js中查找最近的共有祖先元素的实现代码
先来看概念,首先DOM是一棵树,其根节点是Document,大致可以用下图来表示: 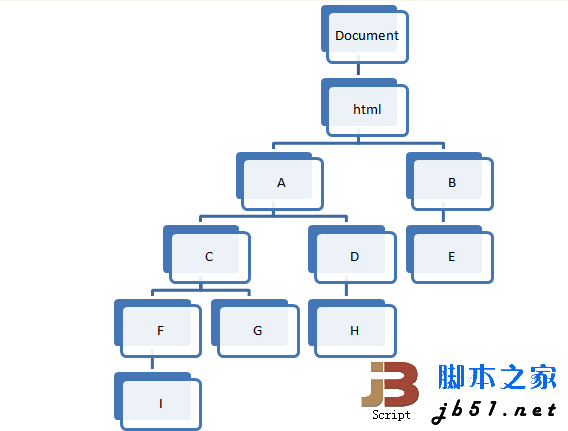
所谓“最近的共有祖先元素”,是指给定一系列元素,找出在树中深度最大的,但同时为所有这些元素的祖先元素的元素。
比如上图中,I和G的结果为C,G和H的结果为A,D和E的结果为html,C和B的结果为html等。
测试驱动
对于偏逻辑的题,并没有十足的把握函数是正确的,因此还是先构造测试的用命,力求让函数通过测试。
本次就以上图的结构作为DOM结构,A表示body,B表示head,其他节点均使用div元素,同时以上文中所说的作为测试的输入和输出,先构造一下测试:
代码如下:
function test() {
var result;
result = find('i', 'g');
result.id !== 'c' && alert('fail (i, g)');
result = find('g', 'h');
result.id !== 'a' && alert('fail (g, h)');
result = find('d', 'e');
result.nodeName.toLowerCase() !== 'html' && alert('fail (d, e)');
result = find('c', 'b');
result.nodeName.toLowerCase() !== 'html' && alert('fail (c, b)');
}
基本逻辑
这次的逻辑大致是这样的:
1、针对每个给定的元素,从父元素到document依次向上遍历。
2、对遍历过程中经过的每个元素,保存到一个有序的map中,以元素为键,以遍历到的次数为值。
2、最后遍历map,找同第一个值与给定元素个数相同的项,就是第一个被所有元素的遍历都经过的元素,也即最近的共同祖先元素了。
细节问题
在实际过程中,对map的构建比较重要,这里涉及到2个问题:
1、map不能直接以元素作为键,必须转换为合适的基元类型(如number, string, Regex等)。
2、chrome对object中的键会有自动排序,因此尽量避免使用number类型作为键。
对于第一个问题,必须给元素绑定一个合适的字段,起到唯一性标识符的作用。好在HTML5提供了data-*属性,使DOM的元数据承载能力有了很大的提高,可以大胆地添加希望的属性了。
对于第二个问题,本身也不难,生成的标识符避开number就行了,方便的方法是加个下划线,或者使用String.fromCharCode转成字符,无论怎么样都无所谓。
实现代码
代码有点长,主要是个人比较喜欢偏JAVA的风格,每一个语句每一个分支都清清楚楚,不喜欢用&&或者||来处理条件分支,所以有很多行只有一个大括号之类的情况,其实真正有效的代码还是精简的。懒得装类似toggle之类的插件,也不想看到滚动条,就随便扔在这了。
代码如下:
function find() {
var length = arguments.length,
i = 0,
node, //当前节点
parent, //父节点
counter = 0,
uuid, //给DOM的唯一标识符
hash = {}; //最后结果的map
//对每一个元素,向上遍历至document
//这个双层的循环是不可避免的
for (; i < length; i++) {
//获取node
node = arguments[i];
if (typeof node == 'string') {
node = document.getElementById(node);
}
//向上遍历
while (parent = node.parentElement || node.parentNode) {
//到document就停下来,不然就是死循环
if (parent.nodeType == 9) {
break;
}
//获取或添加一下标识符
uuid = parent.getAttribute('data-find');
if (!uuid) {
uuid = '_' + (++counter); //避免chrome对hash重排序
parent.setAttribute('data-find', uuid);
}
//增加计数
if (hash[uuid]) {
hash[uuid].count++;
}
else {
hash[uuid] = {node: parent, count: 1};
}
node = parent;
}
}
//hash中只存有各节点向上遍历经过的父节点,不应该很大
//因此这个循环是比较快的
for (i in hash) {
if (hash[i].count == length) {
return hash[i].node;
}
}
};
点评
测试没问题,但测试用例是否完善实在不好说,期待网友帮我找出问题来,对于逻辑型的实在是没啥自信说100%没问题。
对于取父元素,习惯性兼容IE写成parentElement || parentNode,这是因为IE的一个BUG,当一个元素刚被创建出来但未进入DOM时,parentNode是不存在的。不过本次函数保证节点在DOM树中,其实parentElement就没有必要了。所以有时候习惯性的兼容代码也不见得就一定是好事,最适合当前环境的代码才是好代码。
虽然说2重循环不可避免,但总隐隐感觉循环还是有办法在特定情况下少做点事,比如向上遍历的时候发现某个元素已经不可能是所有元素的共有祖先了,那么就不要再去递增count值了。
最后的for..in循环有没有办法省掉呢?在上面的2重循环中有没有办法实时地就通过一个变量始终保存最合适的节点呢?
