在 C# 中使用 Span<T> 和 Memory<T> 编写高性能代码的详细步骤
目录
- .NET 中支持的内存类型
- .NET Core 2.1 中新增的类型
- 访问连续内存: Span 和 Memory
- Span 介绍
- C# 中的 Span
- Span 和 Arrays
- Span 和 ReadOnlySpan
- Memory 入门
- ReadOnlyMemory
- Span 和 Memory 的优势
- 连续和非连续内存缓冲区
- 不连续的缓冲区: ReadOnly 序列
- 实际场景
- Benchmarking 基准测试
- 安装 NuGet 包
- Benchmarking Span
- 执行基准测试
- 解读基准测试结果
- Span 限制
- 结论
本文采用半译方式。
在本文中,将会介绍 C# 7.2 中引入的新类型:Span 和 Memory,文章深入研究 Span<T> 和 Memory<T> ,并演示如何在 C# 中使用它们。
本文所有代码用例在 .NET 6.0 下运行。
.NET 中支持的内存类型
.NET 中,开发者能够使用的三种内存类型,分别是:
- Stack memory 堆栈内存: 驻留在堆栈中,并使用
stackalloc关键词分配; - Managed memory 托管内存: 驻留在堆中并由 GC 管理;
- Unmanaged memory 非托管内存: 驻留在非托管堆中,并通过调用
Marshal.AllocHGlobalor 或者Marshal.AllocCoTaskMem方法 分配;
.NET Core 2.1 中新增的类型
.NET Core 2.1 中新引入的类型包括:
- System.Span: 这以类型安全和内存安全的方式表示任意内存的连续部分;
- System.ReadOnlySpan: 这表示任意连续内存区域的类型安全和内存安全只读表示形式;
- **System.Memory: ** 这表示一个连续的内存区域;
- System.ReadOnlyMemory: 类似
ReadOnlySpan, 此类型表示内存的连续部分ReadOnlySpan, 它不是 ByRef 类型;
译者注:
ByRef类型指的是ref readonly struct。
访问连续内存: Span 和 Memory
开发者可能经常需要在应用程序中处理大量数据,例如字符串处理在任何应用程序中都是至关重要的,因此开发者必须遵循推荐的实践以避免不必要的分配。开发者可以使用不安全的代码块和指针直接操作内存,但是这种方法有相当大的风险,指针操作容易出现错误,如溢出、空指针访问、缓冲区溢出和悬空指针。如果 bug 只影响堆栈或静态内存区域,那么它将是无害的,但是如果它影响关键的系统内存区域,则可能导致应用程序崩溃。
因此,出现了 Span<T> 和 Memory<T> ,能够以安全的方式使用指针访问内存。
Span<T> 和 Memory<T> 是 .NET 新引入的类型(都是 struct),它们提供了一种类型安全的方法来访问任意内存的连续区域。Span<T> 和 Memory<T> 都是 System 命名空间的一部分,表示连续的内存块,没有任何复制语义。
C# 新版本添加了 Span<T> 、 Memory<T> 、 ReadOnlySpan 和 ReadOnlyMemory 类型 ,它们可以帮助开发者在安全和性能方面直接使用内存。
这些新类型在 System.Memory 命名空间中,适用于需要处理大量数据或希望避免不必要的内存分配(例如在使用缓冲区时)的高性能场景。与在 GC 堆上分配内存的数组类型不同,这些新类型提供了对任意托管或本机内存的连续区域的抽象,而不需要在 GC 堆上分配内存。
译者注:因为它们都是 struct,会被分配到栈中。
Span<T> 和 Memory<T> 结构体为数组、字符串或任何连续的托管或非托管内存块提供低级接口,它们的主要功能是促进微优化和编写低分配代码,以减少托管内存分配,从而减少垃圾收集器的负担。它们还允许切片或处理数组、字符串或内存块的某个部分,而无需复制原始内存块。Span<T> 和 Memory<T> 在高性能领域非常有用,例如 ASP.NET Core 6 request-processing 管道。
Span 介绍
Span<T> (早期称为 Slice) 出现于 C# 7.2/NET Core 2.1,创建它的开销几乎为零,它提供了一种使用连续内存块的类型安全方法,例如:
- Arrays and subarrays 数组和子数组
- Strings and substrings 字符串和子字符串
- Unmanaged memory buffers 非托管内存缓冲区
