记一次SQL优化的实战记录
目录
- 前言
- 1. 创建表
- 2. 需求
- 3. 给表插入数据
- 4. 开始根据需求写SQL
- 4.1 第一版
- 4.2 第二版
- 4.3 第三版
- 总结
前言
昨天(2022-7-22)上线了我的一个功能,测试环境数据量较小,问题不大,但是上生产之后,直接卡死了,然后就开始了这么一次SQL优化,这里记录一下。
不太方便透露公司的表结构,这里我自己建了几张表,模拟一下就可以了。
肯定有杠精要说表可以不这样设计了,但是事实现在系统就是这样设计的,如果想改动表设计,影响面就太大了(我们急着上线哦)。当然,本文的后面也会给出修改设计的方案,以达到更优解。
1. 创建表
进货单表:
CREATE TABLE `purchase_order` ( `id` int(11) NOT NULL AUTO_INCREMENT COMMENT '主键自增id', `purchase_time` varchar(255) DEFAULT NULL COMMENT '进货时间', `purchase_pre_unit_price` decimal(10,2) unsigned zerofill NOT NULL COMMENT '进货预订单价(元/kg)', `purchase_weight` decimal(10,2) unsigned zerofill NOT NULL COMMENT '进货重量(kg)', `purchase_bill_no` varchar(255) NOT NULL COMMENT '进货单号', PRIMARY KEY (`id`) ) ENGINE=InnoDB AUTO_INCREMENT=62181 DEFAULT CHARSET=utf8 COMMENT='进货单';
进货结算单表:
CREATE TABLE `settlement_voucher` ( `id` int(11) NOT NULL AUTO_INCREMENT COMMENT '自增ID', `purchase_bill_no` varchar(512) DEFAULT NULL COMMENT '进货单号', `settlement_bill_no` varchar(64) NOT NULL COMMENT '结算单号', `unit_price` decimal(10,2) unsigned zerofill NOT NULL COMMENT '实际结算单价(元/kg)', `settlement_weight` decimal(10,2) unsigned zerofill NOT NULL COMMENT '实际结算重量(kg)', `cut_off_time` datetime DEFAULT NULL ON UPDATE CURRENT_TIMESTAMP COMMENT '结算时间', PRIMARY KEY (`id`), KEY `idx_settlement_bill_no` (`settlement_bill_no`) ) ENGINE=InnoDB AUTO_INCREMENT=63288 DEFAULT CHARSET=utf8 COMMENT='进货结算单';
发票表:
CREATE TABLE `invoice` ( `id` int(11) NOT NULL AUTO_INCREMENT COMMENT '主键ID', `invoice_code` varchar(255) NOT NULL COMMENT '发票代码', `invoice_number` varchar(255) NOT NULL COMMENT '发票号码', `pay_amount` decimal(10,2) DEFAULT NULL COMMENT '发票金额', PRIMARY KEY (`id`), KEY `idx_invoice_number` (`invoice_number`) ) ENGINE=InnoDB DEFAULT CHARSET=utf8 COMMENT='发票表';
发票-结算单关联表:
CREATE TABLE `settlement_invoice_relation` ( `id` int(11) NOT NULL AUTO_INCREMENT COMMENT '主键ID', `invoice_code` varchar(255) DEFAULT NULL COMMENT '发票代码', `invoice_number` varchar(255) DEFAULT NULL COMMENT '发票号码', `settlement_bill_no` varchar(64) DEFAULT NULL COMMENT '结算单号', PRIMARY KEY (`id`), KEY `idx_settlement_bill_no` (`settlement_bill_no`), KEY `idx_invoice_number` (`invoice_number`) ) ENGINE=InnoDB DEFAULT CHARSET=utf8 COMMENT='发票-结算单关联表';
以上是我自己创建的几张表,先介绍一下这几张表的关系:
- 进货单表(
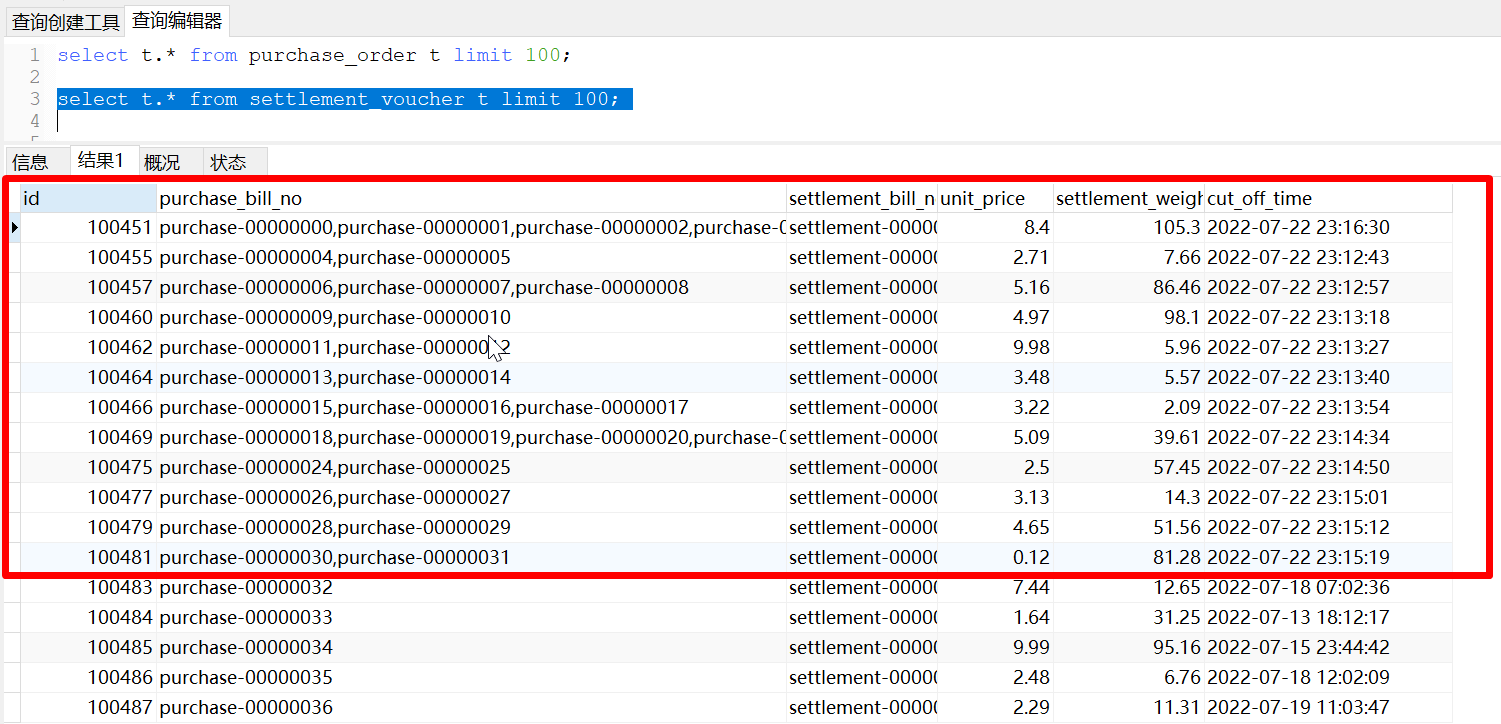
purchase_order)和进货结算单表(settlement_voucher)通过进货单号(purchase_bill_no)关联。这里值得注意的是:- 一个进货单可以对应多个进货结算单,通过
purchase_bill_no关联,如以下数据: - 一个进货结算单可以对应多个进货单,通过
purchase_bill_no关联,settlement_voucher表中的purchase_bill_no字段存放多个进货单号,使用英文逗号隔开。如以下数据:
- 一个进货单可以对应多个进货结算单,通过
- 发票表(
invoice)和结算单表(settlement_voucher)有一个关联关系表(settlement_invoice_relation)- 发票表和关联关系表使用
invoice_code和invoice_number关联 - 结算单表和关联关系表使用
settlement_bill_no关联 - 发票和结算单是多对多的关系
- 发票表和关联关系表使用
2. 需求
现在需要以进货结算单表(settlement_voucher)查询出一个列表:
- 列表字段有【进货时间(多个使用英文逗号隔开)、进货平均单价、进货预定总金额,结算单号,结算平均单价,结算金额,结算时间,发票号码(多个使用英文逗号隔开),发票代码(多个使用英文逗号隔开)】
- 查询条件有:进货时间(一个进货结算单对应多个进货单时,只要有一个进货单的时间在范围内,就查询到),结算时间,发票号码(一个结算单对应多个发票时,只要有一个发票能关联上,就查询到)
- 根据结算时间排序
当然,实际当时的那个需求,列表字段比这多,查询条件也比这多......
