SqlServer 表单查询问题及解决方法
Q1:表StudentScores如下,用一条SQL语句查询出每门课都大于80分的学生姓名

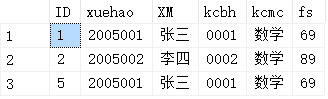
Q2:表DEMO_DELTE如下,删除除了自动编号不同,其他都相同的学生冗余信息
Q3:Team表如下,甲乙丙丁为四个球队,现在四个球对进行比赛,用一条sql语句显示所有可能的比赛组合

Q4:请考虑如下SQL语句在Microsoft SQL Server 引擎中的逻辑处理顺序
USE TSQLFundamentals2008 SELECT empid,YEAR(orderdate) AS orderyear,COUNT(*) numorders FROM Sales.Orders WHERE custid=71 GROUP BY empid,YEAR(orderdate) HAVING COUNT(*)>1 ORDER BY empid,orderyear
本篇文章将剖析一般查询过程中,涉及到的处理逻辑子句,主要包括FROM,WHERE,GROUP BY,HAVING,SELECT,ORDER BY,TOP,OVER等子句。
2 SELECT语句的元素
2.1 常规查询子句和逻辑处理顺序
对数据表进行检索查询时,查询语句一般包括FROM,WHERE,GROUP BY,HAVING,SELECT,ORDER BY,TOP,OVER等子句,请考虑如下例子的逻辑处理顺序。
USE TSQLFundamentals2008 SELECT empid,YEAR(orderdate) AS orderyear,COUNT(*) numorders FROM Sales.Orders WHERE custid=71 GROUP BY empid,YEAR(orderdate) HAVING COUNT(*)>1 ORDER BY empid,orderyear
如上代码,在SQL中逻辑处理顺序如下:
USE TSQLFundamentals2008 FROM Sales.Orders WHERE custid=71 GROUP BY empid,YEAR(orderdate) HAVING COUNT(*)>1 SELECT empid,YEAR(orderdate) AS orderyear,COUNT(*) numorders ORDER BY empid,orderyear
逻辑处理顺序可归结为如下:

注释:
a.在常规编程语言中,如c++,java,c#等,程序按照“从上往下”的顺序一步一步地执行,然而在SQL中,SELECT语句所处位置虽然在最开始,却不是在最先执行的;
b.逻辑处理顺序的每一步返回的结果集均是紧接着该步语句的下一步语句要执行的结果集;
c.FROM获取数据源(或者数据表),WHERE在FROM基础上过滤条件,GROUP BY在WHERE的基础上按照至少一列对集合进行分组,HAVING在GROUP BY基础上,对已经分组的集合进行过滤,SELECT语句在HAVING基础上检索,ORDER BY在SELECT基础上按照一定条件进行排序;
2.2 部分查询子句讲解
2.2.1 FROM子句
a.用数据库架构在限定代码中的对象名称,即使不用数据库架构限定,Sql Server也会隐式解析它,代价更高,初次之外,如果对象名相同,没有架构限定,会产生歧义;
b.FROM * 性能比 FROM conum_name性能低;
c.FROM查询得到的结果集顺序是随机的;
2.2.2 WHERE子句
a.过滤FROM阶段返回的行;
b.WHERE 谓词或逻辑表达式;
c.WHERE子句对查询性能有重要影响,在过滤表达式基础上,Sql Server会计算使用什么索引来访问请求的数据;
d.扫描整张表,返回所有可能的行,在客户端过滤,开销比较大,如产生大量的网络传输流量;
e.T-SQL使用三值谓词逻辑(true,false,unknown);
2.2.3 GROUP BY子句
a.GROUP BY阶段将上一阶段逻辑查询处理返回的行按“组”进行组合,每个组由在GROUP BY子句中指定的个元素决定;
b.如果查询语句中涉及到分组,那么GROUP BY阶段之后测所有阶段(包括HAVING、SELECT以及ORDER BY)的操作对象将是组,而不是单独的行。每个组最终表示为查询结果集中的一行;
c.GROUP BY阶段之后处理的子句中指定的所有表达式务必保证为每个组只返回一个标量(单值)。以GROUP BY列表中的元素为基础的表达式满足这一要求,因为按照定义,在每个组中GROUP BY元素只唯一出现一次;
d.聚合函数只为每个组返回一个值,所以一个元素如果不再GROUP BY列表中出现,就只能作为聚合函数(COUNT、SUM、AVG、MIN和MAX)的输入。(注意:若有GROUP BY子句,聚合函数只操作具体的每组,而非所有组);
e.所有聚合函数都会忽略NULL,但COUNT(*)除外;
f.在聚合函数中,可以使用distinct来处理非重复数,如count(distinct vary);
