使用Node.js搭建静态资源服务详细教程
对于Node.js新手,搭建一个静态资源服务器是个不错的锻炼,从最简单的返回文件或错误开始,渐进增强,还可以逐步加深对http的理解。那就开始吧,让我们的双手沾满网络请求!
Note:
当然在项目中如果有使用express框架,用express.static一行代码就可以达到目的了:
app.use(express.static('public'))
这里我们要实现的正是express.static背后所做工作的一部分,建议同步阅读该模块源码。
基本功能
不急着写下第一行代码,而是先梳理一下就基本功能而言有哪些步骤。
- 在本地根据指定端口启动一个http server,等待着来自客户端的请求
- 当请求抵达时,根据请求的url,以设置的静态文件目录为base,映射得到文件位置
- 检查文件是否存在
- 如果文件不存在,返回404状态码,发送not found页面到客户端
- 如果文件存在:
- 打开文件待读取
- 设置response header
- 发送文件到客户端
6.等待来自客户端的下一个请求
实现基本功能
代码结构
创建一个nodejs-static-webserver目录,在目录内运行npm init初始化一个package.json文件。
mkdir nodejs-static-webserver && cd "$_" // initialize package.json npm init
接着创建如下文件目录:
-- config
---- default.json
-- static-server.js
-- app.js
default.json
{
"port": 9527,
"root": "/Users/sheila1227/Public",
"indexPage": "index.html"
}
default.js存放一些默认配置,比如端口号、静态文件目录(root)、默认页(indexPage)等。当这样的一个请求http://localhost:9527/myfiles/抵达时. 如果根据root映射后得到的目录内有index.html,根据我们的默认配置,就会给客户端发回index.html的内容。
static-server.js
const http = require('http');
const path = require('path');
const config = require('./config/default');
class StaticServer {
constructor() {
this.port = config.port;
this.root = config.root;
this.indexPage = config.indexPage;
}
start() {
http.createServer((req, res) => {
const pathName = path.join(this.root, path.normalize(req.url));
res.writeHead(200);
res.end(`Requeste path: ${pathName}`);
}).listen(this.port, err => {
if (err) {
console.error(err);
console.info('Failed to start server');
} else {
console.info(`Server started on port ${this.port}`);
}
});
}
}
module.exports = StaticServer;
在这个模块文件内,我们声明了一个StaticServer类,并给其定义了start方法,在该方法体内,创建了一个server对象,监听rquest事件,并将服务器绑定到配置文件指定的端口。在这个阶段,我们对于任何请求都暂时不作区分地简单地返回请求的文件路径。path模块用来规范化连接和解析路径,这样我们就不用特意来处理操作系统间的差异。
app.js
const StaticServer = require('./static-server');
(new StaticServer()).start();
在这个文件内,调用上面的static-server模块,并创建一个StaticServer实例,调用其start方法,启动了一个静态资源服务器。这个文件后面将不需要做其他修改,所有对静态资源服务器的完善都发生在static-server.js内。
在目录下启动程序会看到成功启动的log:
> node app.js Server started on port 9527
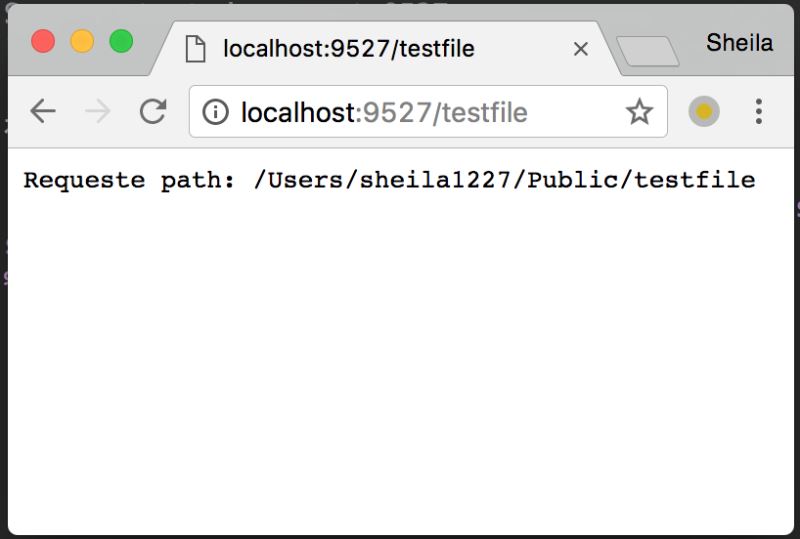
在浏览器中访问,可以看到服务器将请求路径直接返回了。
路由处理
之前我们对任何请求都只是向客户端返回文件位置而已,现在我们将其替换成返回真正的文件:
routeHandler(pathName, req, res) {
}
start() {
http.createServer((req, res) => {
const pathName = path.join(this.root, path.normalize(req.url));
this.routeHandler(pathName, req, res);
}).listen(this.port, err => {
...
