Java源码刨析之ArrayDeque
目录
- 前言
- 双端队列整体分析
- 数组实现ArrayDeque(双端队列)的原理
- 底层数据遍历顺序和逻辑顺序
- ArrayDeque类关键字段分析
- ArrayDeque构造函数分析
- ArrayDeque关键函数分析
- addLast函数分析
- addFirst函数分析
- doubleCapacity函数分析
- pollLast和pollFirst函数分析
- 总结
前言
在本篇文章当中主要跟大家介绍JDK给我们提供的一种用数组实现的双端队列,在之前的文章LinkedList源码剖析当中我们已经介绍了一种双端队列,不过与ArrayDeque不同的是,LinkedList的双端队列使用双向链表实现的。
双端队列整体分析
我们通常所谈论到的队列都是一端进一端出,而双端队列的两端则都是可进可出。下面是双端队列的几个操作:
数据从双端队列左侧进入。

数据从双端队列右侧进入。

数据从双端队列左侧弹出。

数据从双端队列右侧弹出。
而在ArrayDeque当中也给我们提供了对应的方法去实现,比如下面这个例子就是上图对应的代码操作:
public void test() {
ArrayDeque<Integer> deque = new ArrayDeque<>();
deque.addLast(100);
System.out.println(deque);
deque.addFirst(55);
System.out.println(deque);
deque.addLast(-55);
System.out.println(deque);
deque.removeFirst();
System.out.println(deque);
deque.removeLast();
System.out.println(deque);
}
// 输出结果
[100]
[55, 100]
[55, 100, -55]
[100, -55]
[100]
数组实现ArrayDeque(双端队列)的原理
ArrayDeque底层是使用数组实现的,而且数组的长度必须是2的整数次幂,这么操作的原因是为了后面位运算好操作。在ArrayDeque当中有两个整形变量head和tail,分别指向右侧的第一个进入队列的数据和左侧第一个进行队列的数据,整个内存布局如下图所示:

其中tail指的位置没有数据,head指的位置存在数据。
当我们需要从左往右增加数据时(入队),内存当中数据变化情况如下:

当我们需要从右往做左增加数据时(入队),内存当中数据变化情况如下:

当我们需要从右往左删除数据时(出队),内存当中数据变化情况如下:

当我们需要从左往右删除数据时(出队),内存当中数据变化情况如下:

底层数据遍历顺序和逻辑顺序
上面主要谈论到的数组在内存当中的布局,但是他是具体的物理存储数据的顺序,这个顺序和我们的逻辑上的顺序是不一样的,根据上面的插入顺序,我们可以画出下面的图,大家可以仔细分析一下这个图的顺序问题。

上图当中队列左侧的如队顺序是0, 1, 2, 3,右侧入队的顺序为15, 14, 13, 12, 11, 10, 9, 8,因此在逻辑上我们的队列当中的数据布局如下图所示:

根据前面一小节谈到的输入在入队的时候数组当中数据的变化我们可以知道,数据在数组当中的布局为:

ArrayDeque类关键字段分析
// 底层用于存储具体数据的数组 transient Object[] elements; // 这就是前面谈到的 head transient int head; // 与上文谈到的 tail 含义一样 transient int tail; // MIN_INITIAL_CAPACITY 表示数组 elements 的最短长度 private static final int MIN_INITIAL_CAPACITY = 8;
以上就是ArrayDeque当中的最主要的字段,其含义还是比较容易理解的!
ArrayDeque构造函数分析
默认构造函数,数组默认申请的长度为16。
public ArrayDeque() {
elements = new Object[16];
}
指定数组长度的初始化长度,下面列出了改构造函数涉及的所有函数。
public ArrayDeque(int numElements) {
allocateElements(numElements);
}
private void allocateElements(int numElements) {
elements = new Object[calculateSize(numElements)];
}
private static int calculateSize(int numElements) {
int initialCapacity = MIN_INITIAL_CAPACITY;
// Find the best power of two to hold elements.
// Tests "<=" because arrays aren't kept full.
if (numElements >= initialCapacity) {
initialCapacity = numElements;
initialCapacity |= (initialCapacity >>> 1);
initialCapacity |= (initialCapacity >>> 2);
initialCapacity |= (initialCapacity >>> 4);
initialCapacity |= (initialCapacity >>> 8);
initialCapacity |= (initialCapacity >>> 16);
initialCapacity++;
if (initialCapacity < 0) // Too many elements, must back off
initialCapacity >>>= 1;// Good luck allocating 2 ^ 30 elements
}
return initialCapacity;
}
上面的最难理解的就是函数calculateSize了,他的主要作用是如果用户输入的长度小于MIN_INITIAL_CAPACITY时,返回MIN_INITIAL_CAPACITY。否则返回比initialCapacity大的第一个是2的整数幂的整数,比如说如果输入的是9返回的16,输入4返回8。
calculateSize的代码还是很难理解的,让我们一点一点的来分析。首先我们使用一个2的整数次幂的数进行上面移位操作的操作!


从上图当中我们会发现,我们在一个数的二进制数的32位放一个1,经过移位之后最终32位的比特数字全部变成了1。根据上面数字变化的规律我们可以发现,任何一个比特经过上面移位的变化,这个比特后面的31个比特位都会变成1,像下图那样:

因此上述的移位操作的结果只取决于最高一位的比特值为1,移位操作后它后面的所有比特位的值全为1,而在上面函数的最后,我们返回的结果就是上面移位之后的结果 +1。又因为移位之后最高位的1到最低位的1之间的比特值全为1,当我们+1之后他会不断的进位,最终只有一个比特位置是1,因此它是2的整数倍。

经过上述过程分析,我们就可以立即函数calculateSize了。
ArrayDeque关键函数分析
addLast函数分析
// tail 的初始值为 0
public void addLast(E e) {
if (e == null)
throw new NullPointerException();
elements[tail] = e;
// 这里进行的 & 位运算 相当于取余数操作
// (tail + 1) & (elements.length - 1) == (tail + 1) % elements.length
// 这个操作主要是用于判断数组是否满了,如果满了则需要扩容
// 同时这个操作将 tail + 1,即 tail = tail + 1
if ( (tail = (tail + 1) & (elements.length - 1)) == head)
doubleCapacity();
}
代码(tail + 1) & (elements.length - 1) == (tail + 1) % elements.length成立的原因是任意一个数 a a a对 2 n 2^n 2n进行取余数操作和 a a a跟 2 n − 1 2^n - 1 2n−1进行&运算的结果相等,即:
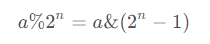
从上面的代码来看下标为tail的位置是没有数据的,是一个空位置。
addFirst函数分析
// head 的初始值为 0
public void addFirst(E e) {
if (e == null)
throw new NullPointerException();
// 若此时数组长度elements.length = 16
// 那么下面代码执行过后 head = 15
// 下面代码的操作结果和下面两行代码含义一致
// elements[(head - 1 + elements.length) % elements.length] = e
// head = (head - 1 + elements.length) % elements.length
elements[head = (head - 1) & (elements.length - 1)] = e;
if (head == tail)
doubleCapacity();
}
上面代码操作结果和上文当中我们提到的,在队列当中从右向左加入数据一样。从上面的代码看,我们可以发现下标为head的位置是存在数据的。
doubleCapacity函数分析
private void doubleCapacity() {
assert head == tail;
int p = head;
int n = elements.length;
int r = n - p; // number of elements to the right of p
int newCapacity = n << 1;
if (newCapacity < 0)
throw new IllegalStateException("Sorry, deque too big");
Object[] a = new Object[newCapacity];
// arraycopy(Object src, int srcPos,
Object dest, int destPos,
int length)
// 上面是函数 System.arraycopy 的函数参数列表
// 大家可以参考上面理解下面的拷贝代码
System.arraycopy(elements, p, a, 0, r);
System.arraycopy(elements, 0, a, r, p);
elements = a;
head = 0;
tail = n;
}
上面的代码还是比较简单的,这里给大家一个图示,大家就更加容易理解了:

扩容之后将原来数组的数据拷贝到了新数组当中,虽然数据在旧数组和新数组当中的顺序发生变化了,但是他们的相对顺序却没有发生变化,他们的逻辑顺序也是一样的,这里的逻辑可能有点绕,大家在这里可以好好思考一下。
pollLast和pollFirst函数分析
这两个函数的代码就比较简单了,大家可以根据前文所谈到的内容和图示去理解下面的代码。
public E pollLast() {
// 计算出待删除的数据的下标
int t = (tail - 1) & (elements.length - 1);
@SuppressWarnings("unchecked")
E result = (E) elements[t];
if (result == null)
return null;
// 将需要删除的数据的下标值设置为 null 这样这块内存就
// 可以被回收了
elements[t] = null;
tail = t;
return result;
}
public E pollFirst() {
int h = head;
@SuppressWarnings("unchecked")
E result = (E) elements[h];
// Element is null if deque empty
if (result == null)
return null;
elements[h] = null; // Must null out slot
head = (h + 1) & (elements.length - 1);
return result;
}
总结
在本篇文章当中,主要跟大家分享了ArrayDeque的设计原理,和他的底层实现过程。ArrayDeque底层数组当中的数据顺序和队列的逻辑顺序这部分可能比较抽象,大家可以根据图示好好体会一下!!!
到此这篇关于Java源码刨析之ArrayDeque的文章就介绍到这了,更多相关Java ArrayDeque内容请搜索我们以前的文章或继续浏览下面的相关文章希望大家以后多多支持我们!
相关推荐
-

java集合 ArrayDeque源码详细分析
问题 (1)什么是双端队列? (2)ArrayDeque是怎么实现双端队列的? (3)ArrayDeque是线程安全的吗? (4)ArrayDeque是有界的吗? 简介 双端队列是一种特殊的队列,它的两端都可以进出元素,故而得名双端队列. ArrayDeque是一种以数组方式实现的双端队列,它是非线程安全的. 继承体系 通过继承体系可以看,ArrayDeque实现了Deque接口,Deque接口继承自Queue接口,它是对Queue的一种增强. public interface Deque<E>
-
Java容器类源码详解 Deque与ArrayDeque
前言 Queue 也是 Java 集合框架中定义的一种接口,直接继承自 Collection 接口.除了基本的 Collection 接口规定测操作外,Queue 接口还定义一组针对队列的特殊操作.通常来说,Queue 是按照先进先出(FIFO)的方式来管理其中的元素的,但是优先队列是一个例外. Deque 接口继承自 Queue接口,但 Deque 支持同时从两端添加或移除元素,因此又被成为双端队列.鉴于此,Deque 接口的实现可以被当作 FIFO队列使用,也可以当作LIFO队列(栈)来使用
-
Java ArrayDeque实现Stack的功能
在J2SE6引入了ArrayDeque类,它继承了Deque(双向队列)接口,使用此类可以自己实现java.util.Stack类的功能,去掉了java.util.Stack的多线程同步的功能. 例如创建一个存放Integer类型的Stack,只要在类中创建一个ArrayDeque类的变量作为属性,之后定义的出栈.入栈,观察栈顶元素的操作就直接操作ArrayDeque的实例变量即可. import java.util.ArrayDeque; import java.util.Deque; pub
-
java.util.ArrayDeque类使用方法详解
本文为大家介绍了java.util.ArrayDeque类使用方法,供大家参考,具体内容如下 1. ArrayDeque有两个类属性,head和tail,两个指针. 2. ArrayDeque通过一个数组作为载体,其中的数组元素在add等方法执行时不移动,发生变化的只是head和tail指针,而且指针是循环变化,数组容量不限制. 3. offer方法和add方法都是通过其中的addLast方法实现,每添加一个元素,就把元素加到数组的尾部,此时,head指针没有变化,而tail指针加一,因为指针是
-
Java ArrayDeque使用方法详解
题目要求为: 卡拉兹(Callatz)猜想: 对任何一个自然数n,如果它是偶数,那么把它砍掉一半:如果它是奇数,那么把(3n+1)砍掉一半.这样一直反复砍下去,最后一定在某一步得到n=1.当我们验证卡拉兹猜想的时候,为了避免重复计算,可以记录下递推过程中遇到的每一个数.例如对n=3进行验证的时候,我们需要计算3.5.8.4.2.1,则当我们对n=5.8.4.2进行验证的时候,就可以直接判定卡拉兹猜想的真伪,而不需要重复计算,因为这4个数已经在验证3的时候遇到过了,我们称5.8.4.2是被3"覆盖
-
Java集合ArrayDeque类实例分析
Java集合ArrayDeque类实例分析 前言 ArrayDeque类是双端队列的实现类,类的继承结构如下面,继承自AbastractCollection(该类实习了部分集合通用的方法,其实现了Collection接口),其实现的接口Deque接口中定义了双端队列的主要的方法,比如从头删除,从尾部删除,获取头数据,获取尾部数据等等. public class ArrayDeque<E> extends AbstractCollection<E> implements Deque&
-
Java源码刨析之ArrayDeque
目录 前言 双端队列整体分析 数组实现ArrayDeque(双端队列)的原理 底层数据遍历顺序和逻辑顺序 ArrayDeque类关键字段分析 ArrayDeque构造函数分析 ArrayDeque关键函数分析 addLast函数分析 addFirst函数分析 doubleCapacity函数分析 pollLast和pollFirst函数分析 总结 前言 在本篇文章当中主要跟大家介绍JDK给我们提供的一种用数组实现的双端队列,在之前的文章LinkedList源码剖析当中我们已经介绍了一种双端队列,
-
Java源码刨析之ArrayQueue
目录 ArrayQueue内部实现 ArrayQueue源码剖析 总结 ArrayQueue内部实现 在谈ArrayQueue的内部实现之前我们先来看一个ArrayQueue的使用例子: public void testQueue() { ArrayQueue<Integer> queue = new ArrayQueue<>(10); queue.add(1); queue.add(2); queue.add(3); queue.add(4); System.out.printl
-
Vue收集依赖与触发依赖源码刨析
目录 定义依赖 收集依赖 触发依赖 总结 定义依赖 定义依赖是什么时候开始的呢?通过源码可以发现在执行_init函数的时候会执行initState(vm)方法: function initState(vm) { ... if (opts.data) { initData(vm); } else { var ob = observe((vm._data = {})); ob && ob.vmCount++; } ... } 先触发initData方法: function initData(v
-
关于Redis网络模型的源码详析
前言 Redis的网络模型是基于I/O多路复用程序来实现的.源码中包含四种多路复用函数库epoll.select.evport.kqueue.在程序编译时会根据系统自动选择这四种库其中之一.下面以epoll为例,来分析Redis的I/O模块的源码. epoll系统调用方法 Redis网络事件处理模块的代码都是围绕epoll那三个系统方法来写的.先把这三个方法弄清楚,后面就不难了. epfd = epoll_create(1024); 创建epoll实例 参数:表示该 epoll 实例最多可监听的
-
Java源码解析之TypeVariable详解
TypeVariable,类型变量,描述类型,表示泛指任意或相关一类类型,也可以说狭义上的泛型(泛指某一类类型),一般用大写字母作为变量,比如K.V.E等. 源码 public interface TypeVariable<D extends GenericDeclaration> extends Type { //获得泛型的上限,若未明确声明上边界则默认为Object Type[] getBounds(); //获取声明该类型变量实体(即获得类.方法或构造器名) D getGenericDe
-
Java源码解析之GenericDeclaration详解
学习别人实现某个功能的设计思路,来提高自己的编程水平.话不多说,下面进入正题. GenericDeclaration 可以声明类型变量的实体的公共接口,也就是说,只有实现了该接口才能在对应的实体上声明(定义)类型变量,这些实体目前只有三个:Class(类).Construstor(构造器).Method(方法)(详见:Java源码解析之TypeVariable详解 源码 public interface GenericDeclaration { //获得声明列表上的类型变量数组 public T
-
Java源码解析之object类
在源码的阅读过程中,可以了解别人实现某个功能的涉及思路,看看他们是怎么想,怎么做的.接下来,我们看看这篇Java源码解析之object的详细内容. Java基类Object java.lang.Object,Java所有类的父类,在你编写一个类的时候,若无指定父类(没有显式extends一个父类)编译器(一般编译器完成该步骤)会默认的添加Object为该类的父类(可以将该类反编译看其字节码,不过貌似Java7自带的反编译javap现在看不到了). 再说的详细点:假如类A,没有显式继承其他类,编译
-
eclipse/intellij idea 查看java源码和注释方法
工作三年了,一直不知道怎么用IDE查看第三方jar包的源码和注释,惭愧啊!看源码还好些,itellij idea自带反编译器,eclipse装个插件即可,看注释就麻烦了,总不能去找api文档吧!现在终于掌握了,下面给出解决方案,供大家参考,以提升开发学习效率! eclipse 1.下载源码包 1.1 去官网下载 1.2 去maven仓库下载( 例如:maven mysql 百度一下,肯定会出现仓库地址,找某一个版本下载即可) 1.3 maven命令下载(适用maven项目),在pom.xml文件
-
android apk反编译到java源码的实现方法
Android由于其代码是放在dalvik虚拟机上的托管代码,所以能够很容易的将其反编译为我们可以识别的代码. 之前我写过一篇文章反编译Android的apk包到smali文件 然后再重新编译签名后打包实现篡改apk的功能. 最近又有一种新的方法来实现直接从Android apk包里的classes.dex文件,把dex码反编译到java的.class二进制码,然后从.class二进制码反编译到java源码想必就不用我来多说了吧. 首先我们需要的工具是dex2jar和jd-gui 其中第一个工具
-
Java源码角度分析HashMap用法
-HashMap- 优点:超级快速的查询速度,时间复杂度可以达到O(1)的数据结构非HashMap莫属.动态的可变长存储数据(相对于数组而言). 缺点:需要额外计算一次hash值,如果处理不当会占用额外的空间. -HashMap如何使用- 平时我们使用hashmap如下 Map<Integer,String> maps=new HashMap<Integer,String>(); maps.put(1, "a"); maps.put(2, "b&quo