Span 类型表示驻留在托管堆、堆栈甚至非托管内存中的连续内存块,如果创建一个基元类型的数组(使用 stackalloc 创建),它将在堆栈上分配,并且不需要垃圾回收来管理其生存期。Span<T> 能够指向分配给堆栈或堆上的内存块。但是,因为 Span<T> 被定义为 ref 结构,所以它应该只驻留在堆栈上。
以下是一目了然的 Span<T> 的特征:
- Value type 值类型
- Low or zero overhead 低或零开销
- High performance 高性能
- Provides memory and type safety 提供内存和类型安全
开发者可以将 Span 与下列任一项一起使用
- Arrays
- Strings
- Native buffers 本地缓冲区
可以转换为 Span<T> 的类型列表如下:
- Arrays
- Pointers 指针
- IntPtr 指针
- stackalloc
开发者可以将以下所有内容转换为 ReadOnlySpan<T> :
- Arrays
- Pointers 指针
- IntPtr 指针
- stackalloc
- string
Span<T> 是一个仅堆栈类型, 准确地说它是一个 ByRef 类型。因此,既不能将 span 装箱,也不能显示为仅限堆栈类型的字段,也不能在泛型参数中使用它们。但是,可以使用 span 来表示返回值或方法参数。请参考下面给出的代码片段,它说明了 Span 结构的完整源代码:
public readonly ref struct Span<T>
{
internal readonly
ByReference<T> _pointer;
private readonly int _length;
//Other members
}
因为 Span 定义时,是 public readonly ref struct Span<T>,表示只能在堆栈中分配。

开发者可以在这里查看 struct Span<T> 的完整源代码: https://github.com/dotnet/corefx/blob/master/src/common/src/corelib/system/Span.cs。
Span<T> 源代码显示它基本上包含两个只读字段: 一个本机指针和一个长度属性,表示 Span 包含的元素数。
Span 的使用方式与数组相同,但是与数组不同,它可以引用堆栈内存,即堆栈上分配的内存、托管内存和本机内存。这为开发者提供了一种简单的方法来利用以前只有在处理非托管代码时才能获得的性能改进。
若要创建空的 Span,可以使用 Span.Empty 属性:
Span<char> span = Span<char>.Empty;
下面的代码片段演示如何在托管内存中创建 Byte 数组,然后从中创建 span 实例。
var array = new byte[100]; var span = new Span<byte>(array);
C# 中的 Span
下面是如何在堆栈中分配一块内存并使用 Span 指向它:
Span<byte> span = stackalloc byte[100];
下面的代码片段显示了如何使用字节数组创建 Span、如何将整数存储在字节数组中以及如何计算存储的所有整数的总和。
var array = new byte[100];
var span = new Span<byte>(array);
byte data = 0;
for (int index = 0; index < span.Length; index++)
span[index] = data++;
int sum = 0;
foreach (int value in array)
sum += value;
下面的代码片段从本机内存(非托管内存)创建一个 Span:
var nativeMemory = Marshal.AllocHGlobal(100);
Span<byte> span;
unsafe
{
span = new Span<byte>(nativeMemory.ToPointer(), 100);
}
现在可以使用下面的代码片段在 Span 指向的内存中存储整数,并显示存储的所有整数的总和:
byte data = 0;
for (int index = 0; index < span.Length; index++)
span[index] = data++;
int sum = 0;
foreach (int value in span)
sum += value;
Console.WriteLine ($"The sum of the numbers in the array is {sum}");
Marshal.FreeHGlobal(nativeMemory);
