pandas数据处理基础之筛选指定行或者指定列的数据
pandas主要的两个数据结构是:series(相当于一行或一列数据机构)和DataFrame(相当于多行多列的一个表格数据机构)。
本文为了方便理解会与excel或者sql操作行或列来进行联想类比
1.重新索引:reindex和ix
上一篇中介绍过数据读取后默认的行索引是0,1,2,3...这样的顺序号。列索引相当于字段名(即第一行数据),这里重新索引意思就是可以将默认的索引重新修改成自己想要的样子。
1.1 Series
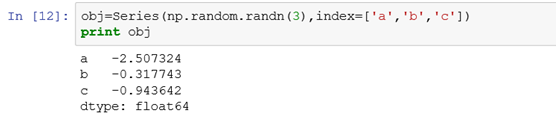
比方说:data=Series([4,5,6],index=['a','b','c']),行索引为a,b,c。
我们用data.reindex(['a','c','d','e'])修改索引后则输出:

可以理解成我们用reindex设了索引后,根据索引去原来data里面匹配对应的值,没匹配上的就是NaN。
1.2 DataFrame
(1)行索引修改:DataFrame行索引同Series
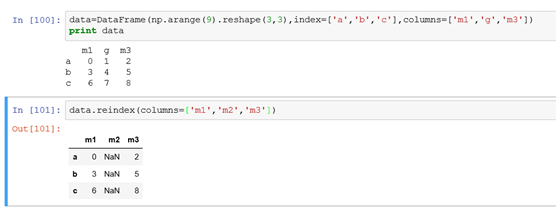
(2)列索引修改:列索引用reindex(columns=['m1','m2','m3']),用参数columns来指定对列索引进行修改。修改逻辑类似行索引,也是相当于用新列索引去匹配原来的数据,没匹配上的置NaN
例:
(3)同时对行和列索引进行修改可以用
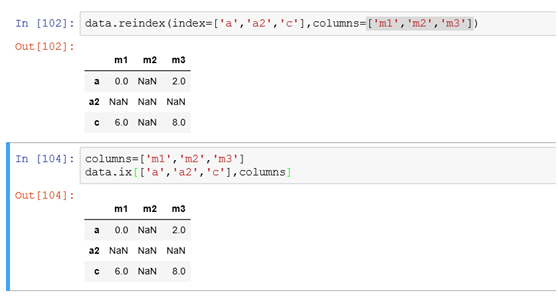
2.丢弃指定轴上的列(通俗的说法就是删除行或者列):drop
通过索引进行选择删除哪一行或者哪一列
data.drop(['a','c']) 相当于delete table a where xid='a' or xid='c'
data.drop('m1',axis=1)相当于delete table a where yid='m1'
3.选取和过滤(通俗的说就是sql中按照条件筛选查询)
python中因为有行列索引,在做数据的筛选会比较方便
3.1 Series
(1)按照行索引进行选择如
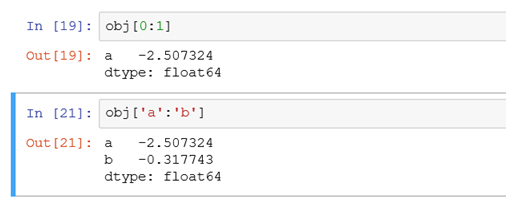
obj['b']相当于select * from tb where xid='b'obj['b','a','c']相当于select * from tb where xid in ('a','b','c'),且结果按照b ,a ,c 的顺序排列后进行展示,这是与sql的区别obj[0:1]和obj['a':'b']的区别如下:
#前者是不包含末端,后者是包含了末端
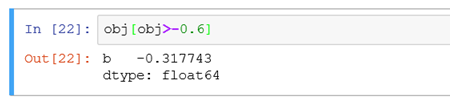
(2)按照值的大小进行筛选obj[obj>-0.6]相当于在obj数据中找出值比-0.6大的记录进行展示
3.2 DataFrame
(1)选择单行用ix或者xs:
如筛选索引为b的那条行记录用以下三种方式

