Nodejs全栈框架StrongLoop推荐

StrongLoop是一个基于Nodejs的强大框架,几乎包含了移动开发全栈所需要的所有功能。2013年成立,很少的员工,一个技术驱动,执行力强大的团队。也是在13年我开始接触StrongLoop,当时是为了做nodejs方面的技术选型,看了许多框架,LoopBack是我觉得最酷的一个。我还记得当时是觉得LoopBack的文档太差(主要是跟在线的版本不一样),不知道能活多久所以才放弃了它。时隔一年回来看到这个绿油油的框架,这一年可真是突飞猛进呢。
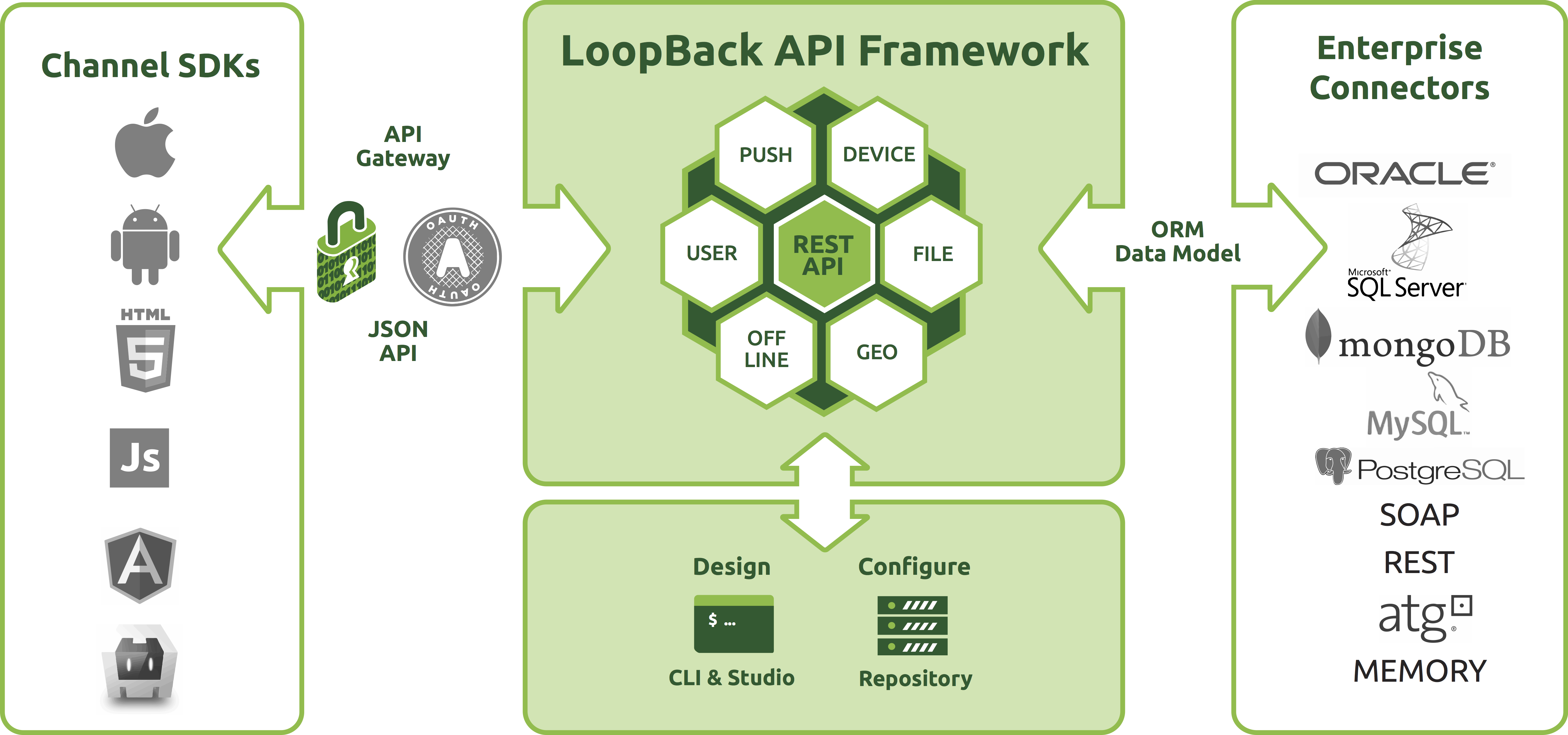
全栈框架StrongLoop
StrongLoop基本提供了制作一个移动产品所有的框架和工具,从标准的Backend server,Devops,应用监控,。要想介绍完全StrongLoop的所有产品得写一个长篇连载了,这里只简单的浏览一遍。
LoopBack
一个功能很强大的WebServer框架,隐约看到Spring的影子...
