Python使用pandas将表格数据进行处理
目录
- 前言
- 一、构建es库中的数据
- 1.1 创建索引
- 1.2 插入数据
- 1.3 查询数据
- 二、对excel表格中的数据处理操作
- 2.1 导出es查询的数据
前言
任务描述:
当前有一份excel表格数据,里面存在缺失值,需要对缺失的数据到es数据库中进行查找并对其进行把缺失的数据进行补全。
excel表格数据如下所示:

一、构建es库中的数据
1.1 创建索引
# 创建physical_examination索引
PUT /physical_examination
{
"settings": {
"index": {
"number_of_shards": "1",
"number_of_replicas": "1"
}
},
"mappings": {
"properties": {
"nums": {
"type": "integer"
},
"name": {
"type": "text"
},
"sex": {
"type": "text"
},
"phone": {
"type": "integer"
},
"result": {
"type": "text"
}
}
}
}

1.2 插入数据
【注意:json数据不能格式化换行,否则报错】
# 向physical_examination索引中添加数据
POST physical_examination/_bulk
{"index":{"_id":"1"}}
{"nums":1,"name":"刘一","sex":"男","phone":1234567891,"result":"优秀"}
{"index":{"_id":"2"}}
{"nums":2,"name":"陈二","sex":"男","phone":1234567892,"result":"优秀"}
{"index":{"_id":"3"}}
{"nums":3,"name":"张三","sex":"男","phone":1234567893,"result":"优秀"}
{"index":{"_id":"4"}}
{"nums":4,"name":"李四","sex":"男","phone":1234567894,"result":"优秀"}
{"index":{"_id":"5"}}
{"nums":5,"name":"王五","sex":"男","phone":1234567895,"result":"优秀"}

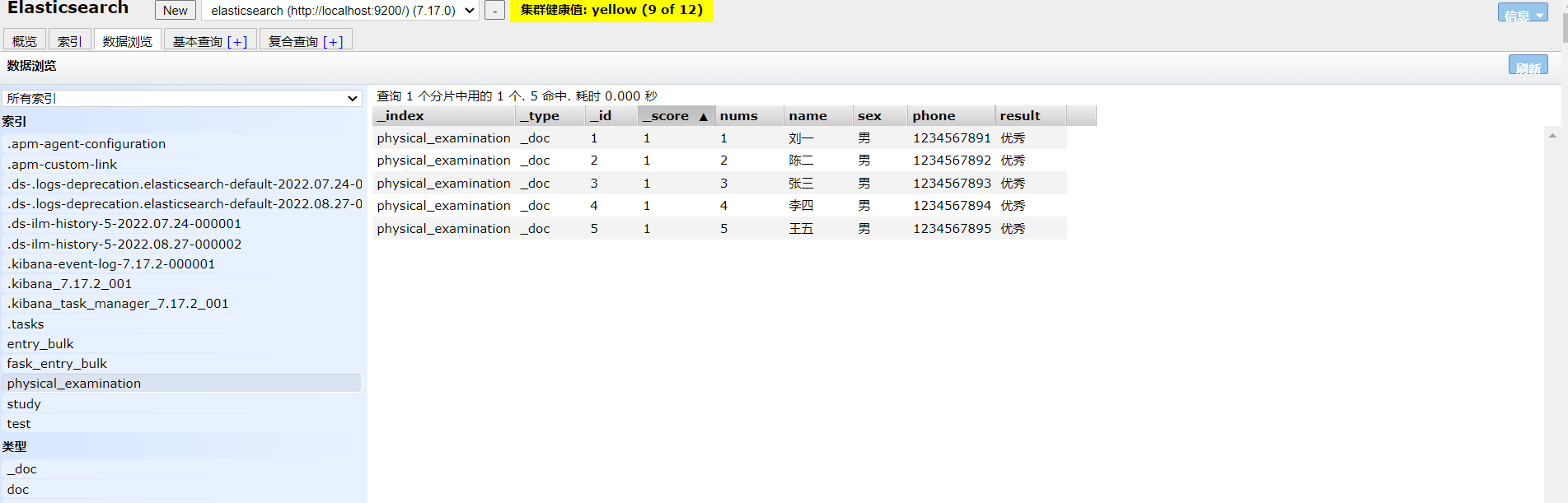

1.3 查询数据
【注意:默认查询索引下的所有数据】
# 查询索引中的所有数据
GET physical_examination/_search
{
"query": {
"match_all": {}
}
}