相关推荐
-

js中查找最近的共有祖先元素的实现代码
先来看概念,首先DOM是一棵树,其根节点是Document,大致可以用下图来表示: 所谓"最近的共有祖先元素",是指给定一系列元素,找出在树中深度最大的,但同时为所有这些元素的祖先元素的元素. 比如上图中,I和G的结果为C,G和H的结果为A,D和E的结果为html,C和B的结果为html等. 测试驱动 对于偏逻辑的题,并没有十足的把握函数是正确的,因此还是先构造测试的用命,力求让函数通过测试. 本次就以上图的结构作为DOM结构,A表示body,B表示head,其他节点均使用div元素,
-
js中利用tagname和id获取元素的方法
本文分享了js中利用tagname和id获取元素的3种方法,供大家参考,具体内容如下 方法一:整体法,先获取所有的元素,再通过ai+-b的方法来算出需要的元素 方法二:数组法,在全局环境下建立空数组,遇到需要循环的结构时,在循环中获取元素,并放入数组 方法三:函数法,遇到相同的几组元素时,只操作一组元素,并用函数传参来实现所有的效果 具体代码如下 <!DOCTYPE html> <html lang="en"> <head> <meta cha
-
JS中注入eval, Function等系统函数截获动态代码
现在很多网站都上了各种前端反爬手段,无论手段如何,最重要的是要把包含反爬手段的前端javascript代码加密隐藏起来,然后在运行时实时解密动态执行. 动态执行js代码无非两种方法,即eval和Function.那么,不管网站加密代码写的多牛,我们只要将这两个方法hook住,即可获取到解密后的可执行js代码. 注意,有些网站会检测eval和Function这两个方法是否原生,因此需要一些小花招来忽悠过去. 挂钩代码 首先是eval的挂钩代码: (function() { if (window._
-
JAVA中数组插入与删除指定元素的实例代码
今天学了Java的数组,写了数组的插入和删除,本人小白,写给不会的小白看,大神请忽略,有错请大家指出来: /** 给数组指定位置数组的插入 */ import java.util.*; public class ArrayInsert{ public static void main(String []args){ System.out.println("请用键盘输入5个数:"); int [] array =new int[10]; Scanner sc=new Scanner(Sy
-
JS中使用DOM来控制HTML元素
1.getElementsByName():获取name. ~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~` 例: <p name="pn">hello</p> <p name="pn">hello</p> <p name="pn">hello</p> <script> function getName(){ var count=docume
-
jquery 查找iframe父级页面元素的实现代码
父页面代码 复制代码 代码如下: <!DOCTYPE html PUBLIC "-//W3C//DTD XHTML 1.0 Transitional//EN" "http://www.w3.org/TR/xhtml1/DTD/xhtml1-transitional.dtd"> <html xmlns="http://www.w3.org/1999/xhtml"> <head> <meta http-equ
-
jquery中通过过滤器获取表单元素的实现代码
:enable 获取可输入状态的元素 :disabled 获取不可输入状态的元素 :checked 获取选中的表单元素 :seleced 获取下拉框中选中的元素 下面看一粒例子 Html 复制代码 代码如下: <body> <form id="form1" runat="server"> <div> <ul> <li><label>订单号码:</label><input typ
-
js中的escape及unescape函数的php实现代码
<? function phpescape($str) { $sublen=strlen($str); $retrunString=""; for ($i=0;$i<$sublen;$i++) { if(ord($str[$i])>=127) { $
-
js中if语句的几种优化代码写法
尽管我还没使用它去做一些尝试性的测试,但从这里可以看到它的确对js作了美化的工作.也许有人认为if语句就那么简单,能优化到什么程度?但是看看以下的几种方式,你也许会改变看法. 一.使用常见的三元操作符 复制代码 代码如下: if (foo) bar(); else baz(); ==> foo?bar():baz(); if (!foo) bar(); else baz(); ==> foo?baz():bar(); if (foo) return bar(); else return baz
-
js中onload与onunload的使用示例
引言: 今天周末没事,就想起前面自己做的一个B2C的电子商务平台,还有些一些地方没有完善,就想着完善,嗯,问题是这样的,在电子商务平台中有这样一个场景,我将购物车放置在Session中,使其在整个购物的过程中都能从Session中得到购物车模型,我在购物车某型中有的商品都会在数据库中减少其购物车中购买的数量,但是如果我关闭窗口,怎样让Session中的购物车模型中的商品数量添加到数据库中,于是我查找了GOOGLE.百度,得到的第一个提示,就是:关闭窗口自动清除Session,于是找到的第一个方法