python3制作捧腹网段子页爬虫
0x01
春节闲着没事(是有多闲),就写了个简单的程序,来爬点笑话看,顺带记录下写程序的过程。第一次接触爬虫是看了这么一个帖子,一个逗逼,爬取煎蛋网上妹子的照片,简直不要太方便。于是乎就自己照猫画虎,抓了点图片。
科技启迪未来,身为一个程序员,怎么能干这种事呢,还是爬点笑话比较有益于身心健康。

0x02
在我们撸起袖子开始搞之前,先来普及点理论知识。
简单地说,我们要把网页上特定位置的内容,扒拉下来,具体怎么扒拉,我们得先分析这个网页,看那块内容是我们需要的。比如,这次爬取的是捧腹网上的笑话,打开 捧腹网段子页我们可以看到一大堆笑话,我们的目的就是获取这些内容。看完回来冷静一下,你这样一直笑,我们没办法写代码。在 chrome 中,我们打开 审查元素 然后一级一级的展开 HTML 标签,或者点击那个小鼠标,定位我们所需要的元素。
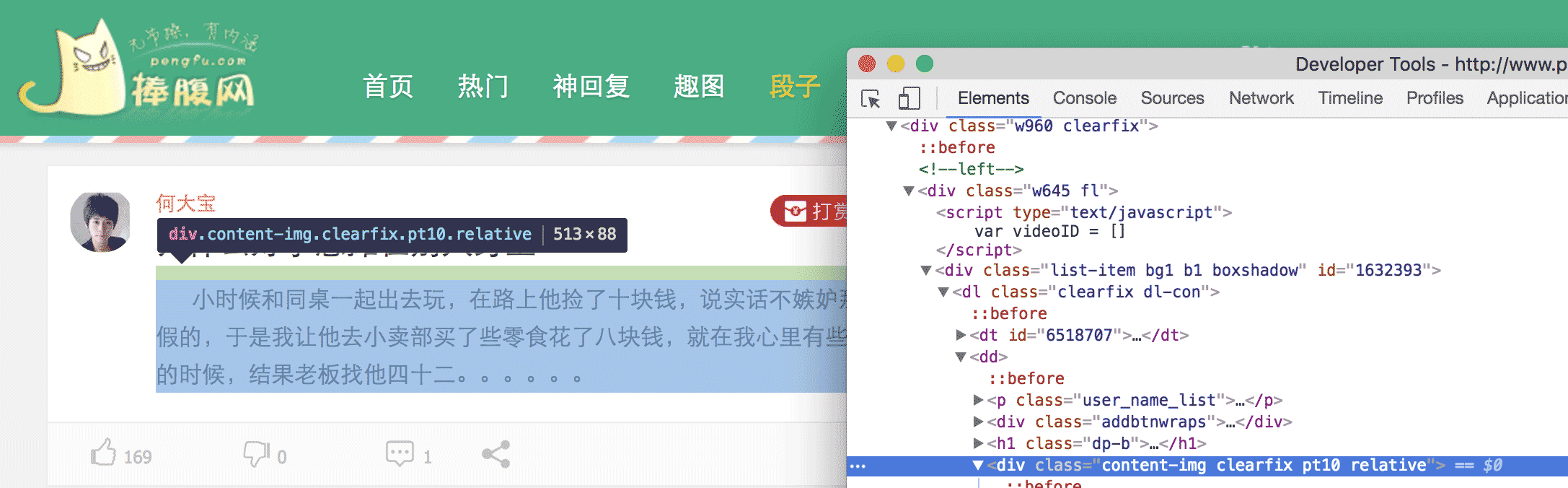
最后可以发现 <div> 中的内容就是我们所需要的笑话,在看第二条笑话,也是这样。于是乎,我们就可以把这个网页中所有的 <div> 找到,然后把里边的内容提取出来,就完成了。
0x03
好了,现在我们知道我们的目的了,就可以撸起袖子开始干了。这里我用的 python3,关于 python2 和 python3 的选用,大家可以自行决定,功能都可以实现,只是有些许不同。但还是建议用 python3。
我们要扒拉下我们需要的内容,首先我们得把这个网页扒拉下来,怎么扒拉呢,这里我们要用到一个库,叫 urllib,我们用这个库提供的方法,来获取整个网页。
首先,我们导入 urllib
import urllib.request as request
然后,我们就可以使用 request 来获取网页了,
def getHTML(url):
return request.urlopen(url).read()
人生苦短,我用 python,一行代码,下载网页,你说,还有什么理由不用 python。
下载完网页后,我们就得解析这个网页了来获取我们所需要的元素。为了解析元素,我们需要使用另外一个工具,叫做 Beautiful Soup,使用它,可以快速解析 HTML 和 XML并获取我们所需要的元素。
soup = BeautifulSoup(getHTML("http://www.pengfu.com/xiaohua_1.html"))
用 BeautifulSoup 来解析网页也就一句话,但当你运行代码的时候,会出现这么一个警告,提示要指定一个解析器,不然,可能会在其他平台或者系统上报错。
/Library/Frameworks/Python.framework/Versions/3.5/lib/python3.5/site-packages/bs4/__init__.py:181: UserWarning: No parser was explicitly specified, so I'm using the best available HTML parser for this system ("lxml"). This usually isn't a problem, but if you run this code on another system, or in a different virtual environment, it may use a different parser and behave differently.
