基于curl数据采集之单页面采集函数get_html的使用
这是一个系列 没办法在一两天写完 所以一篇一篇的发布
大致大纲:
1.curl数据采集系列之单页面采集函数get_html
2.curl数据采集系列之多页面并行采集函数get_htmls
3.curl数据采集系列之正则处理函数get _matches
4.curl数据采集系列之代码分离
5.curl数据采集系列之并行逻辑控制函数web_spider
单页面采集在数据采集过程中是最常用的一个功能 有时在服务器访问限制的情况下 只能使用这种采集方式 慢 但是可以简单的控制 所以写好一个常用的curl函数调用是很重要的
百度和网易比较熟悉 所以拿这两个网站首页采集来做例子讲解
$url = 'http://www.baidu.com';
$ch = curl_init($url);
curl_setopt($ch,CURLOPT_RETURNTRANSFER,true);
curl_setopt($ch,CURLOPT_TIMEOUT,5);
$html = curl_exec($ch);
if($html !== false){
echo $html;
}
由于使用频繁 可以利用curl_setopt_array写成函数的形式:
代码如下:
function get_html($url,$options = array()){
$options[CURLOPT_RETURNTRANSFER] = true;
$options[CURLOPT_TIMEOUT] = 5;
$ch = curl_init($url);
curl_setopt_array($ch,$options);
$html = curl_exec($ch);
curl_close($ch);
if($html === false){
return false;
}
return $html;
}
$url = 'http://www.baidu.com';
echo get_html($url);
有时候需要传递一些特定的参数才能得到正确的页面 如现在要得到网易的页面:
代码如下:
$url = 'http://www.163.com';
echo get_html($url);
会看到一片空白 什么也没有 那么再利用curl_getinfo写一个函数 看看发生了什么:
代码如下:
function get_info($url,$options = array()){
$options[CURLOPT_RETURNTRANSFER] = true;
$options[CURLOPT_TIMEOUT] = 5;
$ch = curl_init($url);
curl_setopt_array($ch,$options);
$html = curl_exec($ch);
$info = curl_getinfo($ch);
curl_close($ch);
return $info;
}
$url = 'http://www.163.com';
var_dump(get_info($url));

可以看到http_code 302 重定向了 这时候就需要传递一些参数了:
代码如下:
$url = 'http://www.163.com';
$options[CURLOPT_FOLLOWLOCATION] = true;
echo get_html($url,$options);
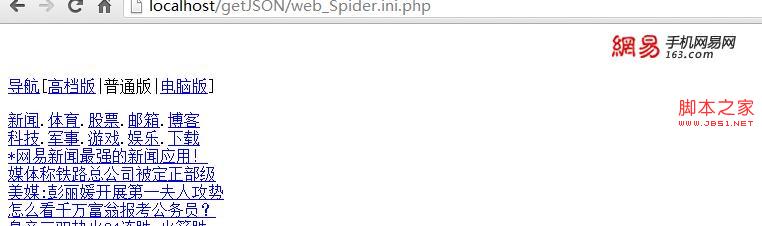
会发现 怎么是这样的一个页面 和我们电脑访问的不同???
看来参数还是不够 不够服务器判断我们的客户端是什么设备上的 就返回了个普通版
$url = 'http://www.163.com';
$options[CURLOPT_FOLLOWLOCATION] = true;
$options[CURLOPT_USERAGENT] = 'Mozilla/5.0 (Windows NT 6.1; rv:19.0) Gecko/20100101 Firefox/19.0';
echo get_html($url,$options);
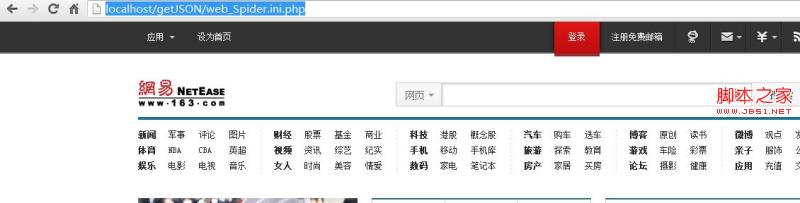
OK现在页面已经出来了 这样基本这个get_html函数基本能实现这样扩展的功能
当然也有另外的办法可以实现,当你明确的知道网易的网页的时候就可以简单采集了:
代码如下:
$url = 'http://www.163.com/index.html';
echo get_html($url);
这样也可以正常的采集
相关推荐
-

Knockoutjs快速入门(经典)
Knockoutjs是一个JavaScript实现的MVVM框架.主要有如下几个功能: 1. Declarative bindings 2. Observables and dependency tracking 3. Templating 它对于分离前台的业务逻辑和视图简化数据绑定过程有显著的作用.闲言少叙,直接看例子,如何下载也不说了,如果用VS开发的话用Nuget就可以一键搞定. 1.基本绑定和依赖跟踪 首先需要定义一个ViewModel: 复制代码 代码如下: <script type=
-
为ASP.NET MVC及WebApi添加路由优先级
