ChatGPT 帮我自动编写 Python 爬虫脚本的详细过程
目录
- 1、爬取知乎上的专栏文章
- 2. 爬取京东某商品的评论
- 3.继续更多的测试
都知道最近ChatGPT聊天机器人爆火,我也想方设法注册了账号,据说后面要收费了。
ChatGPT是一种基于大语言模型的生成式AI,换句话说它可以自动生成类似人类语言的文本,把梳理好的有逻辑的答案呈现在你面前,这完全不同于传统搜索工具。
ChatGPT不光可以回答人文、科学、情感等传统问题,还可以写代码、改bug,程序员可就急了,简直是在抢饭碗,所以网上出现各种ChatGPT让你失业的焦虑言论。
俗话说“百闻不如一见”,我试着让ChatGPT用Python去写爬虫脚本,看它到底行不行?
1、爬取知乎上的专栏文章
提问:
帮我用python写代码爬取网站
ChatGPT:

把给到的代码放进PyCharm中跑一遍,发现没有报错,且打印出了内容。
import requests
from bs4 import BeautifulSoup
url = "https://zhuanlan.zhihu.com/p/595050104"
response = requests.get(url)
soup = BeautifulSoup(response.text, "html.parser")
title = soup.find("h1", class_="Post-Title").text.strip()
body = soup.find("div", class_="Post-RichText").text.strip()
print("Title:", title)
print("Body:", body)
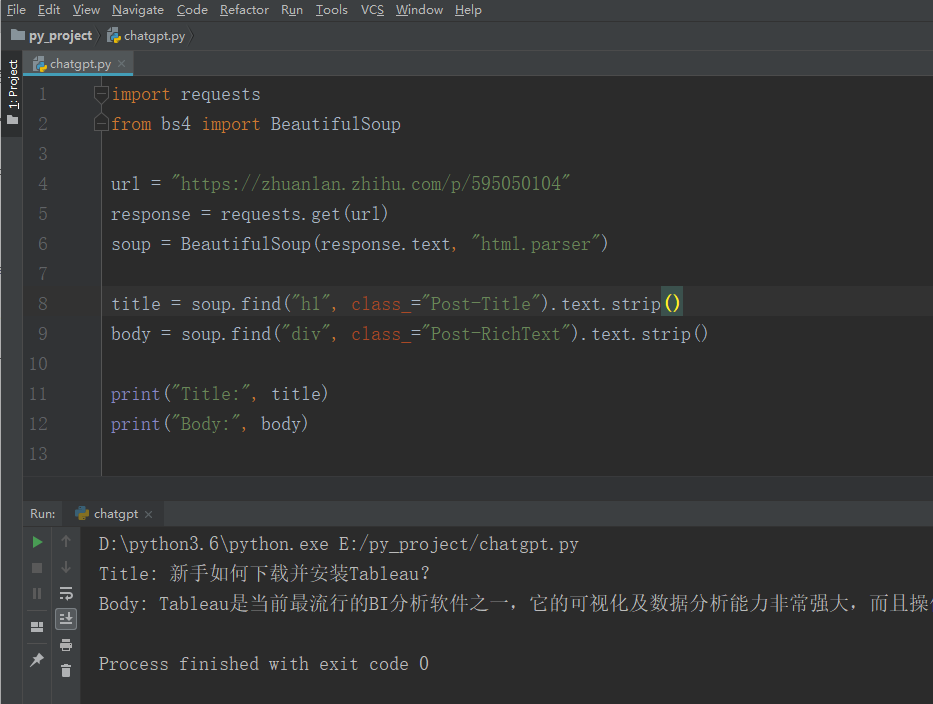
虽然说ChatGPT给出的代码可以执行,但它也提到由于爬取的网站会随时变更,也就是HTML会变动,所以代码可能需要调整才能正常工作。
凡是写过爬虫的同学应该都能理解,人工写的爬虫代码也没法一劳永逸,需要随时改。
这一点ChatGPT提示的很有道理。
后来我测试了medium、百家号上的文章,ChatGPT提供的代码形式几乎和上面一致,没法直接执行获取结果,需要微调后才能跑。
2. 爬取京东某商品的评论
为了给ChatGPT增加难度,我试着让它去爬取某电商网站的用户评论
提问:
请用python写代码爬取这个京东商品的所有用户评论 https://item.jd.com/13652780.html
ChatGPT:

可能这个网页是动态页面,ChatGPT提供的方法并不能爬取评论。
我接着问:
爬取的结果是空值怎么办?