The code that caused this warning is on line 64 of the file joke.py. To get rid of this warning, change code that looks like this:
BeautifulSoup([your markup])
to this:
BeautifulSoup([your markup], "lxml")
markup_type=markup_type))
解析器的种类 和 不同解析器之间的区别 官方文档有详细的说明,目前来说,还是用 lxml 解析比较靠谱。
修改之后
soup = BeautifulSoup(getHTML("http://www.pengfu.com/xiaohua_1.html", 'lxml'))
这样,就没有上述警告了。
div_array = soup.find_all('div', {'class':"content-img clearfix pt10 relative"})
利用 find_all 函数,来找到所有 class = content-img clearfix pt10 relative 的 div 标签 然后遍历这个数组
for x in div_array: content = x.string
这样,我们就取到了目的 div 的内容。至此,我们已经达到了我们的目的,爬到了我们的笑话。
但当以同样的方式去爬取糗百的时候,会报这样一个错误
raise RemoteDisconnected("Remote end closed connection without" http.client.RemoteDisconnected: Remote end closed connection without response
说远端无响应,关闭了链接,看了下网络也没有问题,这是什么情况导致的呢?莫非是我姿势不对?
打开 charles 抓包,果然也没反应。唉,这就奇怪了,好好的一个网站,怎么浏览器可以访问,python 无法访问呢,是不是 UA 的问题呢?看了下 charles,发现,利用 urllib 发起的请求,UA 默认是 Python-urllib/3.5 而在 chrome 中访问 UA 则是 User-Agent:Mozilla/5.0 (Macintosh; Intel Mac OS X 10_12_3) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/56.0.2924.87 Safari/537.36,那会不会是因为服务器根据 UA 来判断拒绝了 python 爬虫。我们来伪装下试试看行不行
def getHTML(url):
headers = {'User-Agent': 'User-Agent:Mozilla/5.0 (Macintosh; Intel Mac OS X 10_12_3) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/56.0.2924.87 Safari/537.36'}
req = request.Request(url, headers=headers)
return request.urlopen(req).read()
这样就把 python 伪装成 chrome 去获取糗百的网页,可以顺利的得到数据。
至此,利用 python 爬取糗百和捧腹网的笑话已经结束,我们只需要分析相应的网页,找到我们感兴趣的元素,利用 python 强大的功能,就可以达到我们的目的,不管是 XXOO 的图,还是内涵段子,都可以一键搞定,不说了,我去找点妹子图看看。
# -*- coding: utf-8 -*-
import sys
import urllib.request as request
from bs4 import BeautifulSoup
def getHTML(url):
headers = {'User-Agent': 'User-Agent:Mozilla/5.0 (Macintosh; Intel Mac OS X 10_12_3) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/56.0.2924.87 Safari/537.36'}
req = request.Request(url, headers=headers)
return request.urlopen(req).read()
def get_pengfu_results(url):
soup = BeautifulSoup(getHTML(url), 'lxml')
return soup.find_all('div', {'class':"content-img clearfix pt10 relative"})
def get_pengfu_joke():
for x in range(1, 2):
url = 'http://www.pengfu.com/xiaohua_%d.html' % x
for x in get_pengfu_results(url):
content = x.string
try:
string = content.lstrip()
print(string + '\n\n')
except:
continue
return
def get_qiubai_results(url):
soup = BeautifulSoup(getHTML(url), 'lxml')
contents = soup.find_all('div', {'class':'content'})
restlus = []
for x in contents:
str = x.find('span').getText('\n','<br/>')
restlus.append(str)
return restlus
def get_qiubai_joke():
for x in range(1, 2):
url = 'http://www.qiushibaike.com/8hr/page/%d/?s=4952526' % x
for x in get_qiubai_results(url):
print(x + '\n\n')
return
if __name__ == '__main__':
