Mysql源码学习笔记 偷窥线程
感觉代码有些凌乱,注释代码都写的比较随意,好像没有什么统一的规范,不同的文件中代码风格也有差异,可能Mysql经过了很多牛人的手之后,集众牛人之长吧。也可能是我见识比较浅薄,适应了自己的代码风格,井底之蛙了,总之还是怀着敬畏的心情开始咱的源码之旅吧。本人菜鸟,大神轻拍。
Mysql可以启动起来了,应该怎么学习呢?总不能从main开始一步一步的看吧,Mysql作为比较底层的大型软件,涉及到数据库实现的方方面面,没有厚实的数据库理论基础和对Mysql各个模块相当的熟悉,从main开始势必会把自己引入某个死胡同啊,什么都看,最后啥也不会,咱伤不起。
经过思考后,我想还是通过客户端来调试服务器,从而学习服务器代码比较现实。也就是通过客户端的动作,看服务器的反应。比如从客户端的登录动作来看SERVER如何进行通信、用户识别、鉴定以及任务分配的,通过CREATE TABLE,来看SERVER如何解析DDL语句以及针对不同的存储引擎采取的不同的物理存储方式,通过INSERT语句,来看SERVER如何进行Btree的操作。通过SELECT语句来看如何进行SQL语句语法树的创建和优化的,通过ROLL BACK,来看SERVER事务是如何实现的。这里主要是通过跟踪代码学习Mysql数据库实现的思想,对于具体的代码不去做过多的追究(主要是我对C++不是很熟悉),好读书,不求甚解,呵呵。
由此,暂时准备了以下几条SQL语句,来有针对的进行SERVER的分析
代码如下:
1、 LOGIN(登录)
mysql.exe –uroot –p
2、 DDL(建表语句)
create table tb_myisam(c1 int, c2 varchar(256)) engine = myisam;
create table tb_innodb(c1 int, c2 varchar(256)) engine = innodb;
3、 INSERT
Insert into tb_myisam values(1 , '寂寞的肥肉');
Insert into tb_innodb values(1 , '寂寞的肥肉');
4、 SELECT
Select c1 from tb_myisam;
Select * from tb_innodb;
5、 ROLLBACK
大家都知道,mysql可以通过多个客户端,进行并发操作,当然也包括登录了。在别人登录的时候,其他的用户可能正在进行一些其它的操作,因此对于登录我们猜测应该有专门的线程负责客户端和服务器的连接的创建,以保证登录的及时性,对于每个连接的用户,应该用一个独立的线程进行任务的执行。
首先介绍下mysql中创建线程的函数,创建线程的函数貌似就是_begin_thread,CreateThread,我们通过VS在整个解决方案中进行查找,bingo!在my_winthread.c中找到了调用_begin_thread的函数pthread_create,在os0thread.c中找到了调用CreateThread的函数os_thread_create,一个系统怎么封装两个系统函数呢??再仔细看下,发现my_winthread.c是在项目mysys下,而os0thread.c是在项目innobase下。innobase!!这不就是innodb的插件式存储引擎么,原来这是存储引擎自己的封装的底层函数,哥心中豁然开朗了。我想Mysql应用范围如此之广,除了开源之外,插件式的存储引擎功不可没啊,用户可以根据自己的实际应用采取不同的存储引擎,对于大公司,估计会开发自己的存储引擎。
下面分析下pthread_create是如何调用_begin_thread的,先粗略看下源码。
代码如下:
int pthread_create(pthread_t *thread_id, pthread_attr_t *attr,
pthread_handler func, void *param)
{
HANDLE hThread;
struct pthread_map *map;
DBUG_ENTER("pthread_create");
if (!(map=malloc(sizeof(*map))))
DBUG_RETURN(-1);
map->func=func;
map->param=param;
pthread_mutex_lock(&THR_LOCK_thread);
#ifdef __BORLANDC__
hThread=(HANDLE)_beginthread((void(_USERENTRY *)(void *)) pthread_start,
attr->dwStackSize ? attr->dwStackSize :
65535, (void*) map);
#else
hThread=(HANDLE)_beginthread((void( __cdecl *)(void *)) pthread_start,
attr->dwStackSize ? attr->dwStackSize :
65535, (void*) map);
#endif
DBUG_PRINT("info", ("hThread=%lu",(long) hThread));
*thread_id=map->pthreadself=hThread;
pthread_mutex_unlock(&THR_LOCK_thread);
if (hThread == (HANDLE) -1)
{
int error=errno;
DBUG_PRINT("error",
("Can't create thread to handle request (error %d)",error));
DBUG_RETURN(error ? error : -1);
}
VOID(SetThreadPriority(hThread, attr->priority)) ;
DBUG_RETURN(0);
}
map->func=func;
map->param=param;
_beginthread((void( __cdecl *)(void *)) pthread_start,
attr->dwStackSize ? attr->dwStackSize :
65535, (void*) map);
从这可以看出,创建的新线程的名字是个固定的函数——pthread_start,而我们传进来的想创建的函数func是挂载在了map上了,函数的参数同样的挂载在map上了,这样我们就可以推理出在pthread_start函数中,肯定会出现这样的代码:
map->func(map->param);
mysql没有选择直接_beginthread(func, stack_size, param)的形式,而是进行了一次封装,不知道这样的好处是什么,可能牛人的思想不是我这样小菜鸟能顿悟的,跑题了~~
至此,我们只在pthread_create函数上设置断点,调试启动mysqld,断点停下来,看下系统的线程状况:
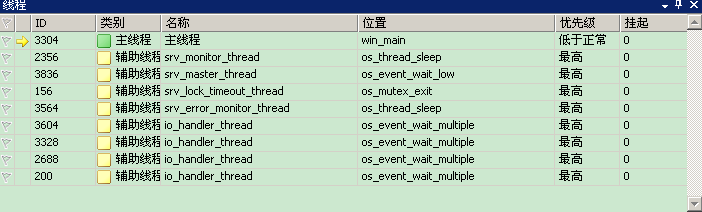
我们第一次进入pthread_create,任何线程都没开始创建呢,按理说系统线程应该就只有一个主线程,可现在多了这么多,这些应该是innodb存储引擎创建的线程了(具体是在plugin_init)。根据线程的名称,结合注释,猜测了下这些线程的作用。
Io_handler_thread:从名称可以知道这些是I/O线程,负责进行磁盘I/O。
Svr_error_monitor_thread:应该是服务器出错监控线程。
Svr_lock_timeout_thread:应该是和上锁相关的线程。
Svr_master_thread:
/*************************************************************************
The master thread controlling the server. */
服务器控制线程,应该是具体进行作业的线程。
Svr_monitor_thread:
/*************************************************************************
A thread prints the info output by various InnoDB monitors. */
监控线程,负责打印信息。
淡然飘过吧,不去细究了,我们只关心pthread_create创建的线程。根据调试,发现多了几个线程同名的线程_threadstart,如下所示: 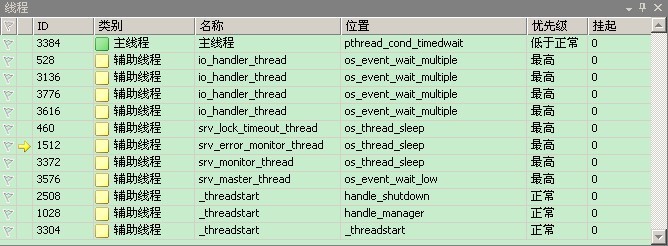
调试时看堆栈可以知道这三个线程的创建者和作用,如下所示
创建者 |
处理函数 |
|
create_shutdown_thread |
handle_shutdown |
|
start_handle_manager |
handle_manager |
|
handle_connections_methods |
handle_connections_sockets |
处理函数:调用pthread_create所创建的线程的具体的线程函数。
由名称我们就可以看出,handle_connections_sockets应该是处理连接的线程了,从顺序上看,也应该是这样,只有系统中所有的其他必须的线程创建完毕后,才能创建监听线程(连接线程),即监听线程应该是系统最后创建的。
找到了我们LOGIN需要的线程了,下次针对这个线程,分析下如何进行登录的,以及登录后为用户分配哪些资源。时间不早啦,洗洗睡了
作者 : cnblogs 心中无码
相关推荐
-

MySQL学习笔记1:安装和登录(多种方法)
今天开始学习数据库,由于我对微软不怎么感冒,所以就不用他家的产品了本来想装ORACLE的,不过太大了,看着害怕对于我这种喜欢一切从简的人来说,MySQL是个不错的选择好了,关于数据库的大理论我就懒得写了,那些考试必备的内容我已经受够了我只需要知道一点,人们整理数据和文件的行为在不断进化,以至现在使用数据库来更好的管理 下面我们开始安装 我使用的是Linux Mint,基于Ubuntu的一种发行版,用起来的确不错 由于有现成的包管理工具使用,我就不从官网下载编译安装了 一条命令搞定: 安装过程中会
-
MySQL学习笔记4:完整性约束限制字段
完整性约束是对字段进行限制,从而符合该字段达到我们期望的效果比如字段含有默认值,不能是NULL等 直观点说:如果插入的数据不满足限制要求,数据库管理系统就拒绝执行操作 设置表的主键 主键能够标识表中每条信息的唯一性,如同身份证号码和人的关系 人可以同名,但是身份证号码却是唯一的, 创建主键的目的在于快速查找到表中的某一条信息 单字段主键 复制代码 代码如下: mysql> create table student( -> id int primary key, -> name varch
-
MySQL定时器EVENT学习笔记
要使定时起作用 MySQL的常量GLOBAL event_scheduler必须为on或者是1 -- 查看是否开启定时器 SHOW VARIABLES LIKE '%sche%'; -- 开启定时器 0:off 1:on SET GLOBAL event_scheduler = 1; -- 创建事件 --每隔一秒自动调用e_test()存储过程 CREATE EVENT IF NOT EXISTS event_test ON SCHEDULE EVERY 1 SECOND ON COMPLETI
-
MySql官方手册学习笔记1 MySql简单上手
连接与断开服务器 连接服务器通常需要提供一个MySQL用户名并且很可能需要一个 密码.如果服务器运行在登录服务器之外的其它机器上,还需要指定主机名: shell> mysql -h host -u user -pEnter password: ******** host代表MySQL服务器运行的主机名,user代表MySQL账户用户名,******** 代表你的密码. 如果有效,你应该看见mysql>提示符后的一些介绍信息: shell> mysql -h host -u user -p
-
MySQL学习笔记2:数据库的基本操作(创建删除查看)
我们所安装的MySQL说白了是一个数据库的管理工具,真正有价值的东西在于数据关系型数据库的数据是以表的形式存在的,N个表汇总在一起就成了一个数据库现在来看看数据库的基本操作 无非就是三点:创建 删除 查看 创建数据库 复制代码 代码如下: mysql> create database school; Query OK, 1 row affected (0.00 sec) create database语句用于创建数据库 后面的school是数据库的名字,分号结束 执行成功则会显示Query OK
-
MySQL学习笔记3:表的基本操作介绍
要操作表首先需要选定数据库,因为表是存在于数据库内的 选择数据库 mysql> use school; Database changed 选择好数据库之后,我们就可以在此数据库之中创建表了 创建表 mysql> create table student( -> id int, -> name varchar(20), -> sex boolean -> ); Query OK, 0 rows affected (0.11 sec) create table用于创建表,后
-
MySql官方手册学习笔记2 MySql的模糊查询和正则表达式
SQL模式匹配允许你使用"_"匹配任何单个字符,而"%"匹配任意数目字符(包括零字符).在 MySQL中,SQL的模式默认是忽略大小写的.下面给出一些例子.注意使用SQL模式时,不能使用=或!=:而应使用LIKE或NOT LIKE比较操作符. 要想找出以"b"开头的名字: mysql> SELECT * FROM pet WHERE name LIKE 'b%';+--------+--------+---------+------+---
-
MySQL学习笔记5:修改表(alter table)
我们在创建表的过程中难免会考虑不周,因此后期会修改表修改表需要用到alter table语句 修改表名 复制代码 代码如下: mysql> alter table student rename person; Query OK, 0 rows affected (0.03 sec) 这里的student是原名,person是修改过后的名字 用rename来重命名,也可以使用rename to 修改字段的数据类型 复制代码 代码如下: mysql> alter table person modi
-
Mysql存储过程学习笔记--建立简单的存储过程
一.存储过程 存储过程(Stored Procedure)是在大型数据库系统中,一组为了完成特定功能的SQL语句集,经编译后存储在数据库中,用户 通过指定存储过程的名字并给出参数(如果该存储过程带有参数)来执行它.而我们常用的操作数据库语言SQL语句在执行的时 候需要要先编译,然后执行,所以执行的效率没有存储过程高. 存储过程优点如下: 重复使用.存储过程可以重复使用,从而可以减少数据库开发人员的工作量.提高性能.存储过程在创建的时候在进行了编译,将来使用的时候不再重新翻译.一般的SQL语句每执
-
一千行的MySQL学习笔记汇总
本文详细汇总了MySQL学习中的各类技巧,分享给大家供大家参考. 具体如下: /* 启动MySQL */ net start mysql /* 连接与断开服务器 */ mysql -h 地址 -P 端口 -u 用户名 -p 密码 /* 跳过权限验证登录MySQL */ mysqld --skip-grant-tables -- 修改root密码 密码加密函数password() update mysql.user set password=password('root'); SHOW PROCE
-
MYSQL的select 学习笔记
记录一些select的技巧: 1.select语句可以用回车分隔 $sql="select * from article where id=1" 和 $sql="select * from article where id=1",都可以得到正确的结果,但有时分开写或许能更明了一点,特别是当sql语句比较长时 2.批量查询数据 可以用in来实现 $sql="select * from article where id in(1,3,5)"