2.2.4 HAVING子句
a.HAVING子句用于指定对组进行过滤的谓词或逻辑表达式,这与WHERE阶段对单独的行进行过滤相对应;
b.因为HAVING子句是在对行进行分组后处理的,所以可以在逻辑表达式中引用聚合函数,如 HAVING COUNT(*)>1,意味着HAVING阶段过滤器只保留包含多行的组;
2.2.5 SELECT 子句
a.SELECT子句用于指定需要在查询返回的结果集中包含的属性(列);
b.SELECT子句返回列的名称类型:
直接基于正在查询的表的各个列三种方式定义别名,推荐使用AS。<表达式>AS<别名>;<别名>=<表达式>(别名 等号 表达式);<表达式> <别名>(表达式 空格 别名)没有名字的列
c.在关系模型中,所有操作和关系都基于关系代数和关系(集合)中的结果,但在SQL中,情况略有不同,因SELECT查询并不保证返回一个真正的集合(即,由唯一行组成的无序集合)。首先,SQL不要求表必须符合集合条件。SQL表可以没有键,行也不一定具有唯一性,在这些情况下表都不是集合,而是多集(multiset)或包(bag)。但即使正在查询的表具有主键、也符合集合的条件,针对这个表的SELECT查询任然可能返回包含重复的结果。在描述SELECT查询的输出时,经常会使用结果集这个属于,不过,结果集并不一定非得严格满足数学意义上的集合条件;
d.DISTINCT约束,确保行的唯一性,删除重复的行;
e.尽量不用SELECT * 形式查询所有列,而尽量用列明;
2.2.6 ORDER BY
a.理解SQL最重要的一点就是要明白表不保证是有序的,因为表是为了代表一个集合(如果有重复项,则是多集),而集合是无序的。这意味着,如果在查询表时不指定一个ORDER BY子句,那么虽然查询可以返回一个结果表,但SQL Server可以自由地按任意顺序对结果张的行进行排序;
b.在ORDRTB BY中使用ASC代表升序,DESC代表降序,默认情况是升序;
c.带有ORDER BY子句的查询会生成一种ANSI称之为游标(cursor)的结果(一种非关系结果,其中的行具有固定的顺序)。在SQL中的某些语言元素和运算预期只对查询的表结果进行处理,而不能处理游标,如表表达式和集合运算;
3 问题答案
Q1:KEY
--方法1 select distinct studentName from StudentScores where studentName not in ( select distinct studentName from StudentScores where courseGrades<=80 ) --方法2 select studentName from StudentScores group by studentName having min(courseGrades)>80
Q2:KEY
DELETE DEMO_DELTE WHERE ID NOT IN( SELECT min(ID) FROM DEMO_DELTE_2 GROUP BY xuehao,XM,kcbh,kcmc,fs)
Q3:KEY
SELECT team1.TeamName,team2.TeamName FROM Team team1,Team team2 WHERE team1.TeamName<team2.TeamName
Q4:KEY
参照第2章分析。
4 参考文献
【01】Microsoft SqlServer 2008技术内幕:T-SQL语言基础
【02】Microsoft SqlServer 2008技术内幕:T-SQL查询
【03】程序员的SQL经典
PS:下面给大家分享一段代码
sqlserver查询数据的所有表名和行数 //查询所有表明select name from sysobjects where xtype='u' select * from sys.tables//查询数据库中所有的表名及行数 SELECT a.name, b.rows FROM sysobjects AS a INNER JOIN sysindexes AS b ON a.id = b.id WHERE (a.type = 'u') AND (b.indid IN (0, 1)) ORDER BY a.name,b.rows DESC //查询所有的标明及空间占用量\行数 select object_name(id) tablename, 8*reserved/1024 reserved, rtrim(8*dpages)+'kb' used, 8*(reserved-dpages)/1024 unused, 8*dpages/1024-rows/1024*minlen/1024 free, rows --,* from sysindexes where indid=1 order by tablename,reserved desc
总结
以上所述是小编给大家介绍的SqlServer 表单查询问题及解决方法,希望对大家有所帮助,如果大家有任何疑问请给我留言,小编会及时回复大家的。在此也非常感谢大家对我们网站的支持!
