JAVA线上常见问题排查手段(小结)
在平时开发过程中,对于线上问题的排查以及系统的优化,免不了和Linux进行打交道。每逢大促和双十一,对系统的各种压测性能测试,优化都是非常大的一次考验。抽空整理了一下自己在线上问题排查以及系统优化的一些经验。
一、系统性能瓶颈在哪
我们常常提到项目的运行环境,那么运行环境包括哪些呢?一般包括你的操作系统、CPU、内存、硬盘、网络带宽、JRE环境、你的代码依赖的各种组件等等。所以系统性能的瓶颈往往是IO瓶颈、CPU瓶颈、内存瓶颈或者程序导致的性能瓶颈
登录到服务器上,我们使用TOP命令可以很全面的看到系统资源使用情况
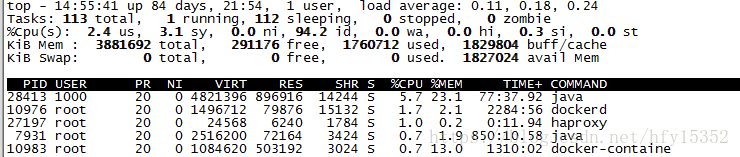
CPU瓶颈如何分析
使用TOP命令,输入大写P(即shift + P)可以按照CPU使用大小降序排序,在TOP命令第三行可以看到关键信息 %id:空闲CPU时间百分比,如果这个值过低,表明系统CPU存在瓶颈。如果过低,一般都是你的java程序导致的,所以需要登录到docker容器通过jstack命令查看堆栈信息来分析原因
确认目标进程
查看对应进程信息 -> 登录容器查看容器id -> 进入容器 -> 容器内top命令查看CPU过高的目标进程
#top #ps -ef | grep 进程号 #sudo docker ps -a #sudo docker exec -it 容器id bash #top
对于CPU使用情况详细信息可以使用sar命令;命令中1 3 表示每秒采样1次,一共采样3次
#sar -u 1 3
打印堆栈信息
由于进程是admin用户启动的,所以jstack打印堆栈信息需要切换admin用户,确保你的机器上装了jstack命令;
然后退出容器,将文件复制移动到个人家目录(如果cp命令不能使用,可以通过scp命令移动到个人家目录)
通过sftp命令将文件copy到本地机器上,来分析堆栈日志信息;如果装了sz命令,或者通过sz命令下载也可以
# sudo -u admin /opt/usr/java/bin/jstack -l 76 > /home/admin/test/logs/jstack.log # cp /home/admin/test/logs/jstack.log ~/
分析堆栈信息
进入容器,查看哪些线程占比高(截图只是为了说明如何使用,实际cpu并没有很高)
#top -H p 进程id
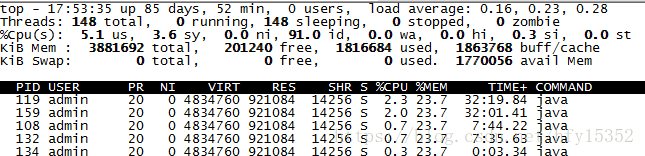
将占比高的线程PID换算成16进制,去堆栈日志找对应的线程堆栈信息,分析问题就可以了
内存瓶颈如何分析
项目开发过程中,线程的不合理使用或者集合的不合理使用,通常会导致内存oom情况,对于内存瓶颈一般通过top命令查看,或者free命令查看内存使用情况;更详细可以通过vmstat命令查看
free命令,实际可用内存为free + buff + available;
#free -m
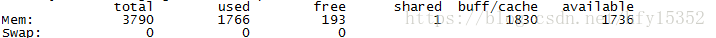
如何分析内存使用,找到内存过高的原因呢,需要登录到docker容器中查看内存占比比较高的进程,通过jmap命令dump下来,通过IBM的分析工具MA来分析