ChatGPT:
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-nnDP8sph-1676473447460)(null)]
ChatGPT提供了3种可能存在的原因,但并没有帮我修改代码。
于是我又问:
还是空值 请帮我重新写代码爬取
ChatGPT:

这次就牛掰了,它重新用Selenium写了爬虫代码,并告诉我爬取动态网页需要模拟浏览器行为,因此得用selenium技术。
我没有运行去测试代码正确与否,但ChatGPT确实惊艳到我了,能够前后关联对话内容,并给出正确的解决方法。
3.继续更多的测试
上面只是蜻蜓点水的玩玩,ChatGPT就已经吸引到我,
我准备多花时间去测试ChatGPT应对各种爬虫的解决方案,以及它对bug的修复能力。
仅仅从写代码层面看,ChatGPT已经可以媲美中高级程序员的水平了,而且它的知识范畴远超人类最厉害的程序员
ChatGPT能够根据对话生成人想要的内容,这是AI巨大的突破,未来它的应用之广难以想象。
到此这篇关于ChatGPT 帮我自动编写 Python 爬虫脚本的文章就介绍到这了,更多相关ChatGPT自动编写 Python 爬虫脚本内容请搜索我们以前的文章或继续浏览下面的相关文章希望大家以后多多支持我们!
相关推荐
-
Python+ChatGPT实现5分钟快速上手编程
目录 1.chatGPT是个啥 2.chatGPT怎么注册 3.chatGPT怎么用 4.小结 最近一段时间chatGPT火爆出圈!无论是在互联网行业,还是其他各行业都赚足了话题. 俗话说:“外行看笑话,内行看门道”,今天从chatGPT个人体验感受以及如何用的角度来分享一下. 1.chatGPT是个啥 chatGPT是最近新出来的玩意?并不是!在国内,chatGPT最早是在2022年11月就由OpenAI于推出的.只是去年底火了一把,后力不足又遇春节,热度草草就结束了. 先讲一下,OpenAI
-
使用ChatGPT来自动化Python任务
目录 1.概述 2.内容 2.1 使用ChatGPT来绘制线性回归 2.2 使用Python给微信发信息 2.3 使用Python发送电子邮件 2.4 使用Python开发一个爬虫程序 3.总结 1.概述 最近,比较火热的ChatGPT很受欢迎.今天,笔者为大家来介绍一下ChatGPT能做哪些事情. 2.内容 ChatGPT是一款由OpenAI开发的专门从事对话的AI聊天机器人.它的目标是让AI系统更加自然的与之交互,但它也可以在我们编写代码的时候提供一些帮助. 2.1 使用ChatGPT来绘制
-
详解如何在ChatGPT内构建一个Python解释器
目录 下面是初始化ChatGPT的命令: 总结 引用:Art Kulakov <How to Build a Python Interpreter Inside ChatGPT> 这个灵感来自于一个类似的故事,在ChatGPT里面建立一个虚拟机(Building A Virtual Machine inside ChatGPT).给我留下了深刻的印象,并决定尝试类似的东西,但这次不是用Linux命令行工具,而是让ChatGPT成为我们的Python解释器. 下面是初始化ChatGPT的命令:
-
如何在Python里使用ChatGPT及ChatGPT是什么?注册方式?
目录 问: 如何在python中使用chatGPT? ChatGPT是什么?怎么注册? 废话不多说,直接开干!需要库 pip install openai import openai # Set your API key openai.api_key = "你的chatgpt的密钥key" # Use the GPT-3 model completion = openai.Completion.create(engine="text-davinci-002",pro
-
手把手教你在Python里使用ChatGPT
目录 前言 知识点 实现 代码 后话 前言 近来chatGPT挺火的,也试玩了一下,确实挺有意思.这里记录一下在Python中如何去使用chatGPT. 本篇文章的实现100%基于 chatGPT,我是搬运工无疑了!!! 本片文章比较简单. 知识点 pip install openai 看看 chatGPT的表现: 使用python编写一段发送网络请求的代码 python如何md5 也有抽风的表现: 小明妈妈大小明20岁,20年后小明妈妈大小明多少岁? 一个蛋糕切成8块我吃不完,切成4块刚刚好?
