Python seaborn barplot画图案例
目录
- 默认barplot
- 使用案例
- 修改capsize
- 显示error bar的值
- annotata error bar
- error bar选取sd
- 设置置信区间(68)
- 设置置信区间(95)
- dataframe aggregate函数使用
- dataframe aggregate 自定义函数
- dataframe aggregate 自定义函数2
- seaborn显示网格
- seaborn设置刻度
- 使用其他estaimator
默认barplot
import seaborn as sns
import matplotlib.pyplot as plt
import numpy as np
sns.set_theme(style="whitegrid")
df = sns.load_dataset("tips")
#默认画条形图
sns.barplot(x="day",y="total_bill",data=df)
plt.show()
#计算平均值看是否和条形图的高度一致
print(df.groupby("day").agg({"total_bill":[np.mean]}))
print(df.groupby("day").agg({"total_bill":[np.std]}))
# 注意这个地方error bar显示并不是标准差

total_bill
mean
day
Thur 17.682742
Fri 17.151579
Sat 20.441379
Sun 21.410000
total_bill
std
day
Thur 7.886170
Fri 8.302660
Sat 9.480419
Sun 8.832122
使用案例
# import libraries
import seaborn as sns
import numpy as np
import matplotlib.pyplot as plt
# load dataset
tips = sns.load_dataset("tips")
# Set the figure size
plt.figure(figsize=(14, 8))
# plot a bar chart
ax = sns.barplot(x="day", y="total_bill", data=tips, estimator=np.mean, ci=85, capsize=.2, color='lightblue')

修改capsize
ax=sns.barplot(x="day",y="total_bill",data=df,capsize=1.0) plt.show()

显示error bar的值
import seaborn as sns