get_pengfu_joke()
get_qiubai_joke()
相关推荐
-

Python正则抓取网易新闻的方法示例
本文实例讲述了Python正则抓取网易新闻的方法.分享给大家供大家参考,具体如下: 自己写了些关于抓取网易新闻的爬虫,发现其网页源代码与网页的评论根本就对不上,所以,采用了抓包工具得到了其评论的隐藏地址(每个浏览器都有自己的抓包工具,都可以用来分析网站) 如果仔细观察的话就会发现,有一个特殊的,那么这个就是自己想要的了 然后打开链接就可以找到相关的评论内容了.(下图为第一页内容) 接下来就是代码了(也照着大神的改改写写了). #coding=utf-8 import urllib2 import
-
Python爬取网易云音乐上评论火爆的歌曲
前言 网易云音乐这款音乐APP本人比较喜欢,用户量也比较大,而网易云音乐之所以用户众多和它的歌曲评论功能密不可分,很多歌曲的评论非常有意思,其中也不乏很多感人的评论.但是,网易云音乐并没有提供热评排行榜和按评论排序的功能,没关系,本文就使用爬虫给大家爬一爬网易云音乐上那些热评的歌曲. 结果 对过程没有兴趣的童鞋直接看这里啦. 评论数大于五万的歌曲排行榜 首先恭喜一下我最喜欢的歌手(之一)周杰伦的<晴天>成为网易云音乐第一首评论数过百万的歌曲! 通过结果发现目前评论数过十万的歌曲正好十首,通过这
-
python3爬虫之入门基础和正则表达式
前面的python3入门系列基本上也对python入了门,从这章起就开始介绍下python的爬虫教程,拿出来给大家分享:爬虫说的简单,就是去抓取网路的数据进行分析处理:这章主要入门,了解几个爬虫的小测试,以及对爬虫用到的工具介绍,比如集合,队列,正则表达式: 用python抓取指定页面: 代码如下: import urllib.request url= "http://www.baidu.com" data = urllib.request.urlopen(url).read()# d
-
Python3实战之爬虫抓取网易云音乐的热门评论
前言 之前刚刚入门python爬虫,有大概半个月时间没有写python了,都快遗忘了.于是准备写个简单的爬虫练练手,我觉得网易云音乐最优特色的就是其精准的歌曲推荐和独具特色的用户评论,于是写了这个抓取网易云音乐热歌榜里的热评的爬虫.我也是刚刚入门爬虫,有什么意见和问题欢迎提出,大家一起共同进步. 废话就不多说了-下面来一起看看详细的介绍吧. 我们的目标是爬取网易云中的热歌排行榜中所有歌曲的热门评论. 这样既可以减少我们需要爬取的工作量,又可以保存到高质量的评论. 实现分析 首先,我们打开网易云网
-
一则python3的简单爬虫代码
不得不说python的上手非常简单.在网上找了一下,大都是python2的帖子,于是随手写了个python3的.代码非常简单就不解释了,直接贴代码. 复制代码 代码如下: #test rdpimport urllib.requestimport re<br>#登录用的帐户信息data={}data['fromUrl']=''data['fromUrlTemp']=''data['loginId']='12345'data['password']='12345'user_agent='Mozil
-
使用Python实现下载网易云音乐的高清MV
Python下载网易云音乐的高清MV,没有从首页进去解析,直接循环了.... downPage1.py 复制代码 代码如下: #coding=utf-8 import urllib import re import os def getHtml(url): page = urllib.urlopen(url) html = page.read() return html def getVideo(html): reg = r'hurl=(.+?\.jpg)'
-
Python爬取网易云音乐热门评论
最近在研究文本挖掘相关的内容,所谓巧妇难为无米之炊,要想进行文本分析,首先得到有文本吧.获取文本的方式有很多,比如从网上下载现成的文本文档,或者通过第三方提供的API进行获取数据.但是有的时候我们想要的数据并不能直接获取,因为并不提供直接的下载渠道或者API供我们获取数据.那么这个时候该怎么办呢?有一种比较好的办法是通过网络爬虫,即编写计算机程序伪装成用户去获得想要的数据.利用计算机的高效,我们可以轻松快速地获取数据. 那么该如何写一个爬虫呢?有很多种语言都可以写爬虫,比如Java,php,py
-
python3制作捧腹网段子页爬虫
0x01 春节闲着没事(是有多闲),就写了个简单的程序,来爬点笑话看,顺带记录下写程序的过程.第一次接触爬虫是看了这么一个帖子,一个逗逼,爬取煎蛋网上妹子的照片,简直不要太方便.于是乎就自己照猫画虎,抓了点图片. 科技启迪未来,身为一个程序员,怎么能干这种事呢,还是爬点笑话比较有益于身心健康. 0x02 在我们撸起袖子开始搞之前,先来普及点理论知识. 简单地说,我们要把网页上特定位置的内容,扒拉下来,具体怎么扒拉,我们得先分析这个网页,看那块内容是我们需要的.比如,这次爬取的是捧腹网上的笑话,打
-
基于Python3制作一个带GUI界面的小说爬虫工具
目录 效果图 开发完成后的界面 采集过程界面 采集后存储 主要功能 用到的第三方模块 打包为 exe 命令 全部源码 效果图 最近帮朋友写个简单爬虫,顺便整理了下,搞成了一个带GUI界面的小说爬虫工具,用来从笔趣阁爬取小说. 开发完成后的界面 采集过程界面 采集后存储 主要功能 1.多线程采集,一个线程采集一本小说 2.支持使用代理,尤其是多线程采集时,不使用代理可能封ip 3.实时输出采集结果 使用 threading.BoundedSemaphore() pool_sema.acquire(
-
Python3.4编程实现简单抓取爬虫功能示例
本文实例讲述了Python3.4编程实现简单抓取爬虫功能.分享给大家供大家参考,具体如下: import urllib.request import urllib.parse import re import urllib.request,urllib.parse,http.cookiejar import time def getHtml(url): cj=http.cookiejar.CookieJar() opener=urllib.request.build_opener(urllib.