还可以使用 stackalloc 关键字在堆栈内存中分配 Span,如下所示:
byte data = 0;
Span<byte> span = stackalloc byte[100];
for (int index = 0; index < span.Length; index++)
span[index] = data++;
int sum = 0;
foreach (int value in span)
sum += value;
Console.WriteLine ($"The sum of the numbers in the array is {sum}");
需要开启不安全代码设置。
Span 和 Arrays
切片允许将数据视为逻辑块,然后可以以最小的资源开销处理这些逻辑块。Span<T> 可以包装整个数组,因为它支持切片,所以可以让它指向数组中的任何连续区域。下面的代码片段显示了如何使用 Span<T> 指向数组中由三个元素组成的片段。
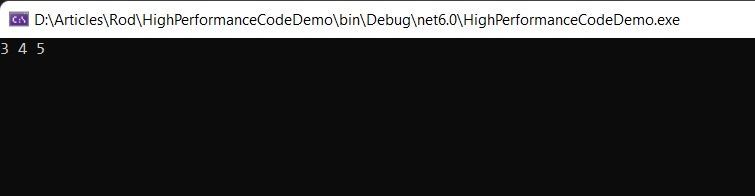
int[] array = new int[] { 1, 2, 3, 4, 5, 6, 7, 8, 9 } ;
Span<int> slice = new Span<int>(array, 2, 3);
作为 Span<T> struct 的一部分,Slice 方法有两个重载,允许基于索引创建,这允许将Span<T> 数据作为一系列逻辑块来处理,这些逻辑块可以单独处理,也可以按照数据处理流水线的各个部分的要求来处理。
开发者可以使用 Span<T> 来包装整个数组。因为它支持切片,所以它不仅可以指向数组的第一个元素,还可以指向数组中任何连续的元素范围。
foreach (int i in slice)
Console.WriteLine($"{i} ");
执行前面的代码片段时,分片数组中的整数将显示在控制台上,如图2所示。
Span 和 ReadOnlySpan
ReadOnlySpan<T> 实例通常用于引用数组项或数组的块。与数组不同,ReadOnlySpan<T> 实例可以引用本机内存、托管内存或堆栈内存。Span<T> 和 ReadOnlySpan<T> 都提供了连续内存区域的类型安全表示, Span<T> 提供对内存区域的读写访问, ReadOnlySpan<T> 提供对内存段的只读访问。
下面的代码片段说明了如何使用 ReadOnlySpan 在 C# 中切割字符串的一部分:
ReadOnlySpan<char> readOnlySpan = "This is a sample data for testing purposes.";
int index = readOnlySpan.IndexOf(' ');
var data = ((index < 0) ?
readOnlySpan : readOnlySpan.Slice(0, index)).ToArray();
Memory 入门
Memory<T> 是一个引用类型,它表示内存的一个连续区域,具有一个长度,但不一定从索引0开始,可以是另一个 Memory 中的许多区域之一。由 Memory 表示的内存甚至可能不是开发者自己的进程,因为它可能已经在非托管代码中分配。内存对于表示非连续缓冲区中的数据非常有用,因为它允许开发者像对待单个连续缓冲区一样对待它们,而不需要进行复制。
以下是 Memory 的定义:
public struct Memory<T>
{
void* _ptr;
T[] _array;
int _offset;
int _length;
public Span<T> Span => _ptr == null ? new Span<T>(_array, _offset, _length) : new Span<T>(_ptr, _length);
}
除了包含 Span<T> 功能外,Memory<T> 还提供了一个安全的、可切片的视图,可以进入任何连续的缓冲区,无论是数组还是字符串。与 Span<T> 不同,它没有仅限于堆栈的约束,因为它不是类似于 ref 的类型。因此,开发者可以将它放在堆上,在集合中或异步等待中使用它,将它保存为字段或装箱,就像对待任何其他 C# 结构一样。
当需要修改或处理 Memory<T> 引用的缓冲区时,Span<T> 属性允许开发者获得高效的索引功能。相反,Memory<T> 是一种比 Span 更通用和高级的交换类型,它具有一个名为 ReadOnlyMemory<T> 的不可变的只读对应物。
