Node.js完整实现博客系统详解
目录
- 一、项目功能说明
- 二、最终效果
- 三、文件目录结构说明
- 四、项目技术栈
- 五、核心技术
- 1. 使用Schema定义数据模型
- 2. mongoose 的操作
- 3. mogodb数据库的操作
- 4. 使用第三方插件 express-session:存取数据状态
- 5. 挂载路由
- 6. 使用md5对密码进行加密
- 六、遇到的问题
- 七、github链接
一、项目功能说明
- 登录、注册
- 新建博客
- 首页显示全部博客
- 查看博客详情页
- 查看博客评论区
- 修改、删除博客
二、最终效果
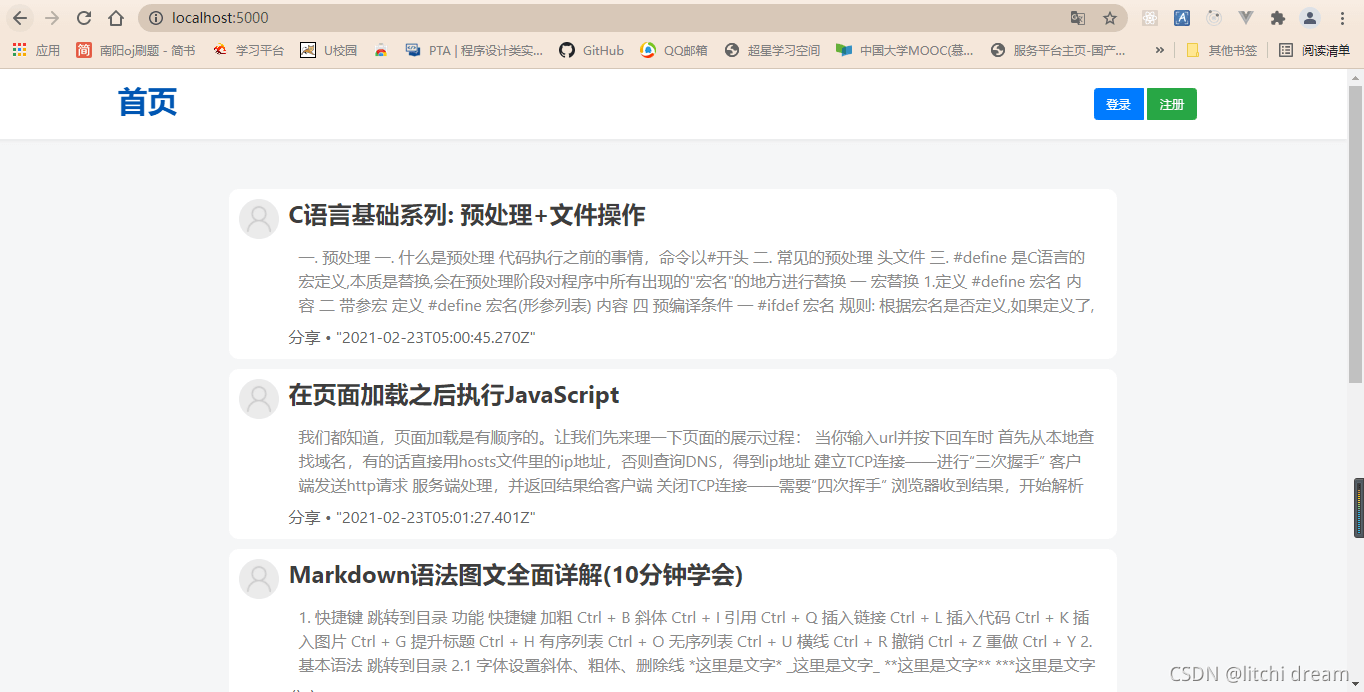
首页:
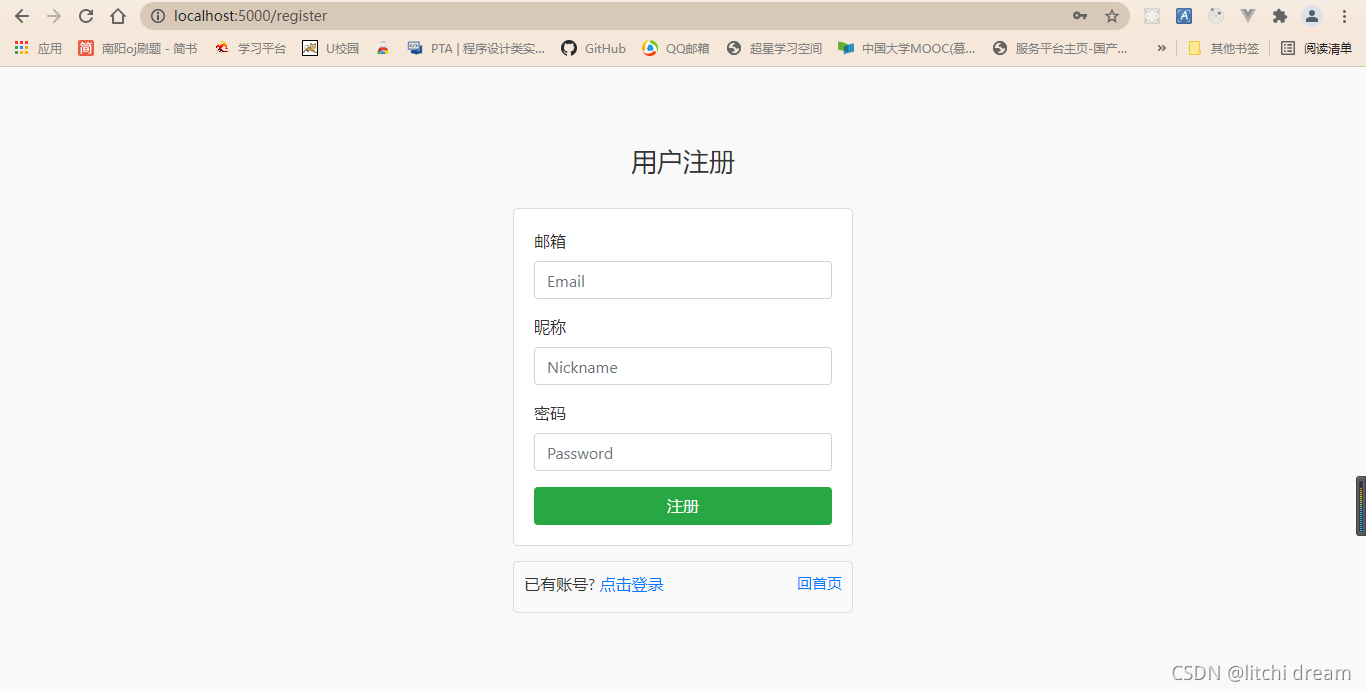
登录、注册:

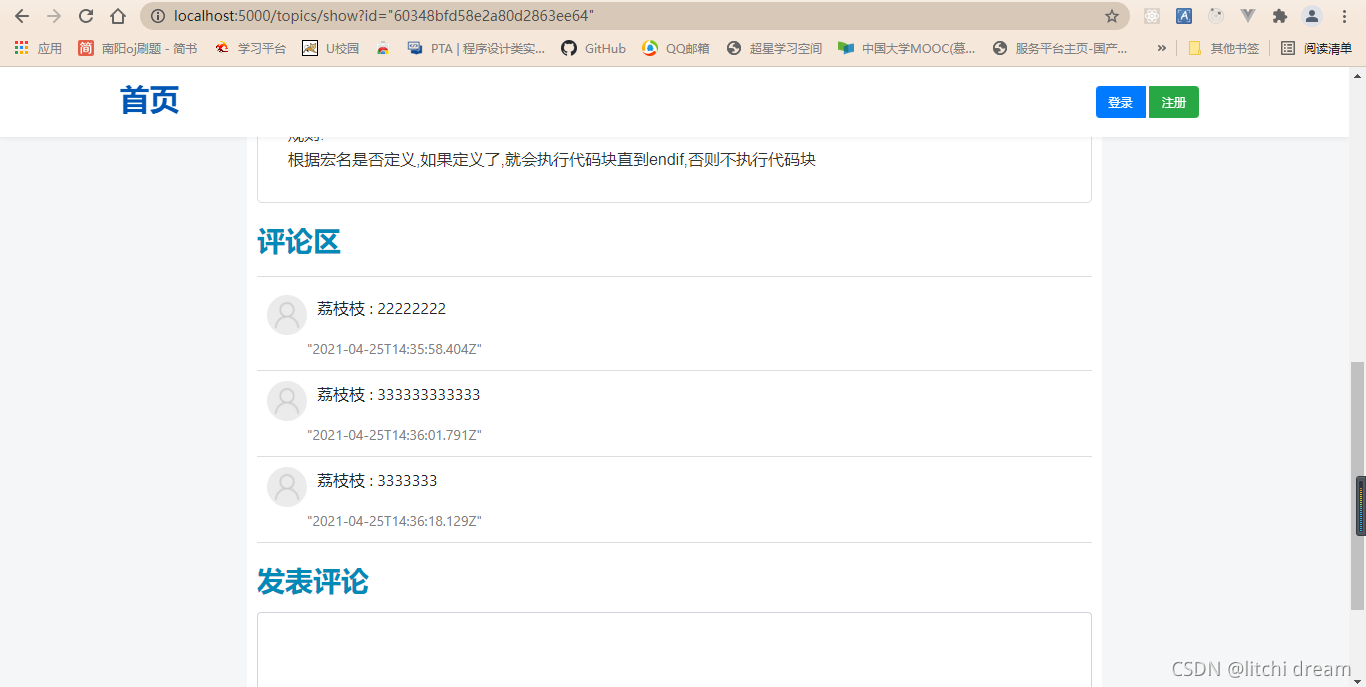
详情页:

评论区:
新建博客:

登陆后的Banner:

用户设置->基本信息:
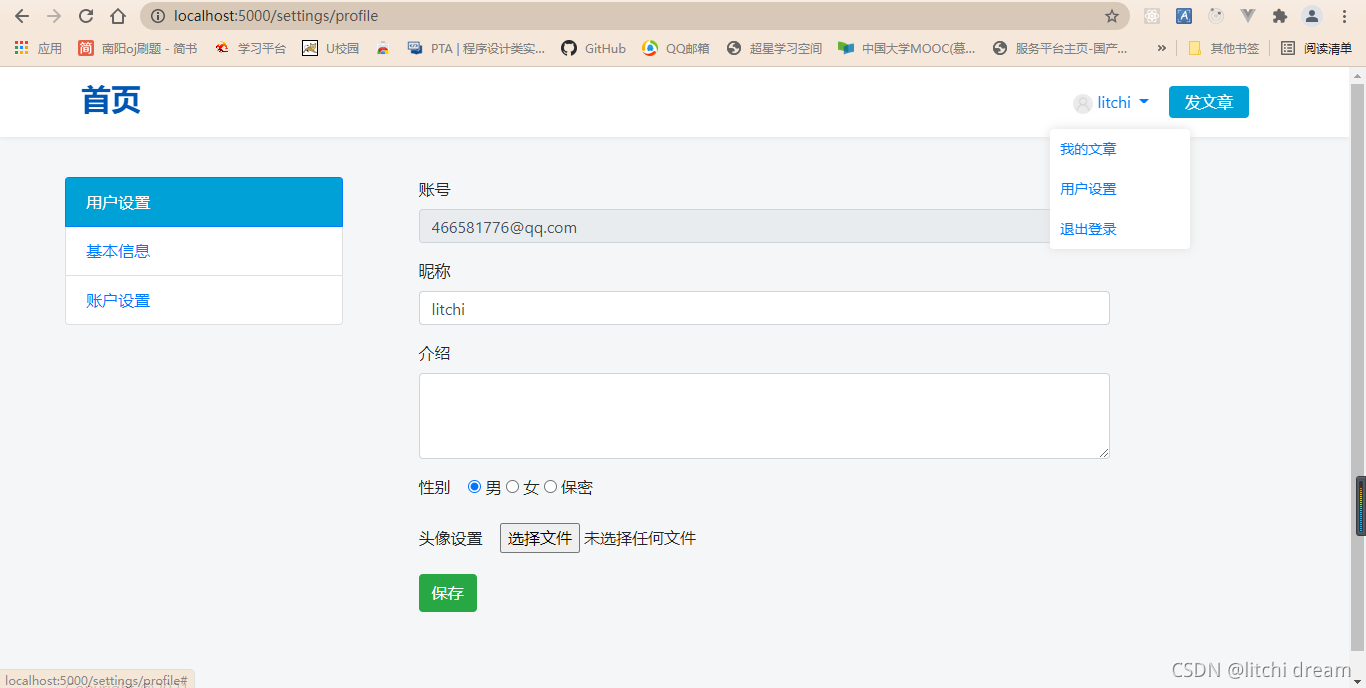
用户设置->账户设置:

三、文件目录结构说明
- modules:包含需要建多个的Schema
- public:包含公共的Css、Js、Image
- views:按照不同功能、板块创建文件夹,并在对应文件夹下创建html文件
