Python中寻找数据异常值的3种方法
目录
- 1. 引言
- 2. 举个栗子
- 3. 孤立森林
- 4. 椭圆模型拟合
- 5. 局部异常因子算法
- 6. 挑选异常值检测方法
- 7. 异常值消除
- 8. 总结
1. 引言
在数据处理、机器学习等领域,我们经常需要对各式各样的数据进行处理,本文重点介绍三种非常简单的方法来检测数据集中的异常值。
2. 举个栗子
为了方便介绍,这里给出我们的测试数据集,如下:
data = pd.DataFrame([ [87, 82, 85], [81, 89, 75], [86, 87, 69], [91, 79, 86], [88, 89, 82], [0, 0, 0], # this guy missed the exam [100, 100, 100], ], columns=["math", "science", "english"])
图示如下:
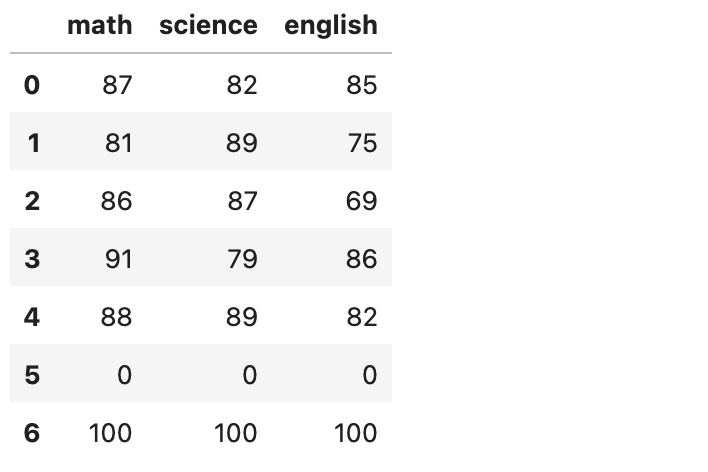
假设这里我们有一堆学生的三门科目的考试成绩——英语、数学和科学。这些学生通常表现很好,但其中一人错过了所有考试,三门科目都得了0分。在我们的分析中包括这个家伙可能会把事情搞砸,所以我们需要将他视为异常。
3. 孤立森林
使用孤立森林算法来求解上述异常值分析非常简单,代码如下:
from sklearn.ensemble import IsolationForest predictions = IsolationForest().fit(data).predict(data) # predictions = array([ 1, 1, 1, 1, 1, -1, -1])
这里预测值针对每一行进行预测,预测结果为1或者-1;其中1表示该行不是异常值,而-1表示该行是异常值。在上述例子中,我们的孤立森林算法将数据中的最后2行都预测为异常值。
4. 椭圆模型拟合
使用孤椭圆模型拟合算法来求解上述异常值同样非常方便,代码如下:
from sklearn.covariance import EllipticEnvelope predictions = EllipticEnvelope().fit(data).predict(data) # predictions = array([ 1, 1, 1, 1, 1, -1, 1])
在上述代码中,我们使用了另外一种异常值检测算法来代替孤立森林算法,但是代码保持不变。相似地,在预测值中,1表示非异常值,-1表示异常值。在上述情况下,我们的椭圆模型拟合算法只将倒数第二个学生作为异常值,即所有成绩都为零的考生。
5. 局部异常因子算法
类似地,我们可以非常方便地使用局部异常因子算法来对上述数据进行分析,样例代码如下:
from sklearn.neighbors import LocalOutlierFactor predictions = LocalOutlierFactor(n_neighbors=5, novelty=True).fit(data).predict(data) # array([ 1, 1, 1, 1, 1, -1, 1])
局部异常因子算法是sklearn上可用的另一种异常检测算法,我们可以简单地在这里随插随用。同样地,这里该算法仅将最后第二个数据行预测为异常值。
6. 挑选异常值检测方法
那么,我们如何决定哪种异常检测算法更好呢? 简而言之,没有“最佳”的异常值检测算法——我们可以将它们视为做相同事情的不同方式(并获得略有不同的结果)
7. 异常值消除
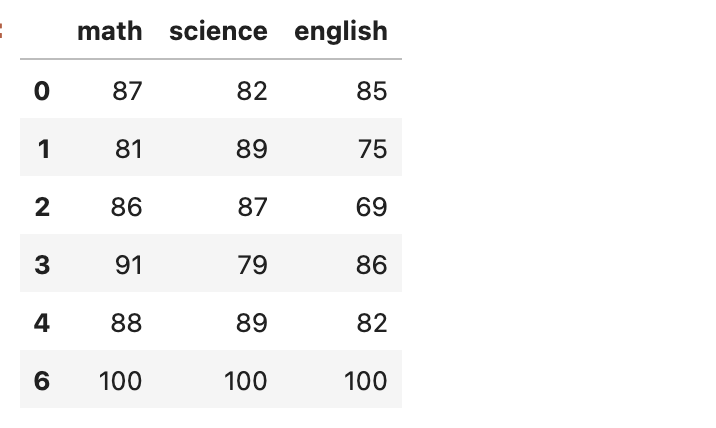
在我们从上述三种异常检测算法中的任何一种获得异常预测后,我们现在可以执行异常值的删除。 这里我们只需保留异常预测为1的所有数据行,
代码如下:
# predictions = array([ 1, 1, 1, 1, 1, -1, 1]) data2 = data[predictions==1]
结果如下:
8. 总结
本文重点介绍了在Python中使用sklearn机器学习库来进行异常值检测的三种方法,并给出了相应的代码示例。
到此这篇关于Python中寻找数据异常值的3种方法的文章就介绍到这了,更多相关Python寻找数据异常值内容请搜索我们以前的文章或继续浏览下面的相关文章希望大家以后多多支持我们!
相关推荐
-
python实现数据清洗(缺失值与异常值处理)
1. 将本地sql文件写入mysql数据库 本文写入的是python数据库的taob表 source [本地文件] 其中总数据为9616行,列分别为title,link,price,comment 2.使用python链接并读取数据 查看数据概括 #-*- coding:utf-8 -*- #author:M10 import numpy as np import pandas as pd import matplotlib.pylab as plt import mysql.connector
-

python数据分析实战指南之异常值处理
目录 异常值 1.异常值定义 2.异常值处理方式 2.1 均方差 2.2 箱形图 3.实战 3.1 加载数据 3.2 检测异常值数据 3.3 显示异常值的索引位置 总结 异常值 异常值是指样本中的个别值,其数值明显偏离其余的观测值.异常值也称离群点,异常值的分析也称为离群点的分析. 常用的异常值分析方法为3σ原则.箱型图分析.机器学习算法检测,一般情况下对异常值的处理都是删除和修正填补,即默认为异常值对整个项目的作用不大,只有当我们的目的是要求准确找出离群点,并对离群点进行分析时有必要用到机器学
-
Python数据分析基础之异常值检测和处理方式
目录 1 什么是异常值? 2 异常值的检测方法 1. 简单统计 2. 3∂原则 3. 箱型图 4. 基于模型检测 5. 基于近邻度的离群点检测 6. 基于聚类的方法来做异常点检测 7. 专门的离群点检测 3 异常值的处理方法 4 异常值总结 1 什么是异常值? 在机器学习中,异常检测和处理是一个比较小的分支,或者说,是机器学习的一个副产物,因为在一般的预测问题中,模型通常是对整体样本数据结构的一种表达方式,这种表达方式通常抓住的是整体样本一般性的性质,而那些在这些性质上表现完全与整体样本不一致的
-
Python基于matplotlib画箱体图检验异常值操作示例【附xls数据文件下载】
本文实例讲述了Python基于matplotlib画箱体图检验异常值操作.分享给大家供大家参考,具体如下: # -*- coding:utf-8 -*- #! python3 import pandas as pd import os import matplotlib.pyplot as plt data=pd.read_excel('catering_sale.xls',index_col='日期') plt.rcParams['font.sans-serif']=['SimHei']#正常
-
Python中寻找数据异常值的3种方法
目录 1. 引言 2. 举个栗子 3. 孤立森林 4. 椭圆模型拟合 5. 局部异常因子算法 6. 挑选异常值检测方法 7. 异常值消除 8. 总结 1. 引言 在数据处理.机器学习等领域,我们经常需要对各式各样的数据进行处理,本文重点介绍三种非常简单的方法来检测数据集中的异常值. 2. 举个栗子 为了方便介绍,这里给出我们的测试数据集,如下: data = pd.DataFrame([ [87, 82, 85], [81, 89, 75], [86, 87, 69], [91, 79, 86]
-
对python中执行DOS命令的3种方法总结
1. 使用os.system("cmd") 特点是执行的时候程序会打出cmd在Linux上执行的信息. import os os.system("ls") 2. 使用Popen模块产生新的process 现在大部分人都喜欢使用Popen.Popen方法不会打印出cmd在linux上执行的信息.的确,Popen非常强大,支持多种参数和模式.使用前需要from subprocess import Popen, PIPE.但是Popen函数有一个缺陷,就是它是一个阻塞的方
-
python中调试或排错的五种方法示例
前言 本文主要给大家介绍了关于python中调试或排错的五种方法,分享出来供大家参考学习,下面话不多说了,来一起看看详细的的介绍吧 python调试或排错的五种方法 1.print,直接打印,比较简单而且粗暴 在代码中直接输入print+需要输出的结果,根据打印的内容判断即可 2.assert断言,很方便,测试人员常常在写自动化用例的时候用的比较多 如下,直接将预期结果和实际结果做判断 def true_code(): x = 3 y = 2 z = x + y assert(5==z), "z
-
在angularJs中进行数据遍历的2种方法
2种方式分别为: 1.数组数据遍历 2.对象数据遍历 <!doctype html> <html lang="en"> <head> <meta charset="UTF-8"> <script src="angular.min.js"></script> </head> <body> <div ng-app="module"
-
python中对数据进行各种排序的方法
Python列表具有内置的 list.sort()方法,可以在原地修改列表. 还有一个 sorted()内置的函数从迭代构建一个新的排序列表.在本文中,我们将探讨使用Python排序数据的各种技术. 请注意,sort()原始数据被破坏,sorted()没有对原始数据进行操作,而是新建了一个新数据. 一.基本的排序 最基本的排序很简单.只要使用sorted()函数即可返回一个 新的排序的列表 >>>sorted([5, 2, 3, 1, 4]) [1, 2, 3, 4, 5] 咱们也可以使
-
Python中提取人脸特征的三种方法详解
目录 1.直接使用dlib 2.使用深度学习方法查找人脸,dlib提取特征 3.使用insightface提取人脸特征 安装InsightFace 提取特征 1.直接使用dlib 安装dlib方法: Win10安装dlib GPU过程详解 思路: 1.使用dlib.get_frontal_face_detector()方法检测人脸的位置. 2.使用 dlib.shape_predictor()方法得到人脸的关键点. 3.使用dlib.face_recognition_model_v1()方法提取
-
python中DataFrame数据合并merge()和concat()方法详解
目录 merge() 1.常规合并 ①方法1 ②方法2 重要参数 合并方式 left right outer inner 2.多对一合并 3.多对多合并 concat() 1.相同字段的表首位相连 2.横向表合并(行对齐) 3.交叉合并 总结 merge() 1.常规合并 ①方法1 指定一个参照列,以该列为准,合并其他列. import pandas as pd df1 = pd.DataFrame({'id': ['001', '002', '003'], 'num1': [120, 101,
-
python中list列表复制的几种方法(赋值、切片、copy(),deepcopy())
目录 1.浅拷贝和深拷贝 2.直接赋值 3.for循环 4.切片 5.copy()方法 (1)list.copy()方法 (2)copy.copy()方法 6.deepcopy()方法 1.浅拷贝和深拷贝 浅拷贝复制指向某个对象的地址(指针),而不复制对象本身,新对象和原对象共享同一内存. 深拷贝会额外创建一个新的对象,新对象跟原对象并不共享内存,修改新对象不会影响到原对象. 赋值其实就是引用了原对象.两者指向同一内存,两个对象是联动的,无论哪个对象发生改变都会影响到另一个. 2.直接赋值 使用
-
Python中给List添加元素的4种方法分享
List 是 Python 中常用的数据类型,它一个有序集合,即其中的元素始终保持着初始时的定义的顺序(除非你对它们进行排序或其他修改操作). 在Python中,向List添加元素,方法有如下4种方法(append(),extend(),insert(), +加号) 1. append() 追加单个元素到List的尾部,只接受一个参数,参数可以是任何数据类型,被追加的元素在List中保持着原结构类型. 此元素如果是一个list,那么这个list将作为一个整体进行追加,注意append()和ext
-
利用Python代码实现数据可视化的5种方法详解
前言 数据科学家并不逊色于艺术家.他们用数据可视化的方式绘画,试图展现数据内隐藏的模式或表达对数据的见解.更有趣的是,一旦接触到任何可视化的内容.数据时,人类会有更强烈的知觉.认知和交流. 数据可视化是数据科学家工作中的重要组成部分.在项目的早期阶段,你通常会进行探索性数据分析(Exploratory Data Analysis,EDA)以获取对数据的一些理解.创建可视化方法确实有助于使事情变得更加清晰易懂,特别是对于大型.高维数据集.在项目结束时,以清晰.简洁和引人注目的方式展现最终结果是非常