3. 给表插入数据
先给货单表(purchase_order)和进货结算单表(settlement_voucher)各自插入10万条数据,我这里使用了存储过程:
begin
declare i int;
declare purchase_weight decimal(10,2);
declare unit_price decimal(10,2);
declare purchase_bill_no varchar(255);
declare settlement_bill_no varchar(255);
set i=0;
while i<100000 do
select ROUND(RAND()*100,2) into purchase_weight from dual;
select ROUND(RAND()*10,2) into unit_price from dual;
select CONCAT('purchase-',LPAD(i,8,'0')) into purchase_bill_no from dual;
select CONCAT('settlement-',LPAD(i,8,'0')) into settlement_bill_no from dual;
-- 插入进货单表,进货时间随机生成
insert into purchase_order(purchase_time,purchase_pre_unit_price,purchase_weight,purchase_bill_no)
select (DATE_ADD(NOW(), INTERVAL FLOOR(1 - (RAND() * 864000)) SECOND )),
unit_price,purchase_weight,purchase_bill_no from dual;
-- 插入结算单表,结算时间随机生成
insert into settlement_voucher(purchase_bill_no,settlement_bill_no,unit_price,settlement_weight,cut_off_time)
select purchase_bill_no,settlement_bill_no,unit_price,purchase_weight,
(DATE_ADD(NOW(), INTERVAL FLOOR(1 - (RAND() * 864000)) SECOND )) from dual;
set i=i+1;
end while;
end
调用存储过程生成数据:
call pre();
生成之后需要随机改几条数据,模拟一个进货单可以对应多个进货结算单,以及一个进货结算单可以对应多个进货单两种情况(这样数据更真实一点)。
一个进货单可以对应多个进货结算单的情况就不模拟了,这种情况其实对这次查询的影响并不大。
一个进货结算单可以对应多个进货单的情况:
再创建一些发票数据和结算单-发票关联数据,需要体现多对多的关系:
insert into invoice(invoice_code,invoice_number,pay_amount)
VALUES
('111111','1111100','1000'),
('111112','1111101','1001'),
('111113','1111102','1002'),
('111114','1111103','1003'),
('111115','1111104','1004'),
('111116','1111105','1005'),
('111117','1111106','1006'),
('111118','1111107','1007'),
('111119','1111108','1008'),
('111110','1111109','1009');
INSERT into settlement_invoice_relation(invoice_code,invoice_number,settlement_bill_no)
VALUES
('111111','1111100','settlement-00000000'),
('111112','1111101','settlement-00000000'),
('111113','1111102','settlement-00000000'),
('111114','1111103','settlement-00000004'),
('111114','1111103','settlement-00000006'),
('111114','1111103','settlement-00000030'),
('111116','1111105','settlement-00000041'),
('111117','1111106','settlement-00000041'),
('111118','1111107','settlement-00000043');
4. 开始根据需求写SQL
优化第一步,当然是想让产品经理去掉一些查询条件,避免进货单表和进货结算表关联了,但是你懂的。。。。。。
这里就以进货时间为条件查询为例(因为主要就是进货单和进货结算单关联导致慢查询),记得需求哦,就是一个进货结算单可能对应多个进货单,只要有其中一个进货单在时间范围内,就需要查询出这条进货结算单
