ZooKeeper集群操作及集群Master选举搭建启动
目录
- ZooKeeper介绍
- ZooKeeper特征
- 分层命名空间
- 搭建ZK集群
- 启动zk集群
- zk集群master选举
ZooKeeper介绍
ZooKeeper 是一个为 分布式应用 提供的 分布式 、开源的 协调服务 。
它公开了一组简单的 原语 ,分布式应用程序可以根据这些原语来实现用于 同步 、配置维护 以及 命名 的更高级别的服务。
怎么理解协调服务呢?比如我们有很多应用程序,他们之间都需要读写维护一个 id ,那么这些 id 怎么命名呢,程序一多,必然会乱套,ZooKeeper 能协调这些服务,解决命名、配置、同步等问题,而做到这些,只需要一组简单的 原语 即可:
create : 在树中的某个位置创建一个节点
delete : 删除一个节点
exists : 测试节点是否存在于某个位置
get data : 从节点读取数据
set data : 往一个节点里写入数据
get children : 检索节点的子节点列表
sync : 等待数据被传播
从这些 ZooKeeper (以下简称ZK)的 API 可以看到,都是围绕 Node 来操作,下文实操看一下怎么操作 Node 。
ZooKeeper特征
- 简单
ZooKeeper 允许分布式进程通过 共享的层级命名空间 相互协调,该命名空间的组织类似于标准文件系统。
命名空间由数据寄存器组成,在 ZooKeeper 称为 znodes ,它们类似于文件和目录。
与典型的文件系统不同,它是为 存储 而设计的,ZooKeeper 数据保存在 内存 中,这意味着ZooKeeper 可以实现 高吞吐量 和 低延迟数 。
ZooKeeper 很重视 高性能,高可用性 ,严格有序访问 :性能高意味着它可以在大型分布式系统中使用;而他又具备可靠性,这使它不会成为单点故障;严格的排序意味着可以在客户端上实现复杂的同步原语。
- 可被复制(高可用)
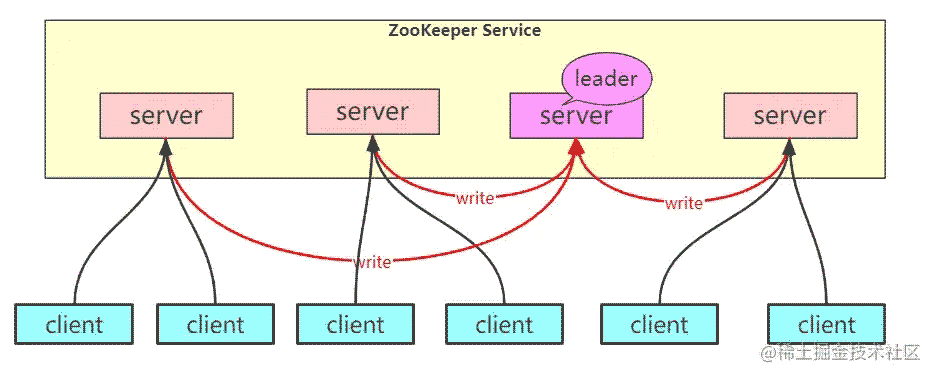
像它协调的分布式进程一样,ZooKeeper 本身也可以在称为集合的一组主机上进行复制。
组成ZooKeeper 服务的服务器都必须彼此了解。它们维护内存中的状态镜像,以及持久存储中的事务日志和快照。只要大多数服务器可用,ZooKeeper 服务将可用。
客户端连接到单个 ZooKeeper 服务器。客户端维护一个 TCP连接 ,通过该连接发送请求,获取响应,获取监视事件并发送心跳。如果与服务器的 TCP连接 断开,则客户端将连接到其他服务器。
- 有序的
ZooKeeper 用一个反映所有 ZooKeeper 事务顺序 的数字标记每个更新。后续操作可以使用该命令来实现更高级别的抽象,例如 同步 、 分布式锁 。