确定目标进程 -> jmap -> 通过scp命令copy到个人家目录 -> 由于dump文件比较大,所以下载到本地之前通过tar命令压缩一下
#sudo -u admin /opt/usr/java/bin/jmap -dump:live,format=b,file=/home/admin/test/logs/java.heap.bin 进程号 #scp 用户名@host:/home/admin/test/logs/java.heap.bin ~/ #cd ~ #tar -zcvf java.heap.bin.tar.gz java.heap.bin
一般内存分析查看最多的就是Actions下面的Histogram,查看对象引用有多少没有GC;一般正常一个dump文件看起来不明显,需要多个dump文件对比来查看内存泄露的原因

IO瓶颈如何分析
如果IO存在性能瓶颈,top工具中的%wa会偏高,进一步分析用iostat命令工具分析
#iostat -d -k -x 1 1
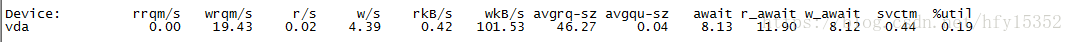
如果%iowait的值过高,表示硬盘存在I/O瓶颈。
如果 %util 接近 100%,说明产生的I/O请求太多,I/O系统已经满负荷,该磁盘可能存在瓶颈。
如果 svctm 比较接近 await,说明 I/O 几乎没有等待时间;
如果 await 远大于 svctm,说明I/O 队列太长,io响应太慢,则需要进行必要优化。
如果avgqu-sz比较大,也表示有大量io在等待
解决这种问题一般方法有:使用缓存,讲述磁盘IO;同步转化成异步、随机写转化成顺序写、替换硬件
调用第三方接口网络报文分析
项目中有时候会遇到第三方接口的服务调用,一般通过HTTP客户端请求,对于常见的服务连接超时、系统抖动等问题经常遇到;这种问题有时候排查起来比较麻烦,只有通过tcpdump来抓取网络层的报文,在通过wireshark工具来分析原因;对于HTTS协议的,只能依赖第三方服务端抓包来分析
#tcpdump -i eth0 dst host hostname -C 10240 -W 50 -w xx.cap
一般需要root用户权限,hostname替换成实际主机ip或域名,eth0是网卡,一般服务器会有多个网卡,所以一定要指定抓取哪个网卡上对应的网络数据报文
我们来回顾一下在传输层TCP三次握手和四次挥手的过程
客户端和服务端进行数据传输一般都是HTTP或者HTTPS协议,HTTP超文本传输协议是建议在TCP传输协议上进行传输数据的,底层TCP传输通过套接字Socket进行数据流传输;至于为什么是三次握手,可以理解为信道不可靠,传输要可靠,三次握手是理论上的最小值
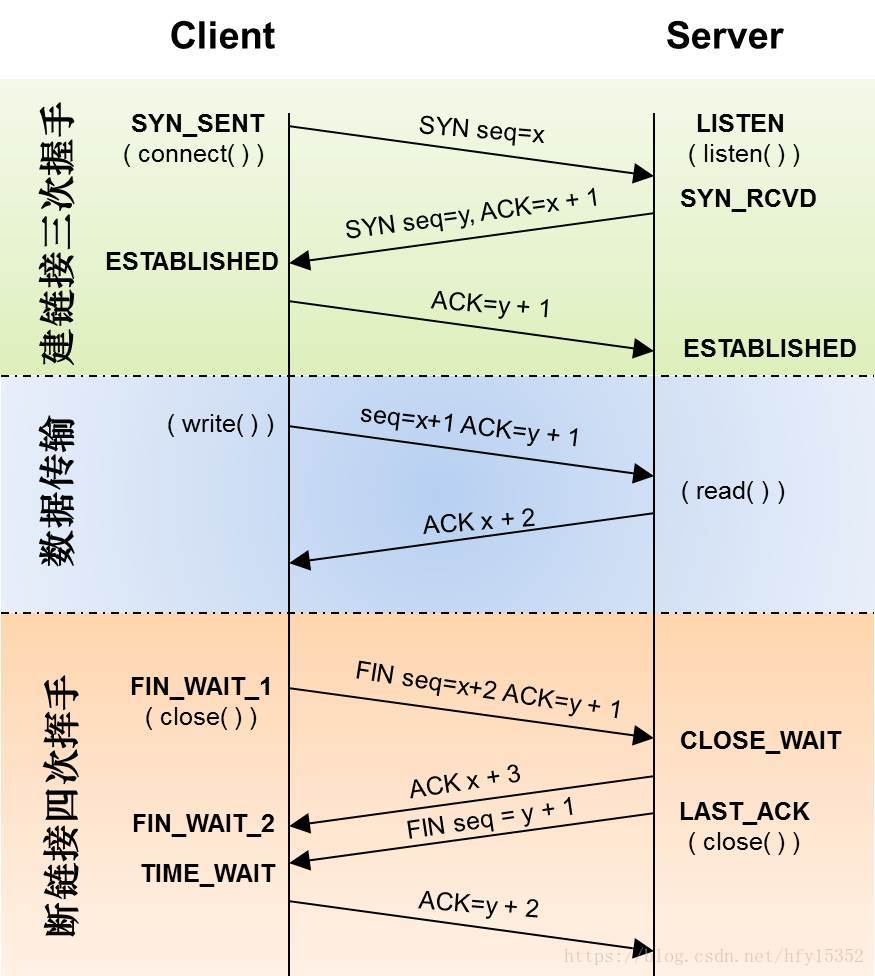
第一次握手:建立连接。客户端发送连接请求报文段,将SYN位置为1,Sequence Number为x;然后,客户端进入SYN_SEND状态,等待服务器的确认;
第二次握手:服务器收到SYN报文段。服务器收到客户端的SYN报文段,需要对这个SYN报文段进行确认,设置Acknowledgment Number为x+1(Sequence Number+1);同时,自己自己还要发送SYN请求信息,将SYN位置为1,Sequence Number为y;服务器端将上述所有信息放到一个报文段(即SYN+ACK报文段)中,一并发送给客户端,此时服务器进入SYN_RECV状态;