(2)选择多行:
筛选索引为a,b的两条行记录的方式

#以上不能直接写成data[['a','b']]
data[0:2]表示从第一行到第二行的记录。第一行默认从0开始数,不包含末端的2。
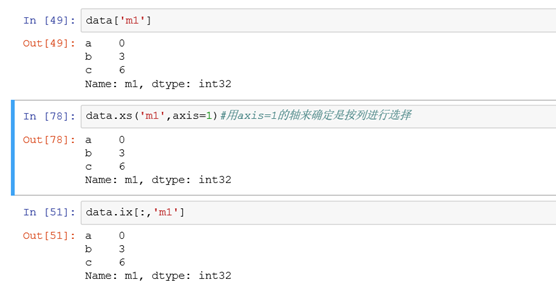
(3)选择单列
筛选m1列的所有行记录数据
(4)选择多列
筛选m1,m3两个列,所有行记录的数据
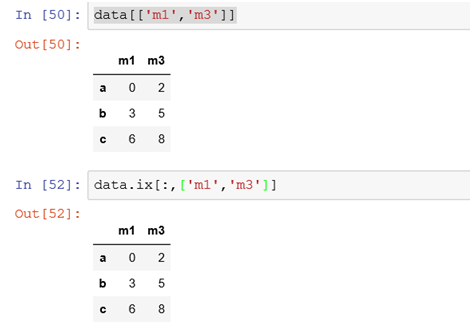
ix[:,['m1','m2']]前面的:表示所有的行都筛选进来。
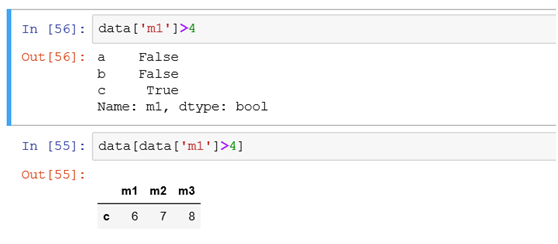
(5)根据值的大小条件筛选行或者列
如筛选出某一列值大于4的所有记录相当于select * from tb where 列名>4
(6)如果筛选某列值大于4的所有记录,且只需展示部分列的情况时

行用条件进行筛选,列用[0,2]筛选第一列和第三列的数据
总结
以上所述是小编给大家介绍的pandas数据处理基础之筛选指定行或者指定列的数据,希望对大家有所帮助,如果大家有任何疑问请给我留言,小编会及时回复大家的。在此也非常感谢大家对我们网站的支持!
您可能感兴趣的文章:
- Python 数据处理库 pandas进阶教程
- Python 数据处理库 pandas 入门教程基本操作
- pandas系列之DataFrame 行列数据筛选实例
- pandas按若干个列的组合条件筛选数据的方法
相关推荐
-
pandas按若干个列的组合条件筛选数据的方法
还是用图说话 A文件: 比如,我想筛选出"设计井别"."投产井别"."目前井别"三列数据都为11的数据,结果如下: 当然,这里的筛选条件可以根据用户需要自由调整,代码如下: # -*- coding: utf-8 -*- """ Created on Wed Nov 29 10:46:31 2017 @author: wq """ import pandas as pd #input.c
-

