python3写爬取B站视频弹幕功能
需要准备的环境:
一个B站账号,需要先登录,否则不能查看历史弹幕记录
联网的电脑和顺手的浏览器,我用的Chrome
Python3环境以及request模块,安装使用命令,换源比较快:
pip3 install request -i http://pypi.douban.com/simple
爬取步骤: 登录后打开需要爬取的视频页面,打开开发者工具台,Chrome可以使用F12快捷键,选择network监听请求
点击查看历史弹幕,获取请求
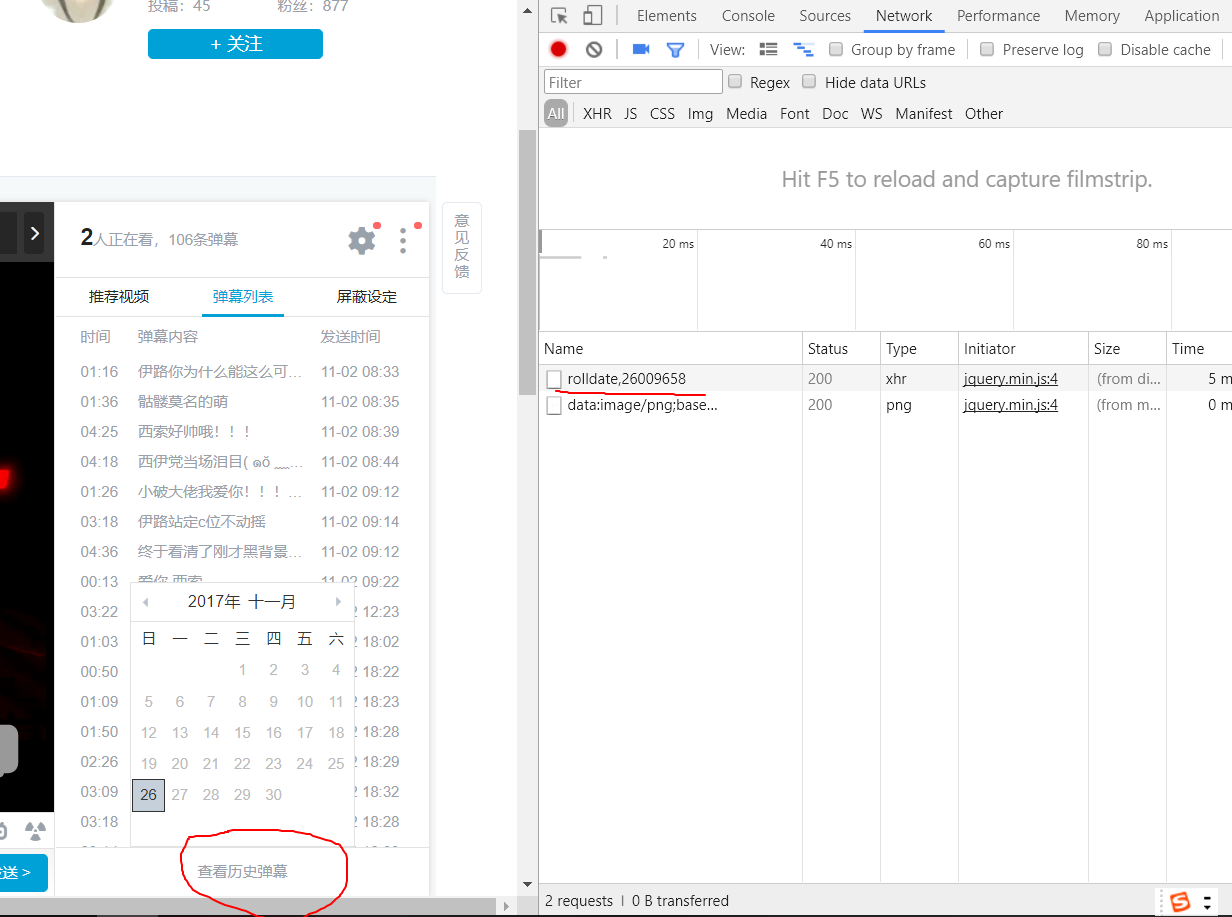

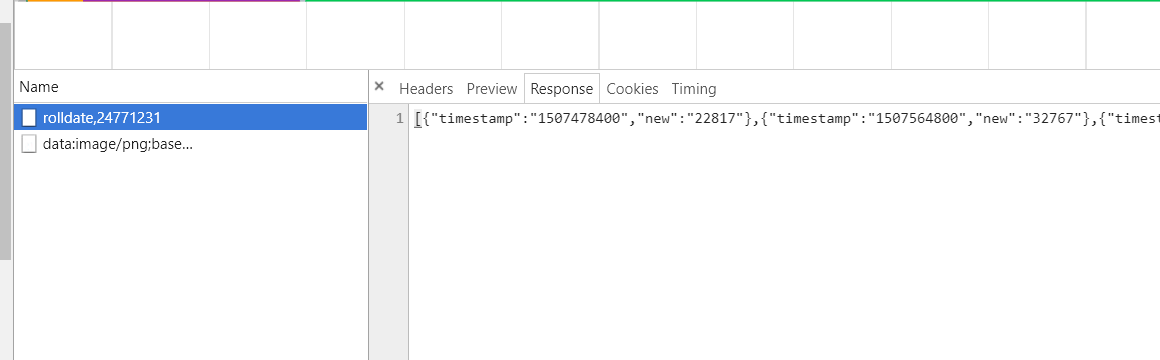
其中rolldate后面的数字表示该视频对应的弹幕号,返回的数据中timestamp表示弹幕日期,new表示数目
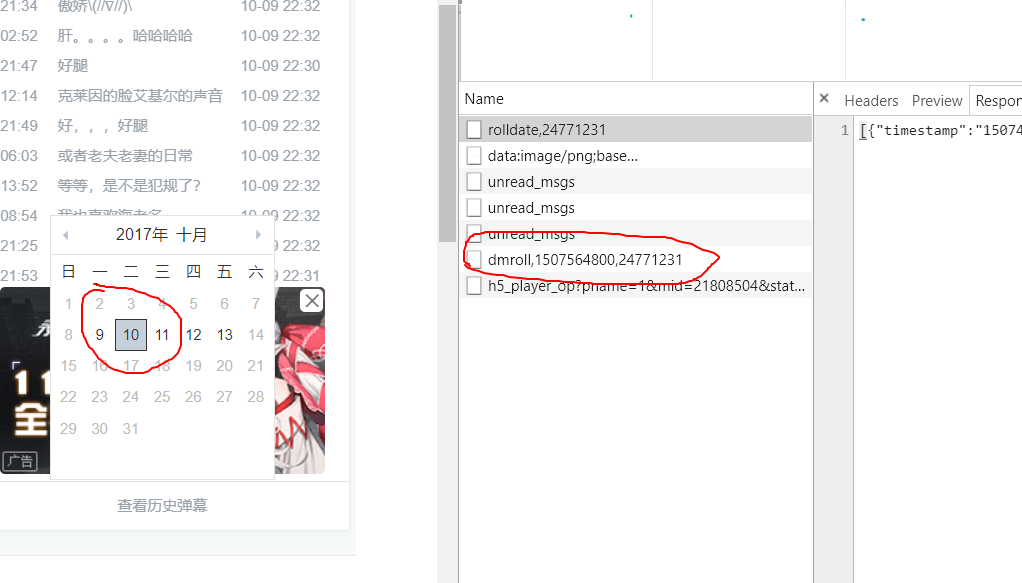
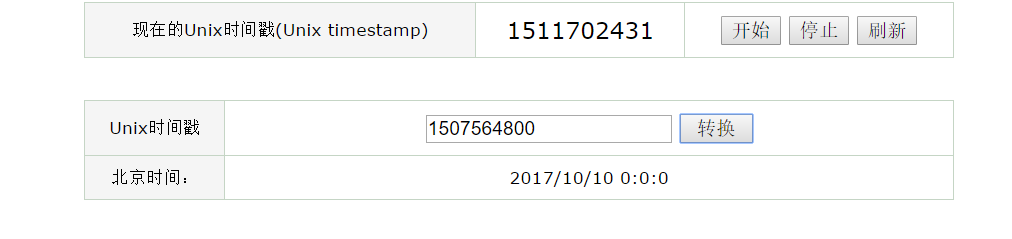