第三次握手:客户端收到服务器的SYN+ACK报文段。然后将Acknowledgment Number设置为y+1,向服务器发送ACK报文段,这个报文段发送完毕以后,客户端和服务器端都进入ESTABLISHED状态,完成TCP三次握手。
完成了三次握手,客户端和服务器端就可以开始传送数据。以上就是TCP三次握手的总体介绍
那四次分手呢?
当客户端和服务器通过三次握手建立了TCP连接以后,当数据传送完毕,肯定是要断开TCP连接的啊。那对于TCP的断开连接,这里就有了神秘的“四次分手”。
第一次分手:主机1(可以使客户端,也可以是服务器端),设置Sequence Number和Acknowledgment Number,向主机2发送一个FIN报文段;此时,主机1进入FIN_WAIT_1状态;这表示主机1没有数据要发送给主机2了;
第二次分手:主机2收到了主机1发送的FIN报文段,向主机1回一个ACK报文段,Acknowledgment Number为Sequence Number加1;主机1进入FIN_WAIT_2状态;主机2告诉主机1,我“同意”你的关闭请求;
第三次分手:主机2向主机1发送FIN报文段,请求关闭连接,同时主机2进入LAST_ACK状态;
第四次分手:主机1收到主机2发送的FIN报文段,向主机2发送ACK报文段,然后主机1进入TIME_WAIT状态;主机2收到主机1的ACK报文段以后,就关闭连接;此时,主机1等待2MSL后依然没有收到回复,则证明Server端已正常关闭,那好,主机1也可以关闭连接了。
追踪online应用java动态运行细节
对于online应用,有时候需要关注java运行时的一些细节,可以通过Btrace命令跟踪
https://legacy.gitbook.com/book/json-liu/btrace/details
二、项目代码常见问题排查
在讲述这个问题之前,有必要聊一下java的类加载机制以及JVM内存结构,理解了这些,对于我们常见的OOM问题、性能调优会带来很大帮助
类加载机制
类加载虚拟机内存到最终卸载是有一个完整的生命周期的,它的整个生命周期包括:加载、验证、准备、解析、初始化、使用和卸载七个阶段

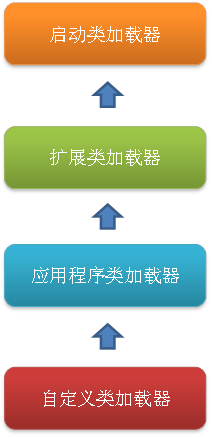
类加载过程,类加载器采用的是双亲委派原则,首先是启动类加载器BootStrap加载,然后是扩展类加载器、应用程序加载器、
自定义类加载器
验证:通过对class文件的类全名通过getResourceAsStream转化成二进制流,然后将静态的数据结构(构造函数、属性、方法等)转化成运行时方法区的数据结构
验证主要有class文件格式校验(class文件是否以一些非法字符开头)、元数据信息校验(比如java类是否有父类,父类是否被final修饰符修饰等等)、字节码验证(对类的方法进行验证)、符号引用验证(通过全限定名能否找到对应的类)
准备:就是对类进行分配内存、对变量进行初始化赋值 public static int = 123 赋值为0 还不是123 因为 putstatic指令存在类构造器方法中,只有在初始化阶段赋值为123