尽管 Span<T> 和 Memory<T> 都代表一个连续的内存块,但与 Span<T> 不同,Memory<T> 不是一个 ref 结构。因此,与 Span<T> 相反,开发者可以在托管堆上的任何位置使用 Memory<T> 。因此,在 Memory<T> 中没有与 Span<T> 中相同的限制,开发者可以使用 Memory<T> 作为类字段,并且可以跨 await 和 yield 边界(下面会说到)。
ReadOnlyMemory
与 ReadOnlySpan<T> 类似,ReadOnlyMemory<T> 表示对连续内存区域的只读访问,但与 ReadOnlySpan<T> 不同,它不是 ByRef 类型。
现在请参考下面的字符串,其中包含由空格字符分隔的国家名称。
string countries = "India Belgium Australia USA UK Netherlands";
var countries = ExtractStrings("India Belgium Australia USA UK Netherlands".AsMemory());
通过提取字符串的方法提取每个国家的名称,如下所示:
public static IEnumerable<ReadOnlyMemory <char>> ExtractStrings(ReadOnlyMemory<char> c)
{
int index = 0, length = c.Length;
for (int i = 0; i < length; i++)
{
if (char.IsWhiteSpace(c.Span[i]) || i == length)
{
yield return c[index..i];
index = i + 1;
}
}
}
开发者可以调用上述方法,并使用以下代码片段在控制台窗口中显示国家名称:
var data = ExtractStrings(countries.AsMemory());
foreach(var str in data)
Console.WriteLine(str);
Span 和 Memory 的优势
使用 Span 和 Memory 类型的主要优点是提高了性能。开发者可以通过使用 stackalloc 关键字来分配堆栈上的内存,该关键字分配一个未初始化的块,该块是 T[size]类型的实例。如果开发者的数据已经在堆栈上,则不需要这样做,但是对于大型对象,这样做很有用,因为以这种方式分配的数组只有在其作用域持续存在时才存在。如果使用堆分配的数组,可以通过 Slice()这样的方法传递它们,并在不复制任何数据的情况下创建视图。
这里还有一些好处:
- 它们减少了垃圾收集器的分配数量。它们还减少了数据的副本数量,并提供了一种更有效的方法来同时处理多个缓冲区;
- 它们允许开发者编写高性能代码。例如,如果开发者有一大块内存需要分成小块,那么使用 Span 作为原始内存的视图。这允许开发者的应用程序直接从原始缓冲区访问字节,而无需复制;
- 它们允许开发者直接访问内存而无需复制内存。这在使用本机库或与其他语言进行互操作时特别有用;
- 它们允许开发者在性能至关重要的紧密循环(如加密或网络包检查)中消除边界检查;
- 它们允许开发者消除与通用集合(如 List)相关的装箱和取消装箱成本;
- 通过使用单一数据类型(Span)而不是两种不同类型(Array 和 ArraySegment) ,它们可以编写更容易理解的代码;
连续和非连续内存缓冲区
连续内存缓冲区是将数据保存在顺序相邻位置的内存块,换句话说,所有的字节在内存中都是相邻的。数组表示连续的内存缓冲区。
例如:
int[] values = new int[5];
上面示例中的五个整数将从第一个元素(值[0])开始,按顺序放置在内存中的五个位置。
与连续缓冲区不同,开发者可以使用非连续缓冲区来处理多个数据块并不相邻的情况,或者在使用非托管代码时使用非连续缓冲区,Span 和 Memory 类型是专门为非连续缓冲区设计的,并提供了使用它们的方便方法。
非连续的内存区域不能保证元素以任何特定的顺序存储,也不能保证元素在内存中紧密地存储在一起。非连续缓冲区(如 ReadOnlySequence (与段一起使用时))驻留在内存的单独区域中,这些区域可能分散在堆中,不能被单个指针访问。
例如,IEnumable 是非连续的,因为在开发者逐个枚举每个项之前,无法知道下一个项将在哪里。为了表示段之间的这些间隔,必须使用附加数据来跟踪每个段的开始和结束位置。
不连续的缓冲区: ReadOnly 序列
让作者们假设开发者正在使用一个不连续的缓冲区。例如,数据可能来自网络流、数据库调用或文件流。这些场景中的每一个都可以有多个大小不同的缓冲区。一个 ReadOnlySequence 实例可以包含一个或多个内存段,每个段可以有自己的 Memory 实例。因此,单个 ReadOnlySequence 实例可以更好地管理可用内存,并提供比许多串联内存实例更好的性能。
