用Q-learning算法实现自动走迷宫机器人的方法示例
项目描述:

在该项目中,你将使用强化学习算法,实现一个自动走迷宫机器人。
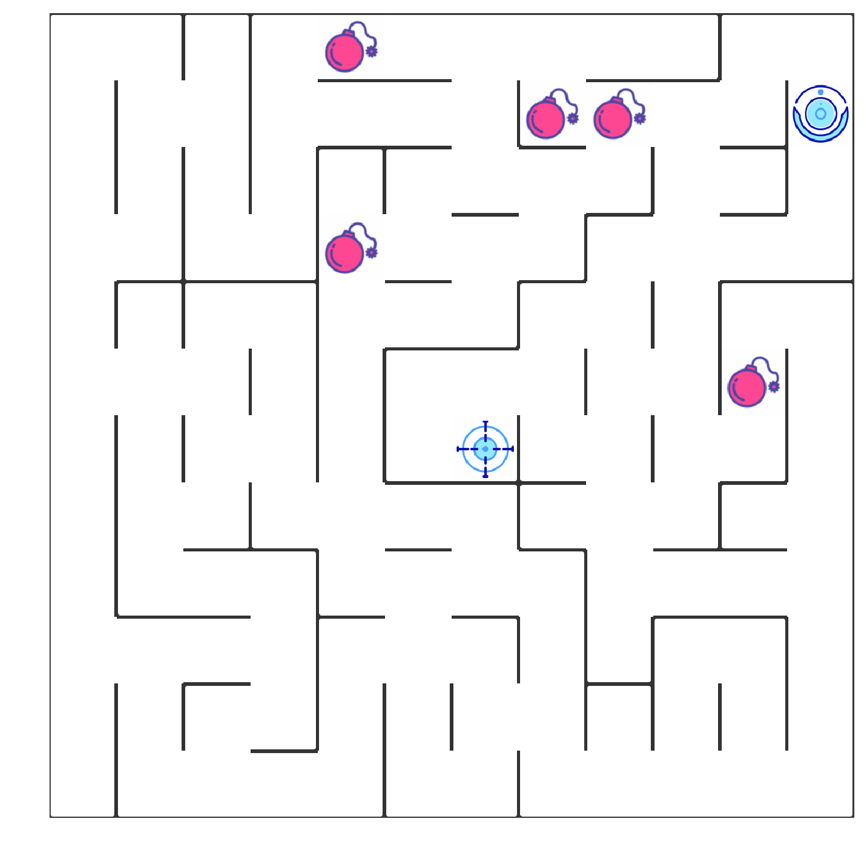
如上图所示,智能机器人显示在右上角。在我们的迷宫中,有陷阱(红色×××)及终点(蓝色的目标点)两种情景。机器人要尽量避开陷阱、尽快到达目的地。
小车可执行的动作包括:向上走 u、向右走 r、向下走 d、向左走l。
执行不同的动作后,根据不同的情况会获得不同的奖励,具体而言,有以下几种情况。
- 撞到墙壁:-10
- 走到终点:50
- 走到陷阱:-30
- 其余情况:-0.1
我们需要通过修改 robot.py 中的代码,来实现一个 Q Learning 机器人,实现上述的目标。
Section 1 算法理解
1.1 强化学习总览
强化学习作为机器学习算法的一种,其模式也是让智能体在“训练”中学到“经验”,以实现给定的任务。但不同于监督学习与非监督学习,在强化学习的框架中,我们更侧重通过智能体与环境的交互来学习。通常在监督学习和非监督学习任务中,智能体往往需要通过给定的训练集,辅之以既定的训练目标(如最小化损失函数),通过给定的学习算法来实现这一目标。然而在强化学习中,智能体则是通过其与环境交互得到的奖励进行学习。这个环境可以是虚拟的(如虚拟的迷宫),也可以是真实的(自动驾驶汽车在真实道路上收集数据)。
在强化学习中有五个核心组成部分,它们分别是:环境(Environment)、智能体(Agent)、状态(State)、动作(Action)和奖励(Reward)。在某一时间节点t:
智能体在从环境中感知其所处的状态
智能体根据某些准则选择动作 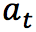
环境根据智能体选择的动作,向智能体反馈奖励 
通过合理的学习算法,智能体将在这样的问题设置下,成功学到一个在状态 选择动作 的策略 。
1.2 计算Q值
在我们的项目中,我们要实现基于 Q-Learning 的强化学习算法。Q-Learning 是一个值迭代(Value Iteration)算法。与策略迭代(Policy Iteration)算法不同,值迭代算法会计算每个”状态“或是”状态-动作“的值(Value)或是效用(Utility),然后在执行动作的时候,会设法最大化这个值。因此,对每个状态值的准确估计,是我们值迭代算法的核心。通常我们会考虑最大化动作的长期奖励,即不仅考虑当前动作带来的奖励,还会考虑动作长远的奖励。
在 Q-Learning 算法中,我们把这个长期奖励记为 Q 值,我们会考虑每个 ”状态-动作“ 的 Q 值,具体而言,它的计算公式为:

也就是对于当前的“状态-动作”  ,我们考虑执行动作
,我们考虑执行动作  后环境给我们的奖励
后环境给我们的奖励 ,以及执行动作
,以及执行动作  到达
到达  后,执行任意动作能够获得的最大的Q值
后,执行任意动作能够获得的最大的Q值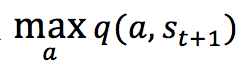 ,
,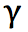 为折扣因子。
为折扣因子。
不过一般地,我们使用更为保守地更新 Q 表的方法,即引入松弛变量 alpha,按如下的公式进行更新,使得 Q 表的迭代变化更为平缓。
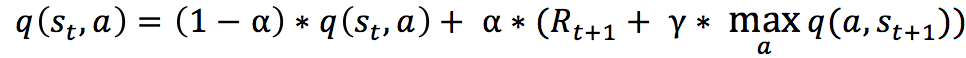

根据已知条件求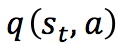 。
。
已知:如上图,机器人位于 s1,行动为 u,行动获得的奖励与题目的默认设置相同。在 s2 中执行各动作的 Q 值为:u: -24,r: -13,d: -0.29、l: +40,γ取0.9。
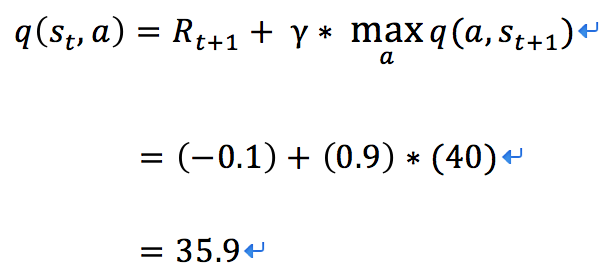
1.3 如何选择动作
在强化学习中,「探索-利用」问题是非常重要的问题。具体来说,根据上面的定义,我们会尽可能地让机器人在每次选择最优的决策,来最大化长期奖励。但是这样做有如下的弊端:
- 在初步的学习中,我们的 Q 值会不准确,如果在这个时候都按照 Q 值来选择,那么会造成错误。
- 学习一段时间后,机器人的路线会相对固定,则机器人无法对环境进行有效的探索。
因此我们需要一种办法,来解决如上的问题,增加机器人的探索。由此我们考虑使用 epsilon-greedy 算法,即在小车选择动作的时候,以一部分的概率随机选择动作,以一部分的概率按照最优的 Q 值选择动作。同时,这个选择随机动作的概率应当随着训练的过程逐步减小。
在如下的代码块中,实现 epsilon-greedy 算法的逻辑,并运行测试代码。
import random
import operator
actions = ['u','r','d','l']
qline = {'u':1.2, 'r':-2.1, 'd':-24.5, 'l':27}
epsilon = 0.3 # 以0.3的概率进行随机选择
def choose_action(epsilon):
action = None
if random.uniform(0,1.0) <= epsilon: # 以某一概率
action = random.choice(actions)# 实现对动作的随机选择
else:
action = max(qline.items(), key=operator.itemgetter(1))[0] # 否则选择具有最大 Q 值的动作
return action
range(100): res += choose_action(epsilon) print(res) res = '' for i in range(100): res += choose_action(epsilon) print(res) ldllrrllllrlldlldllllllllllddulldlllllldllllludlldllllluudllllllulllllllllllullullllllllldlulllllrlr
Section 2 代码实现
2.1 Maze 类理解
我们首先引入了迷宫类 Maze,这是一个非常强大的函数,它能够根据你的要求随机创建一个迷宫,或者根据指定的文件,读入一个迷宫地图信息。
- 使用
Maze("file_name")根据指定文件创建迷宫,或者使用Maze(maze_size=(height, width))来随机生成一个迷宫。 - 使用
trap number参数,在创建迷宫的时候,设定迷宫中陷阱的数量。 - 直接键入迷宫变量的名字按回车,展示迷宫图像(如
g=Maze("xx.txt"),那么直接输入g即可。 - 建议生成的迷宫尺寸,长在 6~12 之间,宽在 10~12 之间。
在如下的代码块中,创建你的迷宫并展示。
from Maze import Maze %matplotlib inline %confer InlineBackend.figure_format = 'retina' ## to-do: 创建迷宫并展示 g=Maze(maze_size=(6,8), trap_number=1) g Maze of size (12, 12 )