- 快
在 读取为主 的工作负载中,它特别快。
ZooKeeper 应用程序可在数千台计算机上运行,并且在读取比写入更常见的情况下,其性能最佳,比率约为10:1。
分层命名空间
ZooKeeper提供的名称空间与标准文件系统的名称空间非常相似。
名称是由 斜杠 (/)分隔的一系列路径元素。ZooKeeper 命名空间中的每个节点均由路径标识。
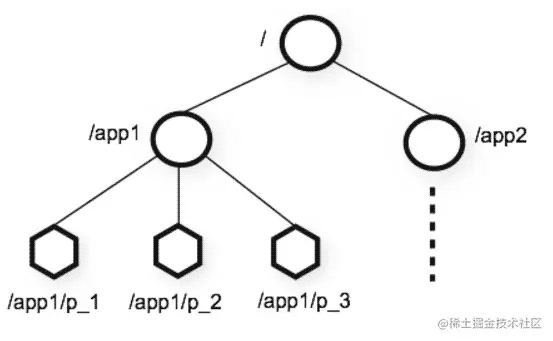
一个 ZK Node 可以存储 1M 数据,Node分为 持久节点 和 临时性节点 。
- 持久节点
与标准文件系统不同,ZooKeeper 命名空间中的每个节点都可以具有与其关联的 数据 以及 子节点 。就像拥有一个文件系统一样,该文件系统也允许文件成为目录。
ZooKeeper旨在存储协调数据:状态信息,配置,位置信息等,因此存储在每个节点上的数据通常很小,在字节到千字节范围内。
Znodes 维护一个统计信息结构,其中包括用于 数据更改 ,ACL更改(权限控制) 和 时间戳的版本号 ,以允许进行 缓存验证 和 协调更新 。
Znode 的数据每次更改时,版本号都会增加。例如,每当客户端检索数据时,它也会接收数据的版本。
原子地读取和写入存储在名称空间中每个 Znode 上的数据。读取将获取与znode关联的所有数据字节,而写入将替换所有数据。每个节点都有一个访问控制列表(ACL),用于限制谁可以做什么。
- 临时节点
只要创建 Znode 的会话处于 活动状态 ,这些 Znode 就一致存在。会话结束时,将删除 Znode ,这就是临时节点。
类比于web容器比如tomcat的session,创建临时节点的session存在,则node存在,session结束,删除node。
以上是理论知识,还是实际操作一遍比较靠谱,理解一下zk创建连接、node、session这些概念,以及看看zk集群的leader出故障后,选出leader的速度。
搭建ZK集群
首先准备 4 台 CentOS 7 虚拟机,都安装好了JDK 8(JDK版本最好不要小于8)。
这四台虚拟机主机名称分别设置为:zknode01 、zknode02 、zknode03 、zknode04 。
hostnamectl set-hostname zknode01
主机名在配置 ZooKeeper 集群的时候有用。
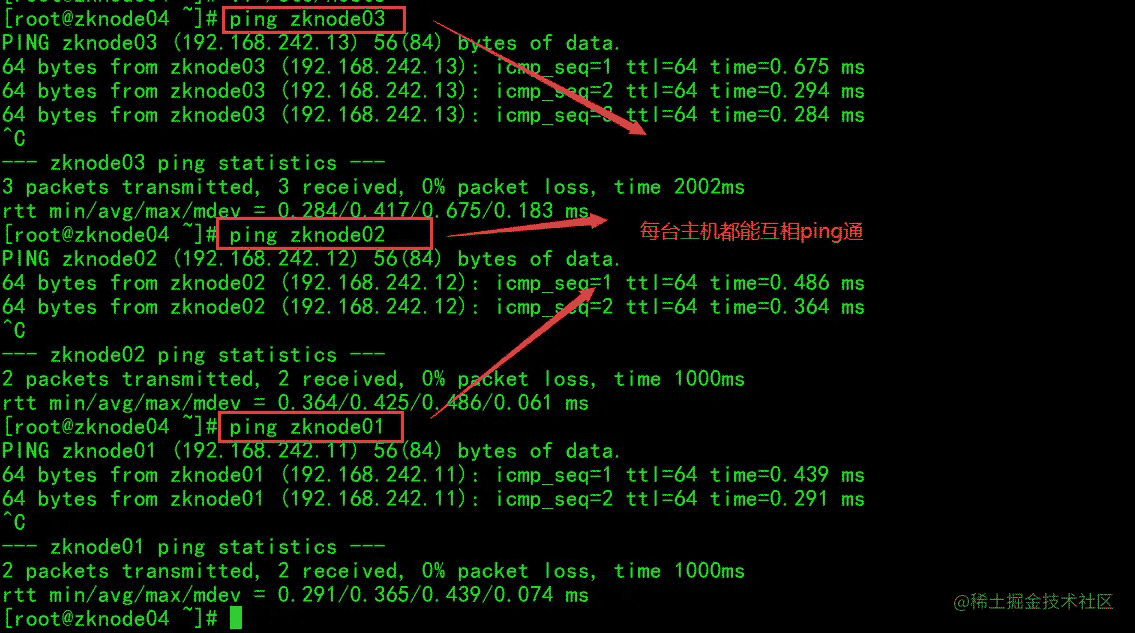
主机名称配置好之后,还需要配置主机名和IP地址的映射关系,每台主机均编辑 /etc/hosts 文件,末尾添加如下内容:
192.168.242.11 zknode01
192.168.242.12 zknode02