在查看历史弹幕中任选一天,查看,会发出新的请求
dmroll ,时间戳,弹幕号,表示获取该日期的弹幕,1507564800 表示2017/10/10 0:0:0
该请求返回xml数据
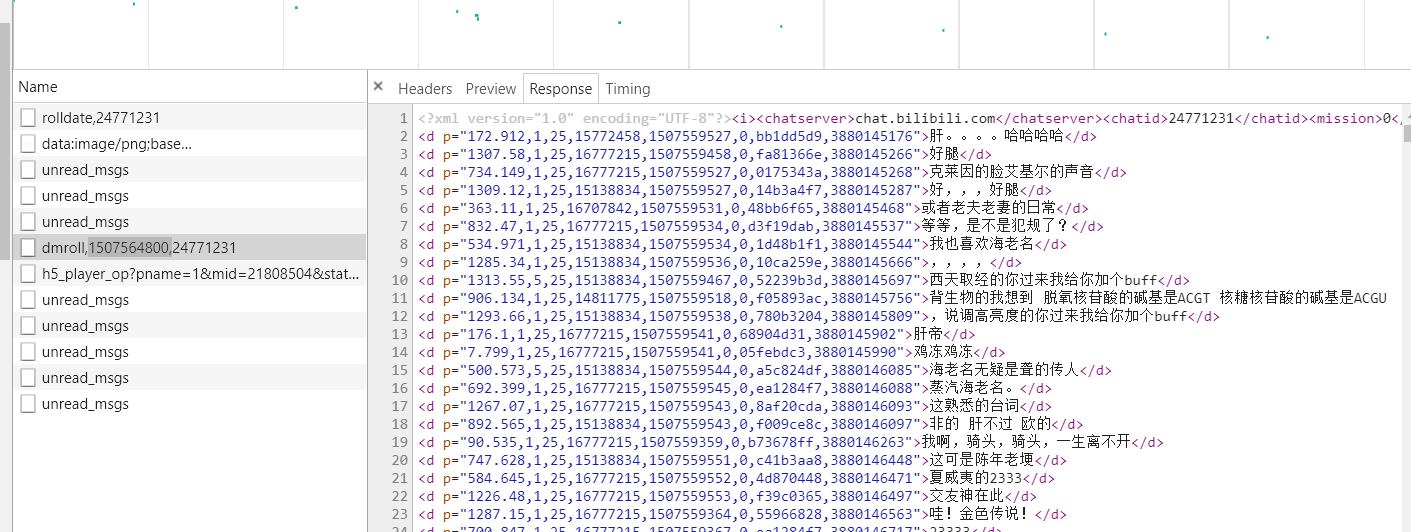
使用正则表达式获取所有弹幕消息,匹配模式
'<d p=".*?">(.*?)</d>'
拼接字符串,将所有弹幕保存到本地文件即可
with open('content.txt', mode='w+', encoding='utf8') as f: f.write(content)
参考代码如下,将弹幕按照日期保存为单个文件...因为太多了...
import requests
import re
import time
"""
爬取哔哩哔哩视频弹幕信息
"""
# 2043618 是视频的弹幕标号,这个地址会返回时间列表
# https://www.bilibili.com/video/av1349282
url = 'https://comment.bilibili.com/rolldate,2043618'
