python lxml中etree的简单应用
我一般都是通过xpath解析DOM树的时候会使用lxml的etree,可以很方便的从html源码中得到自己想要的内容。
这里主要介绍一下我常用到的两个方法,分别是etree.HTML()和etree.tostrint()。
1.etree.HTML()
etree.HTML()可以用来解析字符串格式的HTML文档对象,将传进去的字符串转变成_Element对象。作为_Element对象,可以方便的使用getparent()、remove()、xpath()等方法。
如果想通过xpath获取html源码中的内容,就要先将html源码转换成_Element对象,然后再使用xpath()方法进行解析。例如,这里有一段最简单的html源码:"<html><body><h1>This is a test</h1></body></html>",现在想要得到h1标签中的文本,可以这样实现:
# encoding=utf8
from lxml import etree
html = '<html><body><h1>This is a test</h1></body></html>'
# 将html转换成_Element对象
_element = etree.HTML(html)
# 通过xpath表达式获取h1标签中的文本
text = _element.xpath('//h1/text()')
print 'result is: ', text
结果:
result is: ['This is a test']
通过结果可以知道,xpath()方法放回的结果是一个列表,所以通常在取xpath()方法结果的时候,只取列表中的第一个元素。
2.etree.tostring()
etree.tostring()方法用来将_Element对象转换成字符串。一般通过简单的xpath表达式无法得到想要的内容的时候我就会用该方法。例如,将上面的html小改动一下:"<html><body><h1>This <a>is a </a>test</h1></body></html>",这时候如果想要得到h1中的文本该怎么办呢?使用“//h1/text()”试试(将上面的html保存并用火狐浏览器打开,然后在FirePath中输入该xpath表达式):
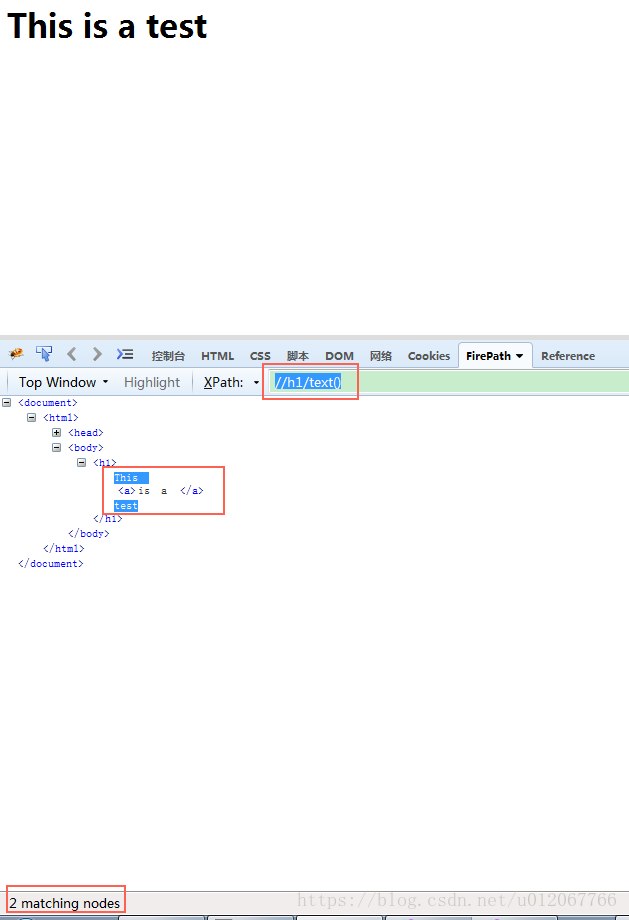
通过截图左下角的提示可以知道,使用xpath表达式“//h1/text()”只能得到h1标签中文本的“This”和“test”,用代码实现看看:
# encoding=utf8
from lxml import etree
html = '<html><body><h1>This <a>is a </a>test</h1></body></html>'
_element = etree.HTML(html)
text = _element.xpath('//h1/text()')
print 'result is: ', text
运行结果:
result is: ['This ', 'test']
确实,使用xpath()方法,只能得到h1中部分文本内容,我们再试试使用“//h1//text()”看看:
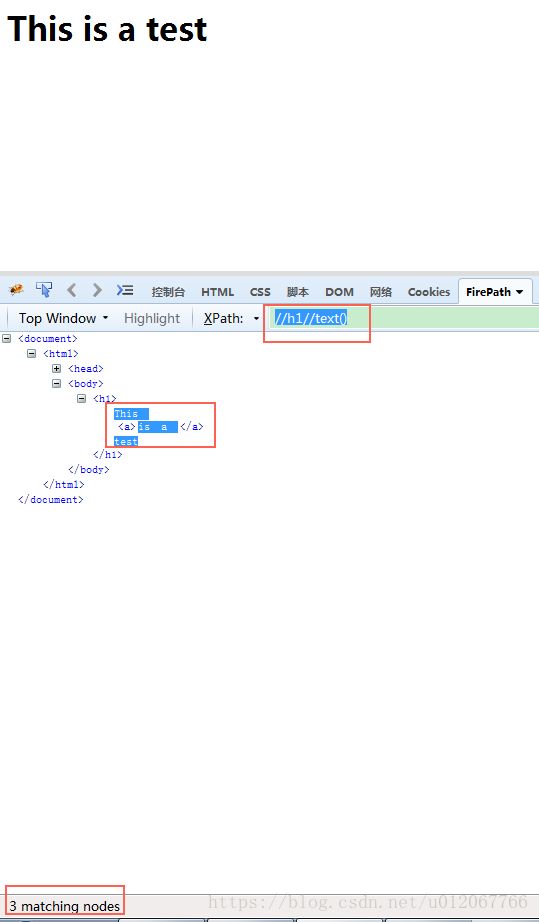
然后通过代码实现看看:
# encoding=utf8
from lxml import etree
html = '<html><body><h1>This <a>is a </a>test</h1></body></html>'
_element = etree.HTML(html)
text = _element.xpath('//h1//text()')
print 'result is: ', text
运行结果:
result is: ['This ', 'is a ', 'test']