开发者可以使用 SequenceReader 类上的工厂方法 Create()以及 AsReadOnlySequence()等其他方法创建 ReadOnlySequence 实例。Create() 方法有几个重载,允许开发者传入 byte [] 或 ArraySegment、字节数组序列(IEnumable)或 IReadOnlyCollection /IReadOnlyList/IList / ICollection 字节数组集合(byte [])和 ArraySegment。
开发者现在知道 Span<T> 和 Memory<T> 提供了对连续内存缓冲区(如数组)的支持。系统。缓冲区命名空间包含一个名为 ReadOnlySequense<T> 的结构,该结构支持处理不连续的内存缓冲区。下面的代码片段说明了如何在 C# 中使用 ReadOnlySequence<T> :
int[] array = { 1, 2, 3, 4, 5, 6, 7, 8, 9 };
var readOnlySequence = new ReadOnlySequence<int>(array);
var slicedReadOnlySequence = readOnlySequence.Slice(1, 5);
开发者也可以使用 ReadOnlyMemory<T> ,如下所示:
int[] array = { 1, 2, 3, 4, 5, 6, 7, 8, 9 };
ReadOnlyMemory<int> memory = array;
var readOnlySequence = new ReadOnlySequence<int>(memory);
var slicedReadOnlySequence = readOnlySequence.Slice(1, 5);
实际场景
现在让作者们来谈谈一个现实中的场景,以及 Span<T> 和 Memory<T> 是如何起作用的。请考虑以下字符串数组,其中包含从日志文件检索到的日志数据:
string[] logs = new string[]
{
"a1K3vlCTZE6GAtNYNAi5Vg::05/12/2022 09:10:00 AM::http://localhost:2923/api/customers/getallcustomers",
"mpO58LssO0uf8Ced1WtAvA::05/12/2022 09:15:00 AM::http://localhost:2923/api/products/getallproducts",
"2KW1SfJOMkShcdeO54t1TA::05/12/2022 10:25:00 AM::http://localhost:2923/api/orders/getallorders",
"x5LmCTwMH0isd1wiA8gxIw::05/12/2022 11:05:00 AM::http://localhost:2923/api/orders/getallorders",
"7IftPSBfCESNh4LD9yI6aw::05/12/2022 11:40:00 AM::http://localhost:2923/api/products/getallproducts"
};
请记住,开发者可以拥有数百万条日志记录,因此性能至关重要。这个示例只是从大量日志数据中提取的日志数据。每个行的数据由 HTTP 请求 ID、 HTTP 请求的 DateTime 和端点 URL 组成。现在假设开发者需要从这些数据中提取请求 ID 和端点 URL。
开发者需要一个高性能的解决方案。如果使用 String 类的 Substring 方法,就会创建许多字符串对象,这也会降低应用程序的性能。最好的解决方案是在这里使用 Span<T> 来避免分配。解决这个问题的方法是使用 Span<T> 和 Slice 方法,如下一节所示。
Benchmarking 基准测试
是时候测量一下了。现在让作者们对 Span<T> struct 与 String 类的 Substring 方法的性能进行基准测试。
安装 NuGet 包
目前为止还不错。下一步是安装必要的 NuGet 包。要将所需的包安装到项目中,右键单击解决方案并选择 Manage NuGet Packages for Solution... 。现在在搜索框中搜索名为 BenchmarkDotNet 的软件包并安装它。或者,开发者也可以在NuGet Package Manager 命令提示符下键入以下命令:
PM> Install-Package BenchmarkDotNet
Benchmarking Span