-
python制作花瓣网美女图片爬虫
花瓣图片的加载使用了延迟加载的技术,源代码只能下载20多张图片,修改后基本能下载所有的了,只是速度有点慢,后面再优化下 import urllib, urllib2, re, sys, os,requests path=r"C:\wqa\beautify" url = 'http://huaban.com/favorite/beauty' #http://huaban.com/explore/zhongwenlogo/?ig1un9tq&max=327773629&li
-
利用Node.js制作爬取大众点评的爬虫
前言 Node.js天生支持并发,但是对于习惯了顺序编程的人,一开始会对Node.js不适应,比如,变量作用域是函数块式的(与C.Java不一样):for循环体({})内引用i的值实际上是循环结束之后的值,因而引起各种undefined的问题:嵌套函数时,内层函数的变量并不能及时传导到外层(因为是异步)等等. 一. API分析 大众点评开放了查询餐馆信息的API,这里给出了城市与cityid之间的对应关系, 链接:http://m.api.dianping.com/searchshop.json
-
使用Python3制作TCP端口扫描器
在渗透测试的初步阶段通常我们都需要对攻击目标进行信息搜集,而端口扫描就是信息搜集中至关重要的一个步骤.通过端口扫描我们可以了解到目标主机都开放了哪些服务,甚至能根据服务猜测可能存在某些漏洞. TCP端口扫描一般分为以下几种类型: TCP connect扫描:也称为全连接扫描,这种方式直接连接到目标端口,完成了TCP三次握手的过程,这种方式扫描结果比较准确,但速度比较慢而且可轻易被目标系统检测到. TCP SYN扫描:也称为半开放扫描,这种方式将发送一个SYN包,启动一个TCP会话,并等待目标响应
-
用python3 urllib破解有道翻译反爬虫机制详解
前言 最近在学习python 爬虫方面的知识,网上有一博客专栏专门写爬虫方面的,看到用urllib请求有道翻译接口获取翻译结果.发现接口变化很大,用md5加了密,于是自己开始破解.加上网上的其他文章找源码方式并不是通用的,所有重新写一篇记录下. 爬取条件 要实现爬取的目标,首先要知道它的地址,请求参数,请求头,响应结果. 进行抓包分析 打开有道翻译的链接:http://fanyi.youdao.com/.然后在按f12 点击Network项.这时候就来到了网络监听窗口,在这个页面中发送的所有网络
-
vbs制作的校内网古惑仔外挂(可智能加血)
set Obj = createobject("WScript.Shell") VBS YN=Obj.Popup("欢迎使用<淡月下清荷>古惑仔外挂程序,<自动式>恢复生命值吗?",0,"关机?",36) Gosub jiance ///////检测位置 up=500 down=0 Rem brotherset VBSCall up=InputBox ("请设置攻击目标的 兄弟上限") VBSCall
-
Python多线程爬虫实战_爬取糗事百科段子的实例
多线程爬虫:即程序中的某些程序段并行执行, 合理地设置多线程,可以让爬虫效率更高 糗事百科段子普通爬虫和多线程爬虫 分析该网址链接得出: https://www.qiushibaike.com/8hr/page/页码/ 多线程爬虫也就和JAVA的多线程差不多,直接上代码 ''' #此处代码为普通爬虫 import urllib.request import urllib.error import re headers = ("User-Agent","Mozilla/5.0
-
用css制作星级评分第1/3页
原文:Creating a Star Rater using CSS 链接:http://komodomedia.com/blog/index.php/2005/08/24/creating-a-star-rater-using-css/ 版权:版权归原作者所有,翻译文档版权归本人|greengnn,和blueidea. 先看看效果 Step 1: XHTML <ul class="star-rating"> <li><a href="