MySQL中隐式转换的踩坑记录以及解决方法分享
目录
- 复现当时的情景
- 根源所在
- 隐式转换的规则
- 避免进行隐式转换
本来是一个平静而美好的下午,其他部门的同事要一份数据报表临时汇报使用,因为系统目前没有这个维度的功能,所以需要写个SQL马上出一下,一个同事接到这个任务,于是开始在测试环境拼装这条 SQL,刚过了几分钟,同事已经自信的写好了这条SQL,于是拿给DBA,到线上跑一下,用客户端工具导出Excel 就好了,毕竟是临时方案嘛。
就在SQL执行了之后,意外发生了,先是等了一下,发现还没执行成功,猜测可能是数据量大的原因,但是随着时间滴滴答答流逝,逐渐意识到情况不对了,一看监控,CPU已经上去了,但是线上数据量虽然不小,也不至于跑成这样吧,眼看着要跑死了,赶紧把这个事务结束掉了。
什么原因呢?查询的条件和 join 连接的字段基本都有索引,按道理不应该这样啊,于是赶紧把SQL拿下来,也没看出什么问题,于是限制查询条数再跑了一次,很快出结果了,但是结果却大跌眼镜,出来的查询结果并不是预期的。
经过一番检查之后,最终发现了问题所在,是 join 连接中有一个字段写错了,因为这两个字段有一部分名称是相同的,于是智能的 SQL 客户端给出了提示,顺手就给敲上去了。但是接下来,更让人迷惑了,因为要连接的字段是 int 类型,而写错的这个字段是 varchar 类型,难道不应该报错吗?怎么还能正常执行,并且还有预期外的查询结果?
难道是 MySQL 有 bug 了,必须要研究一下了。
复现当时的情景
假设有两张表,这两张表的结构和数据是下面这样的。
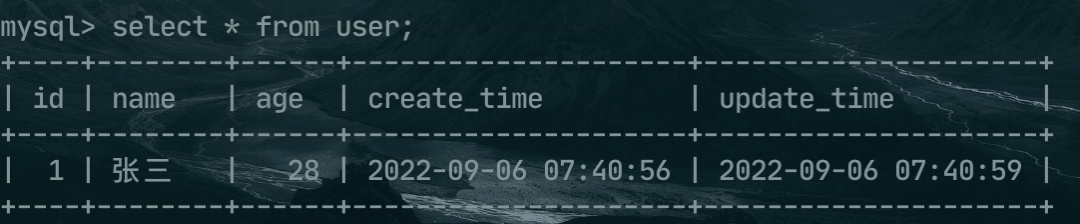
第一张 user表。
CREATE TABLE `user` ( `id` int(11) NOT NULL AUTO_INCREMENT, `name` varchar(50) COLLATE utf8_bin DEFAULT NULL, `age` int(3) DEFAULT NULL, `create_time` datetime DEFAULT NULL, `update_time` datetime DEFAULT NULL, PRIMARY KEY (`id`) ) ENGINE=InnoDB AUTO_INCREMENT=2 DEFAULT CHARSET=utf8 COLLATE=utf8_bin; INSERT INTO `user` VALUES (1, '张三', 28, '2022-09-06 07:40:56', '2022-09-06 07:40:59');
第二张 order表
CREATE TABLE `order` ( `id` int(11) NOT NULL AUTO_INCREMENT, `user_id` int(11) DEFAULT NULL, `order_code` varchar(64) COLLATE utf8_bin DEFAULT NULL, `money` decimal(20,0) DEFAULT NULL, `title` varchar(255) COLLATE utf8_bin DEFAULT NULL, `create_time` datetime DEFAULT NULL, `update_time` datetime DEFAULT NULL, PRIMARY KEY (`id`) ) ENGINE=InnoDB AUTO_INCREMENT=2 DEFAULT CHARSET=utf8 COLLATE=utf8_bin; INSERT INTO `order` VALUES (1, 2, '1d90530e-6ada-47c1-b2fa-adba4545aabd', 100, 'xxx购买两件商品', '2022-09-06 07:42:25', '2022-09-06 07:42:27');

目的是查看所有用户的 order 记录,假设数据量比较少,可以直接查,不考虑性能问题。
本来的 SQL 语句应该是这样子的,查询 order表中用户iduser_id在user表的记录。
select o.* from `user` u left JOIN `order` o on u.id = o.user_id;
但是呢,因为手抖,将 on 后面的条件写成了 u.id = o.order_code,完全关联错误,这两个字段完全没有联系,而且u.id是 int 类型,o.order_code是varchar类型。
select o.* from `user` u left JOIN `order` o on u.id = o.order_code;
这样的话, 当我们执行这条语句的时候,会不会查出数据来呢?