你可能已经注意到,在迷宫中我们已经默认放置了一个机器人。实际上,我们为迷宫配置了相应的 API,来帮助机器人的移动与感知。其中你随后会使用的两个 API 为 maze.sense_robot() 及 maze.move_robot() 。
maze.sense_robot()为一个无参数的函数,输出机器人在迷宫中目前的位置。maze.move_robot(direction)对输入的移动方向,移动机器人,并返回对应动作的奖励值。
随机移动机器人,并记录下获得的奖励,展示出机器人最后的位置。
rewards = [] ## 循环、随机移动机器人10次,记录下奖励 for i in range(10): res = g.move_robot(random. Choice(actions)) rewards.append(res) ## 输出机器人最后的位置 print(g.sense_robot()) ## 打印迷宫,观察机器人位置 g (0,9)
2.2 Robot 类实现
Robot 类是我们需要重点实现的部分。在这个类中,我们需要实现诸多功能,以使得我们成功实现一个强化学习智能体。总体来说,之前我们是人为地在环境中移动了机器人,但是现在通过实现 Robot 这个类,机器人将会自己移动。通过实现学习函数,Robot 类将会学习到如何选择最优的动作,并且更新强化学习中对应的参数。
首先 Robot 有多个输入,其中 alpha=0.5, gamma=0.9, epsilon0=0.5 表征强化学习相关的各个参数的默认值,这些在之前你已经了解到,Maze 应为机器人所在迷宫对象。
随后观察 Robot.update 函数,它指明了在每次执行动作时,Robot 需要执行的程序。按照这些程序,各个函数的功能也就明了了。
运行如下代码检查效果(记得将 maze 变量修改为你创建迷宫的变量名)。
import random
import operator
class Robot(object):
def __init__(self, maze, alpha=0.5, gamma=0.9, epsilon0=0.5):
self. Maze = maze
self.valid_actions = self.maze.valid_actions
self.state = None
self.action = None
# Set Parameters of the Learning Robot
self.alpha = alpha
self.gamma = gamma
self.epsilon0 = epsilon0
self. Epsilon = epsilon0
self.t = 0
self.Qtable = {}
self. Reset()
def. reset(self):
"""
Reset the robot
"""
self.state = self.sense_state()
self.create_Qtable_line(self.state)
def. set status(self, learning=False, testing=False):
"""
Determine whether the robot is learning its q table, or
executing the testing procedure.
"""
self. Learning = learning
self.testing = testing
def. update_parameter(self):
"""
Some of the paramters of the q learning robot can be altered,
update these parameters when necessary.
"""
if self.testing:
# TODO 1. No random choice when testing
self. Epsilon = 0
else:
# TODO 2. Update parameters when learning
self. Epsilon *= 0.95
return self. Epsilon
def. sense_state(self):
"""
Get the current state of the robot. In this
"""
# TODO 3. Return robot's current state
return self.maze.sense_robot()
def. create_Qtable_line(self, state):
"""
Create the qtable with the current state
"""
# TODO 4. Create qtable with current state
# Our qtable should be a two level dict,
# Qtable[state] ={'u':xx, 'd':xx, ...}
# If Qtable[state] already exits, then do
# not change it.
self.Qtable.setdefault(state, {a: 0.0 for a in self.valid_actions})
def. choose_action(self):
"""
Return an action according to given rules
"""
def. is_random_exploration():
# TODO 5. Return whether do random choice
# hint: generate a random number, and compare
# it with epsilon
return random.uniform(0, 1.0) <= self. Epsilon
if self. Learning:
if is_random_exploration():
# TODO 6. Return random choose aciton
return random. Choice(self.valid_actions)
else:
# TODO 7. Return action with highest q value
return max(self.Qtable[self.state].items(), key=operator.itemgetter(1))[0]
elif self.testing:
# TODO 7. choose action with highest q value
return max(self.Qtable[self.state].items(), key=operator.itemgetter(1))[0]
else:
# TODO 6. Return random choose aciton
return random. Choice(self.valid_actions)
def. update_Qtable(self, r, action, next_state):
"""
Update the qtable according to the given rule.
"""
if self. Learning:
# TODO 8. When learning, update the q table according
# to the given rules
self.Qtable[self.state][action] = (1 - self.alpha) * self.Qtable[self.state][action] + self.alpha * (
r + self.gamma * max(self.Qtable[next_state].values()))
def. update(self):
"""
Describle the procedure what to do when update the robot.
Called every time in every epoch in training or testing.
Return current action and reward.
"""
self.state = self.sense_state() # Get the current state
self.create_Qtable_line(self.state) # For the state, create q table line
action = self.choose_action() # choose action for this state
reward = self.maze.move_robot(action) # move robot for given action
next_state = self.sense_state() # get next state
self.create_Qtable_line(next_state) # create q table line for next state
if self. Learning and not self.testing:
self.update_Qtable(reward, action, next_state) # update q table
self.update_parameter() # update parameters
return action, reward
# from Robot import Robot
# g=Maze(maze_size=(6,12), trap_number=2)
g=Maze("test_world\maze_01.txt")
robot = Robot(g) # 记得将 maze 变量修改为你创建迷宫的变量名
robot.set_status(learning=True,testing=False)
print(robot.update())
g
('d', -0.1)
Maze of size (12, 12)
2.3 用 Runner 类训练 Robot
在完成了上述内容之后,我们就可以开始对我们 Robot 进行训练并调参了。我们准备了又一个非常棒的类 Runner ,来实现整个训练过程及可视化。使用如下的代码,你可以成功对机器人进行训练。并且你会在当前文件夹中生成一个名为 filename 的视频,记录了整个训练的过程。通过观察该视频,你能够发现训练过程中的问题,并且优化你的代码及参数。
尝试利用下列代码训练机器人,并进行调参。可选的参数包括:
- 训练参数
- 训练次数
epoch
- 训练次数
- 机器人参数:
epsilon0(epsilon 初值)epsilon衰减(可以是线性、指数衰减,可以调整衰减的速度),你需要在 Robot.py 中调整alphagamma
- 迷宫参数:
- 迷宫大小
- 迷宫中陷阱的数量
- 可选的参数:
- epoch = 20
- epsilon0 = 0.5
- alpha = 0.5
- gamma = 0.9
- maze_size = (6,8)
- trap_number = 2
from Runner import Runner g = Maze(maze_size=maze_size,trap_number=trap_number) r = Robot(g,alpha=alpha, epsilon0=epsilon0, gamma=gamma) r.set_status(learning=True) runner = Runner(r, g) runner.run_training(epoch, display_direction=True) #runner.generate_movie(filename = "final1.mp4") # 你可以注释该行代码,加快运行速度,不过你就无法观察到视频了。 g

使用 runner.plot_results() 函数,能够打印机器人在训练过程中的一些参数信息。
- Success Times 代表机器人在训练过程中成功的累计次数,这应当是一个累积递增的图像。
- Accumulated Rewards 代表机器人在每次训练 epoch 中,获得的累积奖励的值,这应当是一个逐步递增的图像。
- Running Times per Epoch 代表在每次训练 epoch 中,小车训练的次数(到达终点就会停止该 epoch 转入下次训练),这应当是一个逐步递减的图像。
使用 runner.plot_results() 输出训练结果
runner.plot_results()

以上就是本文的全部内容,希望对大家的学习有所帮助,也希望大家多多支持我们。
相关推荐
-

Python使用回溯法子集树模板解决迷宫问题示例
本文实例讲述了Python使用回溯法解决迷宫问题.分享给大家供大家参考,具体如下: 问题 给定一个迷宫,入口已知.问是否有路径从入口到出口,若有则输出一条这样的路径.注意移动可以从上.下.左.右.上左.上右.下左.下右八个方向进行.迷宫输入0表示可走,输入1表示墙.为方便起见,用1将迷宫围起来避免边界问题. 分析 考虑到左.右是相对的,因此修改为:北.东北.东.东南.南.西南.西.西北八个方向.在任意一格内,有8个方向可以选择,亦即8种状态可选.因此从入口格子开始,每进入一格都要遍历这8种状态.
-
一道python走迷宫算法题
前几天逛博客时看到了这样一道问题,感觉比较有趣,就自己思考了下方案顺便用python实现了一下.题目如下: 用一个二维数组表示一个简单的迷宫,用0表示通路,用1表示阻断,老鼠在每个点上可以移动相邻的东南西北四个点,设计一个算法,模拟老鼠走迷宫,找到从入口到出口的一条路径. 如图所示: 先说下我的思路吧: 1.首先用一个列表source存储迷宫图,一个列表route_stack存储路线图,一个列表route_history存储走过的点,起点(0,0),终点(4,4). 2.老鼠在每个点都有上下左右
-
Python基于递归算法实现的走迷宫问题
本文实例讲述了Python基于递归算法实现的走迷宫问题.分享给大家供大家参考,具体如下: 什么是递归? 简单地理解就是函数调用自身的过程就称之为递归. 什么时候用到递归? 如果一个问题可以表示为更小规模的迭代运算,就可以使用递归算法. 迷宫问题:一个由0或1构成的二维数组中,假设1是可以移动到的点,0是不能移动到的点,如何从数组中间一个值为1的点出发,每一只能朝上下左右四个方向移动一个单位,当移动到二维数组的边缘,即可得到问题的解,类似的问题都可以称为迷宫问题. 在python中可以使用list
-
用Python代码来解图片迷宫的方法整理
译注:原文是StackOverflow上一个如何用程序读取迷宫图片并求解的问题,几位参与者热烈地讨论并给出了自己的代码,涉及到用Python对图片的处理以及广度优先(BFS)算法等. 问题by Whymarrh: 当给定上面那样一张JPEG图片,如何才能更好地将这张图转换为合适的数据结构并且解出这个迷宫? 我的第一直觉是将这张图按像素逐个读入,并存储在一个包含布尔类型元素的列表或数组中,其中True代表白色像素,False代表非白色像素(或彩色可以被处理成二值图像).但是这种做法存在一个问题,那