- app.js:配置解析表单POST请求体数据、存取数据状态、使用模板引擎、挂载路由
- router.js:路由配置
四、项目技术栈
- express 框架
- bootstrap 作为UI框架
- mongodb 数据库
- art-template 模板引擎
- jquery + ajax 发送网络请求
- 使用 express-session 存取数据状态,通过req.session来访问和设置session成员
- mongoose 使用了一种直接的、基于scheme结构的方式定义数据模型
五、核心技术
1. 使用Schema定义数据模型
例如:定义评论的 Schema模型
var commentSchema = new Schema({
articleId:{
type:String,
required:true
},
nickname:{
type:String,
required:true
},
comments:{
type:String,
required:true
},
created_time:{
type:Date,
default:Date.now
}
})
2. mongoose 的操作
连接mongodb数据库:mongoose.connect('mongodb://localhost/user',{ useNewUrlParser: true ,useUnifiedTopology: true})
导出 Schema模型:module.exports = mongoose.model('Comment',commentSchema)
3. mogodb数据库的操作
查找:Topic.find(function(err,topics){ ... })
查找一个:User.findOne({ },function(err,data){})
保存信息:Topic(req.body).save(function(err,data){})
查找一个并更新:User.findOneAndUpdate({查找条件},{要修改的信息},function(err,data){})
删除:User.remove({查找条件},function(err,data){})
4. 使用第三方插件 express-session:存取数据状态
session 的配置
// 使用第三方插件 express-session:存取数据状态
// 1.npm install express-session
// 2.配置,一定要在路由之前
// 3.使用
// 当把这个插件配置好之后,我们就可以通过req.session来访问和设置session成员了
// 添加session数据:req.session.foo = 'bar
// 访问session数据:req.session.foo
var session = require('express-session')
app.use(session({
// 配置加密字符串,他会在原有加密基础上和这个字符串拼起来去加密
// 目的是为了增加安全性,防止客户端恶意伪造
secret: 'itcast',
resave: false,
saveUninitialized: false
}))
通过session 读取状态:
// 用户存在,登录成功,记录登录状态
req.session.user = user
res.status(200).json({
err_code:0,
message:'OK'
})
清除 session:
// 清楚登录状态
// 重定向到登录页,<a>链接是同步请求,所以可以服务端重定向
req.session.user = null
res.redirect('/')
5. 挂载路由
创建路由:var router = express.Router(),并在路由上通过router.get()、router.post()方法添加请求,最后导出 router
6. 使用md5对密码进行加密
通过md5对密码加密,这样数据库也无法读取到正确的密码
六、遇到的问题
- 没有很好的对时间进行格式化
- 未实现搜索文章功能
七、github链接
到此这篇关于Node.js完整实现博客系统详解的文章就介绍到这了,更多相关Node.js博客系统内容请搜索我们以前的文章或继续浏览下面的相关文章希望大家以后多多支持我们!