SDK
这是当时我觉得StrongLoop最好用的一点:根据后端Model自动生成对应的前端SDK。RESTful API
MEAN stack推动了所有新框架默认支持RESTful API,比如Nodejs里的Node-restify,Sailjs之类的天生就是为了serve API的。StrongLoop还提供了一个用来设计API的工具(beta状态),当然跟RAML比还是差不少的。Data model
很容易创建数据模型,自动产生对应的RESTful API。Connectors
当然可以对接各种数据库。StrongLoop Controller
Debug, Package Management, Build, Deploy, Cluster, Log等等一堆Devops工具。Application Monitor
一堆监控服务器的模块。mBaaS
使用StrongLoop,你也可以创建自己的LeanCloud啦,包括Push,地理位置计算(Geopoint),Social Login,User management,各种Replication,Offline sync(离线同步是个好东西),对接各种Stroage云(AWS,Rackspace之类内置了的)。当然,其实这些都是LoopBack里提供的功能,意思是用StrongLoop得永生。开始
安装StrongLoop sudo npm install -g strongloop
创建一个应用 slc loopback(找个空白的目录哦) 它只会问你项目叫啥。
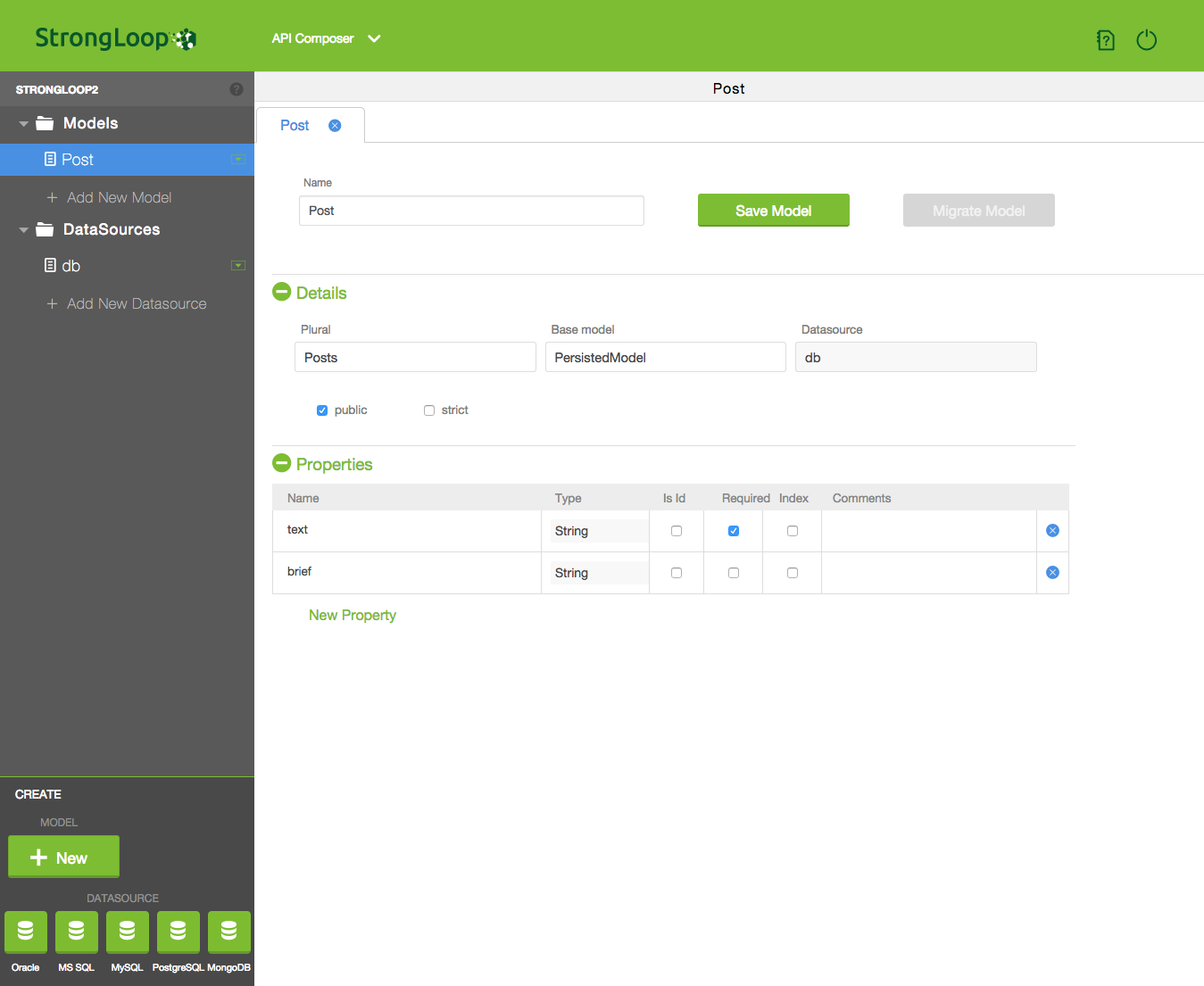
创建一个Model slc loopback:model (是不是想起了Yo generator~),然后它就会问一堆乱七八糟的问题了。
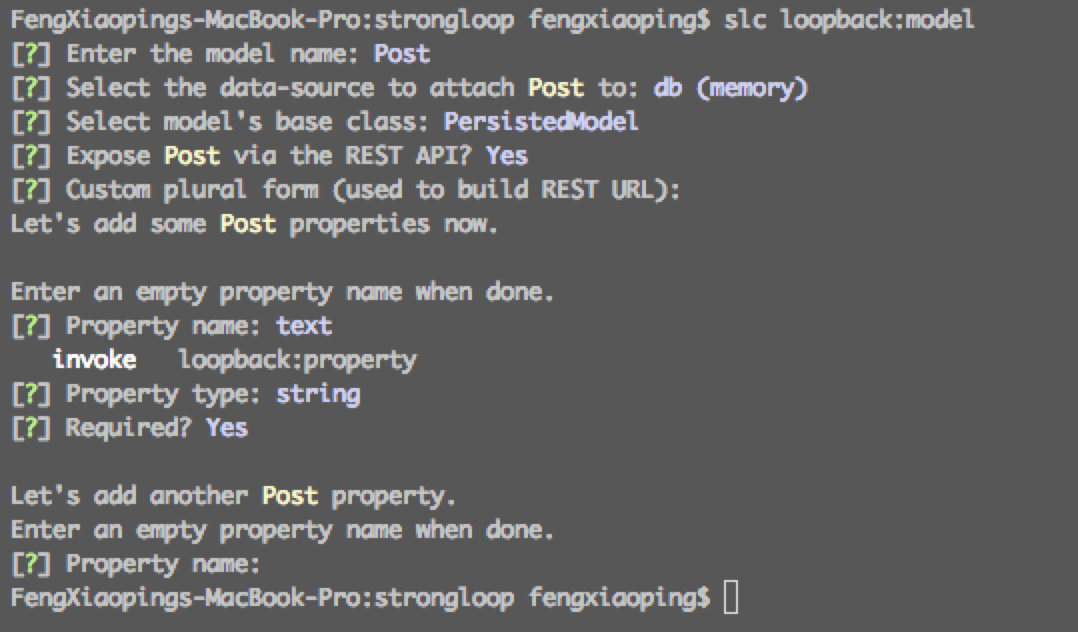
plural指的是RESTful API的route名,一个Model对应的route默认情况下会被plural(复数化),比如Post的路径是Posts。
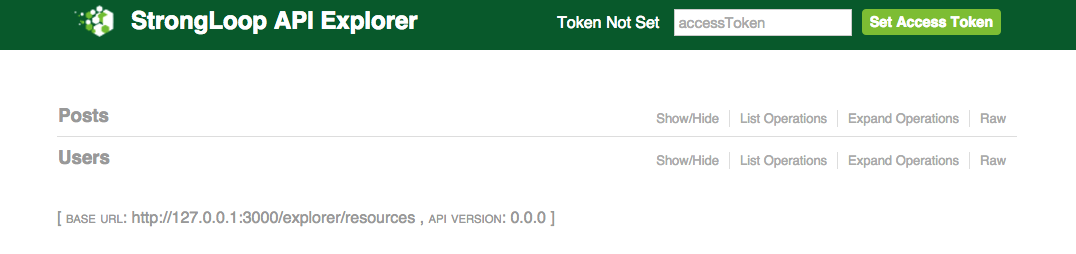
猜一下,像LeanCloud里类似,这时候应该去访问一个类似127.0.0.1:3000/xxx的地方看到他的后台吧~嗯 xxx=explorer http://127.0.0.1:3000/explorer 就能看到一个用Swagger做的API dashboard。
看一下项目的结构,像Meteor一样,LoopBack将JS代码分成服务端(server),前端(client),以及共用部分(common,个人认为这种纯schema的方法比Meteor分割的更清晰)。
略过后面的API Explorer,如何连Database,直接看如何在前端使用刚刚创建出来的API。LoopBack的做法是帮助你创建你当前API的各端SDK,目前只支持Android/iOS/Angularjs。如果你用别的Web框架可能就只能自力更生了。