现在让作者们研究一下如何对 Substring 和 Slice 方法的性能进行基准测试。使用清单1中的代码创建一个名为 BenchmarkPerformance 的新类。开发者应该注意在 GlobalSetup 方法中如何设置数据以及 GlobalSetup 属性的用法。
[MemoryDiagnoser]
[Orderer(BenchmarkDotNet.Order.SummaryOrderPolicy.FastestToSlowest)]
[RankColumn]
public class BenchmarkPerformance
{
[Params(100, 200)]
public int N;
string countries = null;
int index, numberOfCharactersToExtract;
[GlobalSetup]
public void GlobalSetup()
{
countries = "India, USA, UK, Australia, Netherlands, Belgium";
index = countries.LastIndexOf(",",StringComparison.Ordinal);
numberOfCharactersToExtract = countries.Length - index;
}
}
现在,编写名为 Substring 和 Span 的两个方法,如清单2所示。前者使用 String 类的 Substring 方法检索最后一个国家名称,而后者使用 Slice 方法提取最后一个国家名称。
[Benchmark]
public void Substring()
{
for(int i = 0; i < N; i++)
{
var data = countries.Substring(index + 1, numberOfCharactersToExtract - 1);
}
}
[Benchmark(Baseline = true)]
public void Span()
{
for(int i=0; i < N; i++)
{
var data = countries.AsSpan().Slice(index + 1, numberOfCharactersToExtract - 1);
}
}

执行基准测试
class Program
{
static void Main()
{
BenchmarkRunner.Run<BenchmarkPerformance>();
}
}
若要执行基准测试,请将项目的编译模式设置为“发布”,并在项目文件所在的同一文件夹中运行以下命令:
dotnet run -c Release
下图显示了基准测试的执行结果。
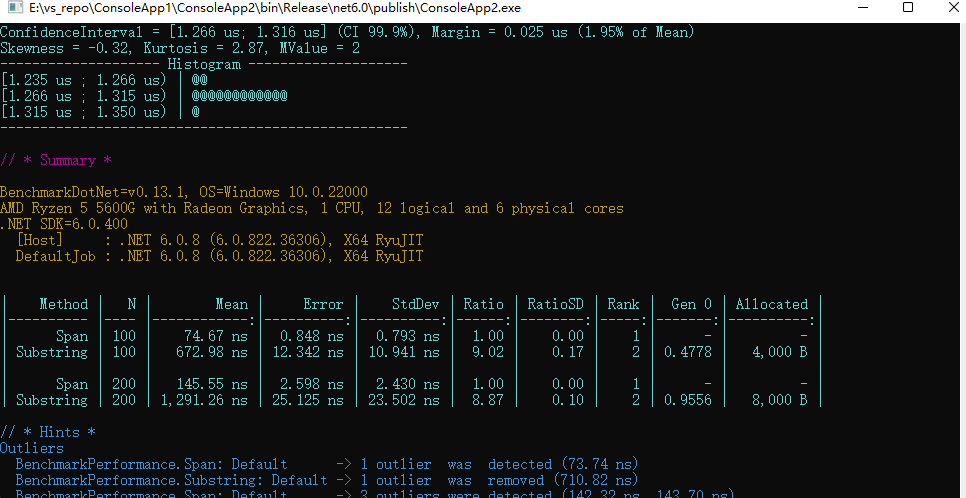
解读基准测试结果
如上一小节的图所示,在使用 Slice 方法提取字符串时,绝对没有分配。对于每个基准测试方法,都会生成一行结果数据。因为有两个基准测试方法,所以有两行基准测试结果数据。基准测试结果显示了平均执行时间、 Gen0集合和分配的内存。从基准测试结果中可以明显看出,Span 比 Substring 方法快7.5倍以上(译者图中的结果是9倍)。
Span 限制
Span<T> 是仅堆栈的,这意味着它不适合在堆上存储对缓冲区的引用,例如在执行异步调用的例程中。它不在托管堆中分配,而是在堆栈中分配,并且它不支持装箱以防止升级到托管堆。不能将 Span<T> 用作泛型类型,但可以将其用作 ref 结构中的字段类型。不能将 Span<T> 赋给动态类型、对象类型或任何其他接口类型的变量。不能在引用类型中使用 Span<T> 作为字段,也不能跨等待和产生边界使用它。此外,由于 Span<T> 不继承 IEnumable,因此不能对其使用 LINQ。
需要注意的是,类中不能有 Span<T> 字段,不能创建 Span<T> 数组,也不能包含 Span<T> 实例。注意, Span<T> 和Memory<T> 都没有实现 IEnumable<T> ,因此,开发者将无法使用 LINQ 与这两者操作。但是,开发者可以利用 SpanLinq 、 NetFabric、Hyperlinq 库来绕过这个限制。
结论
在本文中,作者研究了 Span<T> 和 Memory<T> 的特性和优点,以及如何在应用程序中实现它们。作者还讨论了一个实际场景,其中可以使用 Span 来提高字符串处理性能。请注意,Span<T> 比 Memory<T> 更多才多艺,性能也更好,但它并不能完全取代它。
到此这篇关于在 C# 中使用 Span<T> 和 Memory<T> 编写高性能代码的详细步骤的文章就介绍到这了,更多相关C# Span<T> 和 Memory<T> 编写高性能代码内容请搜索我们以前的文章或继续浏览下面的相关文章希望大家以后多多支持我们!
