YOLOv5改进系列之增加小目标检测层
目录
- 1.YOLOv5算法简介
- 2.原始YOLOv5模型
- 3.增加小目标检测层
- 总结
小目标检测一直以来是CV领域的难点之一,那么,YOLOv5该如何增加小目标检测层呢?
YOLOv5代码修改————针对微小目标检测
1.YOLOv5算法简介
YOLOv5主要由输入端、Backone、Neck以及Prediction四部分组成。其中:
(1) Backbone:在不同图像细粒度上聚合并形成图像特征的卷积神经网络。
(2) Neck:一系列混合和组合图像特征的网络层,并将图像特征传递到预测层。
(3) Head: 对图像特征进行预测,生成边界框和并预测类别。
检测框架:
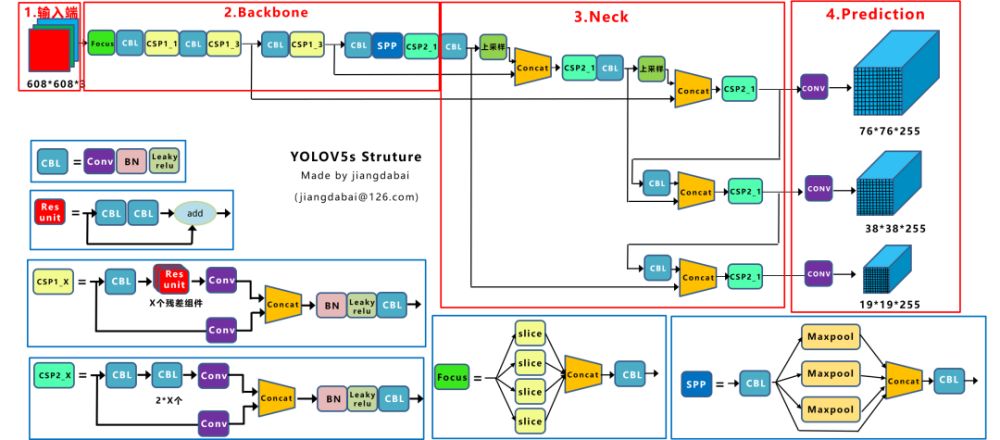
2.原始YOLOv5模型
# YOLOv5 head head: [[-1, 1, Conv, [512, 1, 1]], [-1, 1, nn.Upsample, [None, 2, 'nearest']], [[-1, 6], 1, Concat, [1]], # cat backbone P4 [-1, 3, C3, [512, False]], # 13 [-1, 1, Conv, [256, 1, 1]], [-1, 1, nn.Upsample, [None, 2, 'nearest']], [[-1, 4], 1, Concat, [1]], # cat backbone P3 [-1, 3, C3, [256, False]], # 17 (P3/8-small) [-1, 1, Conv, [256, 3, 2]], [[-1, 14], 1, Concat, [1]], # cat head P4 [-1, 3, C3, [512, False]], # 20 (P4/16-medium) [-1, 1, Conv, [512, 3, 2]], [[-1, 10], 1, Concat, [1]], # cat head P5 [-1, 3, C3, [1024, False]], # 23 (P5/32-large) [[17, 20, 23], 1, Detect, [nc, anchors]], # Detect(P3, P4, P5) ]
若输入图像尺寸=640X640,
# P3/8 对应的检测特征图大小为80X80,用于检测大小在8X8以上的目标。
# P4/16对应的检测特征图大小为40X40,用于检测大小在16X16以上的目标。
# P5/32对应的检测特征图大小为20X20,用于检测大小在32X32以上的目标。
3.增加小目标检测层
# parameters nc: 1 # number of classes depth_multiple: 0.33 # model depth multiple width_multiple: 0.50 # layer channel multiple # anchors anchors: - [5,6, 8,14, 15,11] #4 - [10,13, 16,30, 33,23] # P3/8 - [30,61, 62,45, 59,119] # P4/16 - [116,90, 156,198, 373,326] # P5/32 # YOLOv5 backbone backbone: # [from, number, module, args] [[-1, 1, Focus, [64, 3]], # 0-P1/2 [-1, 1, Conv, [128, 3, 2]], # 1-P2/4 [-1, 3, BottleneckCSP, [128]], #160*160 [-1, 1, Conv, [256, 3, 2]], # 3-P3/8 [-1, 9, BottleneckCSP, [256]], #80*80 [-1, 1, Conv, [512, 3, 2]], # 5-P4/16 [-1, 9, BottleneckCSP, [512]], #40*40 [-1, 1, Conv, [1024, 3, 2]], # 7-P5/32 [-1, 1, SPP, [1024, [5, 9, 13]]], [-1, 3, BottleneckCSP, [1024, False]], # 9 20*20 ] # YOLOv5 head head: [[-1, 1, Conv, [512, 1, 1]], #20*20 [-1, 1, nn.Upsample, [None, 2, 'nearest']], #40*40 [[-1, 6], 1, Concat, [1]], # cat backbone P4 40*40 [-1, 3, BottleneckCSP, [512, False]], # 13 40*40 [-1, 1, Conv, [512, 1, 1]], #40*40 [-1, 1, nn.Upsample, [None, 2, 'nearest']], [[-1, 4], 1, Concat, [1]], # cat backbone P3 80*80 [-1, 3, BottleneckCSP, [512, False]], # 17 (P3/8-small) 80*80 [-1, 1, Conv, [256, 1, 1]], #18 80*80 [-1, 1, nn.Upsample, [None, 2, 'nearest']], #19 160*160 [[-1, 2], 1, Concat, [1]], #20 cat backbone p2 160*160 [-1, 3, BottleneckCSP, [256, False]], #21 160*160 [-1, 1, Conv, [256, 3, 2]], #22 80*80 [[-1, 18], 1, Concat, [1]], #23 80*80 [-1, 3, BottleneckCSP, [256, False]], #24 80*80 [-1, 1, Conv, [256, 3, 2]], #25 40*40 [[-1, 14], 1, Concat, [1]], # 26 cat head P4 40*40 [-1, 3, BottleneckCSP, [512, False]], # 27 (P4/16-medium) 40*40 [-1, 1, Conv, [512, 3, 2]], #28 20*20 [[-1, 10], 1, Concat, [1]], #29 cat head P5 #20*20 [-1, 3, BottleneckCSP, [1024, False]], # 30 (P5/32-large) 20*20 [[21, 24, 27, 30], 1, Detect, [nc, anchors]], # Detect(p2, P3, P4, P5) ]
# 新增加160X160的检测特征图,用于检测4X4以上的目标。
改进后,虽然计算量和检测速度有所增加,但对小目标的检测精度有明显改善。
总结
到此这篇关于YOLOv5改进系列之增加小目标检测层的文章就介绍到这了,更多相关YOLOv5增加小目标检测层内容请搜索我们以前的文章或继续浏览下面的相关文章希望大家以后多多支持我们!
相关推荐
-

YOLOv5目标检测之anchor设定
目录 前言 anchor的检测过程 anchor产生过程 总结 前言 yolo算法作为one-stage领域的佼佼者,采用anchor-based的方法进行目标检测,使用不同尺度的anchor直接回归目标框并一次性输出目标框的位置和类别置信度. 为什么使用anchor进行检测? 最初的YOLOv1的初始训练过程很不稳定,在YOLOv2的设计过程中,作者观察了大量图片的ground truth,发现相同类别的目标实例具有相似的gt长宽比:比如车,gt都是矮胖的长方形:比如行人,gt都是瘦高的长方形
-
Pytorch搭建YoloV5目标检测平台实现过程
目录 学习前言 源码下载 YoloV5改进的部分(不完全) YoloV5实现思路 一.整体结构解析 二.网络结构解析 2.构建FPN特征金字塔进行加强特征提取 三.预测结果的解码 1.获得预测框与得分 2.得分筛选与非极大抑制 四.训练部分 1.计算loss所需内容 2.正样本的匹配过程 a.匹配先验框 b.匹配特征点 3.计算Loss 训练自己的YoloV5模型 一.数据集的准备 二.数据集的处理 三.开始网络训练 四.训练结果预测 学习前言 这个很久都没有学,最终还是决定看看,复现的是Yol
-
YOLOv5改进系列之增加小目标检测层
目录 1.YOLOv5算法简介 2.原始YOLOv5模型 3.增加小目标检测层 总结 小目标检测一直以来是CV领域的难点之一,那么,YOLOv5该如何增加小目标检测层呢? YOLOv5代码修改————针对微小目标检测 1.YOLOv5算法简介 YOLOv5主要由输入端.Backone.Neck以及Prediction四部分组成.其中: (1) Backbone:在不同图像细粒度上聚合并形成图像特征的卷积神经网络. (2) Neck:一系列混合和组合图像特征的网络层,并将图像特征传递到预测层. (
