基于Python实现微博抓取GUI程序
目录
- 前言
- 微博功能布局
- 创建微博 Widget
- 创建微博查询
- 词云制作
- 结果展示
前言
在前面的分享中,我们制作了一个天眼查 GUI 程序,今天我们在这个的基础上,继续开发新的功能,微博抓取工具,先来看下最终的效果
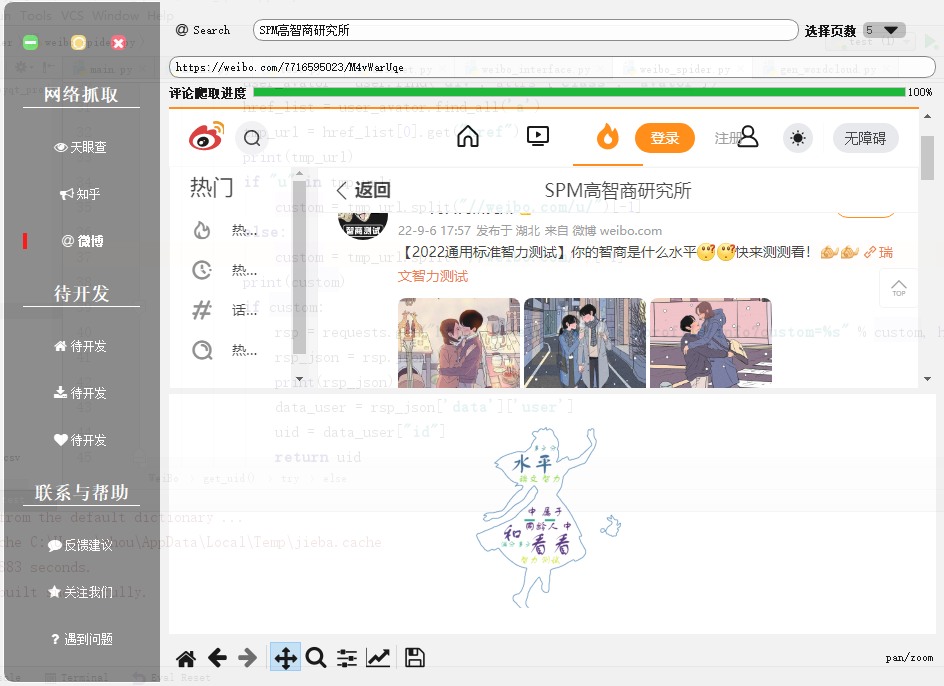
整体的界面还是继承自上次的天眼查界面,我们直接来看相关功能
微博功能布局
我们整体的界面布局就是左侧可以选择不同功能,然后右侧的界面会对应改变
创建微博 Widget
对于右侧界面的切换,我们可以为不同的功能创建不同的 Widget,当点击左侧不同功能按钮后,对应切换 Widget 即可
我们新建一个 weibo 相关的函数,主要用来界面布局
def weiboWidget(self): self.left_button_widget_3 = QtWidgets.QWidget() self.weiboWebEngine = QWebEngineView() self.weiboWebEngine2 = QWebEngineView() self.progressWidget = QtWidgets.QWidget() self.ciyunWidget = QtWidgets.QWidget()
我们还看到整体界面有一个词云,该词云是通过 matplotlib 渲染的,所以还需要创建 matplotlib 布局
# matplotlib 绘图区域 self.figure = plt.figure(figsize=(7, 2)) self.canvas = FigureCanvasQTAgg(self.figure) # 绘图区域放到图层canvas之中 self.gridLayout_weibo.addWidget(self.canvas, 5, 0, 1, 9) # 图层放到pyqt布局之中
创建微博查询
接下来我们创建一个微博查询函数,同时因为我们这里需要实时更新抓取进度条,所以使用了多线程的方式
def doWeiboQuery(self): weibo_link = self.lineEdit_weibo_link.text() weibo_name = self.lineEdit_weibo_name.text() weibo_page = self.weibo_comboBox.currentText() if not weibo_link or not weibo_name: QMessageBox.information(self, "Error", "微博链接或者用户名称不能为空", QMessageBox.Yes) return self.weiboWebEngine.load(QUrl(weibo_link)) self.qth = WeiBoQueryThread() self.qth.update_data.connect(self.weiboPgbUpdate) self.qth.draw_ciyun.connect(self.drawCiyun) self.qth.weibo_page = weibo_page self.qth.weibo_link = weibo_link self.qth.weibo_name = weibo_name self.qth.start()
而主线程与子线程之间的通信,是使用信号槽的形式
def weiboPgbUpdate(self, data): self.pgb.setValue(data) def drawCiyun(self): self.canvas.draw() self.toolbar = NavigationToolbar2QT(self.canvas, self) self.gridLayout_weibo.addWidget(self.toolbar, 8, 0, 1, 9)
接下来就是创建子进程函数,函数主体是爬取微博的代码
"""子进程微博查询"""
class WeiBoQueryThread(QThread):
# 创建一个信号,触发时传递当前时间给槽函数
update_data = pyqtSignal(int)
draw_ciyun = pyqtSignal()
