达梦数据库获取SQL实际执行计划方法详细介绍
目录
- 一、set autotrace trace
- 二、v$cachepln中获取执行计划
- 三、ET系统函数
- 四、dbms_sqltune系统包
- 五、说明
环境说明:
操作系统:银河麒麟V10
数据库:DM8
相关关键字:DM数据库、SQL实际执行计划
一、set autotrace trace
disql下执行set autotrace trace开启AUTOTRACE功能,执行SQL语句,并打印实际的执行计划。
SQL> set autotrace trace SQL> select a.employee_name, b.department_name from dmtest.t_emp a join dmtest.t_dept b on a.department_id = b.department_id and b.department_id=102;

二、v$cachepln中获取执行计划
v$cachepln中保存了SQL缓冲区中的执行计划信息,在ini参数USE_PLN_POOL !=0时才统计。根据v$cachepln中的cache_item可以获取实际执行计划信息:
SQL> select cache_item, sqlstr from v$cachepln where sqlstr like 'select a.employee_name, b.department_name from dmtest.t_emp a join dmtest.t_dept b on a.department_id = b.department_id and b.department_id=102%'; SQL> alter session set events 'immediate trace name plndump level 140244262459496, dump_file ''/opt/dm/sqlplntest.log''';

查看dump的执行计划信息:
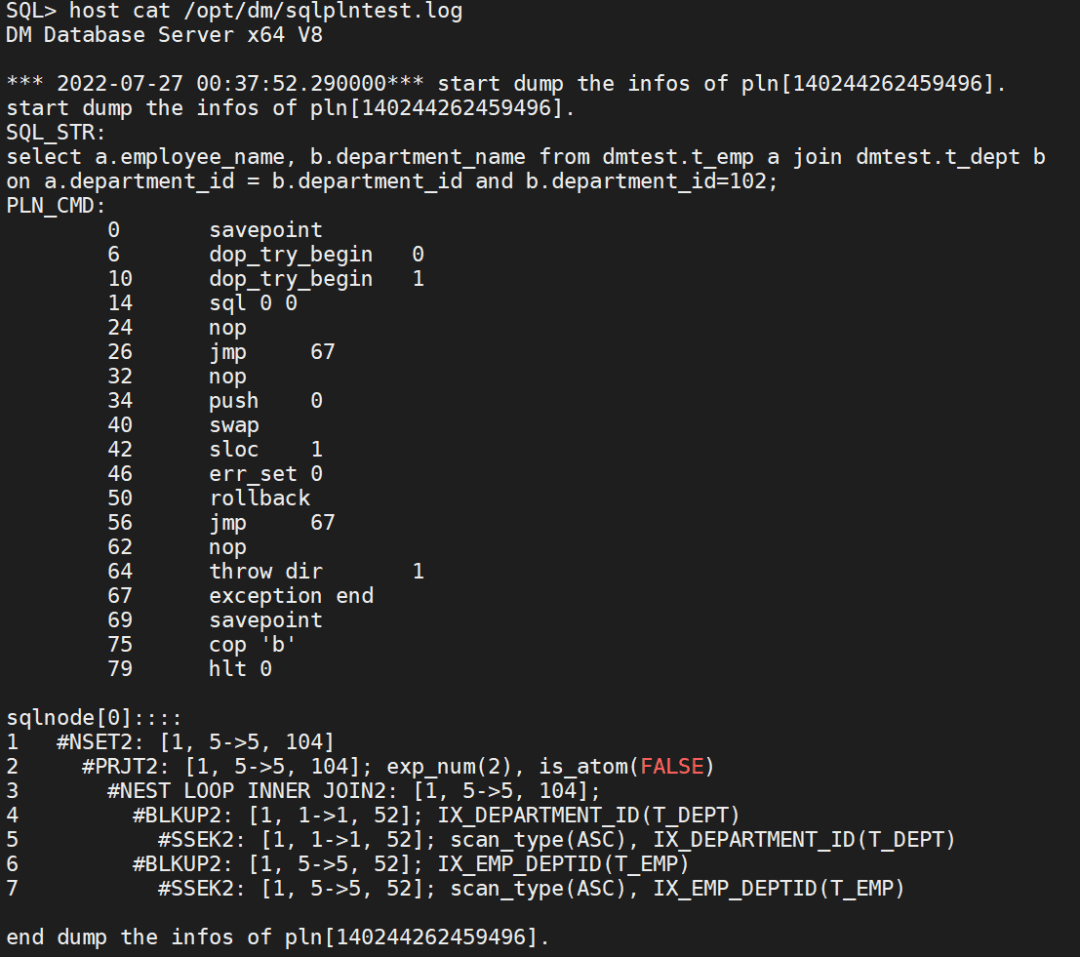
三、ET系统函数
ET函数统计对应执行ID的所有操作符的执行时间。使用ET函数需设置INI参数ENABLE_MONITOR=1、MONITOR_TIME=1和MONITOR_SQL_EXEC=1。
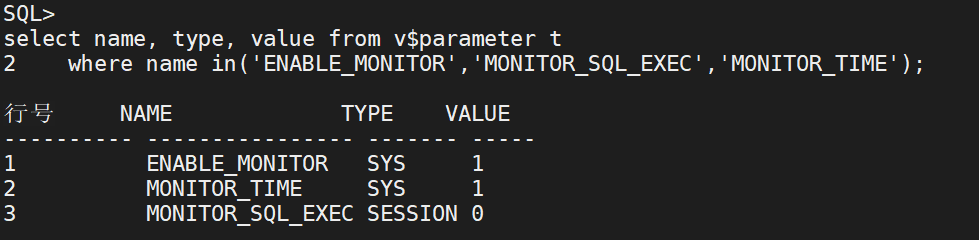
查看参数信息:
SQL>select name, type, value from v$parameter t where name in('ENABLE_MONITOR','MONITOR_SQL_EXEC','MONITOR_TIME');