});
}
将由routeHandler来处理文件发送。
读取静态文件
读取文件之前,用fs.stat检测文件是否存在,如果文件不存在,回调函数会接收到错误,发送404响应.
respondNotFound(req, res) {
res.writeHead(404, {
'Content-Type': 'text/html'
});
res.end(`<h1>Not Found</h1><p>The requested URL ${req.url} was not found on this server.</p>`);
}
respondFile(pathName, req, res) {
const readStream = fs.createReadStream(pathName);
readStream.pipe(res);
}
routeHandler(pathName, req, res) {
fs.stat(pathName, (err, stat) => {
if (!err) {
this.respondFile(pathName, req, res);
} else {
this.respondNotFound(req, res);
}
});
}
Note:
读取文件,这里用的是流的形式createReadStream而不是readFile,是因为后者会在得到完整文件内容之前将其先读到内存里。这样万一文件很大,再遇上多个请求同时访问,readFile就承受不来了。使用文件可读流,服务端不用等到数据完全加载到内存再发回给客户端,而是一边读一边发送分块响应。这时响应里会包含如下响应头:
Transfer-Encoding:chunked
默认情况下,可读流结束时,可写流的end()方法会被调用。
MIME支持
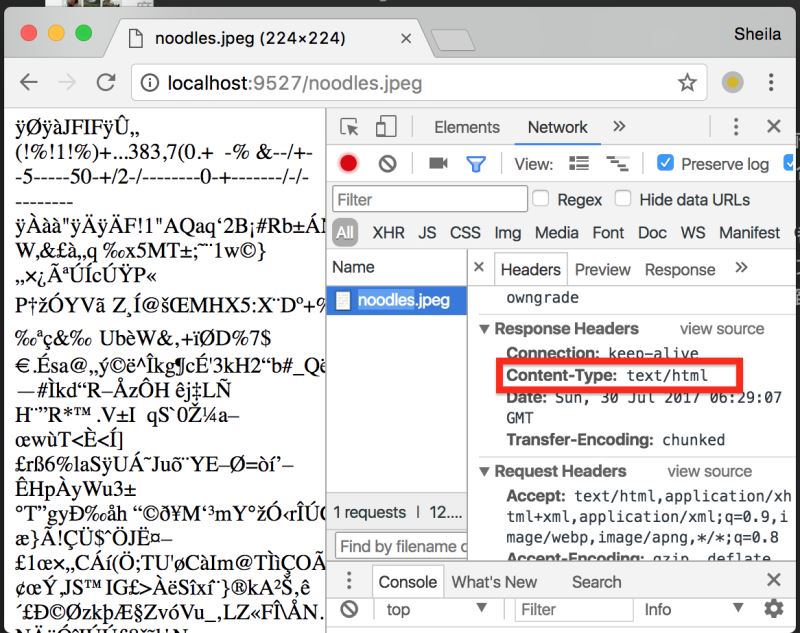
现在给客户端返回文件时,我们并没有指定Content-Type头,虽然你可能发现访问文本或图片浏览器都可以正确显示出文字或图片,但这并不符合规范。任何包含实体主体(entity body)的响应都应在头部指明文件类型,否则浏览器无从得知类型时,就会自行猜测(从文件内容以及url中寻找可能的扩展名)。响应如指定了错误的类型也会导致内容的错乱显示,如明明返回的是一张jpeg图片,却错误指定了header:'Content-Type': 'text/html',会收到一堆乱码。
虽然有现成的mime模块可用,这里还是自己来实现吧,试图对这个过程有更清晰的理解。
在根目录下创建mime.js文件:
const path = require('path');
const mimeTypes = {
"css": "text/css",
"gif": "image/gif",
"html": "text/html",
"ico": "image/x-icon",
"jpeg": "image/jpeg",
...
};
const lookup = (pathName) => {
let ext = path.extname(pathName);
ext = ext.split('.').pop();
return mimeTypes[ext] || mimeTypes['txt'];
}
module.exports = {
lookup
};
该模块暴露出一个lookup方法,可以根据路径名返回正确的类型,类型以‘type/subtype'表示。对于未知的类型,按普通文本处理。
接着在static-server.js中引入上面的mime模块,给返回文件的响应都加上正确的头部字段:
respondFile(pathName, req, res) {
const readStream = fs.createReadStream(pathName);
res.setHeader('Content-Type', mime.lookup(pathName));
readStream.pipe(res);
}
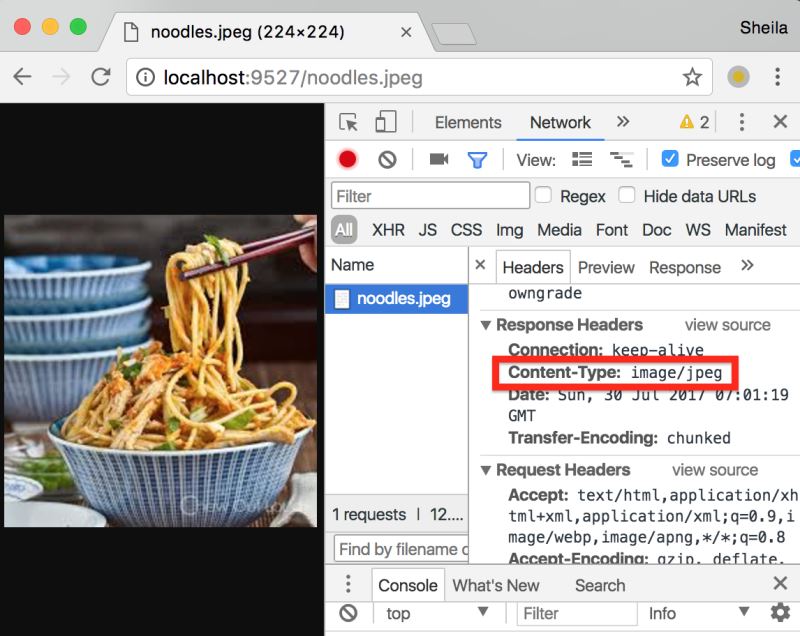
重新运行程序,会看到图片可以在浏览器中正常显示了。
Note:
需要注意的是,Content-Type说明的应是原始实体主体的文件类型。即使实体经过内容编码(如gzip,后面会提到),该字段说明的仍应是编码前的实体主体的类型。
添加其他功能