我的第一感觉是,不仅不会查出数据,而且还会报错,因为连接的这两个字段类型都不一样,值更不一样。
结果却被啪啪打脸,不仅没有报错,而且还查出了数据。

可以把这个问题简化一下,简化成下面这条语句,同样也会出现问题。
select * from `order` where order_code = 1;

明明这条记录的 order_code 字段的值是 1d90530e-6ada-47c1-b2fa-adba4545aabd,怎么用 order_code=1的条件就把它给查出来了。
根源所在
相信有的同学已经猜出来了,这里是 MySQL 进行了隐式转换,由于查询条件后面跟的查询值是整型的,所以 MySQL 将 order_code字段进行了字符串到整数类型的转换,而转换后的结果正好是 1。
通过 cast函数转换验证一下结果。
select cast('1d90530e-6ada-47c1-b2fa-adba4545aabd' as unsigned);

再用两条 SQL 看一下字符串到整数类型转换的规则。
select cast('223kkk' as unsigned);
select cast('k223kkk' as unsigned);
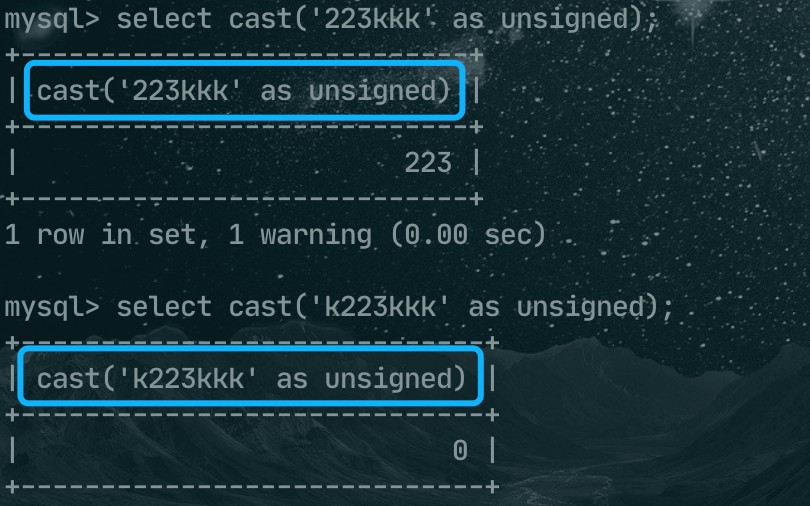
223kkk转换后的结果是 223,而k223kkk转换后的结果是0。总结一下,转换的规则是:
1、从字符串的左侧开始向右转换,遇到非数字就停止;
2、如果第一个就是非数字,最后的结果就是0;
隐式转换的规则
当操作符与不同类型的操作数一起使用的时候,就会发生隐式转换。
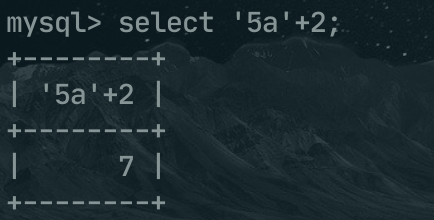
例如算数运算符的前后是不同类型时,会将非数字类型转换为数字,比如 '5a'+2,就会将5a转换为数字类型,然后和2相加,最后的结果就是 7 。
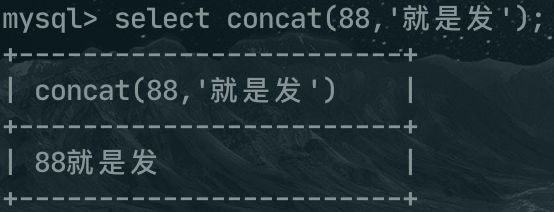
再比如 concat函数是连接两个字符串的,当此函数的参数出现非字符串类型时,就会将其转换为字符串,例如concat(88,'就是发'),最后的结果就是 88就是发。
MySQL 官方文档有以下几条关于隐式转换的规则:
1、两个参数至少有一个是 NULL 时,比较的结果也是 NULL,例外是使用 <=> 对两个 NULL 做比较时会返回 1,这两种情况都不需要做类型转换;
也就是两个参数中如果只有一个是NULL,则不管怎么比较结果都是 NULL,而两个 NULL 的值不管是判断大于、小于或等于,其结果都是1。
2、两个参数都是字符串,会按照字符串来比较,不做类型转换;