解析:类、接口、方法解析,主要是将符号引用替换为直接引用,符号引用java虚拟机内存引用无关,直接引用可以是指针位置,偏移量可以具体定位到内存具体位置的
初始化:对变量进行赋值,putstatic getstatic、invokestatic指令,《clinit》构造方法中,进行赋值
JVM内存结构
java虚拟机在执行java代码的时候,会把它所管理的内存划分不同的区域,JVM内存的划分结构如下:
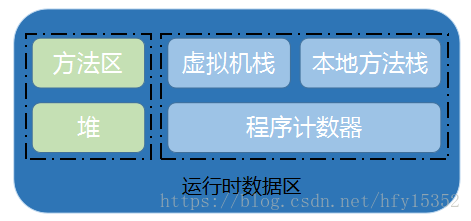
其中方法区和堆区是所有线程共享的区域,虚拟机栈、本地方法栈、程序计数器是线程私有
在这几个区域中,除了程序计数器不会产生oom问题,其他区域都有可能产生oom
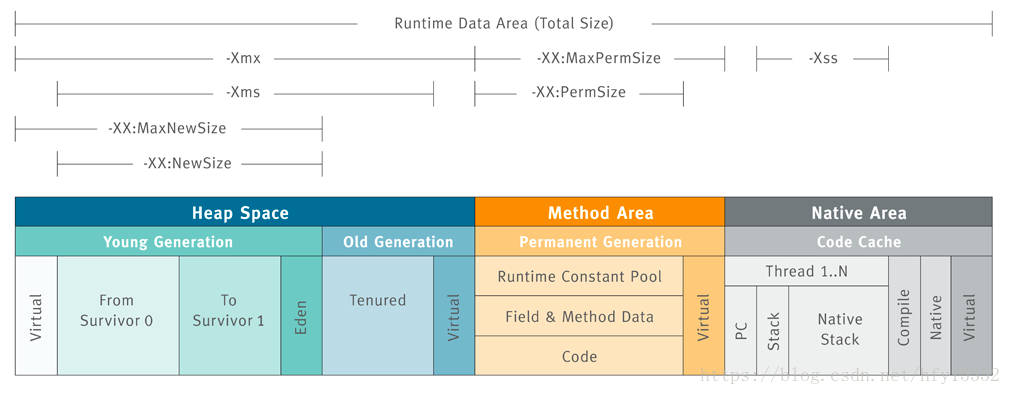
堆区
java heap是JVM内存最大的一块区域,几乎所有的java实例以及数组分配都在这里完成,根据内存的回收算法,可以将堆区划分年轻代和老年代,比例为1:2的关系,其中年轻代又分为Eden和2个survival区,为8:1:1的关系;在这个区域最容易发生oom,一般原因有2种可能,流量峰值超过程序设定的阈值或者内存泄露;比如内存泄露最常见的就是集合局部变量,由于使用不得当,一直无法GC,就会触发java.lang.OutOfMemoryError;
回顾一下年轻代和老年代的垃圾回收算法:在年轻代用复制算法、在老年代用标记清除、标记整理算法,对于java不同的对象,生命周期不一样,有的存活年龄短,有的存活年龄长,JVM是如何判断java对象实例可以GC的呢?java一般引用的是根搜索算法,从GC ROOT节点开始搜索,如果对样到GC ROOT对象节点没有任何引用链相连,就认为对象不可用;常常会有一些大对象初始化,年轻代放不了,会借代老年代存大对象,就容易产生Full GC的情况,所以对于大对象读取一定不要一次性读入内存,而是按照行读取处理;如果因为堆区设置参数不合理,可以通过Xmx来调整堆区大小
方法区
在类加载过程中,会对class文件进行读取,转化成二进制流信息,最后转化成元数据信息进行存储,包括类的全限定名称、版本、方法、字段等信息,这些在编译时就JVM就分配内存,这块区域就是方法区,对于一些常量池等等也在这里分配;在方法区也涉及到垃圾回收,比如类的卸载、无用的常量、无用的类都会回收;一般不断创建动态代理会导致方法区的oom;可以通过MaxPermSize来调节方法区的大小
虚拟机栈
这一块区域属于线程私有的,线程要想在java虚拟机正常的运行,不仅需要计数器来记录行号,线程还需要拥有自己的运行空间,虚拟机栈可以保存方法的运行顺序,方法局部变量以及方法在运算时,需要自己的内存空间;我们把这一块区域称为虚拟机栈;每一个栈内部划分局部变量表、操作数栈、动态链表、返回地址;方法执行都需要一块区域存储局部变量,方法运算时,需要内存空间,就是操作数栈,有些方法需要运行时加载指定的方法,符号引用转化直接引用,就需要动态链表;方法遇到返回指令或者抛出异常就会返回,需要返回地址;在这一块,也会产生oom问题,典型的就是线程池没有设置大小,代码中不断创建线程,而创建线程需要内存空间,物理内存不够就会oom,遇到这样问题通常是调小栈的大小,通过Xss来设置
本地方法栈
和虚拟机栈一样,在java虚拟机中,不但要执行java方法,还要执行本地方法,也会产生oom,除此之外,也会和虚拟机栈一样产生栈溢出异常