至此,已经完成了基本功能中列出的几个步骤,但依然有很多需要改进的地方,比如如果用户输入的url对应的是磁盘上的一个目录怎么办?还有,现在对于同一个文件(从未更改过)的多次请求,服务端都是勤勤恳恳地一遍遍地发送回同样的文件,这些冗余的数据传输,既消耗了带宽,也给服务器添加了负担。另外,服务器如果在发送内容之前能对其进行压缩,也有助于减少传输时间。
读取文件目录
现阶段,用url: localhost:9527/testfolder去访问一个指定root文件夹下真实存在的testfolder的文件夹,服务端会报错:
Error: EISDIR: illegal operation on a directory, read
要增添对目录访问的支持,我们重新整理下响应的步骤:
1.请求抵达时,首先判断url是否有尾部斜杠
2.如果有尾部斜杠,认为用户请求的是目录
- 如果目录存在
- 如果目录下存在默认页(如index.html),发送默认页
- 如果不存在默认页,发送目录下内容列表
- 如果目录不存在,返回404
3.如果没有尾部斜杠,认为用户请求的是文件
- 如果文件存在,发送文件
- 如果文件不存在,判断同名的目录是否存在
- 如果存在该目录,返回301,并在原url上添加上/作为要转到的location
- 如果不存在该目录,返回404
我们需要重写一下routeHandler内的逻辑:
routeHandler(pathName, req, res) {
fs.stat(pathName, (err, stat) => {
if (!err) {
const requestedPath = url.parse(req.url).pathname;
if (hasTrailingSlash(requestedPath) && stat.isDirectory()) {
this.respondDirectory(pathName, req, res);
} else if (stat.isDirectory()) {
this.respondRedirect(req, res);
} else {
this.respondFile(pathName, req, res);
}
} else {
this.respondNotFound(req, res);
}
});
}
继续补充respondRedirect方法:
respondRedirect(req, res) {
const location = req.url + '/';
res.writeHead(301, {
'Location': location,
'Content-Type': 'text/html'
});
res.end(`Redirecting to <a href='${location}'>${location}</a>`);
}
浏览器收到301响应时,会根据头部指定的location字段值,向服务器发出一个新的请求。
继续补充respondDirectory方法:
respondDirectory(pathName, req, res) {
const indexPagePath = path.join(pathName, this.indexPage);
if (fs.existsSync(indexPagePath)) {
this.respondFile(indexPagePath, req, res);
} else {
fs.readdir(pathName, (err, files) => {
if (err) {
res.writeHead(500);
return res.end(err);
}
const requestPath = url.parse(req.url).pathname;
let content = `<h1>Index of ${requestPath}</h1>`;
files.forEach(file => {
let itemLink = path.join(requestPath,file);
const stat = fs.statSync(path.join(pathName, file));
if (stat && stat.isDirectory()) {
itemLink = path.join(itemLink, '/');
}
content += `<p><a href='${itemLink}'>${file}</a></p>`;
