利用Python的pandas数据处理包将宽表变成窄表
目录
- 前言
- 1.引入包
- 3.关键操作,将宽表转换为窄表
- 4.对空值进行处理
- 5.导出存储到Excel中
前言
工作中经常会使用到将宽表变成窄表,例如这样的形式
| 编号 | 编码 | 单位1 | 单位2 | 单位3 | 单位4 | ... | ... | ... | ... | ... | ... |
| 1 | 编码1... | 数量... | 数量... | 数量... | 数量... | ... | ... | ... | ... | ... | ... |
| 2 | 编码2... | 数量... | 数量... | 数量... | 数量... | ... | ... | ... | ... | ... | ... |
然而工作中,这样查看数据不够方便,往往需要窄表的形式,如下:
| 编码 | 单位 | 数量 |
| 编码1 | 单位1 | 数量1 |
| 编码2 | 单位2 | 数量2 |
| 编码3 | 单位3 | 数量3 |
| ...... | ...... | ...... |
尝试使用Excel中的lookup函数进行填充,较为麻烦还不能直接实现功能,刚好在自学Python,就查阅了资料,看看能不能使用Python强大的数据处理功能来实现这个需求。
pandas简介:pandas=pannel data+ data analysis;最初被作为金融数据分析工具而开发出来的,pandas为时间序列分析提供了很好的支持。同是也能够灵活处理缺失数据,为数据分析操作提供了更为便捷的手段。
话不多说,直接上jupyter代码。
1.引入包
供处理分析使用,这步so easy!
import pandas as pd import numpy as np import os
2.加载数据并显示。常规操作。
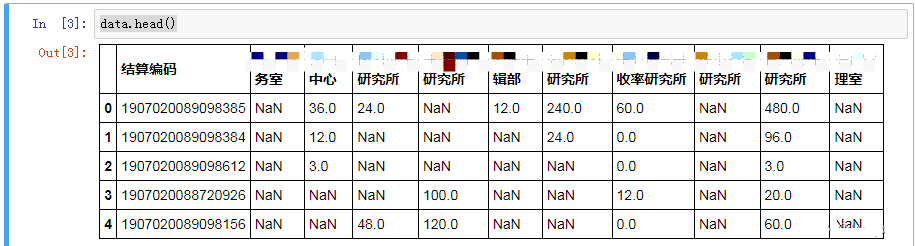
data=pd.read_excel('test.xls')
data.head()
自己的测试数据存在test.xls中,这个文件存储在路径不必考虑,直接将原始存储的文件在jupyter中点upload上传到里根目录里就可以。
显示出来的,结果如图所示:
3.关键操作,将宽表转换为窄表
pd.set_option('display.max_rows', None)
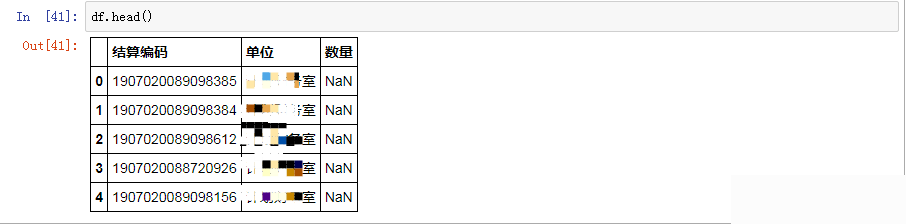
df=pd.melt(data,id_vars="结算编码",var_name="单位",value_name="数量")
df.head()
显示结果如下, 可以看到数据显示不全,还有空值,需要进一步进行处理操作。
4.对空值进行处理
pd.set_option('display.max_rows', None)
#删除所有值为空的行
df.dropna(axis=0, how='any', thresh=None, subset=None, inplace=False)
#how字段可选有any和all,any表示只要有空值出现就删除,all表示全部为空值才删除;inplace字段表示是否替换掉原本的数据
#删除所有值为空的列
df.dropna(axis="columns",how="all",inplace=False)
df.dropna()
处理后的结果可以看到,数据显示齐全,并已过滤处理掉了空值。

5.导出存储到Excel中
file_dir = 'D:/program/write/'
exists = os.path.exists(file_dir)
if not exists:
os.makedirs(file_dir)
df["结算编码"] = df["结算编码"].astype(str) #设置单元格格式
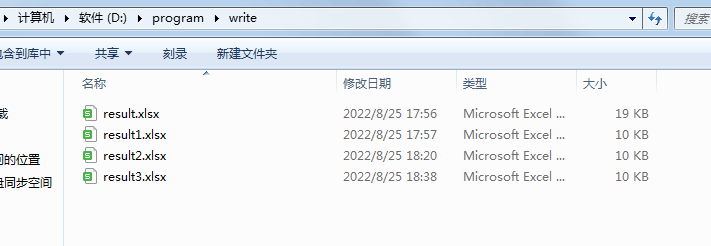
df.dropna().to_excel(os.path.join(file_dir,"result3.xlsx"), sheet_name="处理结果")
处理后的存储结果:
结论:Python对数据处理分析真的操作简单高效,后续可以多多尝试使用Python来简化办公繁杂的程序,提升工作效率。
到此这篇关于利用Python的pandas数据处理包将宽表变成窄表的文章就介绍到这了,更多相关Python的pandas数据处理内容请搜索我们以前的文章或继续浏览下面的相关文章希望大家以后多多支持我们!