-
Python深度优先算法生成迷宫
本文实例为大家分享了Python深度优先算法生成迷宫,供大家参考,具体内容如下 import random #warning: x and y confusing sx = 10 sy = 10 dfs = [[0 for col in range(sx)] for row in range(sy)] maze = [[' ' for col in range(2*sx+1)] for row in range(2*sy+1)] #1:up 2:down 3:left 4:right opera
-
python实现的生成随机迷宫算法核心代码分享(含游戏完整代码)
完整代码下载:http://xiazai.jb51.net/201407/tools/python-migong.rar 最近研究了下迷宫的生成算法,然后做了个简单的在线迷宫游戏.游戏地址和对应的开源项目地址可以通过上面的链接找到.开源项目中没有包含服务端的代码,因为服务端的代码实在太简单了.下面将简单的介绍下随机迷宫的生成算法.一旦理解后你会发现这个算法到底有多简单. 1.将迷宫地图分成多个房间,每个房间都有四面墙. 2.让"人"从地图任意一点A出发,开始在迷宫里游荡.从A房间的1/
-
Python基于分水岭算法解决走迷宫游戏示例
本文实例讲述了Python基于分水岭算法解决走迷宫游戏.分享给大家供大家参考,具体如下: #Solving maze with morphological transformation """ usage:Solving maze with morphological transformation needed module:cv2/numpy/sys ref: 1.http://www.mazegenerator.net/ 2.http://blog.leanote.com
-
Python解决走迷宫问题算法示例
本文实例讲述了Python解决走迷宫问题算法.分享给大家供大家参考,具体如下: 问题: 输入n * m 的二维数组 表示一个迷宫 数字0表示障碍 1表示能通行 移动到相邻单元格用1步 思路: 深度优先遍历,到达每一个点,记录从起点到达每一个点的最短步数 初始化案例: 1 1 0 1 1 1 0 1 1 1 1 0 1 0 0 1 0 1 1 1 1 1 1 0 1 1 1 1 1 1 1 把图周围加上
-
Python使用Tkinter实现机器人走迷宫
这本是课程的一个作业研究搜索算法,当时研究了一下Tkinter,然后写了个很简单的机器人走迷宫的界面,并且使用了各种搜索算法来进行搜索,如下图: 使用A*寻找最优路径: 由于时间关系,不分析了,我自己贴代码吧.希望对一些也要用Tkinter的人有帮助. from Tkinter import * from random import * import time import numpy as np import util class Directions: NORTH = 'North' SOU
-
用Q-learning算法实现自动走迷宫机器人的方法示例
项目描述: 在该项目中,你将使用强化学习算法,实现一个自动走迷宫机器人. 如上图所示,智能机器人显示在右上角.在我们的迷宫中,有陷阱(红色×××)及终点(蓝色的目标点)两种情景.机器人要尽量避开陷阱.尽快到达目的地. 小车可执行的动作包括:向上走 u.向右走 r.向下走 d.向左走l. 执行不同的动作后,根据不同的情况会获得不同的奖励,具体而言,有以下几种情况. 撞到墙壁:-10 走到终点:50 走到陷阱:-30 其余情况:-0.1 我们需要通过修改 robot.py 中的代码,来实现一个 Q
-
Java实现可视化走迷宫小游戏的示例代码
目录 效果图 数据层 视图层 控制层 效果图 数据层 本实例需要从 .txt 文件中读取迷宫并绘制,所以先来实现文件读取IO类 MazeData.java,该程序在构造函数运行时将外部文件读入,并完成迷宫各种参数的初始化,注意规定了外部 .txt 文件的第一行两个数字分别代表迷宫的行数和列数.此外还提供了各类接口来读取或操作私有数据. import java.io.BufferedInputStream; import java.io.File; import java.io.FileInput
-
shell 脚本自动搭建nfs服务的方法示例
本文介绍了shell 脚本自动搭建nfs服务的方法示例,分享给大家,具体如下: #vim /sh/zidong_dajian_nfs_fuwu.sh #!/bin/bash #name:zidong_dajian_nfs_fuwu.sh #path:/sh/ #update:2017-9-17 #测试网络是否通畅 ping -c 1 172.16.13.254 >/dev/null && echo **********网络ok********** #第一步:关闭selinux和防火墙
-
Vue自动构建发布脚本的方法示例
简介 使用cross-env, scp2两个插件完成 cross-env cross-env这是一款运行跨平台设置和使用环境变量的脚本. 为什么需要cross-env? NODE_ENV=production 像这样设置环境变量时,大多数Windows命令提示符都会阻塞 .(Windows上的Bash是例外,它使用本机Bash.)同样,Windows和POSIX命令使用环境变量的方式也有所不同.对于POSIX,您可以使用: $ENV_VAR 和在Windows上可以使用 %ENV_VAR% .
-
jQuery实现滚动到底部时自动加载更多的方法示例
本文实例讲述了jQuery实现滚动到底部时自动加载更多的方法.分享给大家供大家参考,具体如下: 这里利用AJAX,实现滚动到底加载数据功能: <!DOCTYPE html> <html xmlns="http://www.w3.org/1999/xhtml"> <head runat="server"> <meta http-equiv="Content-Type" content="text/
-
Python cookbook(数据结构与算法)从字典中提取子集的方法示例
本文实例讲述了Python从字典中提取子集的方法.分享给大家供大家参考,具体如下: 问题:想创建一个字典,其本身是另一个字典的子集 解决方案:利用字典推导式(dictionary comprehension)可轻松解决 # example of extracting a subset from a dictionary from pprint import pprint prices = { 'ACME': 45.23, 'AAPL': 612.78, 'IBM': 205.55, 'HPQ':
-
Python实现发票自动校核微信机器人的方法
制作初衷: 外地开了票到公司后发现信息有错误,无法报销: 公司的行政和财务经常在工作日被问及公司开票信息,影响心情和工作: 引入相应的专业APP来解决发票问题对于一般公司成本较高: 看到朋友孟要早睡写过脚本来解决这个问题,但因为公司场景不相同,无法复用,所以新写了一个 本代码使用简单的封装方法,并做了比较走心的注释,希望能给初学Python的小伙伴提供一些灵感,也能让有实际需求的人可以快速修改.使用. 源码地址:https://github.com/yc2code/WechatInvoicePa
-
python自动生成证件号的方法示例
前言 在跟进需求的时候,往往涉及到测试,特别是需要用到身份信息的时候,总绕不开身份证号码这个话题.之前在跟一个互联网产品的时候,需要很多身份证做测试,又不想装太多软件自动生成(有需要的小伙伴可自行搜索身份证号码自动生成软件),按照身份证规则现编也比较浪费时间,在处理身份数据时,Python就非常有用了. 方法示例如下 # Author:BeeLe # -*-coding:utf-8-*- # 生成身份证号码主程序 import urllib.request import requests fro
-
Android App实现应用内部自动更新的最基本方法示例
这只是初步的实现,并没有加入自动编译等功能.需要手动更改更新的xml文件和最新的apk. 共涉及到四个文件! 一.客户端 AndroidUpdateTestActivity:程序首页 main.xml:首页布局 Update:更新类 softupdate_progress:更新等待界面 Updage package majier.test; import java.io.File; import java.io.FileOutputStream; import java.io.IOExce
-
Asp.net core中实现自动更新的Option的方法示例
Asp.net core可以监视json.xml等配置文件的变化, 自动刷新内存中的配置内容, 但如果想每隔1秒从zookeeper.consul获取最新的配置信息, 需要自己实现. 阅读了 Asp.net core Document的Custom configuration provider, 得知只需要实现自己的IConfigurationSource和对应ConfigurationProvider即可 在这个示例中, 我建立了一个简单的option, 只包含一个不断变化的计数器变量. pu