文件系统是递归的: 文件夹中包含文件和文件夹, 其中又包含文件和文件夹, 以此类推. 每个文件和文件夹都可用一
-
GoLang中panic与recover函数以及defer语句超详细讲解
目录 一.运行时恐慌panic 二.panic被引发到程序终止经历的过程 三.有意引发一个panic并让panic包含一个值 四.施加应对panic的保护措施从而避免程序崩溃 五.多条defer语句多条defer语句的执行顺序 一.运行时恐慌panic panic是一种在运行时抛出来的异常.比如"index of range". panic的详情: package main import "fmt" func main() { oneC := []int{1, 2,
-
C语言超详细讲解函数栈帧的创建和销毁
目录 1.本节目标 2.相关寄存器 3.相关汇编指令 4.什么是函数栈帧 5.什么是调用堆栈 6.函数栈帧的创建和销毁 (1).main函数栈帧的创建与初始化 (2).main函数的核心代码 (3).Add函数的调用过程 (4).Add函数栈帧的销毁 (5).调用完成 7.对开篇问题的解答 1.本节目标 C语言绝命七连问,你能回答出几个? 局部变量是如何创建的?为什么局部变量不初始化其内容是随机的?有些时候屏幕上输出的"烫烫烫"是怎么来的?函数调用时参数时如何传递的?传参的顺序是怎样的
-
GoLang内存模型详细讲解
目录 栈内存-协程栈-调用栈 逃逸分析 go 堆内存 堆如何进行分配 go 语言对象的垃圾回收 如何减少GC对性能的分析 GC 优化效率 栈内存-协程栈-调用栈 为什么go的栈是在堆上? go 协程栈的位置: go的协程栈位于go的堆内存,go 的gc 也是对堆上内存进行GC, go堆内存位于操作系统虚拟内存上, 记录局部变量,传递参数和返回值 ,go 使用的参数拷贝传递,如果传递的值比较大 注意传递其指针 go 参数传递 使用 值传递, 也就是说传递结构体时候,拷贝结构体的指针,传递结构体指针
-
C语言超详细讲解栈的实现及代码
目录 前言 栈的概念 栈的结构 栈的实现 创建栈结构 初始化栈 销毁栈 入栈 出栈 获取栈顶元素 获取栈中有效元素个数 检测栈是否为空 总代码 Stack.h 文件 Stack.c 文件 Test.c 文件 前言 栈的概念 栈:一种特殊的线性表,其只允许在固定的一端进行插入和删除元素操作.进行数据插入和删除操作的一端称为栈顶,另一端称为栈底.栈中的数据元素遵守后进先出LIFO(Last In First Out)的原则.有点类似于手枪弹夹,后压进去的子弹总是最先打出,除非枪坏了. 压栈:栈的插入
-
C语言函数超详细讲解下篇
目录 前言 函数的声明和定义 函数声明 函数定义 举例 简单的求和函数 把加法单独改写成函数 添加函数声明 带头文件和函数声明 静态库(.lib)的生成 静态库文件的使用方法 函数递归 什么是递归? 递归的两个必要条件 练习1 一般方法 递归的方法 练习2 一般方法 递归方法 练习3 一般方法 递归方法 练习4 一般方法 递归方法 递归与迭代 递归隐藏的问题 如何改进 选递归还是迭代 总结 前言 紧接上文,继续学习函数相关内容. 函数的声明和定义 函数声明 告诉编译器有一个函数叫什么,参数是什么
-
Golang详细讲解常用Http库及Gin框架的应用
目录 1. Http标准库 1.1 http客户端 1.2 自定义请求头 1.3 检查请求重定向 1.4 http服务器性能分析 2. JSON数据处理 2.1 实体序列化 2.2 处理字段为小写下划线 2.3 省略空字段 2.4 反序列化 3. 自然语言处理 3.1 使用Map处理 3.2 定义实体处理 4. http框架 4.1 gin 4.1.1 启动服务 4.1.2 middleware 4.1.3 设置请求ID 1. Http标准库 1.1 http客户端 func main() {
-
GoLang RabbitMQ TTL与死信队列以及延迟队列详细讲解
目录 TTL 死信队列 延迟队列 Go实现延迟队列 TTL TTL 全称 Time To Live(存活时间/过期时间).当消息到达存活时间后,还没有被消费,就会被自动清除.RabbitMQ可以设置两种过期时间: 对消息设置过期时间. 对整个队列(Queue)设置过期时间. 如何设置 设置队列过期时间使用参数:x-message-ttl,单位:ms(毫秒),会对整个队列消息统一过期. 设置消息过期时间使用参数:expiration,单位:ms(毫秒),当该消息在队列头部时(消费时),会单独判断这