Spring Data JPA系列JpaSpecificationExecutor用法详解
目录
- 1、JpaSpecificationExecutor用法
- 2、JpaSpecificationExecutor语法详解
- 2.1 Specification 接口
- 2.2 Root< User >root
- 2.3 CriteriaQuery<?> query
- 2.4 CriteriaBuilder cb
在上一篇文章中,我们介绍了QueryByExampleExecutor动态查询的方法,那么今天我们来学习JpaSpecificationExecutor的详细用法。
1、JpaSpecificationExecutor用法
我们来创建实体类,第一步:创建User类和UserAddress类
// User类
@Data
@Entity
@NoArgsConstructor
@AllArgsConstructor
@Builder
@ToString(exclude = "address")
public class User {
@Id
@GeneratedValue(strategy = GenerationType.AUTO)
private Integer id;
private String name;
private String email;
@Enumerated(value = EnumType.STRING)
private SexEnum sex;
private Integer age;
private LocalDateTime createTime;
private LocalDateTime updateTime;
@OneToMany(mappedBy = "user",fetch = FetchType.EAGER)
private List<UserAddress> address;
}
// Address类
@Entity
@Data
@Builder
@AllArgsConstructor
@NoArgsConstructor
@ToString(exclude = "user")
public class UserAddress {
@Id
@GeneratedValue(strategy = GenerationType.AUTO)
private Long id;
private String address;
@ManyToOne(cascade = CascadeType.ALL)
private User user;
}
// 性别枚举类
public enum SexEnum {
BOY,
GIRL
}
第二步:创建UserRepo ,我们继承JpaSpecificationExecutor接口
public interface UserRepo extends JpaSpecificationExecutor<User> {
}
第三步:测试,构造查询条件
- name模糊查询
- sex精准查询
- age范围查询
- address的in查询
@Test
public void test02(){
User userQuery = User.builder()
.name("jack")
.email("123456@126.com")
.sex(SexEnum.BOY)
.age(20)
.address(Lists.newArrayList(UserAddress.builder().address("shanghai").build()))
.build();
List<User> userList = userRepo.findAll(new Specification<User>() {
@Override
public Predicate toPredicate(Root<User> root, CriteriaQuery<?> query, CriteriaBuilder cb) {
List<Predicate> predicateList = new ArrayList<>();
// name模糊查询
if(StringUtils.isNotBlank(userQuery.getName())) {
predicateList.add(cb.like(root.get("name"),userQuery.getName()));
}
// sex精准查询
if(userQuery.getSex()!=null) {
predicateList.add(cb.equal(root.get("sex"),userQuery.getSex()));
}
// age范围查询
if(userQuery.getAge()!=null){
predicateList.add(cb.greaterThanOrEqualTo(root.get("age"),userQuery.getAge()));
}
// 关联查询
if(!ObjectUtils.isEmpty(userQuery.getAddress())) {
predicateList.add(cb.in(root.join("address").get("address")).value(userQuery.getAddress().stream().map(a->a.getAddress()).collect(Collectors.toList())));
}
return query.where(predicateList.toArray(new Predicate[predicateList.size()])).getRestriction();
}
});
System.out.println(userList);
}
SQL执行结果如下:
select user0_.id as id1_4_, user0_.age as age2_4_, user0_.create_time as create_t3_4_, user0_.email as email4_4_, user0_.name as name5_4_, user0_.sex as sex6_4_, user0_.update_time as update_t7_4_ from user user0_ inner join user_address address1_ on user0_.id=address1_.user_id where (user0_.name like ?) and user0_.sex=? and user0_.age>=20 and (address1_.address in (?))
