Python企业编码生成系统总体系统设计概述
本文实例讲述了Python企业编码生成系统总体系统设计。分享给大家供大家参考,具体如下:
一 系统功能结构

二 系统主界面
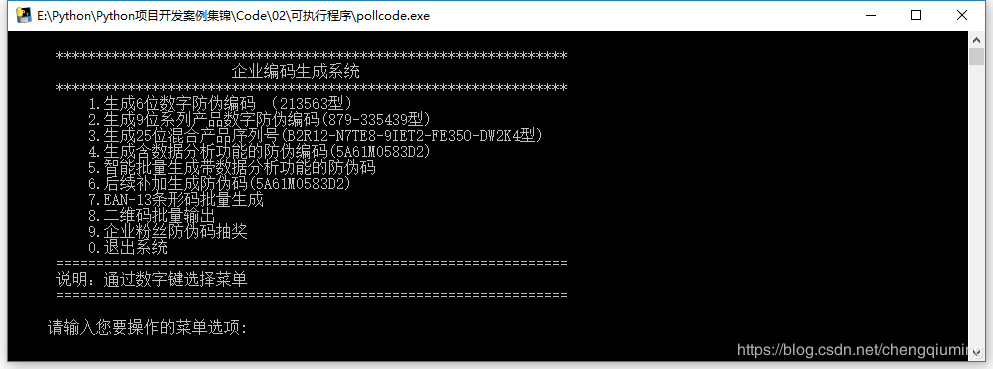
三 认识各种编码
1 6位数字防伪编码
它是一种简单的数字防伪码,由6位组成。例如:
355059 449982 763006 832787 090035 778851
2 9位系列产品数字防伪编码
多个产品系列的防伪码,前3位表示分类,后6位表示具体产品编码。例如:

3 25位混合产品序列号
当防伪要求较高,或者销售产品数量较大的产品,可以用25位混合产品序列号。例如:
FS35X-6L9W9-KJA3W-0BPJ1-YS39S E856A-I33XX-Q9DSJ-DHT41-1A6HW JGCAV-XQWAT-2VDRG-PH2B1-CFYN2 J7C5E-C9GQZ-FUFG3-HLTSH-ER61N 72ZEU-BJI1B-XH61T-N75Y4-5UZWK GMC2E-Y6LNH-KWQ71-J4MCJ-3GETT VKD6Z-3L1DP-UFQ24-AAH5S-6BBCQ FPM8J-6YC75-2JXWF-WY8EJ-U1YFP 83Y25-A8DZ7-35N0P-AK73Y-K1NUQ
4 含数据分析功能的防伪编码
大数据时代,企业不但要保证产品卖出去,还要知道都卖到哪里去了,哪些经销商卖的多,哪些产品卖的好等信息,这些都可以在商品编码中做文章,可以根据字母对应不同地区、产品颜色和产品批次,实现对产品销售情况的数据追踪。例如:
含数据分析功能的防伪码主要由3位字母编码和6位数字编码组成。3位字母编码的位置随机,但相对位置是按首字母对应不同地区,次字母对应产品的颜色,尾字母对应产品批次规则生成。用户在输入防伪码的时候,通过后台的数据分析,就可以很容易知道哪些地区卖得好、哪些颜色卖得好,卖的产品都是哪些批次。
例如:
5A365236B44C A7206B84C549 A501B42675C2 A4172B0C0264 722A93B5C296 A47B9737C547 7A493239B9C3 5A6968B0344C
5 带数据分析功能的防伪码
当产品系列很多,编码生成将是一个很耗费人力和工时的工作。拿到产品的生产数据后,将要生成的所有产品的防伪编码写入一个文件,让计算机根据根据来进行生成编码的工作。例如:

左边是保存产品编码和数量的文件,右边是生成的防伪码文件。
6 补加生成防伪码
随着产品的持续销售,会出现防伪码不足的现象,这时就要补充生成新的防伪码,但补充的防伪码不能和原来的重复。
7 EAN-13条形码
条形码比较常见,经常用于购买商品时手机支付。例如:

8 二维码
二维码更为常见,经常用于购买商品时微信支付。例如:

9 企业粉丝防伪码
将粉丝的防伪码都输入到文件,然后抽出指定数量的防伪码,作为中奖结果。
四 系统开发环境
- 操作系统:Windows 10
- Python版本:Python3.6
- 开发工具:Pycharm
- Python内置模块:random、os、string、tkinter
- Python第三方模块:qrcode、pystrich
五 文件夹结构