});
res.writeHead(200, {
'Content-Type': 'text/html'
});
res.end(content);
});
}
}
当需要返回目录列表时,遍历所有内容,并为每项创建一个link,作为返回文档的一部分。需要注意的是,对于子目录的href,额外添加一个尾部斜杠,这样可以避免访问子目录时的又一次重定向。
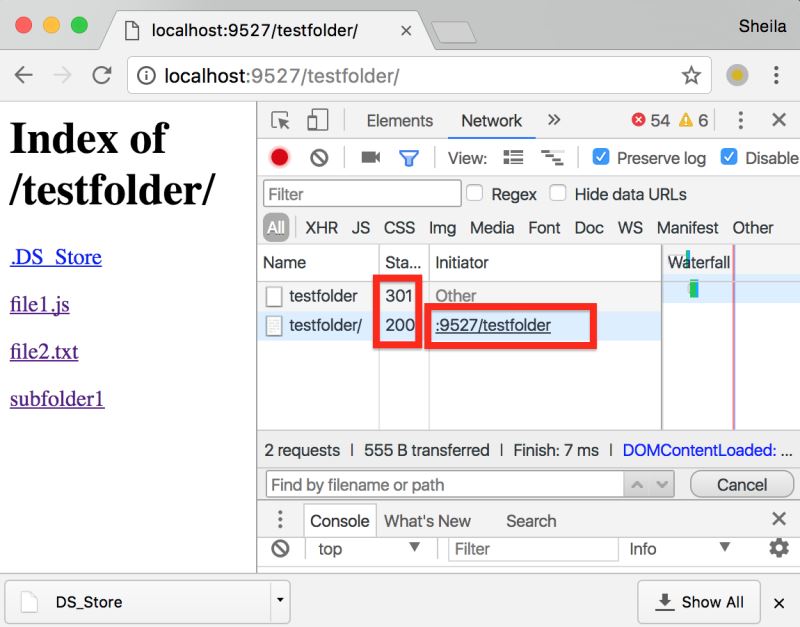
在浏览器中测试一下,输入localhost:9527/testfolder,指定的root目录下并没有名为testfolder的文件,却存在同名目录,因此第一次会收到重定向响应,并发起一个对目录的新请求。
缓存支持
为了减少数据传输,减少请求数,继续添加缓存支持。首先梳理一下缓存的处理流程:
1.如果是第一次访问,请求报文首部不会包含相关字段,服务端在发送文件前做如下处理:
- 如服务器支持ETag,设置ETag头
- 如服务器支持Last-Modified,设置Last-Modified头
- 设置Expires头
- 设置Cache-Control头(设置其max-age值)
- 浏览器收到响应后会存下这些标记,并在下次请求时带上与ETag对应的请求首部If-None-Match或与Last-Modified对应的请求首部If-Modified-Since。
2.如果是重复的请求:
浏览器判断缓存是否过期(通过Cache-Control和Expires确定)
如果未过期,直接使用缓存内容,也就是强缓存命中,并不会产生新的请求
如果已过期,会发起新的请求,并且请求会带上If-None-Match或If-Modified-Since,或者兼具两者
服务器收到请求,进行缓存的新鲜度再验证:
首先检查请求是否有If-None-Match首部,没有则继续下一步,有则将其值与文档的最新ETag匹配,失败则认为缓存不新鲜,成功则继续下一步
接着检查请求是否有If-Modified-Since首部,没有则保留上一步验证结果,有则将其值与文档最新修改时间比较验证,失败则认为缓存不新鲜,成功则认为缓存新鲜
当两个首部皆不存在或者验证结果是不新鲜时,发送200及最新文件,并在首部更新新鲜度。
当验证结果是缓存仍然新鲜时(也就是弱缓存命中),不需发送文件,仅发送304,并在首部更新新鲜度
为了能启用或关闭某种验证机制,我们在配置文件里增添如下配置项:
default.json:
{
...
"cacheControl": true,
"expires": true,
"etag": true,
"lastModified": true,
"maxAge": 5
}
这里为了能测试到缓存过期,将过期时间设成了非常小的5秒。
在StaticServer类中接收这些配置:
class StaticServer {
constructor() {
...
this.enableCacheControl = config.cacheControl;
this.enableExpires = config.expires;
this.enableETag = config.etag;
this.enableLastModified = config.lastModified;
this.maxAge = config.maxAge;
}
现在,我们要在原来的respondFile前横加一杠,增加是要返回304还是200的逻辑。
respond(pathName, req, res) {
fs.stat(pathName, (err, stat) => {
if (err) return respondError(err, res);
this.setFreshHeaders(stat, res);
if (this.isFresh(req.headers, res._headers)) {
this.responseNotModified(res);
} else {
this.responseFile(pathName, res);
}
});
}
准备返回文件前,根据配置,添加缓存相关的响应首部。
generateETag(stat) {
const mtime = stat.mtime.getTime().toString(16);