行号 NAME TYPE VALUE
---- ------ ---------------- ------- -----
1 ENABLE_MONITOR SYS 1
2 MONITOR_TIME SYS 1
3 MONITOR_SQL_EXEC SESSION 0
设置当前会话MONITOR_SQL_EXEC参数为1,并执行sql语句:
SQL> alter session set 'MONITOR_SQL_EXEC'=1;

使用ET获取上述执行号为1124的SQL语句的执行计划和执行时间:

四、dbms_sqltune系统包
DBMS_SQLTUNE系统包兼容Oracle的DBMS_SQLTUNE包的部分功能,提供一系列对实时SQL监控的方法。
当SQL监控功能开启后,DBMS_SQLTUNE包可以实时监控SQL执行过程中的信息,包括:执行时间、执行代价、执行用户、统计信息等情况。使用DBMS_SQLTUNE也需要将DM.INI参数ENABLE_MONITOR、MONITOR_TIME、MONITOR_SQL_EXEC设置为1。
使用DBMS_SQLTUNE.REPORT_SQL_MONITOR方法可以查看上述执行号为1124的执行计划信息。
SQL> set long 100000 SQL> SELECT DBMS_SQLTUNE.REPORT_SQL_MONITOR(SQL_EXEC_ID=>1124);
如下图所示,可以看到此方法获取的执行计划比ET函数更详细。

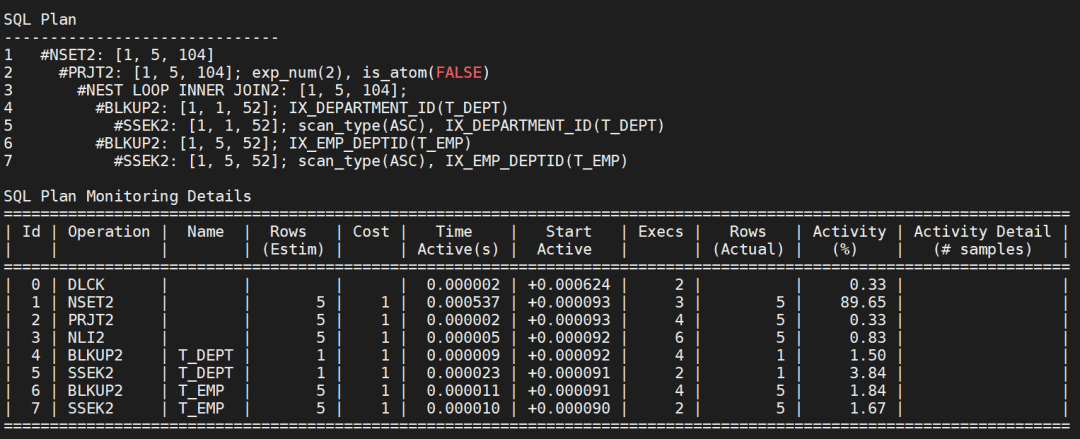
五、说明
1、set autotrace trace和v$cachepln不需要开启其他额外参数,默认就可以使用该方法获取sql语句的执行计划,不同的是set autotrace trace需要等待SQL语句执行完成才会打印执行计划;而通过v$cachepln在语句解析生成执行计划后就可以查询该SQL的执行计划;
2、使用ET函数和dbms_sqltune系统包也需要SQL语句执行完成,并且需要保证ENABLE_MONITOR、MONITOR_TIME、MONITOR_SQL_EXEC三个参数为开启状态才能查看对应SQL的实际执行计划信息,其中,dbms_sqltune执行计划更详细。
到此这篇关于达梦数据库获取SQL实际执行计划方法详细介绍的文章就介绍到这了,更多相关获取SQL实际执行计划内容请搜索我们以前的文章或继续浏览下面的相关文章希望大家以后多多支持我们!
相关推荐
-
带你学习MySQL执行计划
1.执行计划简介 执行计划是指一条 SQL 语句在经过 MySQL 查询优化器的优化会后,具体的执行方式.MySQL 为我们提供了 EXPLAIN 语句,来获取执行计划的相关信息.需要注意的是,EXPLAIN 语句并不会真的去执行相关的语句,而是通过查询优化器对语句进行分析,找出最优的查询方案,并显示对应的信息. 执行计划通常用于 SQL 性能分析.优化等场景.通过 explain 的结果,可以了解到如数据表的查询顺序.数据查询操作的操作类型.哪些索引可以被命中.哪些索引实际会命中.每个数据表
-
MySQL执行计划详解
一.MySQL执行计划介绍 在MySQL中,执行计划的实现是基于JOIN和QEP_TAB这两个对象.其中JOIN类表示一个查询语句块的优化和执行,每个select查询语句(即Query_block对象)在处理的时候,都会被当做JOIN对象,其定义在sql/sql_optimizer.h. QEP_TAB是Query Execution Plan Table的缩写,这里的表Table对象主要包含物化表.临时表.派生表.常量表等.JOIN::optimize()是优化执行器的统一入口,在这里会把一个
-

Mysql中如何查看执行计划
目录 explain执行计划包含的信息 各字段详解 id select_type type possible_keys key key_len ref rows Extra 综合Case 执行顺序 使用explain关键字可以模拟优化器执行SQL查询语句,从而知道MySQL是如何处理你的SQL语句的,分析你的查询语句或是表结构的性能瓶颈. explain执行计划包含的信息 其中最重要的字段为:id.type.key.rows.Extra 各字段详解 id select查询的序列号,包含一组数字,
-
一文带你看懂MySQL执行计划
目录 前言 explain/desc 用法 explain/desc 输出详解 一.id ,select 查询序列号 二.select_type,查询语句类型 三.table,查询涉及的表或衍生表 四.partitions查询涉及到的分区 五.type提供了判断查询是否高效的重要依据依据 六.possible_keys:指示MySQL可以从中选择查找此表中的行的索引. 七.key:MySQL查询实际使用到的索引. 八.key_len:表示索引中使用的字节数(只计算利用索引作为index key的
-
详解 MySQL 执行计划
EXPLAIN语句提供有关MySQL如何执行语句的信息.EXPLAIN与SELECT,DELETE,INSERT,REPLACE和UPDATE语句一起使用. EXPLAIN为SELECT语句中使用的每个表返回一行信息.它按照MySQL在处理语句时读取它们的顺序列出了输出中的表. MySQL使用嵌套循环连接方法解析所有连接.这意味着MySQL从第一个表中读取一行,然后在第二个表,第三个表中找到匹配的行,依此类推.处理完所有表后,MySQL输出所选列,并通过表列表回溯,直到找到一个表,其中有更多匹配
-
达梦数据库获取SQL实际执行计划方法详细介绍
目录 一.set autotrace trace 二.v$cachepln中获取执行计划 三.ET系统函数 四.dbms_sqltune系统包 五.说明 环境说明: 操作系统:银河麒麟V10 数据库:DM8 相关关键字:DM数据库.SQL实际执行计划 一.set autotrace trace disql下执行set autotrace trace开启AUTOTRACE功能,执行SQL语句,并打印实际的执行计划. SQL> set autotrace trace SQL> select a.e
-
Oracle中基于hint的3种执行计划控制方法详细介绍
hint(提示)无疑是最基本的控制执行计划的方式了:通过在SQL语句中直接嵌入优化器指令,进而使优化器在语句执行时强制的选择hint指定的执行路径,这种使用方式最大的好处便是方便和快捷,定制度也很高,通常在对某些SQL语句执行计划进行微调的时候我会首选这种方式,不过尽管如此,hint在使用中仍然有很多不可忽视的问题: 使用hint过程中有一些值得注意的细则,首先便是要准确的识别对应的查询块,如果需要使用注释也可以hint中声明:对于使用别名的对象一律使用别名来引用,并且诸如"用户名.对象&quo
-
国产化中的 .NET Core 操作达梦数据库DM8的两种方式(操作详解)
目录 背景 环境 SDK 操作数据库 DbHelperSQL方式 Dapper方式 背景 某个项目需要实现基础软件全部国产化,其中操作系统指定银河麒麟,数据库使用达梦V8,CPU平台的范围包括x64.龙芯.飞腾.鲲鹏等.考虑到这些基础产品对.NET的支持,最终选择了.NET Core 3.1. 环境 CPU平台:x86-64 / Arm64 操作系统:银河麒麟 v4 数据库:DM8 .NET:.NET Core 3.1 SDK 达梦自己提供了.NET操作其数据库的SDK,可以通过NuGet安装,
-
MySql中如何使用 explain 查询 SQL 的执行计划
explain命令是查看查询优化器如何决定执行查询的主要方法. 这个功能有局限性,并不总会说出真相,但它的输出是可以获取的最好信息,值得花时间去了解,因为可以学习到查询是如何执行的. 1.什么是MySQL执行计划 要对执行计划有个比较好的理解,需要先对MySQL的基础结构及查询基本原理有简单的了解. MySQL本身的功能架构分为三个部分,分别是 应用层.逻辑层.物理层,不只是MySQL ,其他大多数数据库产品都是按这种架构来进行划分的. 应用层,主要负责与客户端进行交互,建立链接,记住链接状态,
-
MyBatis-plus+达梦数据库实现自动生成代码的示例
先说点什么 mybatis-plus是一款增强版的mybatis,功能强大,可以很大程度的简化开发. 然而达梦数据库比较小众,虽然官方说mybatis-plus支持达梦数据库,但是使用起来遇到了很多问题. 这篇文章主要讲如何使用mybatis-plus访问达梦数据库,并使用逆向工程自动生成代码. =.=对了 这是个使用spring boot的项目. (配置)POM文件,引入所需要的依赖 <dependencies> <dependency> <groupId>org.s
-
Centos7 安装达梦数据库的教程
1 准备工作 安装好Linux操作系统这里选择的是Linux 7: [root@slave1 software]# cat /etc/redhat-release CentOS Linux release 7.6.1810 (Core) 关闭防火墙 和 Selinux: [root@slave1 software]# systemctl stop firewalld [root@slave1 software]# systemctl disable firewalld [root@slave1
-
springBoot配置国产达梦数据库的示例详解
1. pom <!-- 达梦数据库驱动 --> <dependency> <groupId>com.dm</groupId> <artifactId>DmJdbcDriver18</artifactId> <version>1.8</version> </dependency> maven中央仓库里面没有,需要手动安装到maven本地仓库 mvn install:install-file -Dfil
-
Docker快速部署国产达梦数据库的实现示例
目录 前言 ️ 1.达梦简介 ️ 2.镜像下载 ️ 3.创建容器 ️ 4.数据库使用 4.1 数据库登陆 4.2 DEM介绍 4.3 远程连接达梦 前言 本文总结了Docker部署达梦数据库的方法,方便大家研究学习. ️ 1.达梦简介 达梦数据库管理系统是达梦公司推出的具有完全自主知识产权的高性能数据库管理系统,简称DM.达梦数据库管理系统的最新版本是8.0版本,简称DM8.DM8采用全新的体系架构,在保证大型通用的基础上,针对可靠性.高性能.海量数据处理和安全性做了大量的研发和改进工作,极大提
-
oracle数据库关于索引建立及使用的详细介绍
索引的说明 索引是与表相关的一个可选结构,在逻辑上和物理上都独立于表的数据,索引能优化查询,不能优化DML操作,Oracle自动维护索引,频繁的DML操作反而会引起大量的索引维护. 如果SQL语句仅访问被索引的列,那么数据库只需从索引中读取数据,而不用读取表. 如果该语句同时还要访问除索引列之外的列,那么,数据库会使用rowid来查找表中的行. 通常,为检索表数据,数据库以交替方式先读取索引块,然后读取相应的表块. 索引的目的 主要是减少IO,这是本质,这样才能体现索引的效率. 1大表,返回的行
-
强制SQL Server执行计划使用并行提升在复杂查询语句下的性能
通过观察执行计划,发现之前的执行计划在很多大表连接的部分使用了Hash Join,由于涉及的表中数据众多,因此查询优化器选择使用并行执行,速度较快.而我们优化完的执行计划由于索引的存在,且表内数据非常大,过滤条件的值在一个很宽的统计信息步长范围内,导致估计行数出现较大偏差(过滤条件实际为15000行,步长内估计的平均行数为800行左右),因此查询优化器选择了Loop Join,且没有选择并行执行,因此执行时间不降反升. 由于语句是在存储过程中实现,因此我们直接对该语句使用一个undocument