更多关于Python相关内容感兴趣的读者可查看本站专题:《Python编码操作技巧总结》、《Python图片操作技巧总结》、《Python数据结构与算法教程》、《Python Socket编程技巧总结》、《Python函数使用技巧总结》、《Python字符串操作技巧汇总》、《Python入门与进阶经典教程》及《Python文件与目录操作技巧汇总》
希望本文所述对大家Python程序设计有所帮助。
相关推荐
-

python编码总结(编码类型、格式、转码)
本文详细总结了python编码.分享给大家供大家参考,具体如下: [所谓unicode] unicode是一种类似于符号集的抽象编码,它只规定了符号的二进制代码,却没有规定这个二进制代码应该如何存储.也就是它只是一种内部表示,不能直接保存.所以存储时需要规定一种存储形式,比如utf-8和utf-16等.理论上unicode是一种能够容纳全世界所有语言文字的编码方案.(其他编码格式不再多说) [所谓GB码] GB就是"国标"的意思,即:中华人民共和国国家标准.GB码是面向汉字的编码,包括
-
python实现unicode转中文及转换默认编码的方法
本文实例讲述了python实现unicode转中文及转换默认编码的方法.分享给大家供大家参考,具体如下: 一.在爬虫抓取网页信息时常需要将类似"\u4eba\u751f\u82e6\u77ed\uff0cpy\u662f\u5cb8"转换为中文,实际上这是unicode的中文编码.可用以下方法转换: 1. >>> s = u'\u4eba\u751f\u82e6\u77ed\uff0cpy\u662f\u5cb8' >>> print s 人生苦短,
-
跟老齐学Python之坑爹的字符编码
字符编码,在编程中,是一个让学习者比较郁闷的东西,比如一个str,如果都是英文,好说多了.但恰恰不是如此,中文是我们不得不用的.所以,哪怕是初学者,都要了解并能够解决字符编码问题. >>> name = '老齐' >>> name '\xe8\x80\x81\xe9\xbd\x90' 在你的编程中,你遇到过上面的情形吗?认识最下面一行打印出来的东西吗?看人家英文,就好多了 >>> name = "qiwsir" >>&g
-
python轻松实现代码编码格式转换
最近刚换工作不久,没太多的时间去整理工作中的东西,大部分时间都在用来熟悉新公司的业务,熟悉他们的代码框架了,最主要的是还有很多新东西要学,我之前主要是做php后台开发的,来这边之后还要把我半路出家的前端学好.还要学习C++,哈哈,总之很充实了,每天下班回家都可以睡的很香(一句话总结,就是吃得香.睡的香~).再说说换工作时候吧,今年年初正式毕业半年了,感觉自己技术增长很快,原公司里面程序员的地位还不如运营,所以想换个工作,面试了3家(2家大的.一家小的),都给offer了,当然从大公司里面挑了个各
-
python3编码问题汇总
这两天写了个监测网页的爬虫,作用是跟踪一个网页的变化,但运行了一晚出现了一个问题....希望大家不吝赐教! 我用的是python3,错误在对html response的decode时抛出,代码原样为: response = urllib.urlopen(dsturl) content = response.read().decode('utf-8') 抛出错误为 File "./unxingCrawler_p3.py", line 50, in getNewPhones content
-
Python获取系统默认字符编码的方法
本文实例讲述了Python获取系统默认字符编码的方法.分享给大家供大家参考.具体分析如下: 在Python代码中,普通字符串的编码方式与程序源文件编码方式一致的,而很多IDE在默认情况下,将程序源文件按照系统默认字符编码来保存的. 下面给出用Python获取系统默认编码的例子: #!/usr/bin/env python #coding=utf-8 """ 获取系统默认编码 """ import sys print sys.getdefaulte
-
python自然语言编码转换模块codecs介绍
python对多国语言的处理是支持的很好的,它可以处理现在任意编码的字符,这里深入的研究一下python对多种不同语言的处理. 有一点需要清楚的是,当python要做编码转换的时候,会借助于内部的编码,转换过程是这样的: 复制代码 代码如下: 原有编码 -> 内部编码 -> 目的编码 python的内部是使用unicode来处理的,但是unicode的使用需要考虑的是它的编码格式有两种,一是UCS-2,它一共有65536个码位,另一种是UCS-4,它有2147483648g个码位.对于这两种格
-
详解Python2.x中对Unicode编码的使用
我确定有很多关于Unicode和Python的说明,但为了方便自己的理解使用,我还是打算再写一些关于它们的东西. 字节流 vs Unicode对象 我们先来用Python定义一个字符串.当你使用string类型时,实际上会储存一个字节串. [ a ][ b ][ c ] = "abc" [ 97 ][ 98 ][ 99 ] = "abc" 在这个例子里,abc这个字符串是一个字节串.97.,98,,99是ASCII码.Python 2.x版本的一个不足之处就是默认将
-
使用python的chardet库获得文件编码并修改编码
首先需要安装chardet库,有很多方式,我才用的是比较笨的方式:sudo pip install chardet 复制代码 代码如下: #!/usr/bin/env python# coding: UTF-8import sysimport osimport chardet def print_usage(): print '''usage: change_charset [file|directory] [charset] [output file]\n for example: cha
-
Python处理JSON时的值报错及编码报错的两则解决实录
1.ValueError: Invalid control character at: line 1 column 8363 (char 8362) 使用json.loads(json_data)时,出现: ValueError: Invalid control character at: line 1 column 8363 (char 8362) 出现错误的原因是字符串中包含了回车符(\r)或者换行符(\n) 解决方法: (1)对这些字符转义: json_data = json_data.r
-
python对html代码进行escape编码的方法
本文实例讲述了python对html代码进行escape编码的方法.分享给大家供大家参考.具体分析如下: python包含一个cgi模块,该模块有一个escape函数可以用来对html代码进行编码转换 import cgi s1 = "Hello <strong>world</strong>" s2 = cgi.escape(s1) assert s2 == "Hello <strong>world</strong>"