相关推荐
-

Node.js+jade抓取博客所有文章生成静态html文件的实例
这篇文章,我们就把上文中采集到的所有文章列表的信息整理一下,开始采集文章并且生成静态html文件了.先看下我的采集效果,我的博客目前77篇文章,1分钟不到就全部采集生成完毕了,这里我截了部分的图片,文件名用文章的id生成的,生成的文章,我写了一个简单的静态模板,所有的文章都是根据这个模板生成的. 项目结构: 好了,接下来,我们就来讲解下,这篇文章主要实现的功能: 1,抓取文章,主要抓取文章的标题,内容,超链接,文章id(用于生成静态html文件) 2,根据jade模板生成html文件 一.抓取文
-
基于Node.js搭建hexo博客过程详解
一.安装新版本的nodejs和npm 安装n模块: npm install -g n 升级node.js到最新稳定版 n stable 二.安装hexo note: 参考github,不要去其官网 安装Hexo npm install hexo-cli -g Setup your blog hexo init blemesh cd blemesh 安装Cactus主题,众多开源主题中比较简洁的一个: 主题页 Cactus页 git clone https://github.com/probber
-
node.js博客项目开发手记
需要安装的模块 body-parser 解析post请求 cookies 读写cookie express 搭建服务器 markdown Markdown语法解析生成器 mongoose 操作Mongodb数据库 swig 模板解析引擎 目录结构 db 数据库存储目录 models 数据库模型文件目录 public 公共文件目录(css,js,img) routers 路由文件目录 schemas 数据库结构文件 views 模板视图文件目录 app.js 启动文件 package.json a
-
利用Vue.js+Node.js+MongoDB实现一个博客系统(附源码)
前言 这篇文章实现的博客系统使用 Vue 做前端框架,Node + express 做后端,数据库使用的是 MongoDB.实现了用户注册.用户登录.博客管理(文章的修改和删除).文章编辑(Markdown).标签分类等功能. 前端模仿的是 hexo 的经典主题 NexT,本来是想把源码直接拿过来用的,后来发现还不如自己写来得快,就全部自己动手实现成 vue components. 实现的功能 1.文章的编辑,修改,删除 2.支持使用 Markdown 编辑与实时预览 3.支持代码高亮 4.给文
-
node.js实现博客小爬虫的实例代码
前言 爬虫,是一种自动获取网页内容的程序.是搜索引擎的重要组成部分,因此搜索引擎优化很大程度上就是针对爬虫而做出的优化. 这篇文章介绍的是利用node.js实现博客小爬虫,核心的注释我都标注好了,可以自行理解,只需修改url和按照要趴的博客内部dom构造改一下filterchapters和filterchapters1就行了! 下面话不多说,直接来看实例代码 var http=require('http'); var Promise=require('Bluebird'); var cheeri
-
Node.js完整实现博客系统详解
目录 一.项目功能说明 二.最终效果 三.文件目录结构说明 四.项目技术栈 五.核心技术 1. 使用Schema定义数据模型 2. mongoose 的操作 3. mogodb数据库的操作 4. 使用第三方插件 express-session:存取数据状态 5. 挂载路由 6. 使用md5对密码进行加密 六.遇到的问题 七.github链接 一.项目功能说明 登录.注册 新建博客 首页显示全部博客 查看博客详情页 查看博客评论区 修改.删除博客 二.最终效果 首页: 登录.注册: 详情页: 评论
-
Javaweb实现完整个人博客系统流程
目录 一.项目背景 二.项目功能 三.项目的基本流程 1.准备工作 2.数据库设计 3.准备前端页面 4.实现前端匹配的Servlet所需功能 5.项目难点 一.项目背景 在学习完JavaWeb相关知识后,有了基础能力就想通过完成一个Javaweb项目来回顾和加强已经学过的知识,并且希望在这个过程中发现自己的不足并加以改正.由于之前一直都在CSDN上分享自己的学习过程,对CSDN博客系统的功能有了一定的了解,因此便尝试完成了个人博客系统. 二.项目功能 1.用户登录: 2.用户主页: 3.查看全
