Node.js爬取豆瓣数据实例分析
一直自以为自己vue还可以,一直自以为webpack还可以,今天在慕课逛node的时候,才发现,自己还差的很远。众所周知,vue-cli基于webpack,而webpack基于node,对node不了解,谈什么了解webpack。所以就自己给自己出了一道题,爬取豆瓣数据,目前还处于初级阶段。今天就浅谈爬取到豆瓣的数据,再另一个页面用自己的方式展现,后续会跟进。
1、需要解决的问题
- 搭建服务
- 怎么处理爬到的数据
- 怎么自动打开默认浏览器
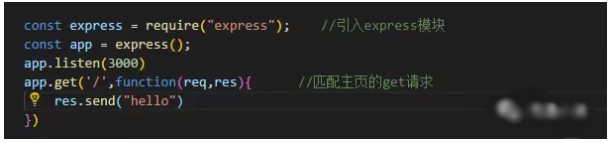
2、搭建服务
搭建服务有好几种方式,一开始我用的http,但是http有个弊端就是不能解析https协议的url,所以就用了express,解析https协议的网址我用了request包,豆瓣的网址是https的,
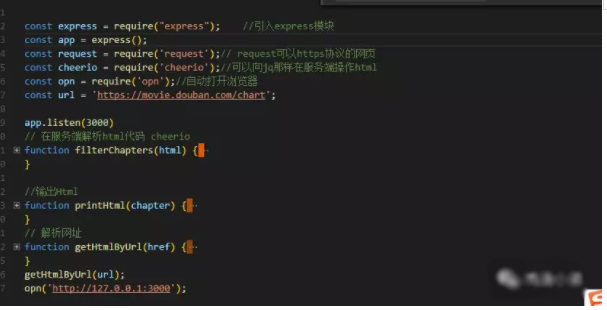
今天爬取的是https://movie.douban.com/chart这个网址;如下图,我要获取的有三个部分,图片、电影名字、电影链接.

3、怎么处理爬到的数据
我们用request爬到的数据,怎么处理呢?cheerio包可以让我们像Jq那样处理爬到的html数据。
①、首先解析数据,取到爬取网页的html数据;

②、然后利用cheerio包操作爬到的数据,取到你想要的数据。

③、取到数据,创建html,输出到页面。如下图,我用的字符串拼接,办法有点笨,还没有找到更好的办法。

4、怎么自动打开默认浏览器
不知道你有没有看vue-cli中webpack的配置,自动打开浏览器,vue-cli用的opn包.

这个包用起来很方便,引入包,直接调用opn(url)即可;
5、展示

您可能感兴趣的文章:
- Node.js 利用cheerio制作简单的网页爬虫示例
- 浅谈Node.js爬虫之网页请求模块
- 使用 Node.js 开发资讯爬虫流程
- Node.js+jade+mongodb+mongoose实现爬虫分离入库与生成静态文件的方法
- 基于node.js制作简单爬虫教程
- 利用node.js写一个爬取知乎妹纸图的小爬虫
- node.js爬虫爬取拉勾网职位信息
- 从零学习node.js之简易的网络爬虫(四)
- Node.js 实现简单小说爬虫实例
- node.js实现博客小爬虫的实例代码
相关推荐
-