192.168.242.13 zknode03
192.168.242.14 zknode04
保证每台主机都能互相 ping 通:
接下来,先安装配置好其中一台服务器的 ZooKeeper ,然后用 scp 分发到各个服务器,再分别修改 zk server 的 id ,这样不用每台虚拟机都执行一遍相同的操作。
下载zk,注意一定要是apache-zookeeper-3.7.1-bin.tar.gz这个带bin的,否则如果不是带bin的,启动的时候会报如下错误:
Error: Could not find or load main class org.apache.zookeeper.server.quorum.QuorumPeerMain Caused by: java.lang.ClassNotFoundException: org.apache.zookeeper.server.quorum.QuorumPeerMain
保姆式安装zk步骤:
将下载好的 apache-zookeeper-3.7.1-bin.tar.gz 放到/opt目录下
1. cd /opt
2. tar xf apache-zookeeper-3.7.1-bin.tar.gz
3. mv apache-zookeeper-3.7.1-bin zookeeper
4. vi /etc/profile
export JAVA_HOME=/usr/local/java
export ZK_HOME=/opt/zookeeper
export PATH=$PATH:$JAVA_HOME/bin:$ZK_HOME/bin
5. source /etc/profile
6. cd /opt/zookeeper/conf
7. cp zoo_sample.cfg zoo.cfg
8. vi zoo.cfg
设置 dataDir=/var/zookeeper
末尾添加:
server.1=zknode01:2888:3888
server.2=zknode02:2888:3888
server.3=zknode03:2888:3888
server.4=zknode04:2888:3888
9. mkdir -p /var/zookeeper
10. echo 1 > /var/zookeeper/myid
这样 zknode01 的 zkserver 就搭建好了,现在将 ZooKeeper目录 和 配置文件 分发到其余三台服务器:
# 传到 zknode02 scp -r /opt/zookeeper/ root@zknode02:/opt/ scp /etc/profile root@zknode02:/etc # 传到 zknode03 scp -r /opt/zookeeper/ root@zknode03:/opt/ scp /etc/profile root@zknode03:/etc # 传到 zknode04 scp -r /opt/zookeeper/ root@zknode04:/opt/ scp /etc/profile root@zknode04:/etc
别忘了 ,每台主机都需要执行 source /etc/profile 和创建 /var/zookeeper/myid 文件,myid 的内容分别为 2,3,4 。
这样 zk集群 就搭建好了。
启动zk集群
按顺序启动 zknode01 ,zknode02 ,zknode03 ,zknode04 的zk服务:
zkServer.sh start-foreground
zk默认后台启动,start-foreground表示前台启动,方便看日志。
启动zknode01的zk server:
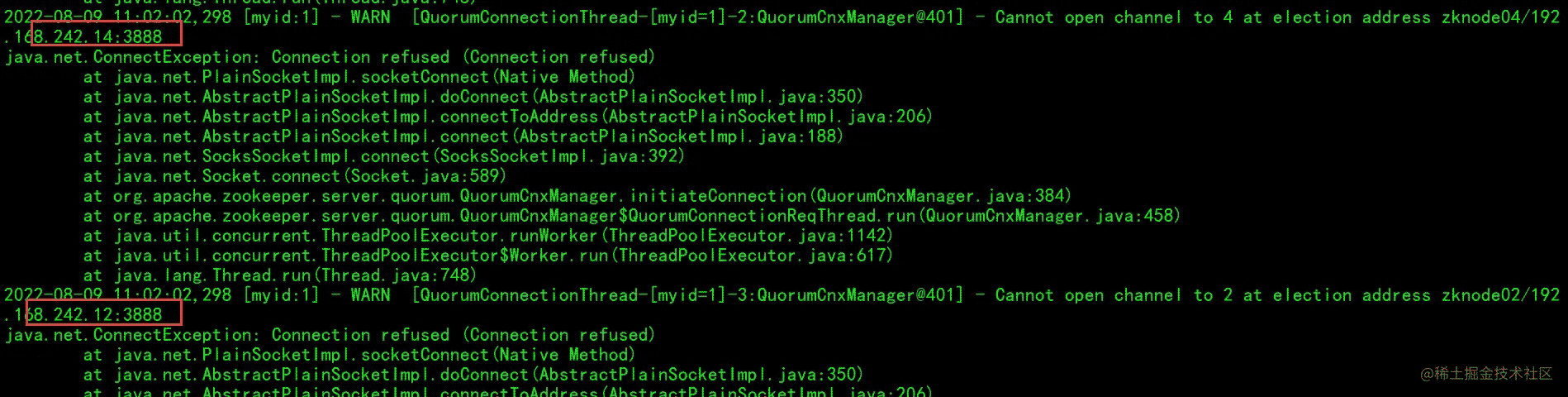
会报错,因为 zoo.cfg 配置了4台主机,其余三台还未启动,接着启动 zknode02 的:
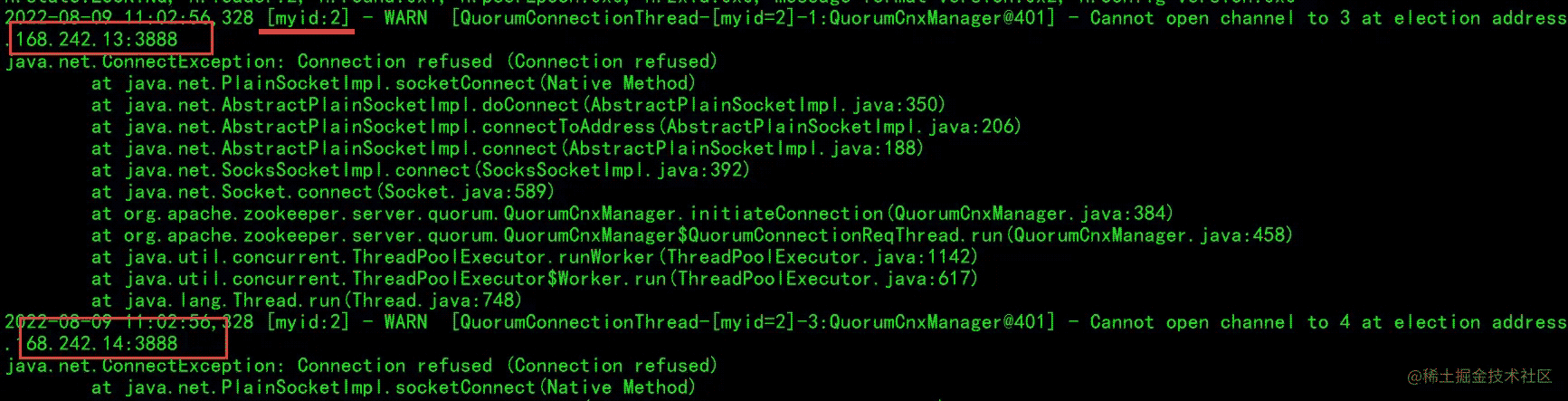
现象同 zknode01 ,继续启动第三台:

这个时候也会报 zknode04 连接不上(因为还没启动),但是整个zk集群已经启动了,并且选择了 zknode03 这个为leader。
把 zknode04 也启动一下:
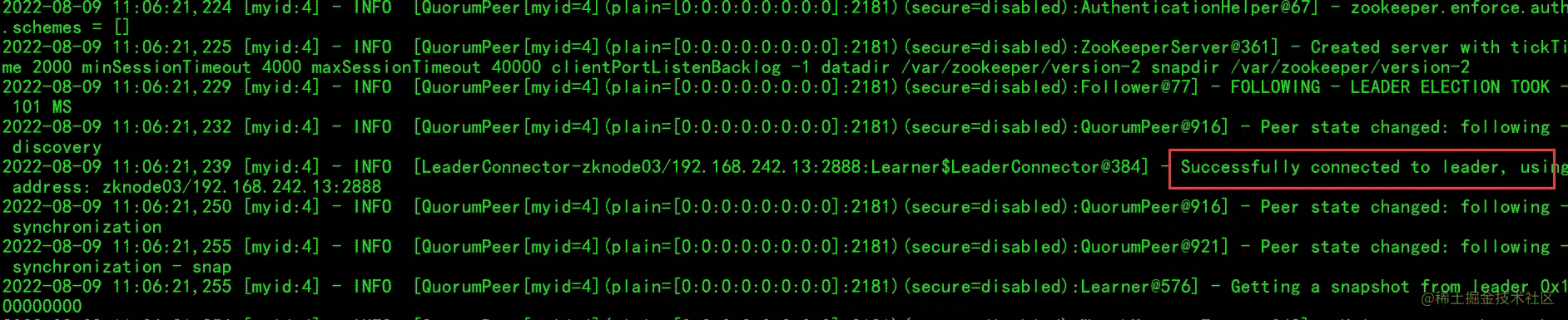
启动完成后,开一个 zknode01 的zk客户端:
zkCli.sh [zk: localhost:2181(CONNECTED) 0] help ZooKeeper -server host:port -client-configuration properties-file cmd args addWatch [-m mode] path # optional mode is one of [PERSISTENT, PERSISTENT_RECURSIVE] - default is PERSISTENT_RECURSIVE addauth scheme auth close config [-c] [-w] [-s] connect host:port create [-s] [-e] [-c] [-t ttl] path [data] [acl] delete [-v version] path deleteall path [-b batch size] delquota [-n|-b] path get [-s] [-w] path getAcl [-s] path getAllChildrenNumber path getEphemerals path history listquota path ls [-s] [-w] [-R] path printwatches on|off quit