通过“//h1//text()”表达式确实可以得到想要的内容,但是得到的是一个列表,还需要将列表中的所有元素“拼”起来才行,是不是有点麻烦。这时候,就可以考虑使用etree.tostring()方法了,etree.tostring()方法可以传递多个参数,包括element_or_tree、encoding、method等,其中method参数为text的时候,表示返回_Element对象中的所有文本,所以可以这样:
# encoding=utf8
from lxml import etree
html = '<html><body><h1>This <a>is a </a>test</h1></body></html>'
_element = etree.HTML(html)
# 先找到h1对象,然后通过etree.tostring方法找到h1对象中的所有文本
_h = _element.xpath('//h1')
# 注意,xpath方法返回的是一个列表,我们需要的是列表中的第一个元素:代表h1标签的_Element对象
result = etree.tostring(_h[0], method='text')
print 'result is: ', result
运行结果:
result is: This is a test
这时候使用etree.tostring()方法是不是很容易的就解决问题了。
以上就是本文的全部内容,希望对大家的学习有所帮助,也希望大家多多支持我们。
相关推荐
-

Python爬虫基础之XPath语法与lxml库的用法详解
前言 本来打算写的标题是XPath语法,但是想了一下Python中的解析库lxml,使用的是Xpath语法,同样也是效率比较高的解析方法,所以就写成了XPath语法和lxml库的用法 XPath 即为 XML 路径语言,它是一种用来确定 XML(标准通用标记语言的子集)文档中某部分位置的语言. XPath 基于 XML 的树状结构,提供在数据结构树中找寻节点的能力. XPath 同样也支持HTML. XPath 是一门小型的查询语言. python 中 lxml库 使用的是 Xpath 语法,是
-
Python lxml解析HTML并用xpath获取元素的方法
代码 使用方法见注释 #-*- coding: UTF-8 -*- from lxml import etree source = u''' <div><p class="p1" data-a="1">测试数据1</p> <p class="p1" data-a="2">测试数据2</p> <p class="p1" data-a="
-
python库lxml在linux和WIN系统下的安装
lxml是python的一个解析库,支持HTML和XML的解析,支持XPath解析方式,而且解析效率非常高 XPath,全称XML Path Language,即XML路径语言,它是一门在XML文档中查找信息的语言,它最初是用来搜寻XML文档的,但是它同样适用于HTML文档的搜索 XPath的选择功能十分强大,它提供了非常简明的路径选择表达式,另外,它还提供了超过100个内建函数,用于字符串.数值.时间的匹配以及节点.序列的处理等,几乎所有我们想要定位的节点,都可以用XPath来选择 XPath
-
Python lxml模块安装教程
lxml是Python中与XML及HTML相关功能中最丰富和最容易使用的库.lxml并不是Python自带的包,而是为libxml2和libxslt库的一个Python化的绑定.它与众不同的地方是它兼顾了这些库的速度和功能完整性,以及纯Python API的简洁性,与大家熟知的ElementTree API兼容但比之更优越!但安装lxml却又有点麻烦,因为存在依赖,直接安装的话用easy_install, pip都不能成功,会报gcc错误.下面列出来Windows.Linux下面的安装方法: [
-
python利用lxml读写xml格式的文件