二、对excel表格中的数据处理操作
2.1 导出es查询的数据
- 方法一:直接在kibana或postman查询的结果中进行复制粘贴到一个文档。
- 方法二:使用kibana导出数据。
- 方法三:使用postman导出数据保存到本地。

使用python处理数据,获取需要的数据。
示例代码:
# 读取json中体检信息
with open('./data/physical_examination.json', 'r', encoding='utf-8') as f:
data_json = f.read()
print(data_json)
# 处理json数据中的异常数据
if 'false' in data_json:
data_json = data_json.replace('false', "False")
data_json = eval(data_json)
print(data_json)
print(data_json['hits']['hits'])
print('*' * 100)
valid_data = data_json['hits']['hits']
need_data = []
for data in valid_data:
print(data['_source'])
need_data.append(data['_source'])
print(need_data)
读取缺失数据的excel表格,把缺失的数据填补进去。
# 读取需要填补数据的表格
data_xlsx = pd.read_excel('./data/体检表.xlsx', sheet_name='Sheet1')
# print(data_xlsx)
# 获取excel表格的行列
row, col = data_xlsx.shape
print(row, col)
# 修改表格中的数据
for i in range(row):
bb = data_xlsx.iloc[i]
print(bb['姓名'], bb['手机号'])
if pd.isnull(bb['手机号']):
bb['手机号'] = '666'
for cc in need_data:
if cc['name'] == bb['姓名']:
bb['手机号'] = cc['phone']
data_xlsx.iloc[i, 3] = bb['手机号']
print(bb['姓名'], bb['手机号'])
print("-" * 100)
print(data_xlsx)
将最终处理好的数据保存在新建的文件中。
# 保存数据到新文件中
data_xlsx.to_excel('./data/new_data.xlsx', sheet_name='Sheet1', index=False, header=True)
完整代码如下:
import pandas as pd
# 读取json中体检信息
with open('./data/physical_examination.json', 'r', encoding='utf-8') as f:
data_json = f.read()
print(data_json)
# 处理json数据中的异常数据
if 'false' in data_json:
data_json = data_json.replace('false', "False")
data_json = eval(data_json)
print(data_json)
print(data_json['hits']['hits'])
print('*' * 100)
valid_data = data_json['hits']['hits']
need_data = []
for data in valid_data:
print(data['_source'])
need_data.append(data['_source'])
print(need_data)
# 读取需要填补数据的表格
data_xlsx = pd.read_excel('./data/体检表.xlsx', sheet_name='Sheet1')
# print(data_xlsx)
# 获取excel表格的行列
row, col = data_xlsx.shape
print(row, col)
# 修改表格中的数据
for i in range(row):
bb = data_xlsx.iloc[i]
print(bb['姓名'], bb['手机号'])
if pd.isnull(bb['手机号']):
bb['手机号'] = '666'
for cc in need_data:
if cc['name'] == bb['姓名']:
bb['手机号'] = cc['phone']
data_xlsx.iloc[i, 3] = bb['手机号']
print(bb['姓名'], bb['手机号'])
print("-" * 100)
print(data_xlsx)
# 保存数据到新文件中
data_xlsx.to_excel('./data/new_data.xlsx', sheet_name='Sheet1', index=False, header=True)
运行效果,最终处理好的数据如下所示:
到此这篇关于Python使用pandas将表格数据进行处理的文章就介绍到这了,更多相关pandas表格数据处理内容请搜索我们以前的文章或继续浏览下面的相关文章希望大家以后多多支持我们!
相关推荐
-
python Pandas 读取txt表格的实例
运行环境 Python 2.7 操作实例 1.原始文本格式:空格分隔的txt,例如 2016-03-22 00:06:24.4463094 中文测试字符 2016-03-22 00:06:32.4565680 需要编辑encoding 2016-03-22 00:06:32.6835965 abc 2016-03-22 00:06:32.8041945 egb 2.pandas 读取数据 import pandas as pd data = pd.read_table('Z:/test.txt'
-