相关推荐
-

C# 对象映射的高性能方案
1.之前在使用AutoMapper 框架感觉用着比较不够灵活,而且主要通过表达式树Api 实现对象映射 ,写着比较讨厌,当出现复杂类型和嵌套类型时性能直线下降,甚至不如序列化快. 2.针对AutoMapper 处理复杂类型和嵌套类型时性能非常差的情况,自己实现一个简化版对象映射的高性能方案 public class Article { public int Id { get; set; } public string CategoryId { get; set; } public string
-
C#高性能动态获取对象属性值的步骤
动态获取对象的性能值,这个在开发过程中经常会遇到,这里我们探讨一下何如高性能的获取属性值.为了对比测试,我们定义一个类People public class People { public string Name { get; set; } } 然后通过直接代码调用方式来取1千万次看要花多少时间: private static void Directly() { People people = new People { Name = "Wayne" }; Stopwatch stopw
-
C#汉字转换拼音技术详解(高性能)
下面将源代码贴出. 复制代码 代码如下: public static class ChineseToPinYin { private static readonly Dictionary<int, string> CodeCollections = new Dictionary<int, string> { { -20319, "a" }, { -20317, "ai" }, { -20304, "an" }, { -2
-
C#中一个高性能异步socket封装库的实现思路分享
前言 socket是软件之间通讯最常用的一种方式.c#实现socket通讯有很多中方法,其中效率最高就是异步通讯. 异步通讯实际是利用windows完成端口(IOCP)来处理的,关于完成端口实现原理,大家可以参考网上文章. 我这里想强调的是采用完成端口机制的异步通讯是windows下效率最高的通讯方式,没有之一! 异步通讯比同步通讯处理要难很多,代码编写中会遇到许多"坑".如果没有经验,很难完成. 我搜集了大量资料,完成了对异步socket的封装.此库已用稳定高效的运行几个月. 纵观网
-
在 C# 中使用 Span<T> 和 Memory<T> 编写高性能代码的详细步骤
目录 .NET 中支持的内存类型 .NET Core 2.1 中新增的类型 访问连续内存: Span 和 Memory Span 介绍 C# 中的 Span Span 和 Arrays Span 和 ReadOnlySpan Memory 入门 ReadOnlyMemory Span 和 Memory 的优势 连续和非连续内存缓冲区 不连续的缓冲区: ReadOnly 序列 实际场景 Benchmarking 基准测试 安装 NuGet 包 Benchmarking Span 执行基准测试 解读
-
IDEA中项目集成git提交代码的详细步骤
简介:在团队协作开发的过程中,好的代码管理能更加有效的使日常开发的过程中对各个开发人员提高开发速度.下面将详细介绍在IDEA中使用git提交代码的过程: 一:pull代码 在提交代码之前,我们必须先对代码就行更新操作,这一步非常重要,如果不进行更新代码操作,当有其他小伙伴有更改的内容已经提交到代码仓库但是我们本地缺没有更新的话,就会造成我们提交的代码跟别人已提交过的代码产生冲突(使用git解决冲突会比较麻烦,在这里就不进行讲解了,后期会单独更新).即使我们解决了冲突,也可能会冲掉别人的代码,造成
-
C#/VB.NET 在Word中添加条码、二维码的示例代码
本文介绍如何通过C# 和VB.NET代码实现在Word文档中添加条码和二维码.代码中将分为在Word正文段落中.页眉页脚中等情况来添加. 使用工具: Free Spire.Office for .NET (免费版) 工具简介: 这是Spire所有.NET平台下免费产品的集合包,包含Spire.Barcode.dll.Spire.DataExport.dll.Spire.Pdf.dll.Spire.Doc.dll.Spire.DocViewer.Forms.dll .Spire.PdfViewer