Python 数据处理库 pandas 入门教程基本操作
pandas是一个Python语言的软件包,在我们使用Python语言进行机器学习编程的时候,这是一个非常常用的基础编程库.本文是对它的一个入门教程. pandas提供了快速,灵活和富有表现力的数据结构,目的是使"关系"或"标记"数据的工作既简单又直观.它旨在成为在Python中进行实际数据分析的高级构建块. 入门介绍 pandas适合于许多不同类型的数据,包括: 具有异构类型列的表格数据,例如SQL表格或Excel数据 有序和无序(不一定是固定频率)时间序列数据.
-
Python 数据处理库 pandas进阶教程
前言 本文紧接着前一篇的入门教程,会介绍一些关于pandas的进阶知识.建议读者在阅读本文之前先看完pandas入门教程. 同样的,本文的测试数据和源码可以在这里获取: Github:pandas_tutorial. 数据访问 在入门教程中,我们已经使用过访问数据的方法.这里我们再集中看一下. 注:这里的数据访问方法既适用于Series,也适用于DataFrame. 基础方法:[]和. 这是两种最直观的方法,任何有面向对象编程经验的人应该都很容易理解.下面是一个代码示例: # select_da
-
pandas系列之DataFrame 行列数据筛选实例
一.对DataFrame的认知 DataFrame的本质是行(index)列(column)索引+多列数据. 为了简化理解,我们不妨换个思路- 现实中,为了简化对一件事物的描述,我们会选择几个特征. 例如,从(性别.身高.学历.职业.爱好..)等角度去刻画一个人,这些"角度"即为"特征". 其中,不同的行表示不同的记录:列代表特征,不同记录因各个特征之间的差异而不同. DataFrame默认索引是序号(0,1,2-),可以理解成位置索引.一般我们用id标识不同记录,
-
pandas数据处理基础之筛选指定行或者指定列的数据
pandas主要的两个数据结构是:series(相当于一行或一列数据机构)和DataFrame(相当于多行多列的一个表格数据机构). 本文为了方便理解会与excel或者sql操作行或列来进行联想类比 1.重新索引:reindex和ix 上一篇中介绍过数据读取后默认的行索引是0,1,2,3...这样的顺序号.列索引相当于字段名(即第一行数据),这里重新索引意思就是可以将默认的索引重新修改成自己想要的样子. 1.1 Series 比方说:data=Series([4,5,6],index=['a',
-
numpy 实现返回指定行的指定元素的位置索引
先上代码,主要语句为np.where(b[c]==1), 详细解释如下: import numpy as np b = np.array([[-2,-3,0,0,0,6,4,1],[88,1,0,0,0,6,4,2],[99,6,0,0,1,6,4,2]]) # 三行八列的数组b print('b\n',b) c = np.array([2,0]) # c表示指定行 print('b[c]\n',b[c]) # b[c]返回 数组b的指定行 这里依次返回了b的下标为2和0的行 print('\n
-
MySQL使用select语句查询指定表中指定列(字段)的数据
本文介绍MySQL数据库中执行select查询语句,查询指定列的数据,即指定字段的数据. 再来回顾一下SQL语句中的select语句的语法: Select 语句的基本语法: Select <列的集合> from <表名> where <条件> order by <排序字段和方式> 如果要查询某个表中的指定列的所有数据,则查询语句可以写作: select 列名1,列名2,列名3... from <表名> 要说明一个,这个语句后面仍然可以使用wher
-
pandas删除指定行详解
在处理pandas的DataFrame中,如果想像excel那样筛选,只要其中的某一行或者几行,可以使用isin()方法来实现,只需要将需要的行值以列表方式传入即可,还可传入字典,进行指定筛选. pandas.DataFrame中删除包涵特定字符串所在的行:https://www.jb51.net/article/159052.htm 以上所述是小编给大家介绍的pandas删除指定行详解整合,希望对大家有所帮助,如果大家有任何疑问请给我留言,小编会及时回复大家的.在此也非常感谢大家对我们网站的支
-
asp.net DataTable相关操作集锦(筛选,取前N条数据,去重复行,获取指定列数据等)
本文实例总结了asp.net DataTable相关操作.分享给大家供大家参考,具体如下: #region DataTable筛选,排序返回符合条件行组成的新DataTable或直接用DefaultView按条件返回 /// <summary> /// DataTable筛选,排序返回符合条件行组成的新DataTable或直接用DefaultView按条件返回 /// eg:SortExprDataTable(dt,"Sex='男'","Time Desc&quo
-
python pandas获取csv指定行 列的操作方法
pandas获取csv指定行,列 house_info = pd.read_csv('house_info.csv') 1:取行的操作: house_info.loc[3:6]类似于python的切片操作 2:取列操作: house_info['price'] 这是读取csv文件时默认的第一行索引 3:取两列 house_info[['price',tradetypename']] 取多个列也是同理的,注意里面是一个list的列表,不然会报错误: 4:增加列: house_Info['adre
-
Python pandas删除指定行/列数据的方法实例
目录 1.滤除缺失数据dropna() 1)滤除含有NaN值的所有行 2)滤除含有NaN值的所有列 3)滤除元素都是NaN值的行 4)滤除元素都是NaN值的列 5)滤除指定列中含有缺失的行 2.删除重复值 drop_duplicates() 1)keep=“first” 2)keep=“last” 3)keep=False 4)删除指定列中重复项对应的行 3.根据指定条件删除行列drop() 1).删除指定列 2).删除指定行 总结 1.滤除缺失数据dropna() import pandas
-
python pandas库读取excel/csv中指定行或列数据
目录 引言 1.根据index查询 2.已知数据在第几行找到想要的数据 3.根据条件查询找到指定行数据 4.找出指定列 5.找出指定的行和指定的列 6.在规定范围内找出符合条件的数据 总结 引言 关键!!!!使用loc函数来查找. 话不多说,直接演示: 有以下名为try.xlsx表: 1.根据index查询 条件:首先导入的数据必须的有index 或者自己添加吧,方法简单,读取excel文件时直接加index_col 代码示例: import pandas as pd #导入pandas库 ex
-
python pandas数据处理之删除特定行与列
目录 dropna() 方法过滤任何含有缺失值的行 方法一:dropna() 其他参数解析 方法二:替换并删除,Python pandas 如果某列值为空,过滤删除所在行数据 总结 dropna() 方法过滤任何含有缺失值的行 pandas.DataFrame里,如果一行数据有任意值为空,则过滤掉整行,这时候使用dropna()方法是合适的.下面的案例,任意列只要有一个为空数据,则整行都干掉.但是我们常常遇到的情况,是根据一个指标(一列)数据的情况,去过滤行数据,类似Excel里面的过滤漏斗,怎
-
python pandas数据处理教程之合并与拼接
目录 前言 一.join 1.leftjoin 2.rightjoin 3.innerjoin 4.outjoin 二.merge 三.concat 1.纵向合并 2.横向合并 四.append 1.同结构数据追加 2.不同结构数据追加 3.追加合并多个数据集 五.combine_first 六.update 总结 前言 在许多应用中,数据可能来自不同的渠道,在数据处理的过程中常常需要将这些数据集进行组合合并拼接,形成更加丰富的数据集.pandas提供了多种方法完全可以满足数据处理的常用需求.具