3、两个参数都是整数,按照整数来比较,不做类型转换;
4、十六进制的值和非数字做比较时,会被当做二进制字符串;
例如下面这条语句,查询 user 表中name字段是 0x61 的记录,0x是16进制写法,其对应的字符串是英文的 'a',也就是它对应的 ASCII 码。
select * from user where name = 0x61;
所以,上面这条语句其实等同于下面这条
select * from user where name = 'a';
可以用 select 0x61;验证一下。
5、有一个参数是 TIMESTAMP 或 DATETIME,并且另外一个参数是常量,常量会被转换为 时间戳;
例如下面这两条SQL,都是将条件后面的值转换为时间戳再比较了,只不过
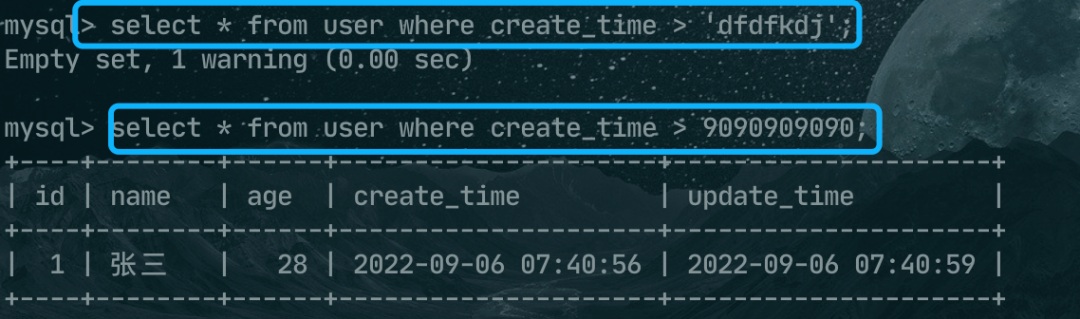
6、有一个参数是 decimal 类型,如果另外一个参数是 decimal 或者整数,会将整数转换为 decimal 后进行比较,如果另外一个参数是浮点数(一般默认是 double),则会把 decimal 转换为浮点数进行比较;
在不同的数值类型之间,总是会向精度要求更高的那一个类型转换,但是有一点要注意,在MySQL 中浮点数的精度只有53 bit,超过53bit之后的话,如果后面1位是1就进位,如果是0就直接舍弃。所以超大浮点数在比较的时候其实只是取的近似值。
7、所有其他情况下,两个参数都会被转换为浮点数再进行比较;
如果不符合上面6点规则,则统一转成浮点数再进行运算
避免进行隐式转换
我们在平时的开发过程中,尽量要避免隐式转换,因为一旦发生隐式转换除了会降低性能外, 还有很大可能会出现不期望的结果,就像我最开始遇到的那个问题一样。
之所以性能会降低,还有一个原因就是让本来有的索引失效。
select * from `order` where order_code = 1;
order_code 是 varchar 类型,假设我已经在 order_code 上建立了索引,如果是用“=”做查询条件的话,应该直接命中索引才对,查询速度会很快。但是,当查询条件后面的值类型不是 varchar,而是数值类型的话,MySQL 首先要对 order_code 字段做类型转换,转换为数值类型,这时候,之前建的索引也就不会命中,只能走全表扫描,查询性能指数级下降,搞不好,数据库直接查崩了。
到此这篇关于MySQL中隐式转换的踩坑记录以及解决方法分享的文章就介绍到这了,更多相关MySQL隐式转换内容请搜索我们以前的文章或继续浏览下面的相关文章希望大家以后多多支持我们!