-
python 实现数据库中数据添加、查询与更新的示例代码
一.前言 最近做web网站的测试,遇到很多需要批量造数据的功能:比如某个页面展示数据条数需要达到10000条进行测试,此时手动构造数据肯定是不可能的,此时只能通过python脚本进行自动构造数据:本次构造数据主要涉及到在某个表里面批量添加数据.在关联的几个表中同步批量添加数据.批量查询某个表中符合条件的数据.批量更新某个表中符合条件的数据等. 二.数据添加 即批量添加数据到某个表中. insert_data.py import pymysql import random import time
-
详解C++中的内存同步模式(memory order)
内存模型中的同步模式(memory model synchronization modes) 原子变量同步是内存模型中最让人感到困惑的地方.原子(atomic)变量的主要作用就是同步多线程间的共享内存访问,一般来讲,某个线程会创建一些数据,然后给原子变量设置标志数值(译注:此处的原子变量类似于一个flag);其他线程则读取这个原子变量,当发现其数值变为了标志数值之后,之前线程中的共享数据就应该已经创建完成并且可以在当前线程中进行读取了.不同的内存同步模式标识了线程间数据共享机制的"强弱"
-
Js代码中的span拼接问题解决
这篇文章主要介绍了Js代码中的span拼接问题解决,文中通过示例代码介绍的非常详细,对大家的学习或者工作具有一定的参考学习价值,需要的朋友可以参考下 今天遇到一个小需求,用bootstrap的table只有两个字段,占用太宽,页面不美观,组长要求用拼接,一行几列的形式展现出来. 我在form表单中拼接了span,遇到以下问题: 1.点击查询,以前生成的span不消失,新的拼接在后面 2.span中的复选框,值的取出,复选框的状态更换 对于职场老手来说,这没什么,但是js代码没接触多久的我来说,只
-
JavaScript中实现无缝滚动、分享到侧边栏实例代码
废话不多说,直接给大家贴代码了,代码解决一起问题! 下面一段代码给大家介绍js无缝滚动实例代码: 代码如下所示: <!DOCTYPE html PUBLIC "-//W3C//DTD XHTML 1.0 Transitional//EN" "http://www.w3.org/TR/xhtml1/DTD/xhtml1-transitional.dtd"> <html xmlns="http://www.w3.org/1999/xhtml&
-
vue中实现图片和文件上传的示例代码
html页面 <input type="file" value="" id="file" @change='onUpload'>//注意不能带括号 js代码 methods: { //上传图片 onUpload(e){ var formData = new FormData(); f ormData.append('file', e.target.files[0]); formData.append('type', 'test');
-
vmware12中安装 RedHat RHEL7.2系统的详细步骤(图文)
本文介绍了vmware12中安装 RedHat RHEL7.2系统的详细步骤(图文),分享给大家,具体如下: 一.开始安装 1)新建虚拟机 RHEL7.2 2)成功引导系统--开机出现此画面 Install Red Hat EnterpriseLinux 7.2 安装RHLE7.2 操作系统 Test this edia & install RedHat Enterprise Linux 7.2 测试安装文件并安装RHLE7.2 操作系统 Troubleshooting 修复故障 3)选择第一项
-
iOS 中根据屏幕宽度自适应分布按钮的实例代码
下载demo链接:https://github.com/MinLee6/buttonShow.git 屏幕摆放的控件有两种方式,一种根据具体内容变化,一种根据屏幕宽度变化. 下面我分别将两个方式,用代码的方式呈现: 1:根据具体内容变化 // // StyleOneViewController.m // buttonShow // // Created by limin on 15/06/15. // Copyright © 2015年 信诺汇通信息科技(北京)有限公司. All rights