weibo_name = None
weibo_link = None
weibo_page = None
total_pv = 0
timestamp = str(int(time.time()))
def run(self):
# 微博爬虫
try:
file_name = self.weibo_name + "_" + self.timestamp + 'comment.csv'
my_weibo = weibo_interface.Weibo(self.weibo_name)
uid, blog_info = my_weibo.weibo_info(self.weibo_link)
pv_max = int(self.weibo_page)
pre_pv = 100 // pv_max
for i in range(int(self.weibo_page)):
my_weibo.weibo_comment(uid, blog_info, str(i), file_name)
self.total_pv += pre_pv
self.update_data.emit(self.total_pv)
print("所有微博评论爬取完成!")
print("开始生成词云")
font, img_array, STOPWORDS, words = ciyun(file_name)
wc = WordCloud(width=2000, height=1800, background_color='white', font_path=font, mask=img_array,
stopwords=STOPWORDS, contour_width=3, contour_color='steelblue').generate(words)
plt.imshow(wc)
plt.axis("off")
self.draw_ciyun.emit()
print("生成词云完成")
except Exception as e:
print(e)
而对于微博的具体爬取方法,这里就不再展开说明了,我是把所有微博爬虫的代码都封装好了,这里直接调用暴露的接口即可
词云制作
对于词云的制作,我们还是先通过 jieba 进行分词处理,然后使用 wordcloud 库生成词云即可
# 词云相关
def ciyun(file, without_english=True):
font = r'C:\Windows\Fonts\FZSTK.TTF'
STOPWORDS = {"回复", "@", "我", "她", "你", "他", "了", "的", "吧", "吗", "在", "啊", "不", "也", "还", "是",
"说", "都", "就", "没", "做", "人", "赵薇", "被", "不是", "现在", "什么", "这", "呢", "知道", "邓"}
df = pd.read_csv(file, usecols=[0])
df_copy = df.copy()
df_copy['comment'] = df_copy['comment'].apply(lambda x: str(x).split()) # 去掉空格
df_list = df_copy.values.tolist()
comment = jieba.cut(str(df_list), cut_all=False)
words = ' '.join(comment)
if without_english:
words = re.sub('[a-zA-Z]', '', words)
img = Image.open('ciyun.png')
img_array = np.array(img)
return font, img_array, STOPWORDS, words
由于很多评论当中会存在链接信息,导致制作的词云有很多高权重的英文字符,所有这里也通过正则进行了去英文字符处理
至此,我们这个微博查询功能就完成了~
结果展示
下面我们来看看最终的效果吧

到此这篇关于基于Python实现微博抓取GUI程序的文章就介绍到这了,更多相关Python微博抓取内容请搜索我们以前的文章或继续浏览下面的相关文章希望大家以后多多支持我们!
相关推荐
-

python制作微博图片爬取工具
有小半个月没有发博客了,因为一直在研究python的GUI,买了一本书学习了一些基础,用我所学做了我的第一款GUI--微博图片爬取工具.本软件源代码已经放在了博客中,另外软件已经打包好上传到网盘中以供下载学习. 一.准备工作 本次要用到以下依赖库:re json os random tkinter threading requests PIL 其中后两个需要安装后使用 二.预览 1.启动 2.运行中 3.结果 这里只将拿一张图片作为展示. 三.设计流程 设计流程分为总体设计和详细设计,这里我会使
-
Python使用Appium在移动端抓取微博数据的实现
目录 使用Appium在移动端抓取微博数据 查找Android App的Package和入口 记录微博刷新动作 爬取微博第一条信息 使用Appium在移动端抓取微博数据 Appium是移动端的自动化测试工具,读者可以类比为PC端的selenium.通过它,我们可以驱动App完成自动化的一系列操作,同样也可以爬取需要的内容. 这里,我们需要首先在PC端安装Appium软件,安装下载的地址如下:https://github.com/appium/appium-desktop/releases 安装软
-
Python selenium抓取微博内容的示例代码
Selenium简介与安装 Selenium是什么? Selenium也是一个用于Web应用程序测试的工具.Selenium测试直接运行在浏览器中,就像真正的用户在操作一样.支持的浏览器包括IE.Mozilla Firefox.Mozilla Suite等. 安装 直接使用pip命令安装即可! pip install selenium Python抓取微博有两种方式,一是通过selenium自动登录后从页面直接爬取,二是通过api. 这里采用selenium的方式. 程序: from selen
-
python爬取微博评论的实例讲解
python爬虫是程序员们一定会掌握的知识,练习python爬虫时,很多人会选择爬取微博练手.python爬虫微博根据微博存在于不同媒介上,所爬取的难度有差异,无论是python新入手的小白,还是已经熟练掌握的程序员,可以拿来练手.本文介绍python爬取微博评论的代码实例. 一.爬虫微博 与QQ空间爬虫类似,可以爬取新浪微博用户的个人信息.微博信息.粉丝.关注和评论等. 爬虫抓取微博的速度可以达到 1300万/天 以上,具体要视网络情况. 难度程度排序:网页端>手机端>移动端.微博端就是最好
-
用Python爬取指定关键词的微博
目录 一.分析页面 二.数据采集 1.发起请求 2.提取数据 三.小结 前几天学校一个老师在做微博的舆情分析找我帮她搞一个用关键字爬取微博的爬虫,再加上最近很多读者问志斌微博爬虫的问题,今天志斌来跟大家分享一下. 一.分析页面 我们此次选择的是从移动端来对微博进行爬取.移动端的反爬就是信息校验反爬虫的cookie反爬虫,所以我们首先要登陆获取cookie. 登陆过后我们就可以获取到自己的cookie了,然后我们来观察用户是如何搜索微博内容的. 平时我们都是在这个地方输入关键字,来进行搜索微博.
-
基于Python实现微博抓取GUI程序
目录 前言 微博功能布局 创建微博 Widget 创建微博查询 词云制作 结果展示 前言 在前面的分享中,我们制作了一个天眼查 GUI 程序,今天我们在这个的基础上,继续开发新的功能,微博抓取工具,先来看下最终的效果 整体的界面还是继承自上次的天眼查界面,我们直接来看相关功能 微博功能布局 我们整体的界面布局就是左侧可以选择不同功能,然后右侧的界面会对应改变 创建微博 Widget 对于右侧界面的切换,我们可以为不同的功能创建不同的 Widget,当点击左侧不同功能按钮后,对应切换 Widget
-
基于python实现的抓取腾讯视频所有电影的爬虫
我搜集了国内10几个电影网站的数据,里面近几十W条记录,用文本没法存,mongodb学习成本非常低,安装.下载.运行起来不会花你5分钟时间. # -*- coding: utf-8 -*- # by awakenjoys. my site: www.dianying.at import re import urllib2 from bs4 import BeautifulSoup import string, time import pymongo NUM = 0 #全局变量,电影数量 m_ty
-
Python基于百度AI实现抓取表情包