const size = stat.size.toString(16);
return `W/"${size}-${mtime}"`;
}
setFreshHeaders(stat, res) {
const lastModified = stat.mtime.toUTCString();
if (this.enableExpires) {
const expireTime = (new Date(Date.now() + this.maxAge * 1000)).toUTCString();
res.setHeader('Expires', expireTime);
}
if (this.enableCacheControl) {
res.setHeader('Cache-Control', `public, max-age=${this.maxAge}`);
}
if (this.enableLastModified) {
res.setHeader('Last-Modified', lastModified);
}
if (this.enableETag) {
res.setHeader('ETag', this.generateETag(stat));
}
}
需要注意的是,上面使用了ETag弱验证器,并不能保证缓存文件与服务器上的文件是完全一样的。关于强验证器如何实现,可以参考etag包的源码。
下面是如何判断缓存是否仍然新鲜:
isFresh(reqHeaders, resHeaders) {
const noneMatch = reqHeaders['if-none-match'];
const lastModified = reqHeaders['if-modified-since'];
if (!(noneMatch || lastModified)) return false;
if(noneMatch && (noneMatch !== resHeaders['etag'])) return false;
if(lastModified && lastModified !== resHeaders['last-modified']) return false;
return true;
}
需要注意的是,http首部字段名是不区分大小写的(但http method应该大写),所以平常在浏览器中会看到大写或小写的首部字段。

但是node的http模块将首部字段都转成了小写,这样在代码中使用起来更方便些。所以访问header要用小写,如reqHeaders['if-none-match']。不过,仍然可以用req.rawreq.rawHeaders来访问原headers,它是一个[name1, value1, name2, value2, ...]形式的数组。
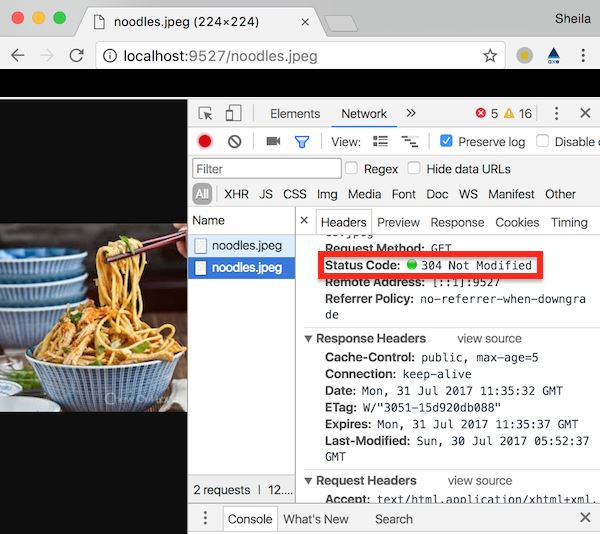
现在来测试一下,因为设置的缓存有效时间是极小的5s,所以强缓存几乎不会命中,所以第二次访问文件会发出新的请求,因为服务端文件并没做什么改变,所以会返回304。
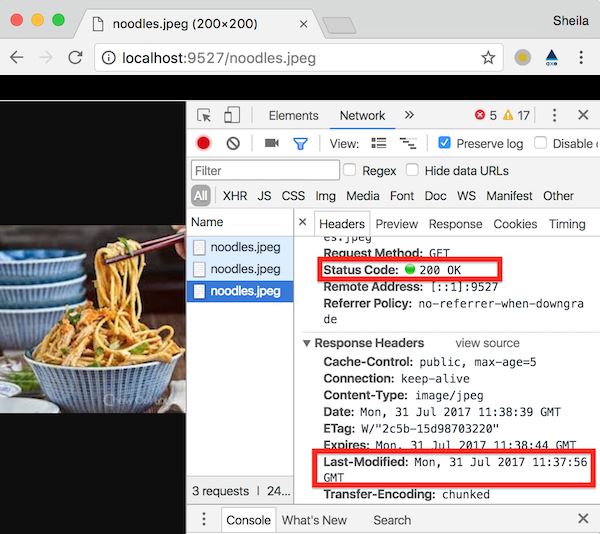
现在来修改一下请求的这张图片,比如修改一下size,目的是让服务端的再验证失败,因而必须给客户端发送200和最新的文件。
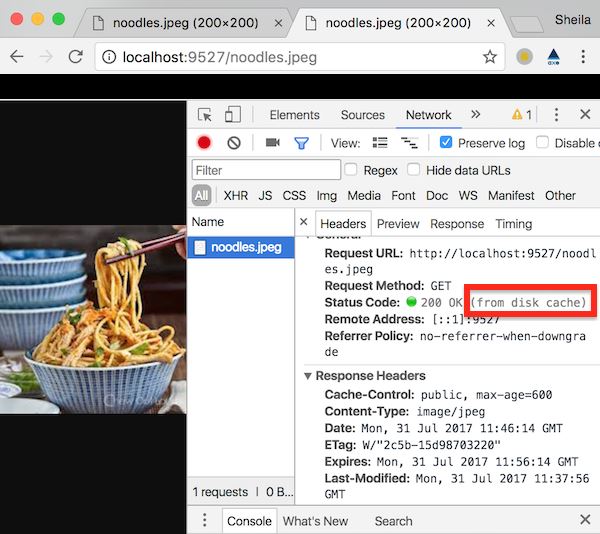
接下来把缓存有效时间改大一些,比如10分钟,那么在10分钟之内的重复请求,都会命中强缓存,浏览器不会向服务端发起新的请求(但network依然能观察到这条请求)。
内容编码
服务器在发送很大的文档之前,对其进行压缩,可以节省传输用时。其过程是:
浏览器在访问网站时,默认会携带Accept-Encoding头
服务器在收到请求后,如果发现存在Accept-Encoding请求头,并且支持该文件类型的压缩,压缩响应的实体主体(并不压缩头部),并附上Content-Encoding首部
浏览器收到响应,如果发现有Content-Encoding首部,按其值指定的格式解压报文
对于图片这类已经经过高度压缩的文件,无需再额外压缩。因此,我们需要配置一个字段,指明需要针对哪些类型的文件进行压缩。
default.json
{
...
"zipMatch": "^\\.(css|js|html)$"
}
static-server.js
constructor() {
...