创建自己的SDK lb-ng server/server.js client/lb-services.js 看看client/lb-services.js,不错吧~
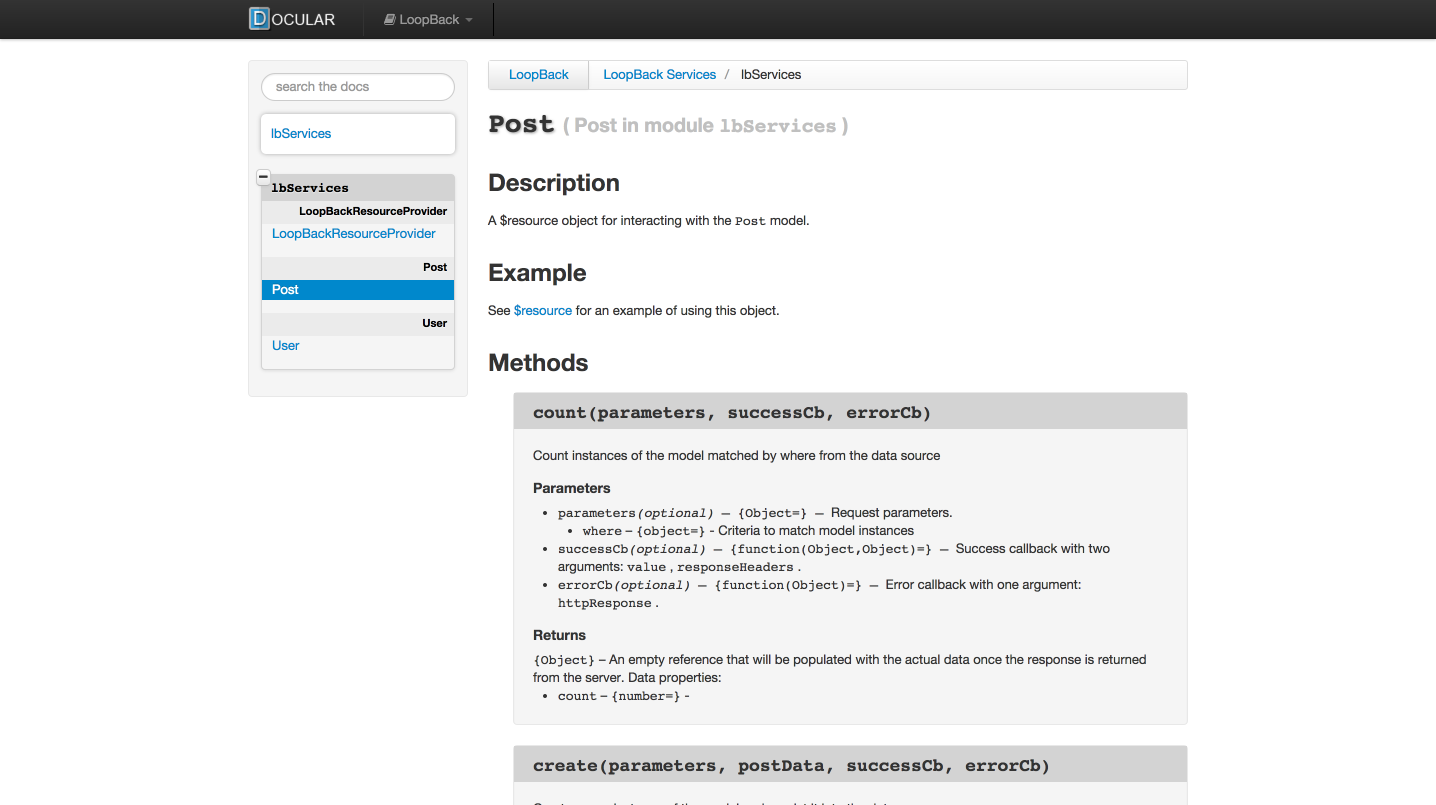
嗯,你的前端工程师需要个文档?执行 lb-ng-doc client/lb-services.js 有时候需要在前面添加sudo(不知道为啥),然后访问 http://localhost:3030/ 就能看到文档啦~这个功能是基于Docular做的。另外,如果你点LoopBack Services进去没东西,别担心,刷新一下。
看看是不是很像早期Angular的文档~
API Designer
相信很多程序员喜欢Parsejs或者LeanCloud的原因都是那个图形化界面的Model设计(或者叫API设计)后台。如果前面用的那个"Yo generator"的API creator看起来还不够贴心,你可以试试StrongLoop新推出的StrongLoop Studio beta。
在工程根目录下
sudo npm install -g http://get-studio.strongloop.com/strong-studio.tgz 安装Studio。启动Studio strong-studio,自动打开浏览器去StrongLoop官网右上角注册个账号(文档里居然写了On the bottom right is a link to go to the registration page on strongloop.com,你们不知道页面很容易改版么...)用注册的用户名登录进去看到API Composer和Profiler。Bingo!各种玩耍吧!
p.s.如果这时候你遇到了类似SyntaxError: Cannot parse package.json: Unexpected token e这样的问题,检查一下你工程根下的package.json里是不是被jslint搞乱了(I dont't know why...)
好吧好吧,我告诉你这个beta还真是特别beta...尽量不要在之前写过代码的项目里用...
懒人们
如果你缺个可以玩耍的Mongodb:Mongolab
如果你想要个可以协作开发的IDE:Koding
如果你想要个便宜好用的VPS:Digital Ocean
如果你觉得他们家不够便宜:Serverbear
如果你连VPS都不想要,只想部署个Node项目:Nodejitsu
如果你想设计个API尽快给客户端同学,又不想搭Node,找地方部署:Apiary
如果你想做(抄)个APP,又不想花钱雇一堆人:Appdupe
30天结束
这是最后一篇30hackdays啦,终于熬出来了(吁...)。Anyway,这三十天我学到了很多,如何寻找自己想要的服务,如何快速实现原型,如何比较开发者产品的竞品...
回头看,文章的内容肯定没有Shekhar的那篇Learning 30 Technologies in 30 Days: A Developer Challenge写的详尽(确实也没人家投入那么多时间精力),但我选择的技术更广泛(或者叫更乱七八糟),对我也是一种扩展视野的过程。
希望我的这个系列能给大家一些启发。技术并不都是那么深奥难懂,拥抱它也许不能立刻涨工资,但至少在寒冷的日子里,没有wifi,孤独寂寞冷的时候,还可以打开浏览器的console,输入个while,来暖暖手。
下面
嗯,不是你想的那个,也不是用来吃的。之后我会继续时不时写一些发现的好玩的开发者服务;另外,我会写一个StrongLoop的系列文章来介绍这个框架更多的特性,希望大家能够尝试这个迅猛发展的产品。
再做个小广告:最近在做一个小班(免费),专门教高中生技术,直到达成可以自行参加Hackathon的程度。如果身边有高中生对技术感兴趣,欢迎联系我~ fxp007@gmail.com
ok,那些输了的情自行来约~

相关推荐
-
NodeJS Express框架中处理404页面一个方式
在用 Express 的时候,路由是我最困惑的事之一.知道用 app.get('*') 可以处理所有页面,但这样除了自定义的其他路由外,静态文件是被忽略的.最近在写一个小工具的时候,找到了一个解决方案: 复制代码 代码如下: var express = require('express'), router = require('./routes'); var app = module.exports = express.createServer(); // Configurationapp
-

nodeJs爬虫获取数据简单实现代码
本文实例为大家分享了nodeJs爬虫获取数据代码,供大家参考,具体内容如下 var http=require('http'); var cheerio=require('cheerio');//页面获取到的数据模块 var url='http://www.jcpeixun.com/lesson/1512/'; function filterData(html){ /*所要获取到的目标数组 var courseData=[{ chapterTitle:"", videosData:{ v
-
14款NodeJS Web框架推荐
在几年的时间里,Node.js逐渐发展成一个成熟的开发平台,吸引了许多开发者.有许多大型高流量网站都采用Node.js进行开发,像PayPal,此外,开发人员还可以使用它来开发一些快速移动Web框架. 下面就介绍14款基于Node.js的Web应用框架,大家不妨过来看看有没有适合你的那一款. 1.Primus Primus,是Transformer的创造者,并且也被称为通用包装器实时框架.Primus里包含了大量的用于Node.js的实时框架,并且它们都拥有各种不同的实时功能.此外,Primus
-
Nodejs Express4.x开发框架随手笔记
Express: ?web application framework for?Node.js?Express 是一个简洁.灵活的 node.js Web 应用开发框架, 它提供一系列强大的特性,帮助你创建各种 Web 和移动设备应用. 目录 此文重点介绍Express4.x(具体是4.10.4)的开发框架,其中还会涉及到Mongoose,Ejs,Bootstrap等相关内容. 建立工程 目录结构 Express4.x配置文件 Ejs模板使用 Bootstrap界面框架 路由功能 Session
-
NodeJS制作爬虫全过程
今天来学习alsotang的爬虫教程,跟着把CNode简单地爬一遍. 建立项目craelr-demo 我们首先建立一个Express项目,然后将app.js的文件内容全部删除,因为我们暂时不需要在Web端展示内容.当然我们也可以在空文件夹下直接 npm install express来使用我们需要的Express功能. 目标网站分析 如图,这是CNode首页一部分div标签,我们就是通过这一系列的id.class来定位我们需要的信息. 使用superagent获取源数据 superagent就是
-
简单好用的nodejs 爬虫框架分享