相关推荐
-

Python Pandas读取Excel日期数据的异常处理方法
目录 异常描述 出现原因 解决方案:修改自定义格式 pandas直接解析Excel数值为日期 总结 异常描述 有时我们的Excel有一个调整过自定义格式的日期字段: 当我们用pandas读取时却是这样的效果: 不管如何指定参数都无效. 出现原因 没有使用系统内置的日期单元格格式,自定义格式没有对负数格式进行定义,pandas读取时无法识别出是日期格式,而是读取出单元格实际存储的数值. 解决方案:修改自定义格式 可以修改为系统内置的自定义格式: 或者在自定义格式上补充负数的定义: 增加;@即可 p
-
python优化数据预处理方法Pandas pipe详解
我们知道现实中的数据通常是杂乱无章的,需要大量的预处理才能使用.Pandas 是应用最广泛的数据分析和处理库之一,它提供了多种对原始数据进行预处理的方法. import numpy as np import pandas as pd df = pd.DataFrame({ "id": [100, 100, 101, 102, 103, 104, 105, 106], "A": [1, 2, 3, 4, 5, 2, np.nan, 5], "B":
-
Python使用Pandas对csv文件进行数据处理的方法
今天接到一个新的任务,要对一个140多M的csv文件进行数据处理,总共有170多万行,尝试了导入本地的MySQL数据库进行查询,结果用Navicat导入直接卡死....估计是XAMPP套装里面全默认配置的MySQL性能不给力,又尝试用R搞一下吧结果发现光加载csv文件就要3分钟左右的时间,相当不给力啊,翻了翻万能的知乎发现了Python下的一个神器包:Pandas(熊猫们?),加载这个140多M的csv文件两秒钟就搞定,后面的分类汇总等操作也都是秒开,太牛逼了!记录一下这次数据处理的过程: 使用
-
Python利用pandas处理Excel数据的应用详解
最近迷上了高效处理数据的pandas,其实这个是用来做数据分析的,如果你是做大数据分析和测试的,那么这个是非常的有用的!!但是其实我们平时在做自动化测试的时候,如果涉及到数据的读取和存储,那么而利用pandas就会非常高效,基本上3行代码可以搞定你20行代码的操作!该教程仅仅限于结合柠檬班的全栈自动化测试课程来讲解下pandas在项目中的应用,这仅仅只是冰山一角,希望大家可以踊跃的去尝试和探索! 一.安装环境: 1:pandas依赖处理Excel的xlrd模块,所以我们需要提前安装这个,安装命令
-
python数据处理67个pandas函数总结看完就用
目录 导⼊数据 导出数据 查看数据 数据选取 数据处理 数据分组.排序.透视 数据合并 不管是业务数据分析 ,还是数据建模.数据处理都是及其重要的一个步骤,它对于最终的结果来说,至关重要. 今天,就为大家总结一下 "Pandas数据处理" 几个方面重要的知识,拿来即用,随查随查. 导⼊数据 导出数据 查看数据 数据选取 数据处理 数据分组和排序 数据合并 # 在使用之前,需要导入pandas库 import pandas as pd 导⼊数据 这里我为大家总结7个常见用法. pd.Da
-
python数据处理之Pandas类型转换的实现
目录 转换为字符串类型 转换为数值类型 转为数值类型还可以使用to_numeric()函数 分类数据(Category) 数据类型小结 转换为字符串类型 tips['sex_str'] = tips['sex'].astype(str) 转换为数值类型 转为数值类型还可以使用to_numeric()函数 DataFrame每一列的数据类型必须相同,当有些数据中有缺失,但不是NaN时(如missing,null等),会使整列数据变成字符串类型而不是数值型,这个时候可以使用to_numeric处理
-
python pandas处理excel表格数据的常用方法总结
目录 前言 1.读取xlsx表格:pd.read_excel() 2.获取表格的数据大小:shape 3.索引数据的方法:[ ] / loc[] / iloc[] 4.判断数据为空:np.isnan() / pd.isnull() 5.查找符合条件的数据 6.修改元素值:replace() 7.增加数据:[ ] 8.删除数据:del() / drop() 9.保存到excel文件:to_excel() 总结 前言 最近助教改作业导出的成绩表格跟老师给的名单顺序不一致,脑壳一亮就用pandas写了
-
Python数据处理的26个Pandas实用技巧总结
目录 从剪贴板中创建DataFram 将DataFrame划分为两个随机的子集 多种类型过滤DataFrame DataFrame筛选数量最多类别 处理缺失值 一个字符串划分成多列 Series扩展成DataFrame 对多个函数进行聚合 聚合结果与DataFrame组合 选取行和列的切片 MultiIndexedSeries重塑 创建数据透视表 连续数据转类别数据 StyleaDataFrame 额外技巧 ProfileaDataFrame 大家好,今天给大家分享一篇 pandas 实用技巧,
-
python pandas数据处理教程之合并与拼接
目录 前言 一.join 1.leftjoin 2.rightjoin 3.innerjoin 4.outjoin 二.merge 三.concat 1.纵向合并 2.横向合并 四.append 1.同结构数据追加 2.不同结构数据追加 3.追加合并多个数据集 五.combine_first 六.update 总结 前言 在许多应用中,数据可能来自不同的渠道,在数据处理的过程中常常需要将这些数据集进行组合合并拼接,形成更加丰富的数据集.pandas提供了多种方法完全可以满足数据处理的常用需求.具
-
VBA处理数据与Python Pandas处理数据案例比较分析
需求: 现有一个 csv文件,包含'CNUM'和'COMPANY'两列,数据里包含空行,且有内容重复的行数据. 要求: 1)去掉空行: 2)重复行数据只保留一行有效数据: 3)修改'COMPANY'列的名称为'Company_New': 4)并在其后增加六列,分别为'C_col','D_col','E_col','F_col','G_col','H_col'. 一,使用 Python Pandas来处理: import pandas as pd import numpy as np from p