-
ChatGPT 帮我自动编写 Python 爬虫脚本的详细过程
目录 1.爬取知乎上的专栏文章 2. 爬取京东某商品的评论 3.继续更多的测试 都知道最近ChatGPT聊天机器人爆火,我也想方设法注册了账号,据说后面要收费了. ChatGPT是一种基于大语言模型的生成式AI,换句话说它可以自动生成类似人类语言的文本,把梳理好的有逻辑的答案呈现在你面前,这完全不同于传统搜索工具. ChatGPT不光可以回答人文.科学.情感等传统问题,还可以写代码.改bug,程序员可就急了,简直是在抢饭碗,所以网上出现各种ChatGPT让你失业的焦虑言论. 俗话说“百闻不如一见
-
Linux部署python爬虫脚本,并设置定时任务的方法
去年因项目需要,用python写了个爬虫.因爬到的数据需要存到生产环境的PG数据库.所以需要将脚本部署到CentOS服务器,并设置定时任务,自动启动脚本. 实施步骤如下: 1.安装pip(操作系统自带了python2.6可以直接用,但是没有pip) # 下载pip安装包 wget "https://pypi.python.org/packages/source/p/pip/pip-1.5.4.tar.gz#md5=834b2904f92d46aaa333267fb1c922bb" --
-

使用Gitee自动化部署python脚本的详细过程
一.前期准备 1.1 安装环境 1.安装python3 2.打开命令行安装selenium pip install selenium 二.python代码 2.1 源码 #!/usr/bin/python # -*- coding: utf-8 -*- import time from selenium import webdriver from selenium.webdriver.common.alert import Alert # 模拟浏览器打开到gitee登录界面 driver = w
-
Python爬虫必备技巧详细总结
自定义函数 import requests from bs4 import BeautifulSoup headers={'User-Agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64; rv:93.0) Gecko/20100101 Firefox/93.0'} def baidu(company): url = 'https://www.baidu.com/s?rtt=4&tn=news&word=' + company print(url
-
python编写网页爬虫脚本并实现APScheduler调度
前段时间自学了python,作为新手就想着自己写个东西能练习一下,了解到python编写爬虫脚本非常方便,且最近又学习了MongoDB相关的知识,万事具备只欠东风. 程序的需求是这样的,爬虫爬的页面是京东的电子书网站页面,每天会更新一些免费的电子书,爬虫会把每天更新的免费的书名以第一时间通过邮件发给我,通知我去下载. 一.编写思路: 1.爬虫脚本获取当日免费书籍信息 2.把获取到的书籍信息与数据库中的已有信息作比较,如果书籍存在不做任何操作,书籍不存在,执行插入数据库的操作,把数据的信息存入Mo
-
编写Python CGI脚本的教程
你是否想使用Python语言创建一个网页,或者处理用户从web表单输入的数据?这些任务可以通过Python CGI(公用网关接口)脚本以及一个Apache web服务器实现.当用户请求一个指定URL或者和网页交互(比如点击""提交"按钮)的时候,CGI脚本就会被web服务器启用.CGI脚本调用执行完毕后,它的输出结果就会被web服务器用来创建显示给用户的网页. 配置Apache web服务器,让其能运行CGI脚本 在这个教程里,我们假设Apache web服务器已经安装好,并
-
Python中创建表格详细过程
目录 1. 引言 2. 准备工作 3. 举个栗子 3.1 使用list生成表格 3.2 使用dict生成表格 3.3 增加索引列 3.4 缺失值处理 1. 引言 如果能够将我们的无序数据快速组织成更易读的格式,对于数据分析非常有帮助. Python 提供了将某些表格数据类型轻松转换为格式良好的纯文本表格的能力,这就是 tabulate 库. 2. 准备工作 安装tabulate库: 安装tabulate库非常容易,使用pip即可安装,代码如下: pip install tabulate 导入ta
-
编写Python爬虫抓取暴走漫画上gif图片的实例分享
本文要介绍的爬虫是抓取暴走漫画上的GIF趣图,方便离线观看.爬虫用的是python3.3开发的,主要用到了urllib.request和BeautifulSoup模块. urllib模块提供了从万维网中获取数据的高层接口,当我们用urlopen()打开一个URL时,就相当于我们用Python内建的open()打开一个文件.但不同的是,前者接收一个URL作为参数,并且没有办法对打开的文件流进行seek操作(从底层的角度看,因为实际上操作的是socket,所以理所当然地没办法进行seek操作),而后
-
编写Python爬虫抓取豆瓣电影TOP100及用户头像的方法
抓取豆瓣电影TOP100 一.分析豆瓣top页面,构建程序结构 1.首先打开网页http://movie.douban.com/top250?start,也就是top页面 然后试着点击到top100的页面,注意带top100的链接依次为 http://movie.douban.com/top250?start=0 http://movie.douban.com/top250?start=25 http://movie.douban.com/top250?start=50 http://movie
-
Python爬虫设置ip代理过程解析
1.get方式:如何为爬虫添加ip代理,设置Request header(请求头) import urllib import urllib.request import urllib.parse import random import time from fake_useragent import UserAgent ua = UserAgent() url = "http://www.baidu.com" ######################################