this.zipMatch = new RegExp(config.zipMatch);
}
用zlib模块来实现流压缩:
compressHandler(readStream, req, res) { const acceptEncoding = req.headers['accept-encoding']; if (!acceptEncoding || !acceptEncoding.match(/\b(gzip|deflate)\b/)) { return readStream; } else if (acceptEncoding.match(/\bgzip\b/)) { res.setHeader('Content-Encoding', 'gzip'); return readStream.pipe(zlib.createGzip()); } else if (acceptEncoding.match(/\bdeflate\b/)) { res.setHeader('Content-Encoding', 'deflate'); return readStream.pipe(zlib.createDeflate()); } }
因为配置了图片不需压缩,在浏览器中测试会发现图片请求的响应中没有Content-Encoding头。
范围请求
最后一步,使服务器支持范围请求,允许客户端只请求文档的一部分。其流程是:
- 客户端向服务端发起请求
- 服务端响应,附上Accept-Ranges头(值表示表示范围的单位,通常是“bytes”),告诉客户端其接受范围请求
- 客户端发送新的请求,附上Ranges头,告诉服务端请求的是一个范围
- 服务端收到范围请求,分情况响应:
范围有效,服务端返回206 Partial Content,发送指定范围内内容,并在Content-Range头中指定该范围
范围无效,服务端返回416 Requested Range Not Satisfiable,并在Content-Range中指明可接受范围
请求中的Ranges头格式为(这里不考虑多范围请求了):
Ranges: bytes=[start]-[end]
其中 start 和 end 并不是必须同时具有:
如果 end 省略,服务器应返回从 start 位置开始之后的所有字节
如果 start 省略,end 值指的就是服务器该返回最后多少个字节
如果均未省略,则服务器返回 start 和 end 之间的字节
响应中的Content-Range头有两种格式:
当范围有效返回 206 时:
Content-Range: bytes (start)-(end)/(total)
当范围无效返回 416 时:
Content-Range: bytes */(total)
添加函数处理范围请求:
rangeHandler(pathName, rangeText, totalSize, res) {
const range = this.getRange(rangeText, totalSize);
if (range.start > totalSize || range.end > totalSize || range.start > range.end) {
res.statusCode = 416;
res.setHeader('Content-Range', `bytes */${totalSize}`);
res.end();
return null;
} else {
res.statusCode = 206;
res.setHeader('Content-Range', `bytes ${range.start}-${range.end}/${totalSize}`);
return fs.createReadStream(pathName, { start: range.start, end: range.end });
}
}
用 Postman来测试一下。在指定的root文件夹下创建一个测试文件:
testfile.js
This is a test sentence.
请求返回前六个字节 ”This “ 返回 206:
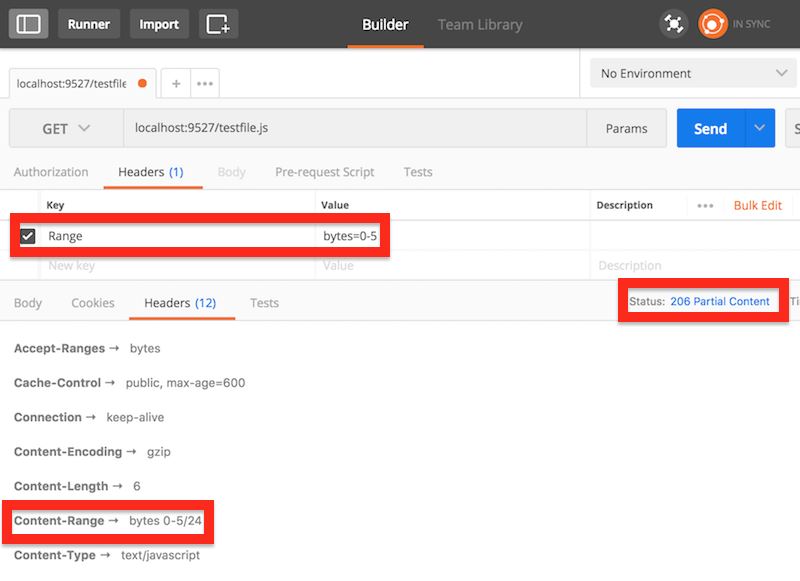
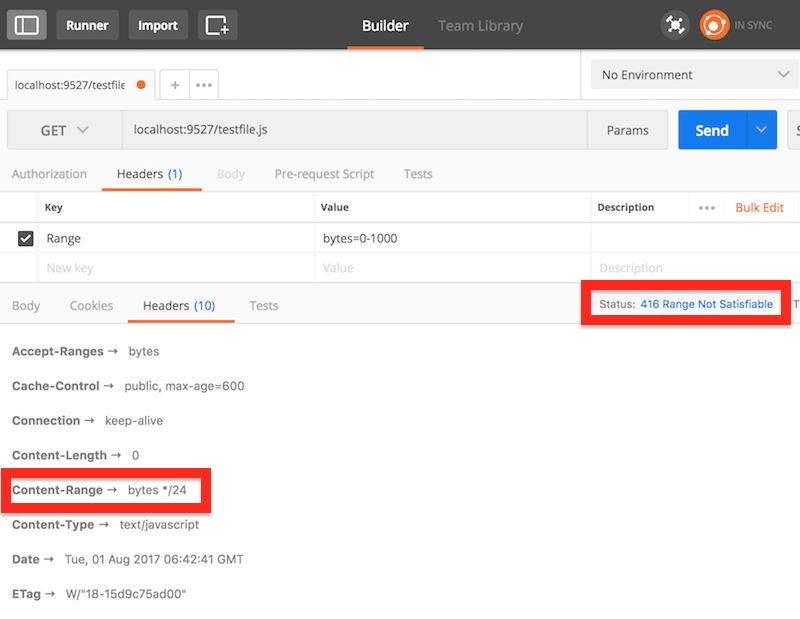
请求一个无效范围返回416:
读取命令行参数
至此,已经完成了静态服务器的基本功能。但是每一次需要修改配置,都必须修改default.json文件,非常不方便,如果能接受命令行参数就好了,可以借助 yargs 模块来完成。
var options = require( "yargs" )
.option( "p", { alias: "port", describe: "Port number", type: "number" } )
.option( "r", { alias: "root", describe: "Static resource directory", type: "string" } )
.option( "i", { alias: "index", describe: "Default page", type: "string" } )
.option( "c", { alias: "cachecontrol", default: true, describe: "Use Cache-Control", type: "boolean" } )
.option( "e", { alias: "expires", default: true, describe: "Use Expires", type: "boolean" } )
.option( "t", { alias: "etag", default: true, describe: "Use ETag", type: "boolean" } )
.option( "l", { alias: "lastmodified", default: true, describe: "Use Last-Modified", type: "boolean" } )
.option( "m", { alias: "maxage", describe: "Time a file should be cached for", type: "number" } )
.help()
.alias( "?", "help" )
.argv;
瞅瞅 help 命令会输出啥:
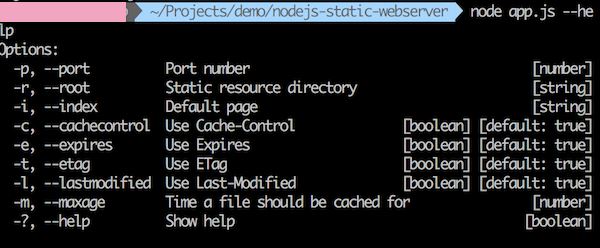
这样就可以在命令行传递端口、默认页等:
node app.js -p 8888 -i main.html
总结
以上所述是小编给大家介绍的使用Node.js搭建静态资源服务详细教程,希望对大家有所帮助,如果大家有任何疑问请给我留言,小编会及时回复大家的。在此也非常感谢大家对我们网站的支持!