用上面的命令操作一波:
[zk: localhost:2181(CONNECTED) 1] ls ls [-s] [-w] [-R] path [zk: localhost:2181(CONNECTED) 2] ls / [zookeeper] [zk: localhost:2181(CONNECTED) 3] [zk: localhost:2181(CONNECTED) 3] create /laogong Created /laogong [zk: localhost:2181(CONNECTED) 4] ls / [laogong, zookeeper] [zk: localhost:2181(CONNECTED) 5] get /laogong null [zk: localhost:2181(CONNECTED) 6] create /laogong "laogong" Node already exists: /laogong [zk: localhost:2181(CONNECTED) 7] delete /laogong [zk: localhost:2181(CONNECTED) 8] ls / [zookeeper] [zk: localhost:2181(CONNECTED) 9] create /laogong "laogong" Created /laogong [zk: localhost:2181(CONNECTED) 10] ls / [laogong, zookeeper] [zk: localhost:2181(CONNECTED) 11] get /laogong laogong [zk: localhost:2181(CONNECTED) 12] create /laogong/laopo "laopo" Created /laogong/laopo [zk: localhost:2181(CONNECTED) 13] ls / [laogong, zookeeper] [zk: localhost:2181(CONNECTED) 14] ls /laogong [laopo] [zk: localhost:2181(CONNECTED) 15] get /laogong/laopo laopo [zk: localhost:2181(CONNECTED) 16]
上面的操作我都是在 zknode01 上面连接zk进行操作的,来看一下,在其他zkserver上有没有同步过来数据:
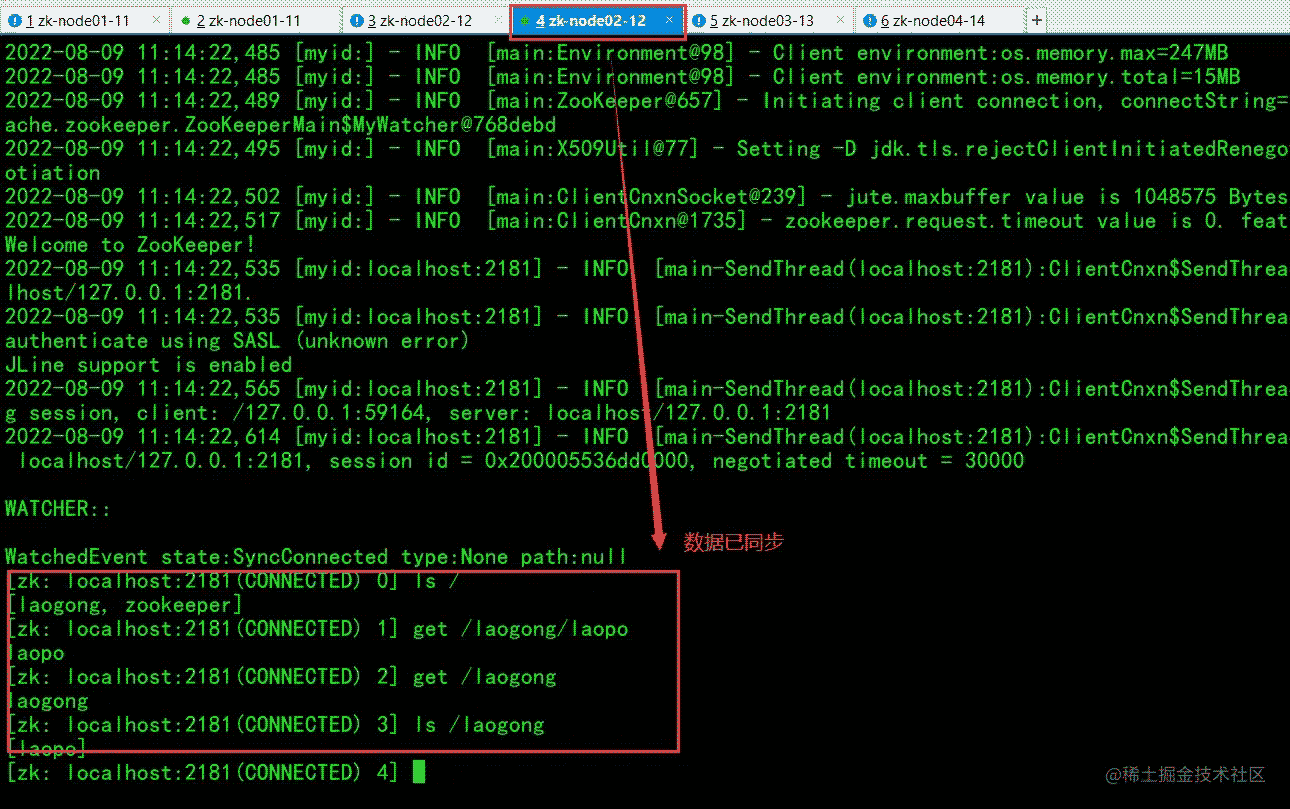
发现数据已经同步,zknode03 和 zknode04 数据也同步了。
再来看一下连接 zknode02 的连接状态:
[root@zknode02 ~]# netstat -natp | egrep '(2888|3888)' tcp6 0 0 192.168.242.12:3888 :::* LISTEN 9530/java tcp6 0 0 192.168.242.12:3888 192.168.242.13:47474 ESTABLISHED 9530/java tcp6 0 0 192.168.242.12:37804 192.168.242.13:2888 ESTABLISHED 9530/java tcp6 0 0 192.168.242.12:3888 192.168.242.14:47530 ESTABLISHED 9530/java tcp6 0 0 192.168.242.12:39666 192.168.242.11:3888 ESTABLISHED 9530/java

连接状态分析:
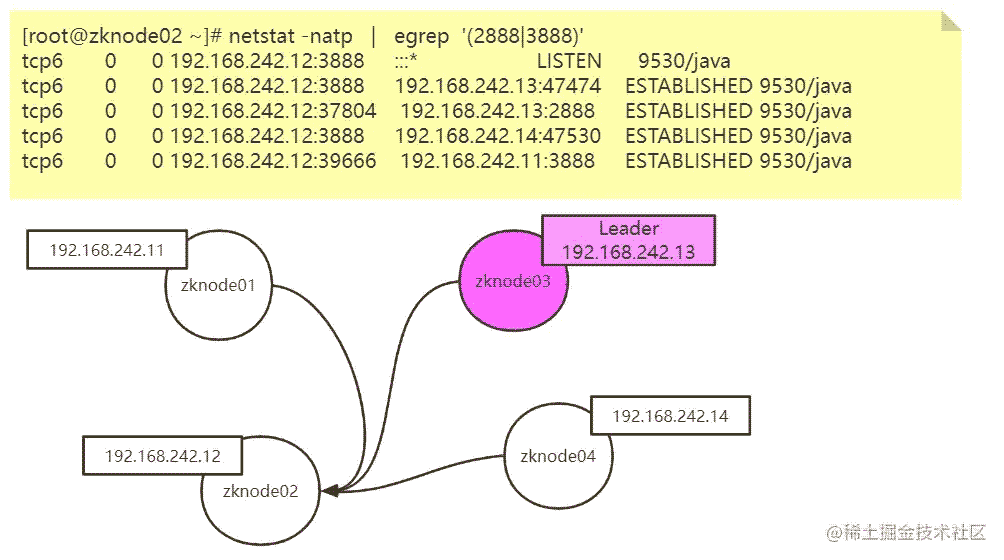
上图是从 zknode02 服务器查看的,通过查看每台服务器,最终,zk集群的服务器每台都 互相通信 。
这个 3888 端口就是选举master用的,而 2888 端口是leader接受write请求用的。
zk集群master选举
前面演示了有 4 个服务器的 zk集群 ,其中 zknode03 是 leader 。
现在我把 zknode03 服务干掉:
^C[root@zknode03 conf]# zkServer.sh status ZooKeeper JMX enabled by default Using config: /opt/zookeeper/bin/../conf/zoo.cfg Client port found: 2181. Client address: localhost. Client SSL: false. Error contacting service. It is probably not running. [root@zknode03 conf]# [root@localhost ~]#
再来分别看一下 zknode01 ~ zknode04的 zk server 状态:


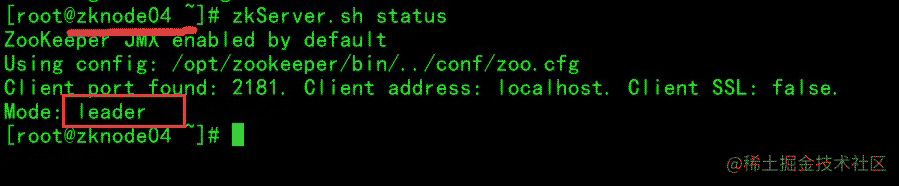
可以看到 zknode04 自动成了 leader !
事实上,zk集群 选举 leader 采用的是 谦让 的办法,谁的 id 大,选举谁。
那么前面为什么zknode3是leader呢?
因为我启动的顺序是 zknode01 ~ zknode04 启动的,当 zknode03 的zk server 启动的时候,已经 满足集群的最少节点数 了,而且 zknode03 的 id 是 当时 最大的,所以 zknode03 的 server自动成了 leader 。
以上就是ZooKeeper集群操作及集群Master选举搭建启动的详细内容,更多关于ZooKeeper集群操作选举的资料请关注我们其它相关文章!
相关推荐
-
docker搭建Zookeeper集群的方法步骤
目录 0.前言 1.前提 2.开始搭建 解释 创建zoo.cfg 3.docker搭建 1.docker创建网络 2.启动第1个zk节点 3.启动第2个zk节点 4.启动第3个zk节点 4.访问节点 1.进入zk第一个节点的docker容器内部 2.使用zk的客户端进行访问 3.在zk中使用命令 0.前言 之前在学springcloud的时候,提到有些项目还是使用zookeeper作为注册中心. 因此决定掌握这个技能,但是本地为了测试而部署一套zookeeper集群还是比较麻烦的. 所以打算使用
-
Zookeeper 单机环境和集群环境搭建
一.单机环境搭建# 1.1 下载# 下载对应版本 Zookeeper,这里我下载的版本 3.4.14.官方下载地址:https://archive.apache.org/dist/zookeeper/ # wget https://archive.apache.org/dist/zookeeper/zookeeper-3.4.14/zookeeper-3.4.14.tar.gz 1.2 解压# # tar -zxvf zookeeper-3.4.14.tar.gz 1.3 配置环境变量# #
-
Docker下安装zookeeper(单机和集群)
启动Docker后,先看一下我们有哪些选择. 有官方的当然选择官方啦~ 下载: [root@localhost admin]# docker pull zookeeper Using default tag: latest Trying to pull repository docker.io/library/zookeeper ... latest: Pulling from docker.io/library/zookeeper 1ab2bdfe9778: Already exists 7a
-
Docker搭建Zookeeper&Kafka集群的实现
最近在学习Kafka,准备测试集群状态的时候感觉无论是开三台虚拟机或者在一台虚拟机开辟三个不同的端口号都太麻烦了(嗯..主要是懒). 环境准备 一台可以上网且有CentOS7虚拟机的电脑 为什么使用虚拟机?因为使用的笔记本,所以每次连接网络IP都会改变,还要总是修改配置文件的,过于繁琐,不方便测试.(通过Docker虚拟网络的方式可以避免此问题,当时实验的时候没有了解到) Docker 安装 如果已经安装Docker请忽略此步骤 Docker支持以下的CentOS版本: CentOS 7 (64
-
基于 ZooKeeper 搭建 Hadoop 高可用集群 的教程图解
一.高可用简介 Hadoop 高可用 (High Availability) 分为 HDFS 高可用和 YARN 高可用,两者的实现基本类似,但 HDFS NameNode 对数据存储及其一致性的要求比 YARN ResourceManger 高得多,所以它的实现也更加复杂,故下面先进行讲解: 1.1 高可用整体架构 HDFS 高可用架构如下: 图片引用自: https://www.edureka.co/blog/how-to-set-up-hadoop-cluster-with-hdfs-hi
-
Linux下ZooKeeper分布式集群安装教程
ZooKeeper 就是动物园管理员的意思,它是用来管理 Hadoop(大象).Hive(蜜蜂).pig(小猪)的管理员,Apache Hbase.Apache Solr.Dubbo 都用到了 ZooKeeper,其实就是一个集群管理工具,是集群的入口.ZooKeeper 是一个分布式的.开源的程序协调服务,是 Hadoop 项目下的一个子项目.ZooKeeper 主要应用场景包括集群管理(主从管理.负载均衡.高可用的管理).配置文件的集中管理.分布式锁.注册中心等.实际项目中,为了保证高可用,
-

ZooKeeper集群操作及集群Master选举搭建启动
目录 ZooKeeper介绍 ZooKeeper特征 分层命名空间 搭建ZK集群 启动zk集群 zk集群master选举 ZooKeeper介绍 ZooKeeper 是一个为 分布式应用 提供的 分布式 .开源的 协调服务 . 它公开了一组简单的 原语 ,分布式应用程序可以根据这些原语来实现用于 同步 .配置维护 以及 命名 的更高级别的服务. 怎么理解协调服务呢?比如我们有很多应用程序,他们之间都需要读写维护一个 id ,那么这些 id 怎么命名呢,程序一多,必然会乱套,ZooKeeper 能
-
java连接ElasticSearch集群操作
我就废话不多说了,大家还是直接看代码吧~ /* *es配置类 * */ @Configuration public class ElasticSearchDataSourceConfigurer { private static final Logger LOG = LogManager.getLogger(ElasticSearchDataSourceConfigurer.class); @Bean public TransportClient getESClient() { //设置集群名称
-
使用docker搭建kong集群操作
docker容器下搭建kong的集群很简单,官网介绍的也很简单,初学者也许往往不知道如何去处理,经过本人的呕心沥血的琢磨,终于搭建出来了. 主要思想:不同的kong连接同一个数据库(就这么一句话) 难点:如何在不同的主机上用kong连接同一数据库 要求: 1.两台主机 172.16.100.101 172.16.100.102 步骤: 1.在101上安装数据库(这里就用cassandra) docker run -d --name kong-database \ -p 9042:9042 \ c
-
Docker搭建RabbitMq的普通集群和镜像集群的详细操作
目录 一.搭建RabbitMq的运行环境 1.通过search查询rabbitmq镜像 2.通过pull拉取rabbitmq的官方最新镜像 3.创建容器 4.启动管理页面 5.设置erlang cookie 二.普通模式 三.镜像模式 普通集群:多个节点组成的普通集群,消息随机发送到其中一个节点的队列上,其他节点仅保留元数据,各个节点仅有相同的元数据,即队列结构.交换器结构.vhost等.消费者消费消息时,会从各个节点拉取消息,如果保存消息的节点故障,则无法消费消息,如果做了消息持久化,那么得等
-
关于docker compose安装redis集群的问题(集群扩容、集群收缩)
目录 一.redis 配置信息模板 二.编写批量生成配置文件脚本 三.批量生成配置文件 四.编写 docker-compose 文件 五.做集群.分配插槽 六.测试: 七.手动扩容 八.添加主从节点 1.添加主节点 2.添加从节点 九.分配插槽 十.集群测试 十一.常用命令 一.redis 配置信息模板 文件名:redis-cluster.tmpl # redis端口 port ${PORT} #redis 访问密码 requirepass 123456 #redis 访问Master节点密码
-
详解MongoDB中用sharding将副本集分配至服务器集群的方法
关于副本集 副本集是一种在多台机器同步数据的进程. 副本集体提供了数据冗余,扩展了数据可用性.在多台服务器保存数据可以避免因为一台服务器导致的数据丢失. 也可以从硬件故障或服务中断解脱出来,利用额外的数据副本,可以从一台机器致力于灾难恢复或者备份. 在一些场景,可以使用副本集来扩展读性能.客户端有能力发送读写操作给不同的服务器. 也可以在不同的数据中心获取不同的副本来扩展分布式应用的能力. mongodb副本集是一组拥有相同数据的mongodb实例,主mongodb接受所有的写操作,所有的其他实
-
Oracle 数据库操作技巧集
正在看的ORACLE教程是:Oracle 数据库操作技巧集.[编者注:]提起数据库,第一个想到的公司,一般都会是Oracle(即甲骨文公司).Oracle在数据库领域一直处于领先地位.Oracle关系数据库系统是目前世界上流行的关系数据库管理系统,系统可移植性好.使用方便.功能强,适用于各类大.中.小.微机环境.Oracle9i是Oracle于今年6月份正式推出的数据库最新产品.Oracle9i在可伸缩性.可靠性和完整性方面有着上佳的表现,一推出就获得了开发者的认同.它是一种高效率.可靠性好的适
-
jQuery 第二课 操作包装集元素代码
例如: 复制代码 代码如下: <html xmlns="http://www.w3.org/1999/xhtml"> <head> <title>jQuery Wrapper</title> <script type="text/javascript" src="jquery-1.3.2.js"></script> <script type="text/jav
-
详解Matlab中自带的Java操作合集
目录 1 获取鼠标在全屏位置 2 获取当前剪切板内容 3 内容复制到剪切板 4 获取鼠标处像素颜色 5 获取屏幕截图 6 创建java窗口(并使其永远在最上方) 7 透明窗口 1 获取鼠标在全屏位置 屏幕左上角为坐标原点,获取鼠标位置和获取鼠标像素颜色建议和while循环或者timer函数结合使用: import java.awt.MouseInfo; mousepoint=MouseInfo.getPointerInfo().getLocation(); mousepoint=[mousepo
-
Python实现简单的文件操作合集
目录 一.文件操作 1.打开 2.关闭 3.写入 4.读取 二:python中自动开启关闭资源 一.文件操作 1.打开 r+ 打开存在文件 文件不存在 报错 file = open("user.txt","r+") print(file,type(file)) w+ 若是文件不存在 会创建文件 file = open("user.txt","w+") print(file,type(file)) 2.关闭 file.close