# 获取弹幕的id 2043618
video_id = url.split(',')[-1]
print(video_id)
# 获取json文件
html = requests.get(url)
# print(html.json())
# 生成时间戳列表
time_list = [i['timestamp'] for i in html.json()]
# print(time_list)
# 获取弹幕网址格式 'https://comment.bilibili.com/dmroll,时间戳,弹幕号'
# 弹幕内容,由于总弹幕量太大,将每个弹幕文件分别保存
for i in time_list:
content = ''
j = 'https://comment.bilibili.com/dmroll,{0},{1}'.format(i, video_id)
print(j)
text = requests.get(j).text
# 匹配弹幕内容
res = re.findall('<d p=".*?">(.*?)</d>', text)
# 将时间戳转化为日期形式,需要把字符串转为整数
timeArray = time.localtime(int(i))
date_time = time.strftime("%Y-%m-%d %H:%M:%S", timeArray)
print(date_time)
content += date_time + '\n'
for k in res:
content += k + '\n'
content += '\n'
file_path = 'txt/{}.txt'.format(time.strftime("%Y_%m_%d", timeArray))
print(file_path)
with open(file_path, mode='w+', encoding='utf8') as f:
f.write(content)
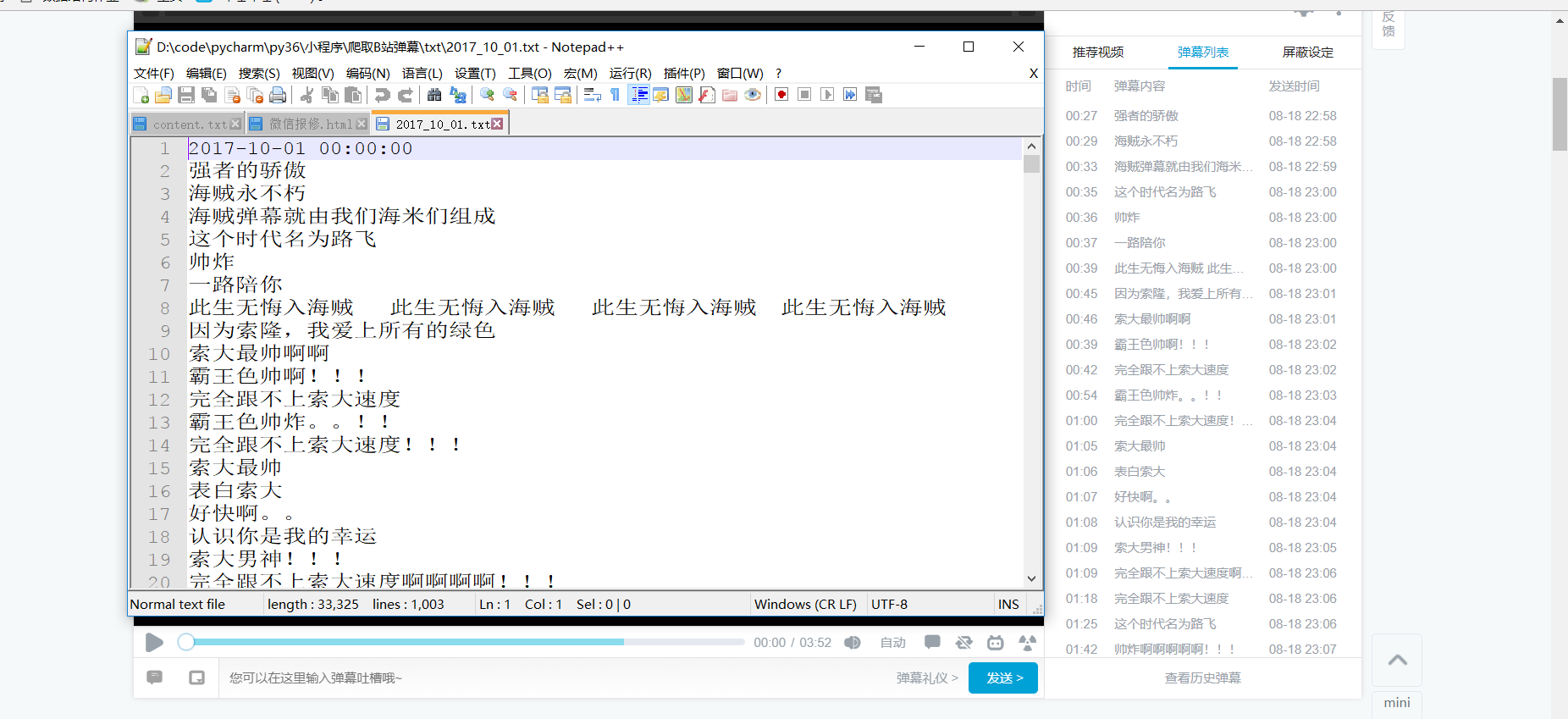
最终效果
之后可以 做一些分词生成词云或者进行情感分析,有时间在说吧....
