一文带你全面了解Java Properties类
目录
- 概述
- 介绍
- 构造方法
- 关键方法
- 使用案例
- 源码解析
- 总结
概述
Properties是JDK1.0中引入的java类,目前也在项目中大量使用,主要用来读取外部的配置,那除了这个,你对它其他的一些api也了解吗? 你了解它是怎么实现的吗? 如果不清楚的话,就通过本篇文章带你一探究竟。
介绍

java.util.Properties继承自java.util.Hashtable,是一个持久化的属性保存对象,可以将属性内容写出到stream中或者从stream中读取属性内容。 它的重要特性如下:
- 在底层的Hashtable中,每一对属性的key和value都是按照string类型来保存的。
- Properties支持文本方式和xml方式的数据存储。在文本方式中,格式为key:value,其中分隔符可以是:冒号(:)、等号(=)、空格。其中空格可以作为key的结束,同时获取的值回将分割符号两端的空格去掉。
- Properties可以将其他的Properties对象作为默认的值。
- Hashtable的所有方法Properties对象均可以访问,但是不建议这么做,因为Hashtable可以存放其他数据类型,这样会导致Properties一些方法调用报错。
- 在properties文件中,可以用井号"#"来作注释。
- 线程安全
- key、value不可以是null
构造方法
Properties()
创建一个无默认值的空属性列表。
Properties(Properties defaults)
创建一个带有指定默认值的空属性列表。
关键方法
getProperty ( String key)
根据指定的key获取对应的属性value值,如果在自身的存储集合中没有找到对应的key,那么就直接到默认的defaults属性指定的Properties中获取属性值。
getProperty(String, String)
当getProperty(String)方法返回值为null的时候,返回给定的默认值,而不是返回null。
load ( InputStream inStream)
从byte stream中加载key/value键值对,要求所有的key/value键值对是按行存储,同时是用ISO-8859-1编译的, 不支持中文。
load(Reader)
从字符流中加载key/value键值对,要求所有的键值对都是按照行来存储的。
loadFromXML(InputStream)
从xml文件中加载property,底层使用XMLUtils.load(Properties,InputStream)方法来加载。
setProperty ( String key, String value)
调用 Hashtable 的方法 put 。他通过调用基类的put方法来设置 键 - 值对。
store ( OutputStream out, String comments)
将所有的property(保存defaults的)都写出到流中,同时如果给定comments的话,那么要加一个注释。
storeToXML(OutputSteam, comment, encoding)
写出到xml文件中。
Set stringPropertyNames()
获取所有Properties中所有的key集合
clear ()
清除所有装载的 键值对。该方法在基类中提供。
使用案例
新建配置文件app.properties
## 用户信息 user.name:旭阳 user.age=28 user.sex 男
通过idea设置它的格式为UTF-8。

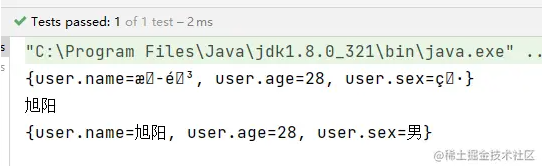
验证读取以及中文乱码的问题
@Test
public void test1() throws IOException {
Properties properties = new Properties();
// 使用load inputstream
properties.load(this.getClass().getClassLoader().getResourceAsStream("app.properties"));
// 出现乱码
System.out.println(properties);
// 转码
System.out.println(new String(properties.getProperty("user.name").getBytes(StandardCharsets.ISO_8859_1), StandardCharsets.UTF_8));
Properties properties2 = new Properties();
// 使用load read
BufferedReader bf = new BufferedReader(new InputStreamReader(this.getClass().getClassLoader().getResourceAsStream("app.properties"), "UTF-8"));
properties2.load(bf);
System.out.println(properties2);
}
运行结果:
保存为xml格式
@Test
public void test2() throws IOException {
Properties properties2 = new Properties();
// 使用load read
BufferedReader bf = new BufferedReader(new InputStreamReader(this.getClass().getClassLoader().getResourceAsStream("app.properties"), "UTF-8"));
properties2.load(bf);
System.out.println(properties2);
// 保存到xml
FileOutputStream fileOutputStream = new FileOutputStream("app.xml");
properties2.storeToXML(fileOutputStream, "alvin info", "UTF-8");
}
运行结果:

源码解析
源码这部分主要分析下load(Reader)和load(InputStream)这两个最常用的方法,这两个方法是指定从文本文件中加载key/value属性值,底层都是将流封装成为LineReader对象,然后通过load0方法来加载属性键值对的。
public synchronized void load(InputStream inStream) throws IOException {
load0(new LineReader(inStream));
}
将inputStream封装程一个LineReader,每次可以读取一行数据。
LineReader源码分析:
class LineReader {
/**
* 根据字节流创建LineReader对象
*
* @param inStream
* 属性键值对对应的字节流对象
*/
public LineReader(InputStream inStream) {
this.inStream = inStream;
inByteBuf = new byte[8192];
}
/**
* 根据字符流创建LineReader对象
*
* @param reader
* 属性键值对对应的字符流对象
*/
public LineReader(Reader reader) {
this.reader = reader;
inCharBuf = new char[8192];
}
// 字节流缓冲区, 大小为8192个字节
byte[] inByteBuf;
// 字符流缓冲区,大小为8192个字符
char[] inCharBuf;
// 当前行信息的缓冲区,大小为1024个字符
char[] lineBuf = new char[1024];
// 读取一行数据时候的实际读取大小
int inLimit = 0;
// 读取的时候指向当前字符位置
int inOff = 0;
// 字节流对象
InputStream inStream;
// 字符流对象
Reader reader;
/**
* 读取一行,将行信息保存到{@link lineBuf}对象中,并返回实际的字符个数
*
* @return 实际读取的字符个数
* @throws IOException
*/
int readLine() throws IOException {
// 总的字符长度
int len = 0;
// 当前字符
char c = 0;
boolean skipWhiteSpace = true;
boolean isCommentLine = false;
boolean isNewLine = true;
boolean appendedLineBegin = false;
boolean precedingBackslash = false;
boolean skipLF = false;
while (true) {
if (inOff >= inLimit) {
// 读取一行数据,并返回这一行的实际读取大小
inLimit = (inStream == null) ? reader.read(inCharBuf) : inStream.read(inByteBuf);
inOff = 0;
// 如果没有读取到数据,那么就直接结束读取操作
if (inLimit <= 0) {
// 如果当前长度为0或者是改行是注释,那么就返回-1。否则返回len的值。
if (len == 0 || isCommentLine) {
return -1;
}
return len;
}
}
// 判断是根据字符流还是字节流读取当前字符
if (inStream != null) {
// The line below is equivalent to calling a ISO8859-1 decoder.
// 字节流是根据ISO8859-1进行编码的,所以在这里进行解码操作。
c = (char) (0xff & inByteBuf[inOff++]);
} else {
c = inCharBuf[inOff++];
}
// 如果前一个字符是换行符号,那么判断当前字符是否也是换行符号
if (skipLF) {
skipLF = false;
if (c == '\n') {
continue;
}
}
// 如果前一个字符是空格,那么判断当前字符是不是空格类字符
if (skipWhiteSpace) {
if (c == ' ' || c == '\t' || c == '\f') {
continue;
}
if (!appendedLineBegin && (c == '\r' || c == '\n')) {
continue;
}
skipWhiteSpace = false;
appendedLineBegin = false;
}
// 如果当前新的一行,那么进入该if判断中
if (isNewLine) {
isNewLine = false;
// 如果当前字符是#或者是!,那么表示该行是一个注释行
if (c == '#' || c == '!') {
isCommentLine = true;
continue;
}
}
// 根据当前字符是不是换行符号进行判断操作
if (c != '\n' && c != '\r') {
// 当前字符不是换行符号
lineBuf[len++] = c;// 将当前字符写入到行信息缓冲区中,并将len自增加1.
// 如果len的长度大于行信息缓冲区的大小,那么对lineBuf进行扩容,扩容大小为原来的两倍,最大为Integer.MAX_VALUE
if (len == lineBuf.length) {
int newLength = lineBuf.length * 2;
if (newLength < 0) {
newLength = Integer.MAX_VALUE;
}
char[] buf = new char[newLength];
System.arraycopy(lineBuf, 0, buf, 0, lineBuf.length);
lineBuf = buf;
}
// 是否是转义字符
// flip the preceding backslash flag
if (c == '\') {
precedingBackslash = !precedingBackslash;
} else {
precedingBackslash = false;
}
} else {
// reached EOL
if (isCommentLine || len == 0) {
// 如果这一行是注释行,或者是当前长度为0,那么进行clean操作。
isCommentLine = false;
isNewLine = true;
skipWhiteSpace = true;
len = 0;
continue;
}
// 如果已经没有数据了,就重新读取
if (inOff >= inLimit) {
inLimit = (inStream == null) ? reader.read(inCharBuf) : inStream.read(inByteBuf);
inOff = 0;
if (inLimit <= 0) {
return len;
}
}
// 查看是否是转义字符
if (precedingBackslash) {
// 如果是,那么表示是另起一行,进行属性的定义,len要自减少1.
len -= 1;
// skip the leading whitespace characters in following line
skipWhiteSpace = true;
appendedLineBegin = true;
precedingBackslash = false;
if (c == '\r') {
skipLF = true;
}
} else {
return len;
}
}
}
}
}
readLine这个方法每次读取一行数据;如果我们想在多行写数据,那么可以使用''来进行转义,在该转义符号后面换行,是被允许的。
load0方法源码如下:
private void load0(LineReader lr) throws IOException {
char[] convtBuf = new char[1024];
// 读取的字符总数
int limit;
// 当前key所在位置
int keyLen;
// value的起始位置
int valueStart;
// 当前字符
char c;
//
boolean hasSep;
// 是否是转义字符
boolean precedingBackslash;
while ((limit = lr.readLine()) >= 0) {
c = 0;
// key的长度
keyLen = 0;
// value的起始位置默认为limit
valueStart = limit;
//
hasSep = false;
precedingBackslash = false;
// 如果key的长度小于总的字符长度,那么就进入循环
while (keyLen < limit) {
// 获取当前字符
c = lr.lineBuf[keyLen];
// 如果当前字符是=或者是:,而且前一个字符不是转义字符,那么就表示key的描述已经结束
if ((c == '=' || c == ':') && !precedingBackslash) {
// 指定value的起始位置为当前keyLen的下一个位置
valueStart = keyLen + 1;
// 并且指定,去除空格
hasSep = true;
break;
} else if ((c == ' ' || c == '\t' || c == '\f') && !precedingBackslash) {
// 如果当前字符是空格类字符,而且前一个字符不是转义字符,那么表示key的描述已经结束
// 指定value的起始位置为当前位置的下一个位置
valueStart = keyLen + 1;
break;
}
// 如果当前字符为'',那么跟新是否是转义号。
if (c == '\') {
precedingBackslash = !precedingBackslash;
} else {
precedingBackslash = false;
}
keyLen++;
}
// 如果value的起始位置小于总的字符长度,那么就进入该循环
while (valueStart < limit) {
// 获取当前字符
c = lr.lineBuf[valueStart];
// 判断当前字符是否是空格类字符,达到去空格的效果
if (c != ' ' && c != '\t' && c != '\f') {
// 当前字符不是空格类字符,而且当前字符为=或者是:,并在此之前没有出现过=或者:字符。
// 那么value的起始位置继续往后移动。
if (!hasSep && (c == '=' || c == ':')) {
hasSep = true;
} else {
// 当前字符不是=或者:,或者在此之前出现过=或者:字符。那么结束循环。
break;
}
}
valueStart++;
}
// 读取key
String key = loadConvert(lr.lineBuf, 0, keyLen, convtBuf);
// 读取value
String value = loadConvert(lr.lineBuf, valueStart, limit - valueStart, convtBuf);
// 包括key/value
put(key, value);
}
}
会将分割符号两边的空格去掉,并且分割符号可以是=,:,空格等。而且=和:的级别比空格分隔符高,即当这两个都存在的情况下,是按照=/:分割的。可以看到在最后会调用一个loadConvert方法,该方法主要是做key/value的读取,并将十六进制的字符进行转换。
总结
本文阐述了Properties的基本作用以及源码实现,是不是对Properties有了更近一步的认识呢。
以上就是一文带你全面了解Java Properties类的详细内容,更多关于Java Properties类的资料请关注我们其它相关文章!
相关推荐
-
快速上手Java中的Properties集合类
目录 概念 为什么需要Properties类? Properties 总结 概念 Java中的Properties文件是一种配置文件,主要用于表达配置信息,格式是文本文件.该类主要用于读取Java的配置文件,也可以对properties文件进行修改 属性配置:以“键=值”的方式书写一个属性的配置信息注 释:在properties文件中,可以用“#”来注释 为什么需要Properties类? 将一些固定修改的内容放到Properties文件,如果我们将这些内容放到程序里面(比如:账号.密码),假如
-

Java中Properties类的操作实例详解
Java中Properties类的操作实例详解 知识学而不用,就等于没用,到真正用到的时候还得重新再学.最近在看几款开源模拟器的源码,里面涉及到了很多关于Properties类的引用,由于Java已经好久没用了,而这些模拟器大多用Java来写,外加一些脚本语言Python,Perl之类的,不得已,又得重新拾起.本文通过看<Java编程思想>和一些网友的博客总结而来,只为简单介绍Properties类的相关操作. 一.Java Properties类 Java中有个比较重要的类Properti
-
浅谈Java中Properties类的详细使用
目录 一.Properties 类 二.打印JVM参数 三.打印自定义.properties文件中的值 3.1.list输出到控制台用绝对路径加载 3.2.propertyNames输出getClass()加载 3.3.stringPropertyNames输出getClassLoader加载(推荐) 四.获取值getProperties 五.写入到Properties文件 5.1.普通写入,中文时乱码 5.2.解决乱码写入的问题 六.加载和导出到xml配置文件 6.1.导出到.xml配置文件s
-
浅谈java Properties类的使用基础
Properties类继承自HashTable,通常和io流结合使用.它最突出的特点是将key/value作为配置属性写入到配置文件中以实现配置持久化,或从配置文件中读取这些属性.它的这些配置文件的规范后缀名为".properties".表示了一个持久的属性集. 需要注意几点: 无论是key还是value,都必须是String数据类型. 虽然继承自HashTable,但它却没有使用泛型. 虽然可以使用HashTable的put方法,但不建议使用它,而是应该使用setProperty()
-
一文带你搞懂Java中Get和Post的使用
目录 1 Get请求数据 1.1 Controller 1.2 Service 1.3 Application 1.4 Postman 2 Post接收数据 2.1 Controller 2.2 Service 2.3 Application 2.4 Postman 3 Post发送数据 3.1 Controller 3.2 Service 3.3 ResponseResult 3.4 Config 3.5 Application 3.6 Postman 1 Get请求数据 项目地址:https
-
一文带你全面了解Java Hashtable
目录 概述 介绍和使用 核心机制 实现机制 扩容机制 源码解析 成员变量 构造函数 put方法 get方法 remove方法 总结 概述 HashTable是jdk 1.0中引入的产物,基本上现在很少使用了,但是会在面试中经常被问到,你都知道吗: HashTable底层的实现机制是什么? HashTable的扩容机制是什么? HashTable和HashMap的区别是什么? 介绍和使用 和HashMap一样,Hashtable也是一个散列表,它存储的内容是键值对(key-value)映射, 重要
-
一文带你彻底理解Java序列化和反序列化
Java序列化是什么? Java序列化是指把Java对象转换为字节序列的过程,Java反序列化是指把字节序列恢复为Java对象的过程. 反序列化: 客户端重文件,或者网络中获取到文件以后,在内存中重构对象. 序列化: 对象序列化的最重要的作用是传递和保存对象的时候,保证对象的完整性和可传递性.方便字节可以在网络上传输以及保存在本地文件. 为什么需要序列化和反序列化 实现分布式 核心在于RMI,可以利用对象序列化运行远程主机上的服务,实现运行的时候,就像在本地上运行Java对象一样. 实现递归保存
-
一文带你深入了解Java泛型
目录 什么是Java泛型 泛型的使用 泛型类 泛型接口 泛型方法 泛型的底层实现机制 ArrayList源码解析 什么是泛型擦除 泛型的边界 ?:无界通配符 extends 上边界通配符 super 下边界通配符 PECS原则 泛型是怎么擦除的 擦除类定义中的无限制类型参数 擦除类定义中的有限制类型擦除 擦除方法定义中的类型参数 桥接方法和泛型的多态 泛型擦除带来的限制与局限 泛型不适用基本数据类型 无法创建具体类型的泛型数组 反射其实可以绕过泛型的限制 什么是Java泛型 Java 泛型(ge
-
一文带你真正理解Java中的内部类
目录 概述 内部类介绍和分类 常规内部类 局部内部类 匿名内部类 静态内部类 静态内部类和普通内部类的区别 内部类的作用 概述 不知道大家在平时的开发过程中或者源码里是否留意过内部类,那有思考过为什么要有内部类,内部类都有哪几种形式,静态内部类和普通内部类有什么区别呢?本篇文章主要带领大家理解下这块内容. 内部类介绍和分类 顾名思义,内部类是指一个类在另外一个类的内部,是定义在另一个类中的类.根据类的位置和属性不同,可以分为下面几种. 常规内部类 @Data public class Tree
-
一文带你玩转Java异常处理
目录 1.前言 2. Exception 类的层次 2.1 Exception 类的层次简介 3. Java 内置异常类 3.1 Java 内置异常类简介 3.2 非检查异常类举例 3.3 检查性异常类表 4. 异常方法 4.1 Throwable 类的主要方法 5. 捕获异常 5.1 捕获异常简介 5.2 try/catch语法如下 5.3 多重捕获块语法说明 6. throws/throw 关键字 6.1 throws/throw 关键字简介 6.2 代码实例 7. finally关键字 7
-
一文带你搞懂Java中的泛型和通配符
目录 概述 泛型介绍和使用 泛型类 泛型方法 类型变量的限定 通配符使用 无边界通配符 通配符上界 通配符下界 概述 泛型机制在项目中一直都在使用,比如在集合中ArrayList<String, String>, Map<String,String>等,不仅如此,很多源码中都用到了泛型机制,所以深入学习了解泛型相关机制对于源码阅读以及自己代码编写有很大的帮助.但是里面很多的机制和特性一直没有明白,特别是通配符这块,对于通配符上界.下界每次用每次百度,经常忘记,这次我就做一个总结,加
-
一文带你深入剖析Java线程池的前世今生
目录 由线程到线程池 线程在做什么 为什么需要线程池 线程池实现原理 总结 由线程到线程池 线程在做什么 灵魂拷问:写了那么多代码,你能够用一句话简练描述线程在干啥吗? public class Demo01 { public static void main(String[] args) { var thread = new Thread(() -> { System.out.println("Hello world from a Java thread"
-
一文带你深入了解Java中延时任务的实现
目录 概述 JAVA DelayQueue DelayQueue的实现原理 DelayQueue实现延时队列的优缺点 时间轮算法 时间轮的具体实现 进阶优化版时间轮算法 时间轮算法的应用 小结 redis延时队列 mq延时队列 rocketmq延时消息 rocketmq的精准延时消息 总结 概述 延时任务相信大家都不陌生,在现实的业务中应用场景可以说是比比皆是.例如订单下单15分钟未支付直接取消,外卖超时自动赔付等等.这些情况下,我们该怎么设计我们的服务的实现呢? 笨一点的方法自然是定时任务去数
-
一文带你搞懂Java中的递归
目录 概述 递归累加求和 计算1 ~ n的和 代码执行图解 递归求阶乘 递归打印多级目录 综合案例 文件搜索 文件过滤器优化 Lambda优化 概述 递归:指在当前方法内调用自己的这种现象. 递归的分类: 递归分为两种,直接递归和间接递归. 直接递归称为方法自身调用自己. 间接递归可以A方法调用B方法,B方法调用C方法,C方法调用A方法. 注意事项: 递归一定要有条件限定,保证递归能够停止下来,否则会发生栈内存溢出. 在递归中虽然有限定条件,但是递归次数不能太多.否则也会发生栈内存溢出. 构造方