相关推荐
-
Node.js 事件循环详解及实例
Node.js 事件循环详解及实例 Node.js 是单进程单线程应用程序,但是通过事件和回调支持并发,所以性能非常高. Node.js 的每一个 API 都是异步的,并作为一个独立线程运行,使用异步函数调用,并处理并发. Node.js 基本上所有的事件机制都是用设计模式中观察者模式实现. Node.js 单线程类似进入一个while(true)的事件循环,直到没有事件观察者退出,每个异步事件都生成一个事件观察者,如果有事件发生就调用该回调函数. Node.js 有多个内置的事件,我们可以
-
使用Node.js实现RESTful API的示例
RESTful基础概念 REST(Representational State Transfer)描述了一个架构样式的网络系统,它首次出现在 2000 年 Roy Fielding 的博士论文中.在REST服务中,应用程序状态和功能可以分为各种资源.资源向客户端公开,客户端可以对资源进行增删改操作.资源的例子有:应用程序对象.数据库记录.算法等等. REST通过抽象资源,提供了一个非常容易理解和使用的API,它使用 URI (Universal Resource Identifier) 唯一表示
-

利用node.js+mongodb如何搭建一个简单登录注册的功能详解
前言 最近突然对数据库和后台感兴趣了,就开始了漫长的学习之路,想想自己只是一个前端,只会java斯科瑞普,所以就开始看nodejs,看着看着突然发现mongodb和nodejs更配哦!,遂就开了我的mongodb之路.下面话不多说了,来一起看看详细的介绍吧. mongodb简介 就超简洁的说一下,mongo就是一个nosql的数据库,不使用sql的语法,当然其实也是大同小异的,增删改查还是差不多的,但是在概念上mongo还是跟mysql有相当大的区别的;比如在mongo中没有表的概念,而是一个集
-
Node.js REPL (交互式解释器)实例详解
Node.js REPL (交互式解释器)实例详解 Node.js REPL(Read Eval Print Loop:交互式解释器) 表示一个电脑的环境,类似 Window 系统的终端,我们可以在终端中输入命令,并接收系统的响应. Node 自带了交互式解释器,可以执行以下任务: 读取 - 读取用户输入,解析输入了Javascript 数据结构并存储在内存中. 执行 - 执行输入的数据结构 打印 - 输出结果 循环 - 循环操作以上步骤直到用户两次按下 ctrl-c 按钮退出. 多行表达式
-
Node.js 基础教程之全局对象
Node.js 基础教程之全局对象 在浏览器 JavaScript 中,通常 window 是全局对象. Node.js 中的全局对象是 global,所有全局变量(除了 global 本身以外)都是 global 对象的属性. global 最根本的作用是作为全局变量的宿主. 注意: 永远使用 var 定义变量以避免引入全局变量,因为全局变量会污染 命名空间,提高代码的耦合风险. __filename 脚本绝对路径 表示当前正在执行的脚本的文件名.它将输出文件所在位置的绝对路径,且和命令行参数
-
使用travis-ci如何持续部署node.js应用详解
前言 在开始之前,我们先来简单介绍下Travis-ci,Travis-ci是一款持续集成(Continuous Integration)服务,它能够很好地与Github结合,每当代码更新时自动地触发集成过程. Travis-ci配置简单,很多nodejs项目都用它做自动测试.然而,对于持续集成,仅做到自动测试是不够的,还要有后续的自动部署,才能完成"提交代码 => 自动测试 => 自动部署"的集成链条. 本文以nodejs应用为例,来谈谈如何利用travis-ci完成自动部
-
使用Node.js搭建静态资源服务详细教程
对于Node.js新手,搭建一个静态资源服务器是个不错的锻炼,从最简单的返回文件或错误开始,渐进增强,还可以逐步加深对http的理解.那就开始吧,让我们的双手沾满网络请求! Note: 当然在项目中如果有使用express框架,用express.static一行代码就可以达到目的了: app.use(express.static('public')) 这里我们要实现的正是express.static背后所做工作的一部分,建议同步阅读该模块源码. 基本功能 不急着写下第一行代码,而是先梳理一下就基
-
Node.js开发静态资源服务器
目录 正文 静态资源服务器 模块化 最后 正文 在09年Node.js出来后,让前端开发人员的开发路线变的不再那么单调,经过这么多年的发展,我们的开发基本已经离不开Node.js,不管是用作于工具类的开发,还是做完服务端的中间层,Node.js都占据了非常重要的地位,今天我们就一起通过原生的js+Node来实现一个简单的静态资源服务,如果你还不了解这方面的知识,那就跟我一起来学习吧! 静态资源服务器 Node.js经过这么多年的发展,已经有了很多很优秀的基础框架或类库,像express.js.K