之前在转换数据集格式的时候需要将json转换到xml文件,用lxml包进行操作非常方便. 1. 写xml文件 a) 用etree和objectify from lxml import etree, objectify E = objectify.ElementMaker(annotate=False) anno_tree = E.annotation( E.folder('VOC2014_instance'), E.filename("test.jpg"), E.source( E.d
-
Python pip安装lxml出错的问题解决办法
Python pip安装lxml出错的问题解决办法 1. 在使用pip安装lxml过程中出现了一下错误: >>> pip install lxml C:\Users\Chen>pip install lxml Collecting lxml Using cached lxml-3.5.0.tar.gz Installing collected packages: lxml Running setup.py install for lxml ... error Complete
-
在windows系统中实现python3安装lxml
lxml是Python中与XML及HTML相关功能中最丰富和最容易使用的库.lxml并不是Python自带的包,而是为libxml2和libxslt库的一个Python化的绑定.它与众不同的地方是它兼顾了这些库的速度和功能完整性,以及纯Python API的简洁性,与大家熟知的ElementTree API兼容但比之更优越!但安装lxml却又有点麻烦,因为存在依赖,直接安装的话用easy_install, pip都不能成功,会报gcc错误. 爬虫时通常要安装LXML,对于通过一下命令行 pip
-
python3解析库lxml的安装与基本使用
前言 在爬虫的学习中,我们爬取网页信息之后就是对信息项匹配,这个时候一般是使用正则.但是在使用中发现正则写的不好的时候不能精确匹配(这其实是自己的问题!)所以就找啊找.想到了可以通过标签来进行精确匹配岂不是比正则要快.所以找到了lxml. lxml是python的一个解析库,支持HTML和XML的解析,支持XPath解析方式,而且解析效率非常高 XPath,全称XML Path Language,即XML路径语言,它是一门在XML文档中查找信息的语言,它最初是用来搜寻XML文档的,但是它同样适用
-
python lxml中etree的简单应用
我一般都是通过xpath解析DOM树的时候会使用lxml的etree,可以很方便的从html源码中得到自己想要的内容. 这里主要介绍一下我常用到的两个方法,分别是etree.HTML()和etree.tostrint(). 1.etree.HTML() etree.HTML()可以用来解析字符串格式的HTML文档对象,将传进去的字符串转变成_Element对象.作为_Element对象,可以方便的使用getparent().remove().xpath()等方法. 如果想通过xpath获取htm
-
详解Python odoo中嵌入html简单的分页功能
在odoo中,通过iframe嵌入 html,页面数据则通过controllers获取,使用jinja2模板传值渲染 html页面分页内容,这里写了判断逻辑 <!-- 分页 --> <ul id="ty_paging"> <li class="home" id="home"><a href="/car/budget/report/1" rel="external nofoll
-
python 中 lxml 的 etree 标签解析
一.安装 pip install lxml 二.创建标签 from lxml import etree root = etree.Element('root') 三.添加子节点 from lxml import etree root = etree.Element('root') span = etree.SubElement(root, 'span') 四.删除子节点 from lxml import etree root = etree.Element('root') span = etre