大家可以在下方给小编留言你学习的心得,也感谢你对我们的支持。
相关推荐
-

python3写爬取B站视频弹幕功能
需要准备的环境: 一个B站账号,需要先登录,否则不能查看历史弹幕记录 联网的电脑和顺手的浏览器,我用的Chrome Python3环境以及request模块,安装使用命令,换源比较快: pip3 install request -i http://pypi.douban.com/simple 爬取步骤: 登录后打开需要爬取的视频页面,打开开发者工具台,Chrome可以使用F12快捷键,选择network监听请求 点击查看历史弹幕,获取请求 其中rolldate后面的数字表示该视频对应的弹幕号,返
-
Python实现爬取某站视频弹幕并绘制词云图
目录 前言 爬取弹幕 爬虫基本思路流程 导入模块 代码 制作词云图 导入模块 读取弹幕数据 前言 [课 题]: Python爬取某站视频弹幕或者腾讯视频弹幕,绘制词云图 [知识点]: 1. 爬虫基本流程 2. 正则 3. requests >>> pip install requests 4. jieba >>> pip install jieba 5. imageio >>> pip install imageio 6. wordcloud >
-
Python爬虫自动化爬取b站实时弹幕实例方法
最近央视新闻记者王冰冰以清除可爱和专业的新闻业务水平深受众多网友喜爱,b站也有很多up主剪辑了关于王冰冰的视频.我们都是知道b站是一个弹幕网站,那你知道如何爬取b站实时弹幕吗?本文以王冰冰视频弹幕为例,向大家介绍Python爬虫实现自动化爬取b站实时弹幕的过程. 1.导入需要的库 import jieba # 分词 from wordcloud import WordCloud # 词云 from PIL import Image # 图片处理 import numpy as np # 图片处理
-
使用python tkinter开发一个爬取B站直播弹幕工具的实现代码
项目地址 https://github.com/jonssonyan... 开发工具 python 3.7.9 pycharm 2019.3.5 代码 import threading import time import tkinter.simpledialog from tkinter import END, simpledialog, messagebox import requests class Danmu(): def __init__(self, room_id): # 弹幕url
-
Python基于Tkinter开发一个爬取B站直播弹幕的工具
简介 使用Python Tkinter开发一个爬取B站直播弹幕的工具,启动后在弹窗中输入房间号即可,弹幕内容会保存在脚本文件同级目录下的.log扩展名的文件中 开发工具 python 3.7.9 pycharm 2019.3.5 实现代码 import threading import time import tkinter.simpledialog # 使用Tkinter前需要先导入 from tkinter import END, messagebox import requests # 全
-
Python如何实现爬取B站视频
5月3日晚,央视在<新闻联播>前播放了B站青年宣言片<后浪>,这是B站首次登陆央视黄金时段,今天在朋友圈陆续看到相关的视频.最早用B站的同学都知道,B站是和A站以异曲同工的鬼畜视频及动漫,进入到大众视野的非主流视频网站.哔哩哔哩现为国内领先的年轻人娱乐.文化社区,该网站于2009年6月26日创建,被粉丝们亲切的称为"B站". B站之所以火,是因为趣味与知识并存.它是一个重度宅腐二次元集结地.B站包含动漫.漫画.游戏,也有很多由繁到简.五花八门的视频,很多冷门的软
-
写一个Python脚本自动爬取Bilibili小视频
我身边的很多小伙伴们在朋友圈里面晒着出去游玩的照片,简直了,人多的不要不要的,长城被堵到水泄不通,老实人想想啊,既然人这么多,哪都不去也是件好事,没事还可以刷刷 B 站 23333 .这时候老实人也有了一个大胆地想法,能不能让这些在旅游景点排队的小伙伴们更快地打发时间呢?考虑到视频的娱乐性和大众观看量,我决定对 B 站新推出的小视频功能下手,于是我跑到B站去找API接口,果不起然,B站在小视频功能处提供了 API 接口,小伙伴们有福了哟! B 站小视频网址在这里哦: http://vc.bili
-
python 爬取B站原视频的实例代码
B站原视频爬取,我就不多说直接上代码.直接运行就好. B站是把视频和音频分开.要把2个合并起来使用.这个需要分析才能看出来.然后就是登陆这块是比较难的. import os import re import argparse import subprocess import prettytable from DecryptLogin import login '''B站类''' class Bilibili(): def __init__(self, username, password, **
-
Python如何爬取b站热门视频并导入Excel
代码如下 #encoding:utf-8 import requests from lxml import etree import xlwt import os # 爬取b站热门视频信息 def spider(): video_list = [] url = "https://www.bilibili.com/ranking?spm_id_from=333.851.b_7072696d61727950616765546162.3" html = requests.get(url, h
-
如何使用python爬取B站排行榜Top100的视频数据
记得收藏呀!!! 1.第三方库导入 from bs4 import BeautifulSoup # 解析网页 import re # 正则表达式,进行文字匹配 import urllib.request,urllib.error # 通过浏览器请求数据 import sqlite3 # 轻型数据库 import time # 获取当前时间 2.程序运行主函数 爬取过程主要包括声明爬取网页 -> 爬取网页数据并解析 -> 保存数据 def main(): #声明爬取网站 baseurl = &q