利用node.js写一个爬取知乎妹纸图的小爬虫
前言 说起写node爬虫的原因,真是羞羞呀.一天,和往常一样,晚上吃过饭便刷起知乎来,首页便是推荐的你见过最漂亮的女生长什么样?,点进去各种漂亮的妹纸爆照啊!!!,看的我好想把这些好看的妹纸照片都存下来啊!一张张点击保存,就在第18张得时候,突然想起.我特么不是程序员么,这种手动草做的事,怎么能做,不行我不能丢程序员的脸了,于是便开始这次爬虫之旅. 原理 初入爬虫的坑,没有太多深奥的理论知识,要获取知乎上帖子中的一张图片,我把它归结为以下几步. 准备一个url(当然是诸如你见过最漂亮的女生长什么
-
基于node.js制作简单爬虫教程
前言:最近想学习node.js,突然在网上看到基于node的爬虫制作教程,所以简单学习了一下,把这篇文章分享给同样初学node.js的朋友. 目标:爬取 http://tweixin.yueyishujia.com/webapp/build/html/ 网站的所有门店发型师的基本信息. 思路:访问上述网站,通过chrome浏览器的network对网页内容分析,找到获取各个门店发型师的接口,对参数及返回数据进行分析,遍历所有门店的所有发型师,直到遍历完毕,同事将信息存储到本地. 步骤一:安装nod
-
node.js爬虫爬取拉勾网职位信息
简介 用node.js写了一个简单的小爬虫,用来爬取拉勾网上的招聘信息,共爬取了北京.上海.广州.深圳.杭州.西安.成都7个城市的数据,分别以前端.PHP.java.c++.python.Android.ios作为关键词进行爬取,爬到的数据以json格式储存到本地,为了方便观察,我将数据整理了一下供大家参考 数据结果 上述数据为3月13日22时爬取的数据,可大致反映各个城市对不同语言的需求量. 爬取过程展示 控制并发进行爬取 爬取到的数据文件 json数据文件 爬虫程序 实现思路 请求拉钩网的
-
Node.js 利用cheerio制作简单的网页爬虫示例
本文介绍了Node.js 利用cheerio制作简单的网页爬虫示例,分享给大家,具有如下: 1. 目标 完成对网站的标题信息获取 将获取到的信息输出在一个新文件 工具: cheerio,使用npm下载npm install cheerio cheerio的API使用方法和jQuery的使用方法基本一致 如果熟练使用jQuery,那么cheerio将会很快上手 2. 代码部分 介绍: 获取segment fault页面的列表标题,将获取到的标题列表编号,最终输出到pageTitle.txt文件里
-
从零学习node.js之简易的网络爬虫(四)
前言 之前已经介绍了node.js的一些基本知识,下面这篇文章我们的目标是学习完本节课程后,能进行网页简单的分析与抓取,对抓取到的信息进行输出和文本保存. 爬虫的思路很简单: 确定要抓取的URL: 对URL进行抓取,获取网页内容: 对内容进行分析并存储: 重复第1步 在这节里做爬虫,我们使用到了两个重要的模块: request : 对http进行封装,提供更多.更方便的接口供我们使用,request进行的是异步请求.更多信息可以去这篇文章上进行查看 cheerio : 类似于jQuery,可以使
-
node.js实现博客小爬虫的实例代码
前言 爬虫,是一种自动获取网页内容的程序.是搜索引擎的重要组成部分,因此搜索引擎优化很大程度上就是针对爬虫而做出的优化. 这篇文章介绍的是利用node.js实现博客小爬虫,核心的注释我都标注好了,可以自行理解,只需修改url和按照要趴的博客内部dom构造改一下filterchapters和filterchapters1就行了! 下面话不多说,直接来看实例代码 var http=require('http'); var Promise=require('Bluebird'); var cheeri
-
Node.js+jade+mongodb+mongoose实现爬虫分离入库与生成静态文件的方法
接着这篇文章Node.js+jade抓取博客所有文章生成静态html文件的实例继续,在这篇文章中实现了采集与静态文件的生成,在实际的采集项目中, 应该是先入库再选择性的生成静态文件. 那么我选择的数据库是mongodb,为什么用这个数据库,因为这个数据库是基于集合,数据的操作基本是json,与dom模块cheerio具有非常大的亲和力,cheerio处理过滤出来的数据,可以直接插入mongodb,不需要经过任何的处理,非常的便捷,当然跟node.js的亲和力那就不用说了,更重要的是,性能很棒.这
-
浅谈Node.js爬虫之网页请求模块
本文介绍了Node.js爬虫之网页请求模块,分享给大家,具体如下: 注:如您下载最新的nodegrass版本,由于部分方法已经更新,本文的例子已经不再适应,详细请查看开源地址中的例子. 一.为什么我要写这样一个模块? 源于笔者想使用Node.js写一个爬虫,虽然Node.js官方API提供的请求远程资源的方法已经非常简便,具体参考 http://nodejs.org/api/http.html 其中对于Http的请求提供了,http.get(options, callback)和http.req
-
Node.js 实现简单小说爬虫实例
最近因为剧荒,老大追了爱奇艺的一部网剧,由丁墨的同名小说<美人为馅>改编,目前已经放出两季,虽然整部剧槽点满满,但是老大看得不亦乐乎,并且在看完第二季之后跟我要小说资源,直接要奔原著去看结局-- 随手搜了下,都是在线资源,下载的话需要登录,注册登录好麻烦,写个爬虫玩玩也好,于是动手用 node 写了一个,这里做下笔记 工作流程 获取 URLs 列表(请求资源 request模块) 根据 URLs 列表获取相关页面源码(可能遇到页面编码问题,iconv-lite模块) 源码解析,获取小说信息(
-
使用 Node.js 开发资讯爬虫流程
最近项目需要一些资讯,因为项目是用 Node.js 来写的,所以就自然地用 Node.js 来写爬虫了 项目地址:github.com/mrtanweijie-,项目里面爬取了 Readhub . 开源中国 . 开发者头条 . 36Kr 这几个网站的资讯内容,暂时没有对多页面进行处理,因为每天爬虫都会跑一次,现在每次获取到最新的就可以满足需求了,后期再进行完善 爬虫流程概括下来就是把目标网站的HTML下载到本地再进行数据提取. 一.下载页面 Node.js 有很多http请求库,这里使用 req