Python Pandas的concat合并
目录
- 使用场景
- concat语法
- append语法
- 案例演示
使用场景
批量合并相同格式的Exce,给DataFrame添加行,给DataFrame添加列
使用说明:
- 1.使用某种合并方式(inner/outer)
- 2.沿着某个轴向(axis=0/1)
- 3.把多个Pandas对象(DataFrame/Series)合并成一个
concat语法
pandas.concat(objs,axis=0,join=‘outer’,ignore_index = False)
- objs:一个列表,内容可以是DaataFrame或者Series,可以混合
- axis:默认是0,代表按行合并,如果等于则按列合并
- join: 合并的时候索引的对其方式,默认是outer join,也可以是inner join
- ignore_index: 是否忽略掉原来的数据索引
append语法
DataFrame.append(other,ignore_index=False)
append只有按行合并,没有按列合并,相当于concat按行的简写形式
- other: 单个dataframe,series,dict,或者列表
- ignore_index:是否忽略掉原来的数据库索引
案例演示

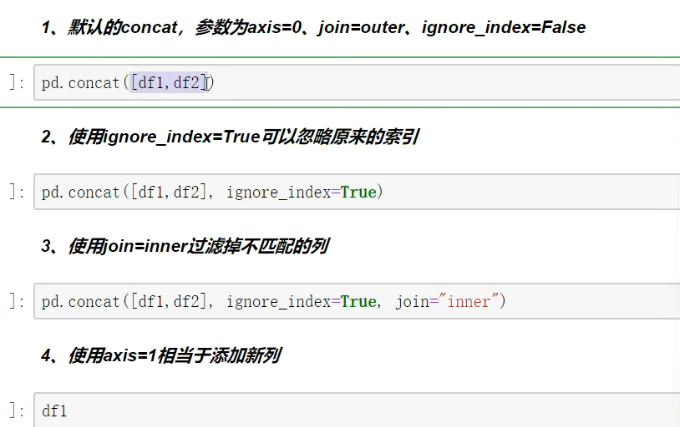



到此这篇关于Python Pandas的concat合并的文章就介绍到这了,更多相关Pandas concat合并内容请搜索我们以前的文章或继续浏览下面的相关文章希望大家以后多多支持我们!
相关推荐
-
python的concat等多种用法详解
本文为大家分享了python的concat等多种用法,供大家参考,具体内容如下 1.numpy中的concatenate()函数: >>> a = np.array([[1, 2], [3, 4]]) >>> b = np.array([[5, 6]]) >>> np.concatenate((a, b), axis=0) array([[1, 2], [3, 4], [5, 6]]) >>> np.concatenate((a, b
-