相关推荐
-
MySQL索引失效之隐式转换的问题
目录 常见索引失效: 一.常见索引失效场景 1.条件字段函数操作 2.条件字段运算操作 3.隐式类型转换 4.隐式字符编码转换 二.类型转换 1.字符串转整型 2.时间类型转换 常见索引失效: 1. 条件索引字段"不干净":函数操作.运算操作 2. 隐式类型转换:字符串转数值:其他类型转换 3. 隐式字符编码转换:按字符编码数据长度大的方向转换,避免数据截取 一.常见索引失效场景 root@test 10:50 > show create table t_num\G ******
-

解析MySQL隐式转换问题
一.问题描述 root@mysqldb 22:12: [xucl]> show create table t1\G *************************** 1. row *************************** Table: t1 Create Table: CREATE TABLE `t1` ( `id` varchar(255) DEFAULT NULL ) ENGINE=InnoDB DEFAULT CHARSET=utf8 1 row in set (0.0
-
谈谈MySQL中的隐式转换
工作过程中会遇到比较多关于隐式转换的案例,隐式转换除了会导致慢查询,还会导致数据不准.本文通过几个生产中遇到的案例来. 基础知识 关于比较运算的原则,MySQL官方文档的描述: https://dev.mysql.com/doc/refman/5.6/en/type-conversion.html 如果 判断符号左右两边有一个为NULL,结果就是null,除非使用安全的等值判断 <=> (none) 05:17:16 >select null = null; +------------
-
MySQL的隐式类型转换整理总结
前言 前几天在看到一篇文章:价值百万的 MySQL 的隐式类型转换感觉写的很不错,再加上自己之前也对MySQL的隐式转化这边并不是很清楚,所以就顺势整理了一下.希望对大家有所帮助. 当我们对不同类型的值进行比较的时候,为了使得这些数值「可比较」(也可以称为类型的兼容性),MySQL会做一些隐式转化(Implicit type conversion). 比如下面的例子: mysql> SELECT 1+'1'; -> 2 mysql> SELECT CONCAT(2,' test'); -
-
MySQL隐式类型转换导致索引失效的解决
目录 问题 复现 隐式转换 总结 参考 问题 在工作中发现,有一个接口只执行一条SQL查询语句,并且SQL明明使用了主键列,但是速度很慢. 在MySQL中EXPLAINN后发现,执行时并没有使用主键索引,而是进行了全表扫描. 复现 数据表DDL如下,使用 user_id 作为主键索引: CREATE TABLE `user_message` ( `user_id` varchar(50) NOT NULL COMMENT '用户ID', `msg_id` int(11) NOT NULL COM
-
MySQL令人大跌眼镜的隐式转换
目录 MySQL的隐式转换 一.问题描述 二.源码解释 三.结论 MySQL的隐式转换 一.问题描述 show create table t1\G *************************** 1. row *************************** Table: t1 Create Table: CREATE TABLE `t1` ( `id` varchar(255) DEFAULT NULL ) ENGINE=InnoDB DEFAULT CHARSET=utf8 1
-
浅谈MySql整型索引和字符串索引失效或隐式转换问题
目录 问题概述 问题重现 问题引申 结论 问题概述 今天在上班时,DBA突然找出来一段sql,表示该sql存在隐式转换,不走索引.经过我们的查看后,发现是类型varchar的字段, 我们使用条件传入了数值型的值,由于担心违反保密协议,在此就不贴图了,由我重现一下类似情况给大家看一下. 问题重现 首先我们先创建一张用户表test_user,其中USER_ID为了效果我们设置为varchar类型且加上唯一索引. CREATE TABLE test_user ( ID int(11) NOT NULL
-
MySQL中隐式转换的踩坑记录以及解决方法分享
目录 复现当时的情景 根源所在 隐式转换的规则 避免进行隐式转换 本来是一个平静而美好的下午,其他部门的同事要一份数据报表临时汇报使用,因为系统目前没有这个维度的功能,所以需要写个SQL马上出一下,一个同事接到这个任务,于是开始在测试环境拼装这条 SQL,刚过了几分钟,同事已经自信的写好了这条SQL,于是拿给DBA,到线上跑一下,用客户端工具导出Excel 就好了,毕竟是临时方案嘛. 就在SQL执行了之后,意外发生了,先是等了一下,发现还没执行成功,猜测可能是数据量大的原因,但是随着时间滴滴答答
-
mybatis if传入字符串数字踩坑记录及解决
目录 mybatis if传入字符串数字踩坑 正确的写法如下 mybatis if比较字符串相等问题 总结 mybatis if传入字符串数字踩坑 前台页面内容,注意这里的类型为字符串类型的数字 <li> <label>支付类型:</label> <form:select path="payType" class="input-medium"> <form:option value
-
mysql 双向同步的键值冲突问题的解决方法分享
出现的问题(多主自增长ID重复) 1:首先我们通过A,B的test表结构 2:掉A,在B上对数据表test(存在自增长ID)执行插入操作,返回插入ID为1 3:后停掉B,在A上对数据表test(存在自增长ID)执行插入操作,返回的插入ID也是1 4:然后 我们同时启动A,B,就会出现主键ID重复 解决方法: 我们只要保证两台服务器上插入的自增长数据不同就可以了 如:A查奇数ID,B插偶数ID,当然如果服务器多的话,你可以定义算法,只要不同就可以了 在这里我们在A,B上加入参数,以实现奇偶插入 A
-
Tensorflow与RNN、双向LSTM等的踩坑记录及解决
1.tensorflow(不定长)文本序列读取与解析 tensorflow读取csv时需要指定各列的数据类型. 但是对于RNN这种接受序列输入的模型来说,一条序列的长度是不固定.这时如果使用csv存储序列数据,应当首先将特征序列拼接成一列. 例如两条数据序列,第一项是标签,之后是特征序列 [0, 1.1, 1.2, 2.3] 转换成 [0, '1.1_1.2_2.3'] [1, 1.0, 2.5, 1.6, 3.2, 4.5] 转换成 [1, '1.0_2.5_1.6_3.2_4.5'] 这样每
-
微信小程序踩坑记录之解决tabBar.list[3].selectedIconPath大小超过40kb
发现问题 重新启动微信小程序编辑器的时候遇到了这样的一个问题: tabBar.list[3].selectedIconPath 大小超过 40kb 微信小程序开发的过程之中总会出现这样或者那样的错误,需要我们耐心的去寻找,仔细查看和百度查询之后,发现了原因:其中有一张图片,替换的时候没有注意图片大小,导致项目无法预览. 解决方法 参考了一下微信小程序的官方API,查看tabBar list定义说明:也就是说选中时的图片路径,icon 大小限制为40kb,建议尺寸为 81px * 81px,而我新
-
一次mysql迁移的方案与踩坑实战记录
目录 背景 方案一:老数据备份 方案二:分表 方案三:迁移至tidb 重点说下同步老数据遇到的坑 最终同步脚本方案 总结 背景 由于历史业务数据采用mysql来存储的,其中有一张操作记录表video_log,每当用户创建.更新或者审核人员审核的时候,对应的video_log就会加一条日志,这个log表只有insert,可想而知,1个video对应多条log,一天10w video,平均统计一个video对应5条log,那么一天50w的log, 一个月50 * 30 = 1500w条记录, 一年就
-
Java踩坑记录之Arrays.AsList
前言 java.util.Arrays的asList方法可以方便的将数组转化为集合,我们平时开发在初始化ArrayList时使用的比较多,可以简化代码,但这个静态方法asList()有几个坑需要注意: 一. 如果对集合使用增加或删除元素的操作将会报错 如下代码: List list = Arrays.asList("a","b","c"); list.add("d"); 输出结果: Exception in thread &q
-
Spring Boot统一返回体的踩坑记录
前言 在Spring Boot项目中我们可以通过RestControllerAdvice配合实现ResponseBodyAdvice<T>接口来保证Spring MVC接口具有统一的返回格式,以保证前端同学能够封装统一的数据接收工具.但是很多网上的文章并没有对实际开发中的细节作出更多的讲解.今天胖哥就来分享一下我的采坑经历,也算作一个总结. 控制作用范围 我记得在前面关于Swagger3的文章中提过,如果我们不指定范围将导致Swagger无法识别接口的元信息.因此如果你使用了Swagger必须
-
Java常见踩坑记录之异常处理
目录 一.Java异常类层次结构 二.Throwable类常用方法 三.try-catch-finally 四.使用 try-with-resources 来代替try-catch-finally 五.自定义异常 总结 一.Java异常类层次结构 Java中,所有的异常都来源于java.lang包中的Throwable类,它有两个重要的子类,Exception(异常)和Error(错误). Exception :程序本身可以处理的异常,可以通过 catch 来进行捕获.Exception 又可以
-
Java中Objects.equals踩坑记录
目录 前言 1. 案发现场 2. 判断相等的方法 2.1 使用==号 2.2 使用equals方法 3. 空指针异常 4. Objects.equals的作用 5. Objects.equals的坑 总结 前言 最近review别人代码的时候,发现有个同事,在某个业务场景下,使用Objects.equals方法判断两个值相等时,返回了跟预期不一致的结果,引起了我的兴趣. 原本以为判断结果会返回true的,但实际上返回了false. 记得很早之前,我使用Objects.equals方法也踩过类似的