本文先抓取网络上的表情图像,然后利用百度 AI 识别表情包上的说明文字,并利用表情文字重命名文件,这样当发表情包时,不需要逐个打开查找,直接根据文件名选择表情并发送. 一.百度 AI 开放平台的 Key 申请方法 本例使用了百度 AI 的 API 接口实现文字识别.因此需要先申请对应的 API 使用权限,具体步骤如下: 在网页浏览器(比如 Chrome 或者火狐) 的地址栏中输入 ai.baidu.com,进入到百度云 AI 的官网,在该页面中单击右上角的 控制台 按钮. 进入到百度云 AI 官
-
Python+Tkinter制作股票数据抓取小程序
目录 程序布局 抓取与保存功能 添加功能 个股查询按钮 批量查询开关 在前面的文章中,我们一起学习了如何通过 Python 抓取东方财富网的实时股票数据,链接如下 用 Python 爬取股票实时数据 今天我们就在这个基础上,实现一个 Tkinter GUI 程序,完成无代码股票抓取! 首先对于 Tkinter 相信大家都是比较了解的,如果有小伙伴对于 Tkinter 的相关用法不是特别熟悉的话,可以看如下文章 Tkinter 入门之旅 首先我们先看一下 GUI 程序的最终效果 该程序共分三个区域
-
python使用mitmproxy抓取浏览器请求的方法
最近要写一款基于被动式的漏洞扫描器,因为被动式是将我们在浏览器浏览的时候所发出的请求进行捕获,然后交给扫描器进行处理,本来打算自己写这个代理的,但是因为考虑到需要抓取https,所以最后找到Mitmproxy这个程序. 安装方法: pip install mitmproxy 接下来通过一个案例程序来了解它的使用,下面是目录结构 sproxy |utils |__init__.py |parser.py |sproxy.py sproxy.py代码 #coding=utf-8 from pprin
-
python+mongodb数据抓取详细介绍
分享点干货!!! Python数据抓取分析 编程模块:requests,lxml,pymongo,time,BeautifulSoup 首先获取所有产品的分类网址: def step(): try: headers = { ..... } r = requests.get(url,headers,timeout=30) html = r.content soup = BeautifulSoup(html,"lxml") url = soup.find_all(正则表达式) for i
-
Python实现多线程抓取网页功能实例详解
本文实例讲述了Python实现多线程抓取网页功能.分享给大家供大家参考,具体如下: 最近,一直在做网络爬虫相关的东西. 看了一下开源C++写的larbin爬虫,仔细阅读了里面的设计思想和一些关键技术的实现. 1.larbin的URL去重用的很高效的bloom filter算法: 2.DNS处理,使用的adns异步的开源组件: 3.对于url队列的处理,则是用部分缓存到内存,部分写入文件的策略. 4.larbin对文件的相关操作做了很多工作 5.在larbin里有连接池,通过创建套接字,向目标站点
-
Python使用爬虫抓取美女图片并保存到本地的方法【测试可用】
本文实例讲述了Python使用爬虫抓取美女图片并保存到本地的方法.分享给大家供大家参考,具体如下: 图片资源来自于www.qiubaichengren.com 代码基于Python 3.5.2 友情提醒:血气方刚的骚年.请 谨慎阅图! 谨慎阅图!! 谨慎阅图!!! code: #!/usr/bin/env python # -*- coding: utf-8 -*- import os import urllib import urllib.request import re from urll
-
用基于python的appium爬取b站直播消费记录
基于python的Appium进行b站直播消费记录爬取 之前看文章说fiddler也可以进行爬取,但尝试了一下没成功,这次选择appium进行爬取.类似的,可以运用爬取微信朋友圈和抖音等手机app相关数据 正文 #环境配置参考 前期工作准备,需要安装python.jdk.PyCharm.Appium-windows-x.x.Appium_Python_Client.Android SDK,pycharm可以用anaconda的jupyter来替代 具体可以参考这篇博客,讲的算是很清楚啦 http
-
Python爬虫实现抓取电影网站信息并入库
目录 一.环境搭建 1.下载安装包 2.修改环境变量 3.安装依赖模块 二.代码开发 三.运行测试 1.新建电影信息表 2.代码运行 四.问题排查和修复 1.空白字符报错 2.请求报错 一.环境搭建 1.下载安装包 访问 Python官网下载地址:https://www.python.org/downloads/ 下载适合自己系统的安装包: 我用的是 Windows 环境,所以直接下的 exe 包进行安装. 下载后,双击下载包,进入 Python 安装向导,安装非常简单,你只需要使用默认的设置一