如果你觉得本文对你有帮助,欢迎转载,烦请注明出处,谢谢!
相关推荐
-

SqlServer使用 case when 解决多条件模糊查询问题
我们在进行项目开发中,经常会遇到多条件模糊查询的需求.对此,我们常见的解决方案有两种:一是在程序端拼接SQL字符串,根据是否选择了某个条件,构造相应的SQL字符串:二是在数据库的存储过程中使用动态的SQL语句.其本质也是拼接SQL字符串,不过是从程序端转移到数据库端而已. 这两种方式的缺点是显而易见的:一是当多个条件每个都可为空时,要使用多个if语句进行判断:二是拼接的SQL语句容易产生SQL注入漏洞. 最近写数据库存储过程的时候经常使用case when 语句,正好可以用这个语句解决一下以上问
-
SqlServer查询和Kill进程死锁的语句
查询死锁进程语句 select request_session_id spid, OBJECT_NAME(resource_associated_entity_id) tableName from sys.dm_tran_locks where resource_type='OBJECT' 杀死死锁进程语句 kill spid 下面再给大家分享一段关于sqlserver检测死锁;杀死锁和进程;查看锁信息 --检测死锁 --如果发生死锁了,我们怎么去检测具体发生死锁的是哪条SQL语句或存储过程?
-
SqlServer 按时间段查询问题
百度的资料,保存下来: 在写按时间段查询的sql语句的时候 一般我们会这么写查询条件: where date>='2010-01-01' and date<='2010-10-1' 但是在实执行Sql时些语句会转换成这样: where date>='2010-01-01 0:00:00' and date<='2010-10-1:0:00:00',再看这个条件的话,也许就会有些明白, 那就是'2010-10-1 0:00:00' 之后的数据例如('2010-10-1:08:25:0
-
JavaScript生成SQL查询表单的方法
本文实例讲述了JavaScript生成SQL查询表单的方法.分享给大家供大家参考.具体如下: 这里使用JavaScript生成复杂的SQL查询表单,运行一下就明白了,它可以根据选择的查询条件,自动修改你的SQL语句,是一个很典型的应用. 运行效果截图如下: 具体代码如下: <!DOCTYPE html PUBLIC "-//W3C//DTD XHTML 1.0 Transitional//EN" "http://www.w3.org/TR/xhtml1/DTD/xhtm
-
SqlServer 表单查询问题及解决方法
Q1:表StudentScores如下,用一条SQL语句查询出每门课都大于80分的学生姓名 Q2:表DEMO_DELTE如下,删除除了自动编号不同,其他都相同的学生冗余信息 Q3:Team表如下,甲乙丙丁为四个球队,现在四个球对进行比赛,用一条sql语句显示所有可能的比赛组合 Q4:请考虑如下SQL语句在Microsoft SQL Server 引擎中的逻辑处理顺序 USE TSQLFundamentals2008 SELECT empid,YEAR(orderdate) AS orderyea
-
ThinkPHP下表单令牌错误与解决方法分析
本文实例讲述了ThinkPHP下表单令牌错误与解决方法.分享给大家供大家参考,具体如下: 在项目的开发过程中,添加.编辑数据时偶尔会遇到系统提示的"表单令牌错误",一开始没怎么在意,直到今天下午QA把此问题提到bug系统了,正好时间也有空余,就追着TP3.13的源码看了下去,几分钟后,便知道原委了. 在项目中开启表单令牌,通常要在配置文件中做如下配置 // 是否开启令牌验证 'TOKEN_ON' => true, // 令牌验证的表单隐藏字段名称 'TOKEN_NAME' =&g
-
js光标定位文本框回车表单提交问题的解决方法
本文实例讲述了js光标定位文本框回车表单提交问题的解决方法.分享给大家供大家参考.具体分析如下: 当光标定位在辅助查找的文本框后回车,页面会出现方法的返回的json串. 原因:When there is only one single-line text input field in a form, the user agent should accept Enter in that field as a request to submit the form. 翻译一下:当form中只有一个in