一.为什么需要路由优先级 大家都知道我们在Asp.Net MVC项目或WebApi项目中注册路由是没有优先级的,当项目比较大.或有多个区域.或多个Web项目.或采用插件式框架开发时,我们的路由注册很可能 不是写在一个文件中的,而是分散在很多不同项目的文件中,这样一来,路由的优先级的问题就突显出来了. 比如: App_Start/RouteConfig.cs中 routes.MapRoute( name: "Default", url: "{controller}/{actio
-
Bootstrap与KnockoutJs相结合实现分页效果实例详解
KnockoutJS是一个JavaScript实现的MVVM框架.非常棒.比如列表数据项增减后,不需要重新刷新整个控件片段或自己写JS增删节点,只要预先定义模板和符合其语法定义的属性即可.简单的说,我们只需要关注数据的存取. 一.引言 由于最近公司的系统需要改版,改版的新系统我打算使用KnockoutJs来制作Web前端.在做的过程中,遇到一个问题--如何使用KnockoutJs来完成分页的功能.在前一篇文章中并没有介绍使用KnockoutJs来实现分页,所以在这篇文章中,将补充用Knockou
-
ko knockoutjs动态属性绑定技巧应用
knockoutjs 简称 ko ko的动态属性是指,ViewModel不确定的属性,而后期却需要的属性. 什么是不确定属性,比如ListModel如果 编辑某一项,想把这一项的状态变更为Edit.数据并不包括Edit属性,mvvm绑定时,会发现报错. 那么一定需要拓展ko才能达到我们的目的. 首先来认识有值属性绑定,和 无值属性绑定: 一.有值属性绑定: JS模型: 复制代码 代码如下: $(function () { var viewModel = function () { var sel
-
Knockoutjs的环境搭建教程
最近要在项目中使用Knockoutjs,因此今天就首先研究了一下Knockoutjs的环境搭建,并进行了一个简单的测试. 首先要到http://knockoutjs.com/index.html下载最新版本的Knockoutjs,笔者这里下载的是knockout-2.2.0.js.然后新建一个.html文件,在html文档中加入以下的语句导入此js: <script type="text/javascript" src="knockout-2.2.0.js"&
-
KnockoutJs快速入门教程
一.引言 之前这个系列文章已经介绍Bootstrap,详情请查看本文: <Bootstrap入门教程> ,由于最近项目中,前端是Asp.net MVC + KnockoutJs + Bootstrap来做的.所以我又重新开始写这个系列.今天就让我们来看看Web前端的MVVM框架--KnockoutJs. 二.KnockoutJs是什么? 做.NET开发的人应该都知道,WPF中就集成了MVVM框架,所以KnockoutJs也是针对Web开发的MVVM框架.关于MVVM好处简单点来说就是--使得业
-
C#进阶系列 WebApi身份认证解决方案推荐:Basic基础认证
前言:最近,讨论到数据库安全的问题,于是就引出了WebApi服务没有加任何验证的问题.也就是说,任何人只要知道了接口的url,都能够模拟http请求去访问我们的服务接口,从而去增删改查数据库,这后果想想都恐怖.经过一番折腾,总算是加上了接口的身份认证,在此记录下,也给需要做身份认证的园友们提供参考. 一.为什么需要身份认证 在前言里面,我们说了,如果没有启用身份认证,那么任何匿名用户只要知道了我们服务的url,就能随意访问我们的服务接口,从而访问或修改数据库. 1.我们不加身份认证,匿名用户可以
-
WebApi+Bootstrap+KnockoutJs打造单页面程序
一.前言 在前一个专题快速介绍了KnockoutJs相关知识点,也写了一些简单例子,希望通过这些例子大家可以快速入门KnockoutJs.为了让大家可以清楚地看到KnockoutJs在实际项目中的应用,本专题将介绍如何使用WebApi+Bootstrap+KnockoutJs+Asp.net MVC来打造一个单页面Web程序.这种模式也是现在大多数公司实际项目中用到的. 二.SPA(单页面)好处 在介绍具体的实现之前,我觉得有必要详细介绍了SPA.SPA,即Single Page Web App
-
node+express+ejs制作简单页面上手指南
1.建立工程文件夹my_ejs. 2.首先利用npm install express和npm install ejs 下载这两个家伙.至于要不要设置成全局的,看习惯,我习惯性的下载到本项目中的文件夹中my_ejs. 然后建立相应的文件: index.js: form.ejs: index.ejs app.js: 开始运行app.js node app.js,然后再浏览器端访问:localhost:1337 单击发表文章: 点击发表,跳转到首页. 好了到此为止,一个简易的"网站"算是出来
-
ASP.net WebAPI 上传图片实例
复制代码 代码如下: [HttpPost] public Task<Hashtable> ImgUpload() { // 检查是否是 multipart/form-data if (!Request.Content.IsMimeMultipartContent("form-data")) throw new HttpResponseException(HttpStatusCode.UnsupportedMediaType); //文