import matplotlib.pyplot as plt
sns.set_theme(style="whitegrid")
df = sns.load_dataset("tips")
#默认画条形图
ax=sns.barplot(x="day",y="total_bill",data=df)
plt.show()
for p in ax.lines:
width = p.get_linewidth()
xy = p.get_xydata() # 显示error bar的值
print(xy)
print(width)
print(p)

[[ 0. 15.85041935] [ 0. 19.64465726]] 2.7 Line2D(_line0) [[ 1. 13.93096053] [ 1. 21.38463158]] 2.7 Line2D(_line1) [[ 2. 18.57236207] [ 2. 22.40351437]] 2.7 Line2D(_line2) [[ 3. 19.66244737] [ 3. 23.50109868]] 2.7 Line2D(_line3)
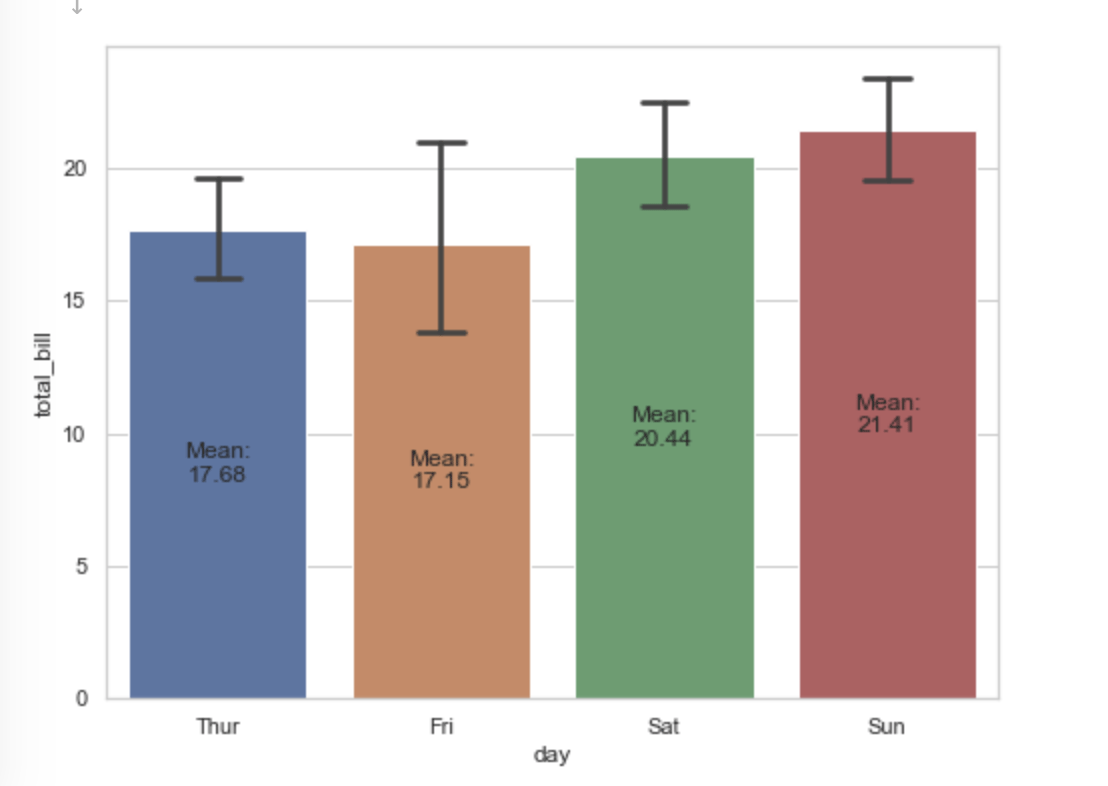
annotata error bar
fig, ax = plt.subplots(figsize=(8, 6))
sns.barplot(x='day', y='total_bill', data=df, capsize=0.2, ax=ax)
# show the mean
for p in ax.patches:
h, w, x = p.get_height(), p.get_width(), p.get_x()
xy = (x + w / 2., h / 2)
text = f'Mean:\n{h:0.2f}'
ax.annotate(text=text, xy=xy, ha='center', va='center')
ax.set(xlabel='day', ylabel='total_bill')
plt.show()
error bar选取sd
import seaborn as sns
import matplotlib.pyplot as plt
sns.set_theme(style="whitegrid")
df = sns.load_dataset("tips")
#默认画条形图
sns.barplot(x="day",y="total_bill",data=df,ci="sd",capsize=1.0)## 注意这个ci参数
plt.show()
print(df.groupby("day").agg({"total_bill":[np.mean]}))
print(df.groupby("day").agg({"total_bill":[np.std]}))

total_bill
mean
day
Thur 17.682742
Fri 17.151579
Sat 20.441379
Sun 21.410000
total_bill
std
day
Thur 7.886170
Fri 8.302660
Sat 9.480419
Sun 8.832122
设置置信区间(68)
import seaborn as sns
import matplotlib.pyplot as plt
sns.set_theme(style="whitegrid")
df = sns.load_dataset("tips")
#默认画条形图
sns.barplot(x="day",y="total_bill",data=df,ci=68,capsize=1.0)## 注意这个ci参数
plt.show()

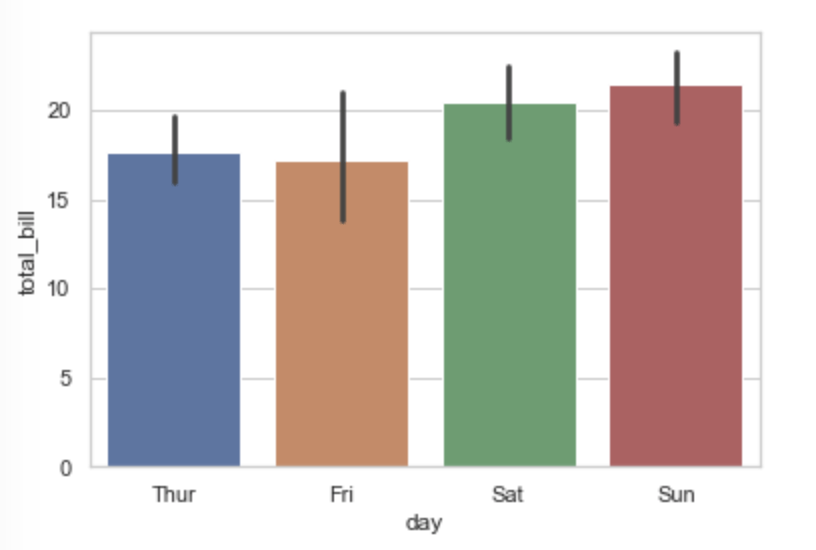
设置置信区间(95)
import seaborn as sns
import matplotlib.pyplot as plt
sns.set_theme(style="whitegrid")
df = sns.load_dataset("tips")
#默认画条形图
sns.barplot(x="day",y="total_bill",data=df,ci=95)
plt.show()
#计算平均值看是否和条形图的高度一致
print(df.groupby("day").agg({"total_bill":[np.mean]}))
total_bill
mean
day
Thur 17.682742
Fri 17.151579
Sat 20.441379
Sun 21.410000
dataframe aggregate函数使用
#计算平均值看是否和条形图的高度一致
df = sns.load_dataset("tips")
print("="*20)
print(df.groupby("day").agg({"total_bill":[np.mean]})) # 分组求均值
print("="*20)
print(df.groupby("day").agg({"total_bill":[np.std]})) # 分组求标准差
print("="*20)
print(df.groupby("day").agg({"total_bill":"nunique"})) # 这里统计的是不同的数目
print("="*20)
print(df.groupby("day").agg({"total_bill":"count"})) # 这里统计的是每个分组样本的数量
print("="*20)
print(df["day"].value_counts())
print("="*20)
====================
total_bill
mean
day
Thur 17.682742
Fri 17.151579
Sat 20.441379
Sun 21.410000
====================
total_bill
std
day
Thur 7.886170
Fri 8.302660
Sat 9.480419
Sun 8.832122
====================
total_bill
day
Thur 61
Fri 18
Sat 85
Sun 76
====================
total_bill
day
Thur 62
Fri 19
Sat 87
Sun 76
====================
Sat 87
Sun 76
Thur 62
Fri 19
Name: day, dtype: int64
====================
dataframe aggregate 自定义函数
import numpy as np
import pandas as pd
df = pd.DataFrame({'Buy/Sell': [1, 0, 1, 1, 0, 1, 0, 0],
'Trader': ['A', 'A', 'B', 'B', 'B', 'C', 'C', 'C']})
print(df)
def categorize(x):
m = x.mean()
return 1 if m > 0.5 else 0 if m < 0.5 else np.nan
result = df.groupby(['Trader'])['Buy/Sell'].agg([categorize, 'sum', 'count'])
result = result.rename(columns={'categorize' : 'Buy/Sell'})
result
Buy/Sell Trader 0 1 A 1 0 A 2 1 B 3 1 B 4 0 B 5 1 C 6 0 C 7 0 C

dataframe aggregate 自定义函数2
df = sns.load_dataset("tips")
#默认画条形图
def custom1(x):
m = x.mean()
s = x.std()
n = x.count()# 统计个数
#print(n)
return m+1.96*s/np.sqrt(n)
def custom2(x):
m = x.mean()
s = x.std()
n = x.count()# 统计个数
#print(n)
return m+s/np.sqrt(n)
sns.barplot(x="day",y="total_bill",data=df,ci=95)
plt.show()
print(df.groupby("day").agg({"total_bill":[np.std,custom1]})) # 分组求标准差
sns.barplot(x="day",y="total_bill",data=df,ci=68)
plt.show()
print(df.groupby("day").agg({"total_bill":[np.std,custom2]})) #
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-pkCx72ui-1658379974318)(output_24_0.png)]
total_bill
std custom1
day
Thur 7.886170 19.645769
Fri 8.302660 20.884910
Sat 9.480419 22.433538
Sun 8.832122 23.395703
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-GFyIePmW-1658379974318)(output_24_2.png)]
total_bill
std custom2
day
Thur 7.886170 18.684287
Fri 8.302660 19.056340
Sat 9.480419 21.457787
Sun 8.832122 22.423114
seaborn显示网格
ax=sns.barplot(x="day",y="total_bill",data=df,ci=95) ax.yaxis.grid(True) # Hide the horizontal gridlines ax.xaxis.grid(True) # Show the vertical gridlines

seaborn设置刻度
fig, ax = plt.subplots(figsize=(10, 8)) sns.barplot(x="day",y="total_bill",data=df,ci=95,ax=ax) ax.set_yticks([i for i in range(30)]) ax.yaxis.grid(True) # Hide the horizontal gridlines

使用其他estaimator
#estimator 指定条形图高度使用相加的和
sns.barplot(x="day",y="total_bill",data=df,estimator=np.sum)
plt.show()
#计算想加和看是否和条形图的高度一致
print(df.groupby("day").agg({"total_bill":[np.sum]}))
'''
total_bill
sum
day
Fri 325.88
Sat 1778.40
Sun 1627.16
Thur 1096.33
'''

到此这篇关于Python seaborn barplot画图案例的文章就介绍到这了,更多相关Python seaborn barplot 内容请搜索我们以前的文章或继续浏览下面的相关文章希望大家以后多多支持我们!
相关推荐
-

Python数据可视化之Seaborn的使用详解
目录 1. 安装 seaborn 2.准备数据 3.背景与边框 3.1 设置背景风格 3.2 其他 3.3 边框控制 4. 绘制 散点图 5. 绘制 折线图 5.1 使用 replot()方法 5.2 使用 lineplot()方法 6. 绘制直方图 displot() 7. 绘制条形图 barplot() 8. 绘制线性回归模型 9. 绘制 核密度图 kdeplot() 9.1 一般核密度图 9.2 边际核密度图 10. 绘制 箱线图 boxplot() 11. 绘制 提琴图 violinpl
-
Python+Seaborn绘制分布图的示例详解
目录 前言 示例 1 示例 2 示例 3 示例 4 示例 5 例子 6 例子 7 示例 8 示例 9 示例10 前言 在本文中,我们将介绍10个示例,以掌握如何使用用于Python的Seaborn库创建图表. 任何数据产品的第一步都应该是理解原始数据.对于成功和高效的产品,这一步骤占据了整个工作流程的很大一部分. 有几种方法用于理解和探索数据.其中之一是创建数据可视化.它们帮助我们探索和解释数据. 通过创建适当和设计良好的可视化,我们可以发现数据中的底层结构和关系. 分布区在数据分析中起着至关重
-
Python matplotlib seaborn绘图教程详解
目录 一.seaborn概述 二.数据整理 01折线图 02柱形图 03直方图 三.绘图 01设定调色盘 02柱状图 03技术图 04点图 05箱型图 06小提琴图 一.seaborn概述 Seaborn是在matplotlib的基础上进行了更高级的API封装,从而使得作图更加容易,在大多数情况下使用seaborn就能做出很具有吸引力的图.详情请查阅官网:seaborn 二.数据整理 import seaborn as sns import numpy as np import matplotl
-
Python可视化学习之seaborn绘制线型回归曲线
目录 本文速览 1.绘图数据准备 2.seaborn.regplot regplot默认参数线型回归图 分别设置点和拟合线属性 置信区间(confidenceinterval)设置 拟合线延伸与坐标轴相交 拟合离散变量曲线 多项式回归(polynomialregression)拟合曲线 3.seaborn.lmplot 按变量分类拟合回归线 散点marker设置 散点调色盘 拟合线属性设置 绘制分面图 本文速览 1.绘图数据准备 依旧使用鸢尾花iris数据集,详细介绍见之前文章. #导入本帖要用
-
Python可视化学习之seaborn调色盘
目录 1.color_palette()函数 2.seaborn可用调色盘 choose_colorbrewer_palette函数 Qualitativecolorpalettes Sequentialcolorpalettes Divergingcolorpalettes 1.color_palette() 函数 该函数是seaborn选取颜色关键函数 color_palette() will accept the name of any seaborn palette or matplot
-
Python可视化学习之seaborn绘制矩阵图详解
目录 本文内容速览 1.绘图数据准备 2.seaborn.pairplot 加上分类变量 修改调色盘 x,y轴方向选取相同子集 x,y轴方向选取不同子集 非对角线散点图加趋势线 对角线上的四个图绘制方式 只显示网格下三角图形 图形外观设置 3.seaborn.PairGrid(更灵活的绘制矩阵图) 每个子图绘制同类型的图 对角线和非对角线分别绘制不同类型图 对角线上方.对角线.对角线下方分别绘制不同类型图 其它一些参数修改 本文内容速览 1.绘图数据准备 还是使用鸢尾花iris数据集 #导入本帖
-
Python seaborn barplot画图案例
目录 默认barplot 使用案例 修改capsize 显示error bar的值 annotata error bar error bar选取sd 设置置信区间(68) 设置置信区间(95) dataframe aggregate函数使用 dataframe aggregate 自定义函数 dataframe aggregate 自定义函数2 seaborn显示网格 seaborn设置刻度 使用其他estaimator 默认barplot import seaborn as sns impor
-
Python matplotlib实时画图案例
实时画图 import matplotlib.pyplot as plt ax = [] # 定义一个 x 轴的空列表用来接收动态的数据 ay = [] # 定义一个 y 轴的空列表用来接收动态的数据 plt.ion() # 开启一个画图的窗口 for i in range(100): # 遍历0-99的值 ax.append(i) # 添加 i 到 x 轴的数据中 ay.append(i**2) # 添加 i 的平方到 y 轴的数据中 plt.clf() # 清除之前画的图 plt.plot(
-
python 绘制3D图案例分享
目录 1.散点图 代码 输入的数据格式 2.三维表面 surface 代码 输入的数据格式 scatter + surface图形展示 3. 三维瀑布图waterfall 代码 输入的数据格式 4. 3d wireframe code 输入的数据格式 1.散点图 代码 # This import registers the 3D projection, but is otherwise unused. from mpl_toolkits.mplot3d import Axes3D # noqa:
-
python 使用plt画图,去除图片四周的白边方法
用matplotlib.pyplot画的图,显示和保存的图片周围都会有白边,可以去掉.为了显示的更清楚,给图片加了红色的框 代码 "` import matplotlib.pyplot as plt fig, ax = plt.subplots() im = im[:, :, (2, 1, 0)] ax.imshow(im, aspect='equal') plt.axis('off') # 去除图像周围的白边 height, width, channels = im.shape # 如果dpi
-
Python OrderedDict的使用案例解析
这篇文章主要介绍了Python OrderedDict的使用案例,文中通过示例代码介绍的非常详细,对大家的学习或者工作具有一定的参考学习价值,需要的朋友可以参考下 很多人认为python中的字典是无序的,因为它是按照hash来存储的,但是python中有个模块collections(英文,收集.集合),里面自带了一个子类 OrderedDict,实现了对字典对象中元素的排序.请看下面的实例: import collections print "Regular dictionary" d
-
python用plt画图时,cmp设置方法
在python,有时候是需要画图的,比如把一个矩阵用图像的形式显示,之前用的好好的,每次用plt.imshow(),都是彩色图,不知为啥,突然全是黑白图了,于是需要设置cmap的值,如下: plt.imshow(confusion_matrix_percent,cmap='gray') plt.colorbar() plt.show() 在上面的代码中,设置cmap='gray',表示绘制灰度图,若需要绘制彩色图,可设置其它值,个人比较喜欢用 PRGn或者PRGn_r cmap的候选值有 'Ac
-
python 实现turtle画图并导出图片格式的文件
如下所示: from turtle import* import turtle setup(800,700,300,50) penup() seth(90) fd(100) seth(0) fd(-200) pendown() pensize(3) pencolor("black") seth(0) fd(210) seth(90) fd(20) seth(115) circle(120,129) seth(270) fd(20) seth(270) fd(15) seth(0) fd
-
VBA处理数据与Python Pandas处理数据案例比较分析
需求: 现有一个 csv文件,包含'CNUM'和'COMPANY'两列,数据里包含空行,且有内容重复的行数据. 要求: 1)去掉空行: 2)重复行数据只保留一行有效数据: 3)修改'COMPANY'列的名称为'Company_New': 4)并在其后增加六列,分别为'C_col','D_col','E_col','F_col','G_col','H_col'. 一,使用 Python Pandas来处理: import pandas as pd import numpy as np from p
-
python实现IOU计算案例
计算两个矩形的交并比,通常在检测任务里面可以作为一个检测指标.你的预测bbox和groundtruth之间的差异,就可以通过IOU来体现.很简单的算法实现,我也随便写了一个,嗯,很简单. 1. 使用时,请注意bbox四个数字的顺序(y0,x0,y1,x1),顺序不太一样. #!/usr/bin/env python # encoding: utf-8 def compute_iou(rec1, rec2): """ computing IoU :param rec1: (y0
-
python 实现任务管理清单案例
base.html: {% extends "bootstrap/base.html" %} {% block styles %} {{ super() }} <link rel="stylesheet" href="../static/css/main.css" rel="external nofollow" > {% endblock %} {% block navbar %} <nav class=&q