-
零基础之Node.js搭建API服务器的详解
零基础之Node.js搭建API服务器 这篇文章写给那些Node.js零基础,但希望自己动手实现服务器API的前端开发者,尝试帮大家打开一扇门. HTTP服务器实现原理 HTTP服务器之所以能提供前端使用的API,其实现原理是服务器保持监听计算机的某个端口(通常是80),等待客户端请求,当请求到达并经过一系列处理后,服务器发送响应数据给到前端. 平时大家通过Ajax调用API,即是发起一次请求,经过服务器处理后,得到结果,然后再进行前端处理.如今使用高级编程语言,要实现服务器那部分功能已经变得非
-
Node.js创建一个Express服务的方法详解
本文实例讲述了Node.js创建一个Express服务的方法.分享给大家供大家参考,具体如下: 1.创建一个HttpServer服务端 在node.js官网下载好node的Windows版本后一路下一步安装好了node,新建一个server.js文件,开始第一个node文件.首先在文件开头需要使用require包含所需要的模块,然后利用http.createServer创建一个server,并执行回调函数.在回调函数内对请求req进行处理,并返回res结果. 利用url的parse方法将req请
-
使用Node.js搭建Web服务器
1. Node.js 创建的第一个应用 1.引入http模块 var http = require("http"); 2. 创建服务器 接下来我们使用 http.createServer() 方法创建服务器,并使用 listen 方法绑定 8888 端口.函数通过 request, response 参数来接收和响应数据. //1.引入 http 模块 var http=require('http'); //2.用 http 模块创建服务 http.createServer(funct
-
Node.js 与并发模型的详细介绍
目录 进程 线程 内核态线程 用户态线程 轻量级进程(LWP) 小结 协程 I/O 模型 阻塞 I/O 非阻塞 I/O 同(异)步 I/O Node.js 的并发模型 总结 前言: Node.js 现在已成为构建高并发网络应用服务工具箱中的一员,何以 Node.js 会成为大众的宠儿?本文将从进程.线程.协程.I/O 模型这些基本概念说起,为大家全面介绍关于 Node.js 与并发模型的这些事. 进程 我们一般将某个程序正在运行的实例称之为进程,它是操作系统进行资源分配和调度的一个基本单元,一般
-
Node.js 搭建后端服务器内置模块( http+url+querystring 的使用)
目录 前言 一.创建服务器 二.返回响应数据 返回复杂对象数据 返回html文档数据 三.设置响应头和状态码 四.实现路由接口 创建简易路由应用 五.处理URL URL格式转换 URL路径拼接 正确转换文件路径 转换为Options Url对象 六.跨域处理 后端设置跨域 jsonp接口 七.Node作为中间层使用 模拟get请求(转发跨域数据) 模拟post请求(服务器提交) 八.使用Node实现爬虫 前言 这一节我们去学习NodeJs的内置模块:http.url.querystring ,并
-
安装Node.js并启动本地服务的操作教程
1.下载安装包: 下载地址:https://nodejs.org/en/download/,根据自己电脑的配置下载相应的windows64位安装包,下载完成后,进行安装. 2.检查是否安装成功 安装完成后,打开命令行窗口,检查是否安装成功,如下图所示,键入node -v出现node.js的版本,键入npm -v出现npm的版本,说明两者均已安装成功. 3.配置环境变量 由于我的电脑之前安装过node.js,所以需要检测一下是否配置了环境变量,打开命令行,输入命令"path",输出结果中
-
使用node.js搭建服务器
使用node搭建小型服务器(其实就是分析url然后输出文件给客户端) 最近需要完成一个课程设计,被项目经理(组长)分配写界面,但是总觉得只写前端的话缺了点什么,所以想自己写下后端玩一下. 期间还稍微纠结了一下用什么语言,本来打算正好学习一下PHP,可后来转念一想,用nodejs岂不美哉,不仅了解了后台开发,也相当于巩固了js基础,一举两得,美滋滋. 在学习node的过程中,学到了使用node实现一个服务器这一块,感觉是对前面所学模块的一个很好的总结.用到了四个基本的模块fs stream htt
-
利用nginx搭建静态资源服务器的方法步骤
以windows为例,linux其实一样: 搭建静态资源服务器 我电脑上的work文件夹下面有很多图片,我想通过nginx搭建静态资源服务器,通过在地址栏输入ip+port的方式完成目录的映射 找到nginx安装目录,打开/conf/nginx.conf配置文件,添加一个虚拟主机 添加监听端口.访问域名 重点是添加location, 映射-URL:/work/; 注意:如果当前server模块中已有一个location且URL为"/",那么新建的location的url应为匹配路径,不