-
Python lxml库的简单介绍及基本使用讲解
1.lxml库介绍 lxml是XML和HTML的解析器,其主要功能是解析和提取XML和HTML中的数据:lxml和正则一样,也是用C语言实现的,是一款高性能的python HTML.XML解析器,也可以利用XPath语法,来定位特定的元素及节点信息 HTML是超文本标记语言,主要用于显示数据,他的焦点是数据的外观 XML是可扩展标记语言,主要用于传输和存储数据,他的焦点是数据的内容 2.安装lxml方法 方法1: 在cmd运行窗口中输入:pip install lxml 方法2: 在Pychar
-
python中for语句简单遍历数据的方法
本文实例讲述了python中for语句简单遍历数据的方法.分享给大家供大家参考.具体如下: 复制代码 代码如下: for name in ["kak", "John", "Mani", "Matt"]: print(name) 运行结果如下: 复制代码 代码如下: kak John Mani Matt 希望本文所述对大家的Python程序设计有所帮助.
-
在Python 3中实现类型检查器的简单方法
示例函数 为了开发类型检查器,我们需要一个简单的函数对其进行实验.欧几里得算法就是一个完美的例子: def gcd(a, b): '''Return the greatest common divisor of a and b.''' a = abs(a) b = abs(b) if a < b: a, b = b, a while b != 0: a, b = b, a % b return a 在上面的示例中,参数 a 和 b 以及返回值应该是 int 类型的.预期的类型将会以函数注解的形式
-
快速了解Python开发中的cookie及简单代码示例
cookie :是用户保存在用户浏览器端的一对键值对,是为了解决http的无状态连接.服务端是可以把 cookie写到用户浏览器上,用户每次发请求会携带cookie. 存放位置: 每次发请求cookie是放在请求头里面的. 应用场景: ·登陆用户和密码的记住密码 ·显示每页显示的数据,以后都是按照设定的数目显示 ·投票机制 案例用户登录 创建用户登录的url url(r'^login/', views.login), 创建登录页面 代码为: <!DOCTYPE html> <html l
-
Python中join函数简单代码示例
本文简述的是string.join(words[, sep]),它的功能是把字符串或者列表,元组等的元素给拼接起来,返回一个字符串,和split()函数与正好相反,看下面的代码理解. 首先展示下结果吧! 代码分享: a=["豫","N","C8","C89"] b=("豫","N","C8","C89") c="zhang" a
-
Python中str.join()简单用法示例
本文实例讲述了Python中str.join()简单用法.分享给大家供大家参考,具体如下: Python join() 方法用于将序列中的元素以指定的字符连接生成一个新的字符串.其中,序列中的元素应是字符串类型. join()方法语法: str.join(sequence) 例子: >>> str='-' >>> l=['2016','5','9'] >>> t=('2016','5','9') >>> str.join(l) '20
-
对python多线程中互斥锁Threading.Lock的简单应用详解
一.线程共享进程资源 每个线程互相独立,相互之间没有任何关系,但是在同一个进程中的资源,线程是共享的,如果不进行资源的合理分配,对数据造成破坏,使得线程运行的结果不可预期.这种现象称为"线程不安全". 实例如下: #-*- coding: utf-8 -*- import threading import time def test_xc(): f = open("test.txt","a") f.write("test_dxc&quo