程序计数器*
众所周知,虚拟机在处理多线程时,通过轮流切换线程,来获取CPU资源的,为了保证每个线程下次能够正确的执行,需要记录每个线程的当前运行位置;程序计数器的作用就是将各个线程下次所执行的(字节码)行号(准确来说是指令的地址)记录下来,以保证其下次执行时可以正确的执行;内存很小,几乎可以忽略不计
讲述完这2个概念之后,我们来看看java的一些常见问题
NoSuchMethodException
出现这种问题的原因一般有2种可能:java ClassLoader机制、java二方包冲突;针对ClassLoader问题可以在JVM配置-XX:+TraceClassLoading 来跟踪class加载过程,二方包冲突直接排除pom文件冲突文件即可
三、数据库mysql慢sql优化
想必大家在和数据库打交道的时候,经常会遇到sql查询很慢,数据量大的时候,性能很低。碰到这样的问题有一定开发经验的同学想到通过explain执行计划,来分析sql;综合业务场景建立合适的索引来优化;在这里我只是总结一下如何分析慢sql,以及如何建立索引
谈到索引,不得不提到数据结构;mysql是一种关系型基于磁盘的关系型数据库,对于磁盘的IO和从内存读取数据性能相差好几个量级,所以为了减少磁盘的IO次数,使用了B+树这种多路平衡树来存储数据,树的高度越低,磁盘IO次数就会越少;假设数据量为N,每个磁盘块数据量为m,则树的高度h=log(m+1)*N,而m=磁盘块的大小/数据项的大小 对于B+树,所有数据都存在叶子节点,这样就会内节点磁盘块就会存储更多的内节点,每个节点的索引范围更大,对于磁盘块大小都固定1页大大小,默认为16K,这样数据项的大小越大,m越小,高度就越低。
原理阐述清楚之后,了解一下建立索引的一些原则
- 最左匹配原则,因为建立搜索树的时候,是通过从做往右的顺序建立的,当遇到范围查询、模糊查询或者并集查询,索引不会生效
- 索引字段区分度要高,也就是不重复比例要大,这样建立索引区分数据才明显
- 索引字段不能参与计算,因为B+树存储的data域都是字段名称,如果含有函数计算,成本相当大
sql语句通过执行计划分析,关键看rows大小,一般情况下rows越小,查询越快,避免全表查询,多表查询尽量采用union或union all来查询
关于mysql存储引擎的区别:从5.7之后,myql默认采用InnoDB存储引擎,相比MyISAM存储引擎,InnoDB支持事务特性,同样使用B+树,但叶子节点data域存储值不一样,InnoDB存储的是完整的数据记录,默认按照主键索引顺序,所以InnoDB一定要有主键,对于普通索引,data域存储的是主键索引的值,所以需要先到普通索引树中找到主键索引,再到主索引树中找到相应的记录。而MyISAM叶子节点存储的是数据的地址,数据文件和索引文件是分离的
以上就是本文的全部内容,希望对大家的学习有所帮助,也希望大家多多支持我们。
相关推荐
-
java实战CPU占用过高问题的排查及解决
最近一段时间 某台服务器上的一个应用总是隔一段时间就自己挂掉 用top看了看 从重新部署应用开始没有多长时间CPU占用上升得很快 排查步骤 1.使用top 定位到占用CPU高的进程PID top 2.通过ps aux | grep PID命令 获取线程信息,并找到占用CPU高的线程 ps -mp pid -o THREAD,tid,time | sort -rn 3.将需要的线程ID转换为16进制格式 printf "%x\n" tid 4.打印线程的堆栈信息 到了这一步具体看堆栈的日