这个就是一篇介绍爬虫框架的文章,开头就不说什么剧情了.什么最近一个项目了,什么分享新知了,剧情是挺好,但介绍的很初级,根本就没有办法应用,不支持队列的爬虫,都是耍流氓. 所以我就先来举一个例子,看一下这个爬虫框架是多么简单并可用. 第一步:安装 Crawl-pet nodejs 就不用多介绍吧,用 npm 安装 crawl-pet $ npm install crawl-pet -g --production 运行,程序会引导你完成配置,首次运行,会在项目目录下生成 info.json 文件 $
-
基于NodeJS的前后端分离的思考与实践(三)轻量级的接口配置建模框架
前言 使用Node做前后端分离的开发模式带来了一些性能及开发流程上的优势, 但同时也面临不少挑战.在淘宝复杂的业务及技术架构下,后端必须依赖Java搭建基础架构,同时提供相关业务接口供前端使用.Node在整个环境中最重要的工作之一就是代理这些业务接口,以方便前端(Node端和浏览器端)整合数据做页面渲染.如何做好代理工作,使得前后端开发分离之后,仍然可以在流程上无缝衔接,是我们需要考虑的问题.本文将就该问题做相关探讨,并提出解决方案. 由于后端提供的接口方式可能多种多样,同时开发人员在编写Nod
-
nodejs爬虫抓取数据乱码问题总结
一.非UTF-8页面处理. 1.背景 windows-1251编码 比如俄语网站:https://vk.com/cciinniikk 可耻地发现是这种编码 所有这里主要说的是 Windows-1251(cp1251)编码与utf-8编码的问题,其他的如 gbk就先不考虑在内了~ 2.解决方案 1. 使用js原生编码转换 但是我现在还没找到办法哈.. 如果是utf-8转window-1251还可以http://stackoverflow.com/questions/2696481/encoding
-
NodeJS制作爬虫全过程(续)
书接上回,我们需要修改程序以达到连续抓取40个页面的内容.也就是说我们需要输出每篇文章的标题.链接.第一条评论.评论用户和论坛积分. 如图所示,$('.reply_author').eq(0).text().trim();得到的值即为正确的第一条评论的用户. {<1>} 在eventproxy获取评论及用户名内容后,我们需要通过用户名跳到用户界面继续抓取该用户积分 复制代码 代码如下: var $ = cheerio.load(topicHtml); //此URL为下一步抓取目标URL var
-
Nodejs爬虫进阶教程之异步并发控制
之前写了个现在看来很不完美的小爬虫,很多地方没有处理好,比如说在知乎点开一个问题的时候,它的所有回答并不是全部加载好了的,当你拉到回答的尾部时,点击加载更多,回答才会再加载一部分,所以说如果直接发送一个问题的请求链接,取得的页面是不完整的.还有就是我们通过发送链接下载图片的时候,是一张一张来下的,如果图片数量太多的话,真的是下到你睡完觉它还在下,而且我们用nodejs写的爬虫,却竟然没有用到nodejs最牛逼的异步并发的特性,太浪费了啊. 思路 这次的的爬虫是上次那个的升级版,不过呢,上次那个虽
-
NodeJS框架Express的模板视图机制分析
模板引擎 Express支持许多模板引擎,常用的有: haml 的实现Haml haml.js 接替者,同时也是Express的默认模板引擎Jade 嵌入JavaScript模板EJS 基于CoffeeScript的模板引擎CoffeeKup 的NodeJS版本jQuery模板引擎 视图渲染(view randering) 视图的文件名默认需遵循"<name>.<engine>"的形式,这里<engine>是要被加载的模块的名字.比如视图layout
-
nodejs爬虫抓取数据之编码问题
cheerio DOM化并解析的时候 1.假如使用了 .text()方法,则一般不会有html实体编码的问题出现 2.如果使用了 .html()方法,则很多情况下(多数是非英文的时候)都会出现,这时,可能就需要转义一番了 类似这些 因为需要作数据存储,所有需要转换 复制代码 代码如下: Халк крушит. Новый способ исполнен 大多数都是&#(x)?\w+的格式 所以就用正则转换一番 var body = ....//这里就是请求后获得的返回数据,或者那些 .html