Python Pandas两个表格内容模糊匹配的实现
目录 一.方法2 1. 导入库 2. 构建关键词 3. 构建句子 4. 建立统一索引 5. 表连接 6. 关键词匹配 二.方法2 1. 构建字典 2. 关键词匹配 3. 结果展示 4. 匹配结果展开 总结 一.方法2 此方法是两个表构建某一相同字段,然后全连接,在做匹配结果筛选,此方法针对数据量不大的时候,逻辑比较简单,但是内存消耗较大 1. 导入库 import pandas as pd import numpy as np import re 2. 构建关键词 #关键词数据 df_keywo
-
Python基于pandas爬取网页表格数据
以网页表格为例:https://www.kuaidaili.com/free/ 该网站数据存在table标签,直接用requests,需要结合bs4解析正则/xpath/lxml等,没有几行代码是搞不定的. 今天介绍的黑科技是pandas自带爬虫功能,pd.read_html(),只需传人url,一行代码搞定. 原网页结构如下: python代码如下: import pandas as pd url='http://www.kuaidaili.com/free/' df=pd.read_html
-
python中pandas输出完整、对齐的表格的方法
今天使用python计算数据相关性,但是发现计算出的表格中间好多省略号,而且也不对齐. 这也太难看了. 于是在程序里加了三行: pd.set_option('display.max_columns', 1000) pd.set_option('display.width', 1000) pd.set_option('display.max_colwidth', 1000) 输出结果如下,输出结果已经全部显示了: 但是依然不对齐. 于是又加了两行: pd.set_option('display.u
-
解决python pandas读取excel中多个不同sheet表格存在的问题
摘要:不同方法读取excel中的多个不同sheet表格性能比较 # 方法1 def read_excel(path): df=pd.read_excel(path,None) print(df.keys()) # for k,v in df.items(): # print(k) # print(v) # print(type(v)) return df # 方法2 def read_excel1(path): data_xls = pd.ExcelFile(path) print(data_x
-
python pandas处理excel表格数据的常用方法总结
目录 前言 1.读取xlsx表格:pd.read_excel() 2.获取表格的数据大小:shape 3.索引数据的方法:[ ] / loc[] / iloc[] 4.判断数据为空:np.isnan() / pd.isnull() 5.查找符合条件的数据 6.修改元素值:replace() 7.增加数据:[ ] 8.删除数据:del() / drop() 9.保存到excel文件:to_excel() 总结 前言 最近助教改作业导出的成绩表格跟老师给的名单顺序不一致,脑壳一亮就用pandas写了
-
python使用pandas按照行数分割表格
目录 问题 思路 代码实现 测试效果 问题 一张excel表格,大概1万行,需要录入系统 系统每次最多只能录入500行表格数据,一旦超过500行,就会录入失败 需要把1万行的数据按照500行分割,形成20个表格,这样才能录入系统 思路 使用pandas得到总行数,比如10002行,分割表格的时候,要保留一行表头 第一张表,是1-500行,第二张表是 501-1000,以此类推 最后一张表应该是1000-10002行,生成的表格数量是10000/500+1,21张 生成的表格按照顺序保存到一个目录
-
Python使用pandas将表格数据进行处理
目录 前言 一.构建es库中的数据 1.1 创建索引 1.2 插入数据 1.3 查询数据 二.对excel表格中的数据处理操作 2.1 导出es查询的数据 前言 任务描述: 当前有一份excel表格数据,里面存在缺失值,需要对缺失的数据到es数据库中进行查找并对其进行把缺失的数据进行补全. excel表格数据如下所示: 一.构建es库中的数据 1.1 创建索引 # 创建physical_examination索引 PUT /physical_examination { "settings&quo
-
使用pandas读取表格数据并进行单行数据拼接的详细教程