-
JAVA线上常见问题排查手段(小结)
在平时开发过程中,对于线上问题的排查以及系统的优化,免不了和Linux进行打交道.每逢大促和双十一,对系统的各种压测性能测试,优化都是非常大的一次考验.抽空整理了一下自己在线上问题排查以及系统优化的一些经验. 一.系统性能瓶颈在哪 我们常常提到项目的运行环境,那么运行环境包括哪些呢?一般包括你的操作系统.CPU.内存.硬盘.网络带宽.JRE环境.你的代码依赖的各种组件等等.所以系统性能的瓶颈往往是IO瓶颈.CPU瓶颈.内存瓶颈或者程序导致的性能瓶颈 登录到服务器上,我们使用TOP命令可以很全面的
-
JAVA线上常见问题排查手段汇总
在平时开发过程中,对于线上问题的排查以及系统的优化,免不了和Linux进行打交道.每逢大促和双十一,对系统的各种压测性能测试,优化都是非常大的一次考验.抽空整理了一下自己在线上问题排查以及系统优化的一些经验. 一.系统性能瓶颈在哪 我们常常提到项目的运行环境,那么运行环境包括哪些呢?一般包括你的操作系统.CPU.内存.硬盘.网络带宽.JRE环境.你的代码依赖的各种组件等等.所以系统性能的瓶颈往往是IO瓶颈.CPU瓶颈.内存瓶颈或者程序导致的性能瓶颈 登录到服务器上,我们使用TOP命令可以很全面的
-

Java线上问题排查神器Arthas实战原理解析
概述 背景 是不是在实际开发工作当中经常碰到自己写的代码在开发.测试环境行云流水稳得一笔,可一到线上就经常不是缺这个就是少那个反正就是一顿报错抽风似的,线上调试代码又很麻烦,让人头疼得抓狂:而且debug不一定是最高效的方法,遇到线上问题不能debug了怎么办.原先我们Java中我们常用分析问题一般是使用JDK自带或第三方的分析工具如jstat.jmap.jstack. jconsole.visualvm.Java Mission Control.MAT等.但此刻的你没有看错,还有一款神器Art
-
j2Cache线上异常排查问题解决记录分析
目录 问题背景 问题分析 假设问题 小心求证 问题重现 问题解决 问题后记-下面才是真正的原因 重新假设 最终解决 问题背景 开发反馈,线上有个服务在运行一段时间后,就会抛异常导致redis缓存不可用.项目使用了j2Caceh,异常是j2Cache的RedisCacheProvider抛出来的,如: Exception in thread "main" redis.clients.jedis.exceptions.JedisException: Could not get a reso
-
线上问题排查之golang使用json进行对象copy
前言: 记一次golang使用json进行对象copy的内存溢出问题排查 问题现象:新增的功能,灰度部署在k8s集群的服务,发现机器老是被打崩,因为是灰度,且控制了qps在100多,但是机器却崩溃.通过对灰度机器的监控.发现是内存太高导致机器挂掉.此次回顾一下排查历程. 增加GC次数,从而可以通过pprof去抓取内存使用情况: 将程序的GOGC由原先的2000改为200,从而增加GC次数,然后去抓取内存消耗情况 第一步操作完成,经验证机器可以正常运行,借助gops导出cpu运行图和内存消耗情况