-
Keras神经网络efficientnet模型搭建yolov3目标检测平台
目录 什么是EfficientNet模型 源码下载 EfficientNet模型的实现思路 1.EfficientNet模型的特点 2.EfficientNet网络的结构 EfficientNet的代码构建 1.模型代码的构建 2.Yolov3上的应用 什么是EfficientNet模型 2019年,谷歌新出EfficientNet,在其它网络的基础上,大幅度的缩小了参数的同时提高了预测准确度,简直太强了,我这样的强者也要跟着做下去 EfficientNet,网络如其名,这个网络非常的有效率,怎
-
教你用YOLOv5实现多路摄像头实时目标检测功能
目录 前言 一.YOLOV5的强大之处 二.YOLOV5部署多路摄像头的web应用 1.多路摄像头读取 2.模型封装 3.Flask后端处理 4.前端展示 总结 前言 YOLOV5模型从发布到现在都是炙手可热的目标检测模型,被广泛运用于各大场景之中.因此,我们不光要知道如何进行yolov5模型的训练,而且还要知道怎么进行部署应用.在本篇博客中,我将利用yolov5模型简单的实现从摄像头端到web端的部署应用demo,为读者提供一些部署思路. 一.YOLOV5的强大之处 你与目标检测高手之差一个Y
-
python目标检测yolo1 yolo2 yolo3和SSD网络结构对比
目录 睿智的目标检测5——yolo1.yolo2.yolo3和SSD的网络结构汇总对比 学习前言各个网络的结构图与其实现代码1.yolo12.yolo23.yolo34.SSD 总结 学习前言 ……最近在学习yolo1.yolo2和yolo3,事实上它们和SSD网络有一定的相似性,我准备汇总一下,看看有什么差别. 各个网络的结构图与其实现代码 1.yolo1 由图可见,其进行了二十多次卷积还有四次最大池化,其中3x3卷积用于提取特征,1x1卷积用于压缩特征,最后将图像压缩到7x7xfilter的
-
python目标检测yolo3详解预测及代码复现
目录 学习前言 实现思路 1.yolo3的预测思路(网络构建思路) 2.利用先验框对网络的输出进行解码 3.进行得分排序与非极大抑制筛选 实现结果 学习前言 对yolo2解析完了之后当然要讲讲yolo3,yolo3与yolo2的差别主要在网络的特征提取部分,实际的解码部分其实差距不大 代码下载 本次教程主要基于github中的项目点击直接下载,该项目相比于yolo3-Keras的项目更容易看懂一些,不过它的许多代码与yolo3-Keras相同. 我保留了预测部分的代码,在实际可以通过执行dete
-
Pytorch搭建YoloV4目标检测平台实现源码
目录 什么是YOLOV4 YOLOV4结构解析 1.主干特征提取网络Backbone 2.特征金字塔 3.YoloHead利用获得到的特征进行预测 4.预测结果的解码 5.在原图上进行绘制 YOLOV4的训练 1.YOLOV4的改进训练技巧 a).Mosaic数据增强 b).Label Smoothing平滑 c).CIOU d).学习率余弦退火衰减 2.loss组成 a).计算loss所需参数 b).y_pre是什么 c).y_true是什么. d).loss的计算过程 训练自己的YoloV4
-
YOLOv5改进之添加SE注意力机制的详细过程
目录 前言: 解决问题: 添加方法: 结果: 总结 前言: 作为当前先进的深度学习目标检测算法YOLOv5,已经集合了大量的trick,但是在处理一些复杂背景问题的时候,还是容易出现错漏检的问题.此后的系列文章,将重点对YOLOv5的如何改进进行详细的介绍,目的是为了给那些搞科研的同学需要创新点或者搞工程项目的朋友需要达到更好的效果提供自己的微薄帮助和参考. 解决问题: 加入SE通道注意力机制,可以让网络更加关注待检测目标,提高检测效果 SE模块的原理和结构 添加方法: 第一步:确定添加的位置,
-
opencv-python+yolov3实现目标检测
因为最近的任务有用到目标检测,所以昨天晚上.今天上午搞了一下,快速地了解了目标检测这一任务,并且实现了使用opencv进行目标检测. 网上资料挺乱的,感觉在搜资源上浪费了我不少时间,所以我写这篇博客,把我这段时间了解到的东西整理起来,供有缘的读者参考学习. 目标检测概况 目标检测是? 目标检测,粗略来说就是:输入图片/视频,经过处理,得到:目标的位置信息(比如左上角和右下角的坐标).目标的预测类别.目标的预测置信度(confidence). 拿Faster R-CNN这个算法举例:输入一个bat