业务需求 一个几十万条数据的Excel表格,现在需要拼接其中某一列的全部数据为一个字符串,例如下面简短的几行表格数据: id code price num 11 22 33 44 22 33 44 55 33 44 55 66 44 55 66 77 55 66 77 88 66 77 88 99 现在需要将code的这一列用逗号,拼接为字符串,并且每个单元格数据都用单引号包含,需要拼接成字符串'22','33','44','55','66','77',这样的情况,我们需要怎么处理呢?当然方式有
-
python使用pandas处理大数据节省内存技巧(推荐)
一般来说,用pandas处理小于100兆的数据,性能不是问题.当用pandas来处理100兆至几个G的数据时,将会比较耗时,同时会导致程序因内存不足而运行失败. 当然,像Spark这类的工具能够胜任处理100G至几个T的大数据集,但要想充分发挥这些工具的优势,通常需要比较贵的硬件设备.而且,这些工具不像pandas那样具有丰富的进行高质量数据清洗.探索和分析的特性.对于中等规模的数据,我们的愿望是尽量让pandas继续发挥其优势,而不是换用其他工具. 本文我们讨论pandas的内存使用,展示怎样
-
python使用pandas抽样训练数据中某个类别实例
废话真的一句也不想多说,直接看代码吧! # -*- coding: utf-8 -*- import numpy from sklearn import metrics from sklearn.svm import LinearSVC from sklearn.naive_bayes import MultinomialNB from sklearn import linear_model from sklearn.datasets import load_iris from sklearn.
-
基于Python快速处理PDF表格数据
我们有下面一张PDF格式存储的表格,现在需要使用Python将它提取出来. 使用Python提取表格数据需要使用pdfplumber模块,打开CMD,安装代码如下: pip install pdfplumber 安装完之后,将需要使用的模块导入 import pdfplumberimport pandas as pd 然后打开PDF文件 # 使用with语句打开pdf文件 with pdfplumber.open("D:\\python\\cai\\yq.pdf") as pdf: #
-
Python利用pandas处理Excel数据的应用详解
最近迷上了高效处理数据的pandas,其实这个是用来做数据分析的,如果你是做大数据分析和测试的,那么这个是非常的有用的!!但是其实我们平时在做自动化测试的时候,如果涉及到数据的读取和存储,那么而利用pandas就会非常高效,基本上3行代码可以搞定你20行代码的操作!该教程仅仅限于结合柠檬班的全栈自动化测试课程来讲解下pandas在项目中的应用,这仅仅只是冰山一角,希望大家可以踊跃的去尝试和探索! 一.安装环境: 1:pandas依赖处理Excel的xlrd模块,所以我们需要提前安装这个,安装命令
-
python爬虫爬取网页表格数据
用python爬取网页表格数据,供大家参考,具体内容如下 from bs4 import BeautifulSoup import requests import csv import bs4 #检查url地址 def check_link(url): try: r = requests.get(url) r.raise_for_status() r.encoding = r.apparent_encoding return r.text except: print('无法链接服务器!!!')
-
python教程网络爬虫及数据可视化原理解析
目录 1 项目背景 1.1Python的优势 1.2网络爬虫 1.3数据可视化 1.4Python环境介绍 1.4.1简介 1.4.2特点 1.5扩展库介绍 1.5.1安装模块 1.5.2主要模块介绍 2需求分析 2.1 网络爬虫需求 2.2 数据可视化需求 3总体设计 3.1 网页分析 3.2 数据可视化设计 4方案实施 4.1网络爬虫代码 4.2 数据可视化代码 5 效果展示 5.1 网络爬虫 5.1.1 爬取近五年主要城市数据 5.1.2 爬取2019年各省GDP 5.1.3 爬取豆瓣电影
-
用Python的pandas框架操作Excel文件中的数据教程
引言 本文的目的,是向您展示如何使用pandas来执行一些常见的Excel任务.有些例子比较琐碎,但我觉得展示这些简单的东西与那些你可以在其他地方找到的复杂功能同等重要.作为额外的福利,我将会进行一些模糊字符串匹配,以此来展示一些小花样,以及展示pandas是如何利用完整的Python模块系统去做一些在Python中是简单,但在Excel中却很复杂的事情的. 有道理吧?让我们开始吧. 为某行添加求和项 我要介绍的第一项任务是把某几列相加然后添加一个总和栏. 首先我们将excel 数据 导入到pa