python中DataFrame数据合并merge()和concat()方法详解
目录 merge() 1.常规合并 ①方法1 ②方法2 重要参数 合并方式 left right outer inner 2.多对一合并 3.多对多合并 concat() 1.相同字段的表首位相连 2.横向表合并(行对齐) 3.交叉合并 总结 merge() 1.常规合并 ①方法1 指定一个参照列,以该列为准,合并其他列. import pandas as pd df1 = pd.DataFrame({'id': ['001', '002', '003'], 'num1': [120, 101,
-
解决Python 异常TypeError: cannot concatenate 'str' and 'int' objects
TypeError: cannot concatenate 'str' and 'int' objects print str + int 的时候就会这样了 python + 作为连接符的时候,不会自动给你把int转换成str 补充知识:TypeError: cannot concatenate 'str' and 'list' objects和Python读取和保存图片 运行程序时报错,然后我将list转化为str就好了. 利用''.join(list) 如果需要用逗号隔开,如1,2,3,4则
-
python pandas处理excel表格数据的常用方法总结
目录 前言 1.读取xlsx表格:pd.read_excel() 2.获取表格的数据大小:shape 3.索引数据的方法:[ ] / loc[] / iloc[] 4.判断数据为空:np.isnan() / pd.isnull() 5.查找符合条件的数据 6.修改元素值:replace() 7.增加数据:[ ] 8.删除数据:del() / drop() 9.保存到excel文件:to_excel() 总结 前言 最近助教改作业导出的成绩表格跟老师给的名单顺序不一致,脑壳一亮就用pandas写了
-
python numpy中array与pandas的DataFrame转换方式
目录 numpy array与pandas的DataFrame转换 1.numpy的array转换为pandas的DataFrame 2.pandas的DataFrame转换为numpy的array Pandas DataFrame转换成Numpy中array的三种方法 1.使用DataFrame中的values方法 2.使用DataFrame中的as_matrix()方法 3.使用Numpy中的array方法 numpy array与pandas的DataFrame转换 1.numpy的arr
-
Python3 pandas.concat的用法说明
前面给大家分享了pandas.merge用法详解,这节分享pandas数据合并处理的姊妹篇,pandas.concat用法详解,参考利用Python进行数据分析与pandas官网进行整理. pandas.merge参数列表如下图,其中只有objs是必须得参数,另外常用参数包括objs.axis.join.keys.ignore_index. 1.pd.concat([df1,df2,df3]), 默认axis=0,在0轴上合并. 2.pd.concat([df1,df4],axis=1)–在1轴
-
Python pandas DataFrame基础运算及空值填充详解
目录 前言 数据对齐 fill_value 空值api dropna fillna 总结 前言 今天我们一起来聊聊DataFrame中的索引. 上一篇文章当中我们介绍了DataFrame数据结构当中一些常用的索引的使用方法,比如iloc.loc以及逻辑索引等等.今天的文章我们来看看DataFrame的一些基本运算. 数据对齐 我们可以计算两个DataFrame的加和,pandas会自动将这两个DataFrame进行数据对齐,如果对不上的数据会被置为Nan(not a number). 首先我们来
-
Python Pandas的concat合并
目录 使用场景 concat语法 append语法 案例演示 使用场景 批量合并相同格式的Exce,给DataFrame添加行,给DataFrame添加列 使用说明: 1.使用某种合并方式(inner/outer) 2.沿着某个轴向(axis=0/1) 3.把多个Pandas对象(DataFrame/Series)合并成一个 concat语法 pandas.concat(objs,axis=0,join=‘outer’,ignore_index = False) objs:一个列表,内容可以是D
-
python merge、concat合并数据集的实例讲解
数据规整化:合并.清理.过滤 pandas和python标准库提供了一整套高级.灵活的.高效的核心函数和算法将数据规整化为你想要的形式! 本篇博客主要介绍: 合并数据集:.merge()..concat()等方法,类似于SQL或其他关系型数据库的连接操作. 合并数据集 1) merge 函数参数 参数 说明 left 参与合并的左侧DataFrame right 参与合并的右侧DataFrame how 连接方式:'inner'(默认):还有,'outer'.'left'.'right' on
-
Python Pandas实现DataFrame合并的图文教程
目录 一.merge(合并)的语法: 二.以关键列来合并两个dataframe 三.理解merge时数量的对齐关系 1.one-to-one 一对一关系的merge 2.one-to-many 一对多关系的merge 3.many-to-many 多对多关系的merge 四.理解left join.right join.inner join.outer join的区别 1.inner join,默认 2.left join 3. right join 4. outer join 五.如果出现非K
-
利用Python pandas对Excel进行合并的方法示例
前言 在网上找了很多Python处理Excel的方法和代码,都不是很尽人意,所以自己综合网上各位大佬的方法,自己进行了优化,具体的代码如下. 博主也是新手一枚,代码肯定有很多需要优化的地方,欢迎各位大佬提出建议~ 代码我自己已经用了一段时间,可以直接拿去用 主要功能 按行合并 ,即保留固定的表头(如前几行),实现多个Excel相同格式相同名字的表单按纵轴合并: 按列合并. 即保留固定的首列,实现多个Excel相同格式相同名字的表单按横轴合并: 表单集成 ,实现不同Excel中相同sheet的集成
-
python pandas dataframe 按列或者按行合并的方法
concat 与其说是连接,更准确的说是拼接.就是把两个表直接合在一起.于是有一个突出的问题,是横向拼接还是纵向拼接,所以concat 函数的关键参数是axis . 函数的具体参数是: concat(objs,axis=0,join='outer',join_axes=None,ignore_index=False,keys=None,levels=None,names=None,verigy_integrity=False) objs 是需要拼接的对象集合,一般为列表或者字典 axis=0 是
-
利用python Pandas实现批量拆分Excel与合并Excel
一.实例演示 1.将一个大Excel等份拆成多个Excel 2.将多个小Excel合并成一个大Excel并标记来源 work_dir="./course_datas/c15_excel_split_merge" splits_dir=f"{work_dir}/splits" import os if not os.path.exists(splits_dir): os.mkdir(splits_dir) 二.读取源Excel到Pandas import pandas
-
python pandas数据处理教程之合并与拼接
目录 前言 一.join 1.leftjoin 2.rightjoin 3.innerjoin 4.outjoin 二.merge 三.concat 1.纵向合并 2.横向合并 四.append 1.同结构数据追加 2.不同结构数据追加 3.追加合并多个数据集 五.combine_first 六.update 总结 前言 在许多应用中,数据可能来自不同的渠道,在数据处理的过程中常常需要将这些数据集进行组合合并拼接,形成更加丰富的数据集.pandas提供了多种方法完全可以满足数据处理的常用需求.具
-
Python Pandas学习之数据离散化与合并详解
目录 1数据离散化 1.1为什么要离散化 1.2什么是数据的离散化 1.3举例股票的涨跌幅离散化 2数据合并 2.1pd.concat实现数据合并 2.2pd.merge 1 数据离散化 1.1 为什么要离散化 连续属性离散化的目的是为了简化数据结构,数据离散化技术可以用来减少给定连续属性值的个数.离散化方法经常作为数据挖掘的工具. 1.2 什么是数据的离散化 连续属性的离散化就是在连续属性的值域上,将值域划分为若干个离散的区间,最后用不同的符号或整数 值代表落在每个子区间中的属性值. 离散化有
-
Python Pandas中合并数据的5个函数使用详解
目录 join 索引一致 索引不一致 merge concat 纵向拼接 横向拼接 append combine 前几天在一个群里面,看到一位朋友,说到自己的阿里面试,被问了一些关于pandas的使用.其中一个问题是:pandas中合并数据的5中方法. 今天借着这个机会,就为大家盘点一下pandas中合并数据的5个函数.但是对于每个函数,我这里不打算详细说明,具体用法大家可以参考pandas官当文档. join主要用于基于索引的横向合并拼接: merge主要用于基于指定列的横向合并拼接: con