-
java开发 线上问题排查命令详解
前言 作为一个合格的开发人员,不仅要能写得一手还代码,还有一项很重要的技能就是排查问题.这里提到的排查问题不仅仅是在coding的过程中debug等,还包括的就是线上问题的排查.由于在生产环境中,一般没办法debug(其实有些问题,debug也白扯...),所以我们需要借助一些常用命令来查看运行时的具体情况,这些运行时信息包括但不限于运行日志.异常堆栈.堆使用情况.GC情况.JVM参数情况.线程情况等. 给一个系统定位问题的时候,知识.经验是关键,数据是依据,工具是运用知识处理数据的手段.为了便
-
Java运算符的常见问题与用法小结
本文实例讲述了Java运算符的常见问题与用法.分享给大家供大家参考,具体如下: 算术运算符: 算术运算符的注意问题 1. 如果对负数取模,可以把模数负号忽略不记,如:5%-2=1.但被模数是负数就另当别论. -5%3=-2:-5%-3=-2:符号跟被模数(左边). 2. 对于除号"/",它的整数除和小数除是有区别的:整数之间做除法时,只保留整数部分而舍弃小数部分. 例如:int x=3510;x=x/1000*1000; x的结果是? 3000 而3560.0/1000*1000=35
-
Java毕业设计实战之线上水果超市商城的实现
主要技术实现:spring. springmvc. redis. springboot. mybatis .session. jquery . md5 .bootstarp.js tomcat..拦截器等. 主要功能实现: 前端:登录.注册.商品分类查看.浏览水果商品.订单管理.发表评论.收藏商品.购物车管理.个人订单管理查看.个人信息查看修改.地址管理等 后台管理员:后台登录.数据统计.系统版本信息等.管理员管理.角色管理.订单管理.通知公告管理.商品种类.和商品详情管理 主要功能截图如下
-
阿里Druid数据连接池引发的线上异常解决
目录 前言 过程一:定位工作流 过程二:定位JPA的OpenEntityManagerInViewInterceptor 过程三:定位Druid,真正的罪魁祸首 后记: 前言 事件起因:项目使用了activiti工作流,系统是由老的spring mvc项目改造成的spring boot项目,数据库链接池从dbcp切换到druid,新系统上线后,同事多次系统隔一段时间后数据查询就很慢,基本出不来. 由此开始了线上bug排查之路.这个问题从一开始就模糊定位到数据库层面的问题,因为只有和数据相关的操作
-
python编程项目中线上问题排查与解决
目录 问题描述 问题分析 问题解决 总结 文 | 極光 来源:Python 技术「ID: pythonall」 最近开发中遇到个小问题,因为业务上的设计存在问题,导致数据库表总是被锁,而且是不定期的锁定,导致服务器运行异常,最后经过排查原因是多线程同时更新同一表中同一条记录导致问题.今天就来跟大家说说该如何避免这种问题. 问题描述 最近因为公司业务需要,产品设计了一套业务系统,据说会有很多内部和外部人员使用,拿到系统说明我们研发部门拼命加班赶时间,经历了两个月的后终于把系统上线运行. 刚开始用的