2、JpaSpecificationExecutor语法详解
先看源码:
public interface JpaSpecificationExecutor<T> {
Optional<T> findOne(@Nullable Specification<T> spec);
List<T> findAll(@Nullable Specification<T> spec);
Page<T> findAll(@Nullable Specification<T> spec, Pageable pageable);
List<T> findAll(@Nullable Specification<T> spec, Sort sort);
long count(@Nullable Specification<T> spec);
boolean exists(Specification<T> spec);
}
- findOne(@Nullable Specification spec):根据Specification 条件查询单个对象
- findAll(@Nullable Specification spec):根据Specification 条件, 查询List结果
- findAll(@Nullable Specification spec, Pageable pageable):根据Specification 条件, 分页查询
- findAll(@Nullable Specification spec, Sort sort):根据Specification 条件,带排序的查询结果
- count(@Nullable Specification spec): 根据Specification 条件,查询数量
- exists(Specification spec):根据Specification 条件,查询是否存在
2.1 Specification 接口
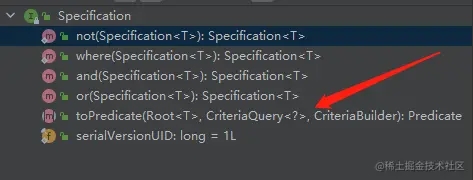
我们主要来看一下需要实现的方法:toPredicate(xx,xx,xx)
@Nullable Predicate toPredicate(Root<T> root, CriteriaQuery<?> query, CriteriaBuilder criteriaBuilder);
调试代码

我们可以分别看到Root的实现类是RootImpl,CriteriaQuery的实现类是CriteriaQueryImpl,CriteriaBuilder的实现类是CriteriaBuilderImpl。这三个实现类都是由Hibernate实现,也就是说JpaSepcificationExecutor封装了原本需要我们直接操作Hibernate中Criteria的API。
2.2 Root< User >root
解释:这个root就相当于查询和操作的实体对象的根,我们就可以通过Path get(xx)的方法,来获取我们想要操作的字段。
<Y> Path<Y> get(String attributeName);
例如:获取User实体类中的name字段
predicateList.add(cb.like(root.get("name"),userQuery.getName()));
2.3 CriteriaQuery<?> query
这是一个Specific的顶层查询对象,它包含着查询的各个部分,比如select、from、where、group by 、Order by、distinct等。提供查询Root的方法,我们来看一下源码:
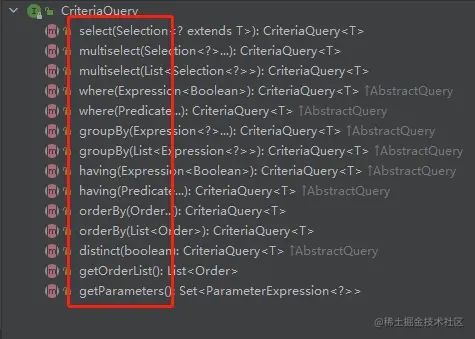
我们可以在上面的案例中看到query的用法:
return query.where(predicateList.toArray(new Predicate[predicateList.size()])).getRestriction();
我们可以再加一个groupBy的例子看看,如下所示:可以链式拼接
return query.where(predicateList.toArray(new Predicate[predicateList.size()])).groupBy(root.get("age")).getRestriction();
执行的SQL如下所示:

2.4 CriteriaBuilder cb
CriteriaBuilder是用来构建CritiaQuery的构建对象,其实就相当于条件或者条件组合,并以Predicate的形式返回,基本提供了所有常用的方法。
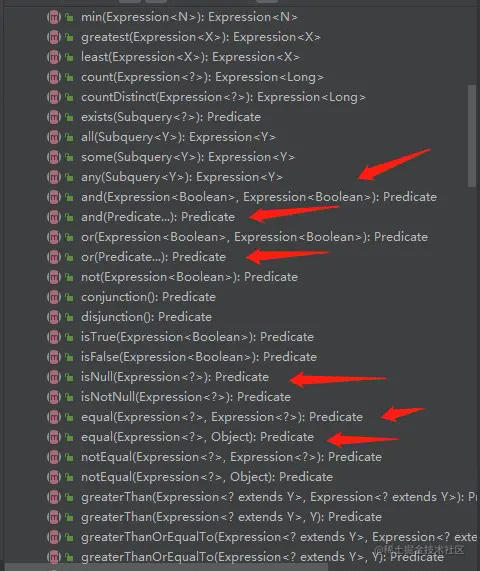
通过源码我们可以看到CriteriaBuilder 提供了and、any等用来查询条件的组合;还提供了between、equal、exist等用来做查询条件的查询。
例如:equal
predicateList.add(cb.equal(root.get("sex"),userQuery.getSex()));
例如:like
predicateList.add(cb.like(root.get("name"),userQuery.getName()));
例如:greaterThanEqualTo
predicateList.add(cb.greaterThanOrEqualTo(root.get("age"),userQuery.getAge()));
解释: 我们利用equal、like、greaterThanEqualTo 可以返回Predicate,而Predicate又可以组合起来,就构成了复杂的查询条件,完全满足日常开发使用。
以上就是Spring Data JPA系列JpaSpecificationExecutor用法详解的详细内容,更多关于Spring Data JPA JpaSpecificationExecutor的资料请关注我们其它相关文章!
相关推荐
-
SpringDataJpa的使用之一对一、一对多、多对多 关系映射问题
目录 SpringDataJpa的使用 -- 一对一.一对多.多对多 关系映射 项目依赖 项目配置 sql文件(MySQL版) 级联关系简述 @OneToOne 一对一 关系映射 1.无中间表,维护方添加外键,被维护方添加对应项 2.无中间表,维护方添加外键,被维护方不添加对应项 3.有中间表,维护方不添加外键,被维护方不添加对应项 @OneToMany.@ManyToOne 一对多 关系映射 1.无中间表,多方维护并添加外键,一方被维护 2.有中间表,多方维护,一方被维护 3.无中间表,多方维
-

Spring Data JPA 注解Entity关联关系使用详解
目录 1.OneToOne关联关系 1.1 解读OneToOne源码 1.2 mappedBy 注意事项 1.3 CascadeType 用法 1.4 orphanRemoval属性用法 1.5 orphanRemoval 和 CascadeType.REMOVE的区别 2.@JoinColumns & @JoinColumn 3.@ManyToOne & @OneToMany 3.1 Lazy机制 4.ManyToMany 4.1 利用@ManyToOne 和 @OneToMany表达多
-
Spring Data Jpa返回自定义对象的3种方法实例
目录 方法一.简单查询直接new对象 方法二.Service层使用EntityManager 方法三.Dao层使用Map接收自定义对象 总结 tasks表对应的Entity @Entity @NoArgsConstructor @AllArgsConstructor @Table(name = "tasks") @Data public class Tasks extends BaseEntity { @Id @GeneratedValue(strategy = GenerationT
-
Spring Data JPA注解Entity使用示例详解
目录 1.JPA协议中关于Entity的相关规定 需要注意的是: 2.常用注解 2.1 JPA支持的注解 2.2 常用注解 3.联合主键 3.1 @IdClass 3.2 @Embeddable与@EmbeddedId注解使用 3.3 两者的区别是什么? 1.JPA协议中关于Entity的相关规定 (1)实体是直接进行数据库持久化操作的领域对象(即一个简单的POJO),必须通过@Entity注解进行标示. (2)实体必须有一个 public 或者 projected的无参数构造方法. (3)持久
-
Spring Data JPA系列QueryByExampleExecutor使用详解
目录 1.QueryByExampleExecutor用法 1.1 介绍 1.2 QueryByExampleExecutor接口 1.3 QueryByExampleExecutor实践 1.4 Example语法详解 1.5 ExampleMatcher语法分析 2.ExampleMatcher语法暴露常用方法 2.1 忽略大小写 2.2 NULL值的Property的处理方式 2.3 忽略某些属性列表,不参与查询过滤条件 2.4 字符串默认的匹配规则 3.实践出真理 3.1 AND查询 3
-
Spring Boot 整合持久层之Spring Data JPA
目录 整合Spring Data JPA 1. 创建数据库 2. 创建项目 3. 数据库配置 4. 创建实体类 5. 创建 BookDao 接口 6. 创建 BookService 7. 创建 BookController 8. 测试 整合Spring Data JPA JPA (Java Persistence API)和 Spring Data 是两个范畴的概念. Hibernate 是一个 ORM 框架,JPA 则是一种ORM,JPA 和 Hibernate 的关系就像 JDBC 与 JD
-
Spring Data JPA系列JpaSpecificationExecutor用法详解
目录 1.JpaSpecificationExecutor用法 2.JpaSpecificationExecutor语法详解 2.1 Specification 接口 2.2 Root< User >root 2.3 CriteriaQuery<?> query 2.4 CriteriaBuilder cb 在上一篇文章中,我们介绍了QueryByExampleExecutor动态查询的方法,那么今天我们来学习JpaSpecificationExecutor的详细用法. 1.Jpa
-
Spring data jpa的使用与详解(复杂动态查询及分页,排序)
一. 使用Specification实现复杂查询 (1) 什么是Specification Specification是springDateJpa中的一个接口,他是用于当jpa的一些基本CRUD操作的扩展,可以把他理解成一个spring jpa的复杂查询接口.其次我们需要了解Criteria 查询,这是是一种类型安全和更面向对象的查询.而Spring Data JPA支持JPA2.0的Criteria查询,相应的接口是JpaSpecificationExecutor. 而JpaSpecifica
-
详解Spring Data JPA系列之投影(Projection)的用法
本文介绍了Spring Data JPA系列之投影(Projection)的用法,分享给大家 在JPA的查询中,有一个不方便的地方,@Query注解,如果查询直接是 Select C from Customer c ,这时候,查询的返回对象就是Customer这个完整的对象,包含所有字段,对于我们的示例并没有什么问题,但是对于比较庞大的domain类,这个查询时就比较要命,并不是所有的字段都能用到,比较头疼.另外,如果定义 select c.firstName as firstName,c.la
-
spring boot + jpa + kotlin入门实例详解
spring boot +jpa的文章网络上已经有不少,这里主要补充一下用kotlin来做. kotlin里面的data class来创建entity可以帮助我们减少不少的代码,比如现在这个User的Entity,这是Java版本的: @Entity public class User { @Id @GeneratedValue(strategy = GenerationType.AUTO) private long id; private String firstName; private S
-
Spring MVC 拦截器 interceptor 用法详解
Spring MVC-拦截器 今天就是把有关拦截器的知识做一个总结. 1.拦截器概述 1.1 什么是拦截器? Spring MVC中的拦截器(Interceptor)类似于Servlet中的过滤器(Filter),它主要用于拦截用户请求并作相应的处理.例如通过拦截器可以进行权限验证.记录请求信息的日志.判断用户是否登录等. 要使用Spring MVC中的拦截器,就需要对拦截器类进行定义和配置.通常拦截器类可以通过两种方式来定义. 1.通过实现HandlerInterceptor接口,或继承Han
-
Spring实战之@Autowire注解用法详解
本文实例讲述了Spring实战之@Autowire注解用法.分享给大家供大家参考,具体如下: 一 配置 <?xml version="1.0" encoding="GBK"?> <beans xmlns="http://www.springframework.org/schema/beans" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance" xmln
-
详解Spring Data Jpa 模糊查询的正确用法
模糊查询 Spring Data Jpa的使用可以减少开发者对sql语句的编写,甚至完全不需要编写sql语句.但是,开发过程中总会遇到各种复杂的场景以及大大小小的坑. 今天项目中某个功能模块需要用到模糊查询.原生sql中模糊查询关键字'Like',而Spring Data Jpa的Repository接口中恰恰也有实体字段对应的Like.但是,如果直接使用它,那么恭喜你,你幸运地掉坑了. Spring Data Jpa 模糊查询正确用法 首先,我们先创建一个实体用来存储我们的数据 /** * 实
-
Spring Data Jpa的四种查询方式详解
这篇文章主要介绍了Spring Data Jpa的四种查询方式详解,文中通过示例代码介绍的非常详细,对大家的学习或者工作具有一定的参考学习价值,需要的朋友可以参考下 一.调用接口的方式 1.基本介绍 通过调用接口里的方法查询,需要我们自定义的接口继承Spring Data Jpa规定的接口 public interface UserDao extends JpaRepository<User, Integer>, JpaSpecificationExecutor<User> 使用这