-
Node.js 应用探索文件解压缩示例详解
目录 引言 compressing 解压 压缩 archiver adm-zip 压缩 解压缩 总结 引言 今天在使用 node 脚本对文件处理时,需要实现一个功能,要对一个 zip 压缩包解压出来,修改里面的文件后,重新打包成zip包.node 解压缩文件的场景在实际应用中还是比较常见,下面介绍几个用来解压缩文件的库和使用方法. compressing compressing 是一个使用起来方便.功能非常强大的node库,它可以对文件.文件夹进行解压或压缩,支持tar.gzip.tgz.zip
-
Node.js 条形码识别程序构建思路详解
在这篇文章中,我们将展示一个非常简单的方法构建一个自定义的 Node 模块,该模块封装了Dynamsoft Barcode Reader SDK ,支持 Windows.Linux 和 OS X,同时我们将演示如何集成这块模块实现一个在线的条形码读取应用. 越来越多的 Web 开发者选择 Node 来构建网站,因为使用 JavaScript 来开发复杂的服务器端 Web 应用越来越便利.为了扩展在不同平台下的 Node 的功能,Node 允许开发者使用 C/C++ 来创建扩展. 介绍 Dynam
-
Node.Js中实现端口重用原理详解
本文介绍了Node.Js中实现端口重用原理详解,分享给大家,具体如下: 起源,从官方实例中看多进程共用端口 const cluster = require('cluster'); const http = require('http'); const numCPUs = require('os').cpus().length; if (cluster.isMaster) { console.log(`Master ${process.pid} is running`); for (let i =
-
Node.js中路径处理模块path详解
前言 在node.js中,提供了一个path某块,在这个模块中,提供了许多使用的,可被用来处理与转换路径的方法与属性,将path的接口按照用途归类,仔细琢磨琢磨,也就没那么费解了.下面我们就来详细介绍下关于Node.js中的路径处理模块path. 获取路径/文件名/扩展名 获取路径:path.dirname(filepath) 获取文件名:path.basename(filepath) 获取扩展名:path.extname(filepath) 获取所在路径 例子如下: var path = re
-
利用Node.js编写跨平台的spawn语句详解
前言 Node.js 是跨平台的,也就是说它能运行在 Windows.OSX 和 Linux 平台上.很多 Node.js 开发者都是在 OSX 上做开发的,然后再将代码部署到 Linux 服务器上.由于 OSX 和 Linux 都是基于 Unix 的,因此两者共性很多.Windows 也是 Node.js 官方支持的平台,只要你通过正确的方式写代码,就能在各个平台上毫无压力的跑起来. Node.js 的子进程 (child_process) 模块下有一 spawn 函数,可以用于调用系统上的命
-
node.js学习之交互式解释器REPL详解
简介 repl是Node.js提供的一个Read-Eval-Print-Loop (REPL,读取-执行-输出-循环)实现,它即可以做为一个独立的程序使用,又可以包含在其它应用中使用.REPL是一个互式命令行解析器,它提供了一个交互式的编程环境,它可以实时的验证你所编写的代码,非常适合于验证Node.js和JavaScript的相关API. Node 自带了交互式解释器,可以执行以下任务: 读取 - 读取用户输入,解析输入了Javascript 数据结构并存储在内存中. 执行 - 执行输入的数据
-
Node.js之readline模块的使用详解
什么是readline readline允许从可读流中以逐行的方式读取数据,比如process.stdin等. 在node.js命令行模式下默认引入了readline模块,但如果是使用node.js运行脚本的话,则需要自己通过require('readline')方式手动引入该模块. 怎么使用readline 创建实例 首先.创建一个接口实例,提供一个Object类型的参数.参数如下: input: 监听的可读流(必需) output: 写入readline的可写流(必需) completer: