Flink 侧流输出源码示例解析
目录
- Flink 侧流输出源码解析
- 源码解析
- TimestampedCollector#collect
- CountingOutput#collect
- BroadcastingOutputCollector#collect
- RecordWriterOutput#collect
- ProcessOperator#ContextImpl#output
- CountingOutput#collect
- BroadcastingOutputCollector#collect
- RecordWriterOutput#collect
- OutputTag#isResponsibleFor
- getSideOutput 源码
- 总结
Flink 侧流输出源码解析
Flink 的 side output 为我们提供了侧流(分流)输出的功能,根据条件可以把一条流分为多个不同的流,之后做不同的处理逻辑,下面就来看下侧流输出相关的源码。
先来看下面的一个 Demo,一个流被分成了 3 个流,一个主流,两个侧流输出。
SingleOutputStreamOperator<JasonLeePOJO> process =
kafka_source1.process(
new ProcessFunction<JasonLeePOJO, JasonLeePOJO>() {
@Override
public void processElement(
JasonLeePOJO value,
ProcessFunction<JasonLeePOJO, JasonLeePOJO>.Context ctx,
Collector<JasonLeePOJO> out)
throws Exception {
// 这个是主流输出
if (value.getName().equals("flink")) {
out.collect(value);
// 下面两个是测流输出
} else if (value.getName().equals("spark")) {
ctx.output(test, value);
// 测流
} else if (value.getName().equals("hadoop")) {
ctx.output(test1, value);
}
}
});
为了更加清楚的查看每一个算子,我禁用了 operator chain,任务的 DAG 图如下所示:
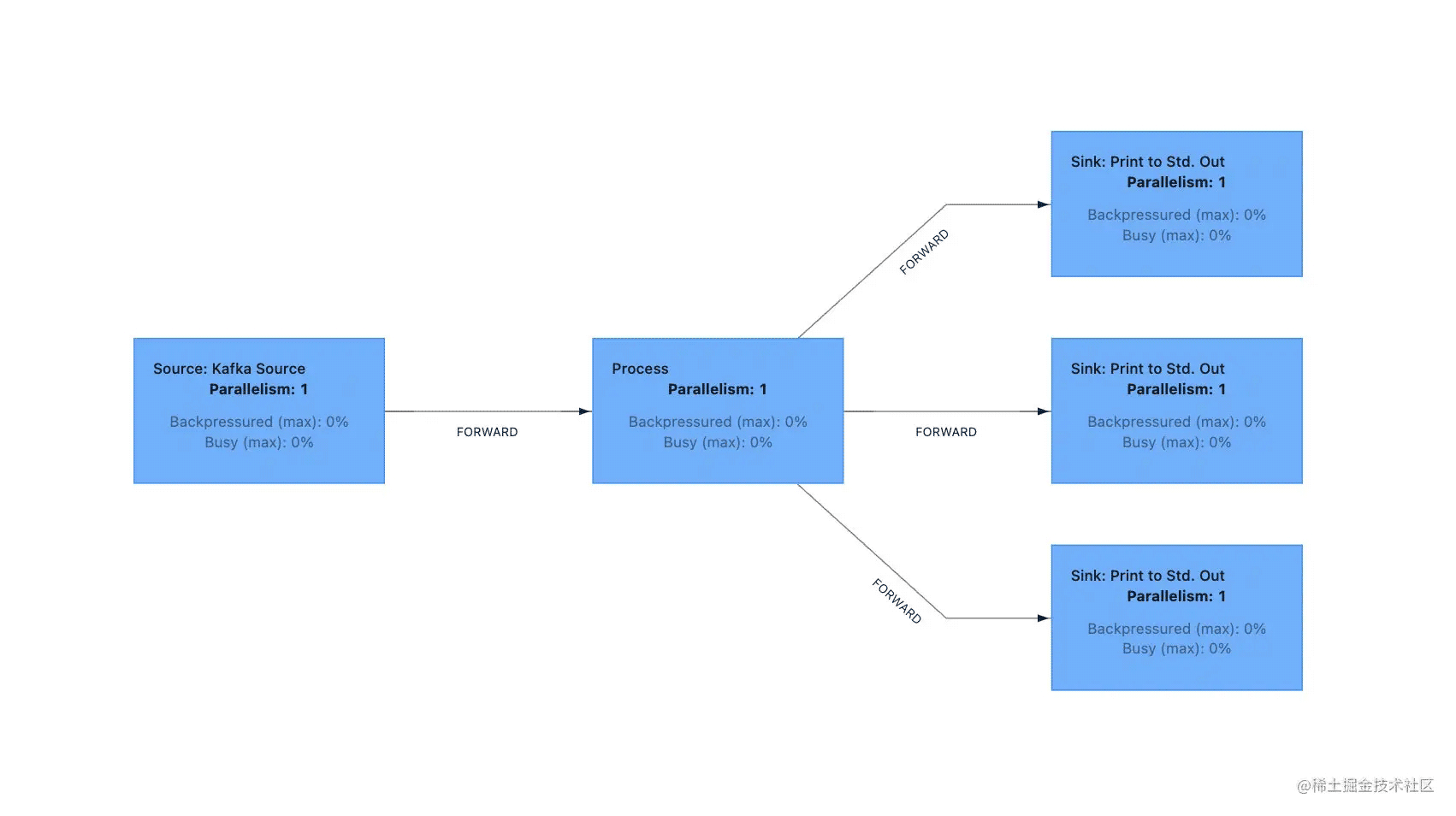
这样就比较清晰了,很明显从 process 算子开始,1 个数据流分为了 3 个数据流,当然,在默认情况下没有禁止
operator chain 所有的算子都是 chain 在一起的。
源码解析
我们先来看第一个主流输出也就是 out.collect(value) 的源码,这里的 out 实际上是 TimestampedCollector 对象。
TimestampedCollector#collect
@Override
public void collect(T record) {
output.collect(reuse.replace(record));
}
在 collect 方法中持有一个 output 对象,用来输出数据,在这里实际上是一个 CountingOutput 它是一个包装了 Output 的对象,主要用于更新发送数据的 metric,并输出数据。
CountingOutput#collect
@Override
public void collect(StreamRecord<OUT> record) {
numRecordsOut.inc();
output.collect(record);
}
在 CountingOutput 中也持有一个 output 对象,但是这里的 output 是 BroadcastingOutputCollector 对象,从名字就可以看出它是往下游广播数据的,这里就有一个疑问?把数据广播到下游,那岂不是下游的每个数据流都有这条数据吗?这样的话是怎么实现分流的呢?带着这个疑问,我们来看 BroadcastingOutputCollector 的 collect 方法是怎么实现的。
BroadcastingOutputCollector#collect
@Override
public void collect(StreamRecord<T> record) {
// 这里的 outputs 数组有三个 output 分别对应上面的三个输出流
for (Output<StreamRecord<T>> output : outputs) {
output.collect(record);
}
}
在 BroadcastingOutputCollector 对象里也持有一个 output 对象,其实他们都实现了 Output 接口,用来往下游发送数据,这里的 outputs 是一个 Output 数组,代表了下游的所有 Output,因为上面有三个输出流,所以数组里面就包含了 3 个 Output 对象。
循环的调用 output 的 collect 方法往下游发送数据,因为我打断了 operator chain,所以 process 算子和下游的 Print 算子不在同一个 operatorChain 内,那么上下游算子之间数据传输用的就是 RecordWriterOutput,否则用的是 CopyingChainingOutput 或者 ChainingOutput,具体使用的是哪个 Output 这里就不多介绍了,后面有时间的话会单独介绍。
RecordWriterOutput#collect
@Override
public void collect(StreamRecord<OUT> record) {
// 主流是没有 outputTag 的,只有测流有 outputTag
if (this.outputTag != null) {
// we are not responsible for emitting to the main output.
return;
}
pushToRecordWriter(record);
}
接着来看 RecordWriterOutput 的 collect 方法,在 collect 方法里面会先判断 outputTag 是否为空,如果不为空不做任何处理,直接返回,否则就把数据推送到下游算子,只有侧流输出才需要定义 outputTag,主流(正常流)是没有 outputTag 的,所以这里会走 pushToRecordWriter 方法把数据写入到下游,也就是说虽然会以广播的形式把数据广播到所有下游,但其实另外两个侧流是直接返回的,只有主流才会把数据推送到下游,这也就解释了上面的疑问。
然后再来看第二个侧流输出 ctx.output(test, value) 的源码,这里的 ctx 实际上是 ProcessOperator#ContextImpl 对象。
ProcessOperator#ContextImpl#output
@Override
public <X> void output(OutputTag<X> outputTag, X value) {
if (outputTag == null) {
throw new IllegalArgumentException("OutputTag must not be null.");
}
output.collect(outputTag, new StreamRecord<>(value, element.getTimestamp()));
}
如果 outputTag 是空,直接抛出异常,因为这个是侧流,所以必须要定义 OutputTag。这里的 output 实际上是父类 AbstractStreamOperator 所持有的变量,如果 outputTag 不为空,就调用 output 的 collect 方法把数据发送到下游,这里的 output 和上面的一样是 CountingOutput 但是 collect 方法是另外一个重载的方法。
CountingOutput#collect
@Override
public <X> void collect(OutputTag<X> outputTag, StreamRecord<X> record) {
numRecordsOut.inc();
output.collect(outputTag, record);
}
可以发现,这个 collect 方法比上面那个多了一个 OutputTag 参数,也就是使用侧流输出的时候定义的 OutputTag 对象,然后调用 output 的 collect 方法发送数据,这个也和上面的一样,同样是 BroadcastingOutputCollector 对象的另外一个重载方法,多了一个 OutputTag 参数。
BroadcastingOutputCollector#collect
@Override
public <X> void collect(OutputTag<X> outputTag, StreamRecord<X> record) {
for (Output<StreamRecord<T>> output : outputs) {
output.collect(outputTag, record);
}
}
这里的逻辑和上面是一样的,同样的循环调用 collect 方法发送数据。
RecordWriterOutput#collect
@Override
public <X> void collect(OutputTag<X> outputTag, StreamRecord<X> record) {
// 先要判断两个 OutputTag 是否一样
if (OutputTag.isResponsibleFor(this.outputTag, outputTag)) {
pushToRecordWriter(record);
}
}
在这个 collect 方法中会先判断传入的 OutputTag 对象和成员变量 this.outputTag 是不是相等,如果是的话,就发送数据,否则不做任何处理,所以这里每次只会选择一个下游侧流输出数据,这样就实现了所谓的分流。
OutputTag#isResponsibleFor
public static boolean isResponsibleFor(
@Nullable OutputTag<?> owner, @Nonnull OutputTag<?> other) {
return other.equals(owner);
}
可以看到在 isResponsibleFor 方法内是直接调用 OutputTag 的 equals 方法判断两个对象是否相等的。
第三个侧流 test1 ctx.output(test1, value) 和第二个侧流 test 是完全一样的情况,这里就不在看代码了。
上面是完成了分流操作,那怎么获取到分流后结果呢(数据流)?我们可以通过 getSideOutput 方法获取。
DataStream<JasonLeePOJO> sideOutput = process.getSideOutput(test); DataStream<JasonLeePOJO> sideOutput1 = process.getSideOutput(test1);
getSideOutput 源码
public <X> DataStream<X> getSideOutput(OutputTag<X> sideOutputTag) {
sideOutputTag = clean(requireNonNull(sideOutputTag));
// make a defensive copy
sideOutputTag = new OutputTag<X>(sideOutputTag.getId(), sideOutputTag.getTypeInfo());
TypeInformation<?> type = requestedSideOutputs.get(sideOutputTag);
if (type != null && !type.equals(sideOutputTag.getTypeInfo())) {
throw new UnsupportedOperationException(
"A side output with a matching id was "
+ "already requested with a different type. This is not allowed, side output "
+ "ids need to be unique.");
}
requestedSideOutputs.put(sideOutputTag, sideOutputTag.getTypeInfo());
SideOutputTransformation<X> sideOutputTransformation =
new SideOutputTransformation<>(this.getTransformation(), sideOutputTag);
return new DataStream<>(this.getExecutionEnvironment(), sideOutputTransformation);
}
getSideOutput 方法里先是构建了一个 SideOutputTransformation 对象,然后又构建了 DataStream 对象,这样我们就可以基于分流后的 DataStream 做不同的处理逻辑了,从而实现了把一个 DataStream 分流成多个 DataStream 功能。
总结
通过对侧流输出的源码进行解析,在分流的时候,数据是通过广播的方式发送到下游算子的,对于主流的数据来说,只有 OutputTag 为空的才会处理,侧流因为 OutputTag 不为空,所以直接返回,不做任何处理,那对于侧流的数据来说,是通过判断两个 OutputTag 是否相等,所以每次只会把数据发送到下游对应的那一个侧流上去,这样即可实现分流逻辑。
以上就是Flink 侧流输出源码示例解析的详细内容,更多关于Flink 侧流输出的资料请关注我们其它相关文章!
相关推荐
-

解析Flink内核原理与实现核心抽象
目录 一.环境对象 1.1 执行环境 StreamExecutionEnvironment LocalStreamEnvironment RemoteStreamEnvironment StreamContextEnvironment StreamPlanEnvironment ScalaShellStreamEnvironment 1.2 运行时环境 RuntimeEnvironment SavepointEnvironment 1.3 运行时上下文 StreamingRuntimeConte
-
浅谈Flink容错机制之作业执行和守护进程
一.作业执行容错 Flink 的错误恢复机制分为多个级别,即 Execution 级别的 Failover 策略和 ExecutionGraph 级别的 Job Restart 策略.当出现错误时,Flink 会先尝试触发范围小的错误恢复机制,如果仍处理不了才会升级为更大范围的错误恢复机制,具体可以看下面的序列图. 当 Task 发生错误,TaskManager 会通过 RPC 通知 JobManager,后者将对应 Execution 的状态转为 failed 并触发 Failover 策略.
-
Flink流处理引擎零基础速通之数据的抽取篇
目录 一.CDC 二.常见CDC的比较 三.Flink CDC 四.Flink CDC支持的数据库 五.阿里实现的FlinkCDC使用示例 依赖引入 基于table 基于sql 总结 一.CDC CDC (Change Data Capture) ,在广义的概念上,只要能捕获数据变更的技术,都可以称为 CDC .但通常我们说的CDC 技术主要面向数据库(包括常见的mysql,Oracle, MongoDB等)的变更,是一种用于捕获数据库中数据变更的技术. 二.常见CDC的比较 常见的主要包括Fl
-
Flink入门级应用域名处理示例
目录 概述 算子 FlatMap KeyBy Reduce 连接socket测试 连接kafka 正式 测试 打包上传服务器 概述 最近做了一个小任务,要使用Flink处理域名数据,在4GB的域名文档中求出每个域名的顶级域名,最后输出每个顶级域名下的前10个子级域名.一个比较简单的入门级Flink应用,代码很容易写,主要用到的算子有FlatMap.KeyBy.Reduce.但是由于Maven打包问题,总是提示找不到入口类,卡了好久,最后也是成功解决了. 主体代码如下: public class
-
Flink支持哪些数据类型?
一.支持的数据类型 Flink 对可以在 DataSet 或 DataStream 中的元素类型进行了一些限制.这样做的原因是系统会分析类型以确定有效的执行策略. 1.Java Tuple 和 Scala Case类: 2.Java POJO: 3.基本类型: 4.通用类: 5.值: 6.Hadoop Writables; 7.特殊类型 二.Flink之Tuple类型 Tuple类型 Tuple 是flink 一个很特殊的类型 (元组类型),是一个抽象类,共26个Tuple子类继承Tuple
-
Flink实践Savepoint使用示例详解
目录 一.背景 Snapshot 状态快照 分布式快照 Checkpoint & Savepoint 二.Flink on yarn 如何使用 savepoint 附录:一致性语义 确保精确一次(exactly once) 端到端精确一次 一.背景 什么是 savepoint,为什么要使用 savepoint ? 保障 flink 作业在 配置迭代.flink 版本升级.蓝绿部署中的数据一致性,提高容错.降低恢复时间: 在此之前引入几个概念: Snapshot 状态快照 Flink 通过状态快照
-
Flink 侧流输出源码示例解析
目录 Flink 侧流输出源码解析 源码解析 TimestampedCollector#collect CountingOutput#collect BroadcastingOutputCollector#collect RecordWriterOutput#collect ProcessOperator#ContextImpl#output CountingOutput#collect BroadcastingOutputCollector#collect RecordWriterOutput
-
JS前端操作 Cookie源码示例解析
目录 引言 源码分析 使用 源码 分析 set get remove withAttributes & withConverter 总结 引言 前端操作Cookie的场景其实并不多见,Cookie也因为各种问题被逐渐淘汰,但是我们不用Cookie也可以学习一下它的思想,或者通过这次的源码来学习其他的一些知识. 今天带来的是:js-cookie 源码分析 使用 根据README,我们可以看到js-cookie的使用方式: // 设置 Cookies.set('name', 'value'); //
-
MyBatis SqlSource源码示例解析
目录 正文 SqlNode SqlNode接口定义 BoundSql SqlSource SqlSource解析时机 SqlSource调用时机 总结 正文 MyBatis版本:3.5.12. 本篇讲从mybatis的角度分析SqlSource.在xml中sql可能是带?的预处理语句,也可能是带$或者动态标签的动态语句,也可能是这两者的混合语句. SqlSource设计的目标就是封装xml的crud节点,使得mybatis运行过程中可以直接通过SqlSource获取xml节点中解析后的SQL.
-
OpenMP task construct 实现原理及源码示例解析
目录 前言 从编译器角度看 task construct Task Construct 源码分析 总结 前言 在本篇文章当中主要给大家介绍在 OpenMP 当中 task 的实现原理,以及他调用的相关的库函数的具体实现. 在本篇文章当中最重要的就是理解整个 OpenMP 的运行机制. 从编译器角度看 task construct 在本小节当中主要给大家分析一下编译器将 openmp 的 task construct 编译成什么样子,下面是一个 OpenMP 的 task 程序例子: #inclu
-
Flutter加载图片流程之ImageProvider源码示例解析
目录 加载网络图片 ImageProvider resolve obtainKey resolveStreamForKey loadBuffer load(被废弃) evict 总结 困惑解答 加载网络图片 Image.network()是Flutter提供的一种从网络上加载图片的方法,它可以从指定的URL加载图片,并在加载完成后将其显示在应用程序中.本节内容,我们从源码出发,探讨下图片的加载流程. ImageProvider ImageProvider是Flutter中一个抽象类,它定义了一种
-
Python 装饰器常用的创建方式及源码示例解析
目录 装饰器简介 基础通用装饰器 源码示例 执行结果 带参数装饰器 源码示例 源码结果 源码解析 多装饰器执行顺序 源码示例 执行结果 解析 类装饰器 源码示例 执行结果 解析 装饰器简介 装饰器(decorator)是一种高级Python语法.可以对一个函数.方法或者类进行加工.在Python中,我们有多种方法对函数和类进行加工,相对于其它方式,装饰器语法简单,代码可读性高.因此,装饰器在Python项目中有广泛的应用.修饰器经常被用于有切面需求的场景,较为经典的有插入日志.性能测试.事务处理
-
React Refs 的使用forwardRef 源码示例解析
目录 三种使用方式 1. String Refs 2. 回调 Refs 3. createRef 两种使用目的 Refs 转发 createRef 源码 forwardRef 源码 三种使用方式 React 提供了 Refs,帮助我们访问 DOM 节点或在 render 方法中创建的 React 元素. React 提供了三种使用 Ref 的方式: 1. String Refs class App extends React.Component { constructor(props) { su
-
Flutter加载图片流程之ImageCache源码示例解析
目录 ImageCache _pendingImages._cache._liveImages maximumSize.currentSize clear evict _touch _checkCacheSize _trackLiveImage putIfAbsent clearLiveImages 答疑解惑 ImageCache const int _kDefaultSize = 1000; const int _kDefaultSizeBytes = 100 << 20; // 100 M
-
Flink JobGraph生成源码解析
目录 引言 概念 JobGraph生成 生成hash值 生成chain 总结 引言 在DataStream基础中,由于其中的内容较多,只是介绍了JobGraph的结果,而没有涉及到StreamGraph到JobGraph的转换过程.本篇我们来介绍下JobGraph的生成的详情,重点是Operator可以串联成Chain的条件 概念 首先我们来回顾下JobGraph中的相关概念 JobVertex:job的顶点,即对应的计算逻辑(这里用的是Vertex, 而前面用的是Node,有点差异),通过in
-
oracle数据与文本导入导出源码示例
oracle提供了sqlldr的工具,有时需要讲数据导入到文本,oracle的spool可以轻松实现. 方便的实现oracle导出数据到txt.txt导入数据到oracle. 一.导出数据到txt 用all_objects表做测试 SQL> desc all_objects; Name Null? Type ----------------------------------------- -------- ---------------------------- OWNER NOT NULL