-
PHP+Session防止表单重复提交的解决方法
index.php 当前表单页面is_submit设为0 SESSION_START(); $_SESSION['is_submit'] = 0; <form id="reg" action="post.php" method="post"> <p>用户名:<input type="text" class="input" name="username" i
-
layui的面包屑或者表单不显示的解决方法
如下所示: 页面上显示空白 是因为加了hidden:让我们去查查官方文档 官方是这样描述的 当你使用表单时,Layui会对select.checkbox.radio等原始元素隐藏,从而进行美化修饰处理.但这需要依赖于form组件,所以你必须加载 form,并且执行一个实例.值得注意的是:导航的Hover效果.Tab选项卡等同理(它们需依赖 element 模块) layui.use('element', function(){ var element = layui.element; //导
-
使用mixins实现elementUI表单全局验证的解决方法
使用ElementUi搭建框架的时候,大家应该都有考虑过怎么做全局验证,毕竟复制粘贴什么的是最烦了,这里分享下个人的解决方法. 验证规则 分析规则 一般验证规则,主要是是否必填,不为空,以及参数类型的验证. 基于这个条件,我们开始找找思路, 单个字段的验证是这样的: name: { required: 是否必填, validator: 自定义规则, message: 失败提示消息(非自定义时触发), trigger: 触发方式 } 循环实现 固定的规则.当一个东西固定之后,那必然是可以重复使用的
-
php表单提交问题的解决方法
在此记录一下,以后不能在同一个地方摔倒了! 数据库为bbs,表为test.三个字段,分别为id,name,sex.id为auto_increment. 连接数据库的php文件conn.php内容为 复制代码 代码如下: $conn = @ mysql_connect("localhost", "root", "") or die("数据库链接错误"); mysql_select_db("bbs", $con
-
oracle表被锁定的完美解决方法
解决办法: ora-00031:session marked for kill处理oracle中杀不掉的锁一些ORACLE中的进程被杀掉后,状态被置为"killed",但是锁定的资源很长时间不释放,有时实在没办法,只好重启数据库.现在提供一种方法解决这种问题,那就是在ORACLE中杀不掉的,在OS一级再杀. 下面的语句用来查询哪些对象被锁: select object_name,machine,s.sid,s.serial# from v$locked_object l,dba_obj
-
Oracle数据库并行查询出错的解决方法
Oracle的并行查询是使用多个操作系统级别的Server Process来同时完成一个SQL查询,本文讲解Oracle数据库并行查询出错的解决方法如下: 1.错误描述 ORA-12801: 并行查询服务器P007中发出错误信号 ORA-01722:无效数字 12801.00000 -"error signaled in parallel query server %s" *Cause: A parallel query server reached an exception cond
-
Django admin.py 在修改/添加表单界面显示额外字段的方法
问题描述: 我有个blogextra表继承自blog,现在我想在blog的admin管理change界面显示对应的blogextra字段 解决方法: 可以使用admin.py的inline内联方法 代码: models.py from django.db import models # Create your models here. class Blog(models.Model): Name = models.CharField(max_length=350) def __unicode__