还有:我上面创建的表中索引也模拟了当时优化之前的索引......
4.1 第一版
select GROUP_CONCAT(po.purchase_time) as 进货时间, AVG(IFNULL(po.purchase_pre_unit_price,0)) as 进货均价, t.settlement_bill_no as 结算单号, AVG(IFNULL(t.unit_price,0)) as 结算均价, any_value(t.cut_off_time) as 结算时间, any_value(invoice_tmp.invoice_code) as 发票代码, any_value(invoice_tmp.invoice_number) as 发票号码 from settlement_voucher t left join purchase_order po on FIND_IN_SET(po.purchase_bill_no,t.purchase_bill_no)>0 left join ( select sir.settlement_bill_no, GROUP_CONCAT(i.invoice_number) invoice_number, GROUP_CONCAT(i.invoice_code) invoice_code from settlement_invoice_relation sir, invoice i where sir.invoice_code = i.invoice_code and sir.invoice_number = i.invoice_number group by sir.settlement_bill_no ) invoice_tmp on invoice_tmp.settlement_bill_no = t.settlement_bill_no where 1=1 -- and t.settlement_bill_no='settlement-00000000' and EXISTS(select 1 from purchase_order po1 where FIND_IN_SET(po1.purchase_bill_no,t.purchase_bill_no)>0 and po1.purchase_time >='2022-07-01 00:00:00' ) and EXISTS(select 1 from purchase_order po1 where FIND_IN_SET(po1.purchase_bill_no,t.purchase_bill_no)>0 and po1.purchase_time <='2022-07-23 23:59:59' ) group by t.settlement_bill_no;
第一版SQL当时在本地环境执行是用了5秒左右,此时就已经意识到问题了,这别说上生产了,就是在测试环境都得挂掉。
但是看看我在自己的垃圾服务器(双核4G)上跑这条SQL吧,是根本执行不出来的(虽然公司服务器好一些,但是生产环境确实卡死了):
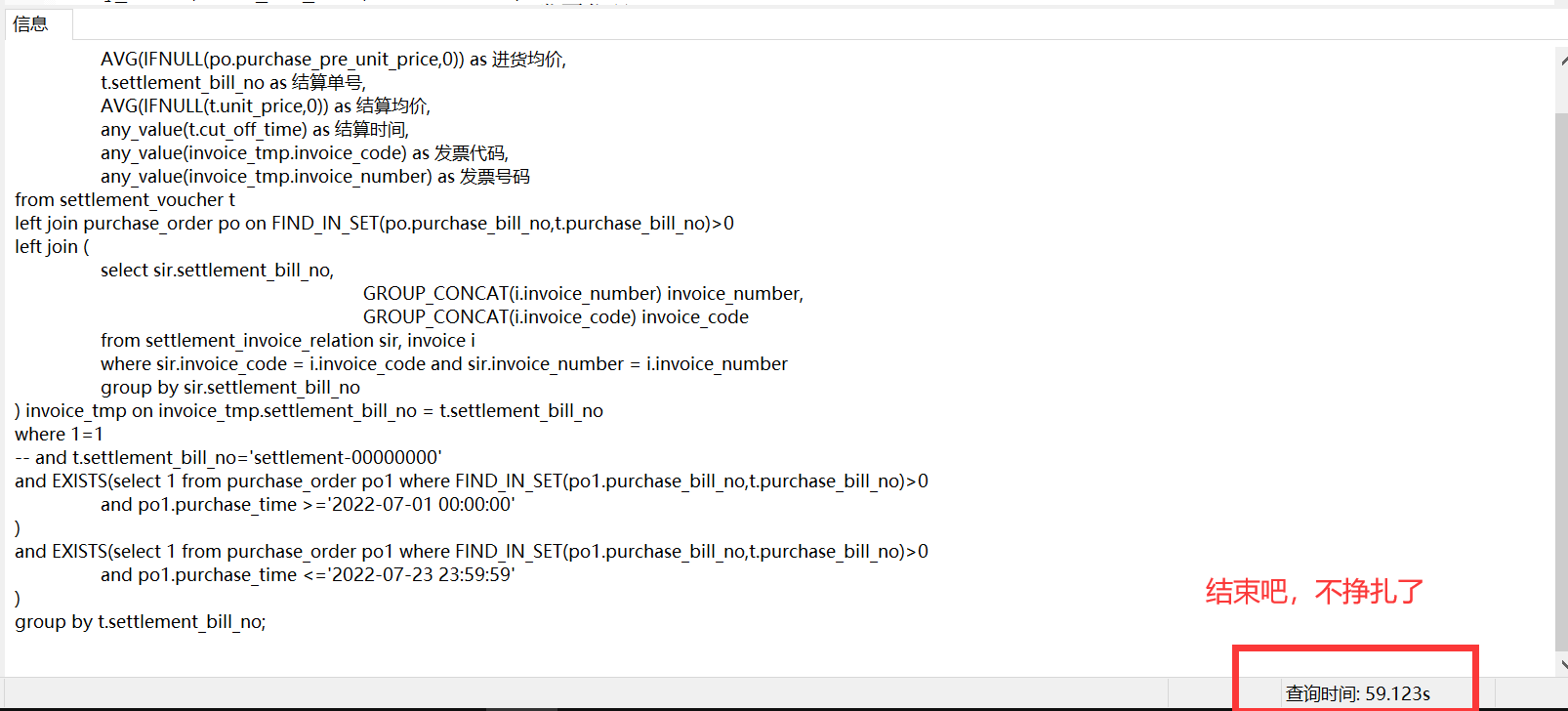
当时就还没没看执行计划,一眼看去,这个SQL中用到了FIND_IN_SET,肯定是不会走索引的,建了索引也没用,也就是主要是进货单表(purchase_order)和进货结算单表settlement_voucher关联会很慢,毕竟他们是多对多的关系,再加上这恶心的需求。所以现在想想该怎么才能不用 FIND_IN_SET。
对,吃饭期间,突发奇想:我应该可以把进货结算单表拆成一个临时表,如果进货结算单表对应了5个进货单,我就把进货结算单拆成5条数据,这五条数据除了进货单号不一样,其他字段都 一样,这样就可以不用FIND_IN_SET了。
说干就干,于是有了下面第二版SQL。
4.2 第二版
向把进货结算单表拆分成上面说的临时表,需要添加一个表:
CREATE TABLE `incre_table` ( `id` int(11) NOT NULL AUTO_INCREMENT, PRIMARY KEY (`id`) ) ENGINE=InnoDB DEFAULT CHARSET=utf8 COMMENT='用于分割进货结算单表'; -- 注意:这里一个进货结算单对应多少个进货单,这里就要依次插入多少条数据,我这里10条 就够用了 insert into incre_table(id) VALUES(1); insert into incre_table(id) VALUES(2); insert into incre_table(id) VALUES(3); insert into incre_table(id) VALUES(4); insert into incre_table(id) VALUES(5); insert into incre_table(id) VALUES(6); insert into incre_table(id) VALUES(7); insert into incre_table(id) VALUES(8); insert into incre_table(id) VALUES(9); insert into incre_table(id) VALUES(10);
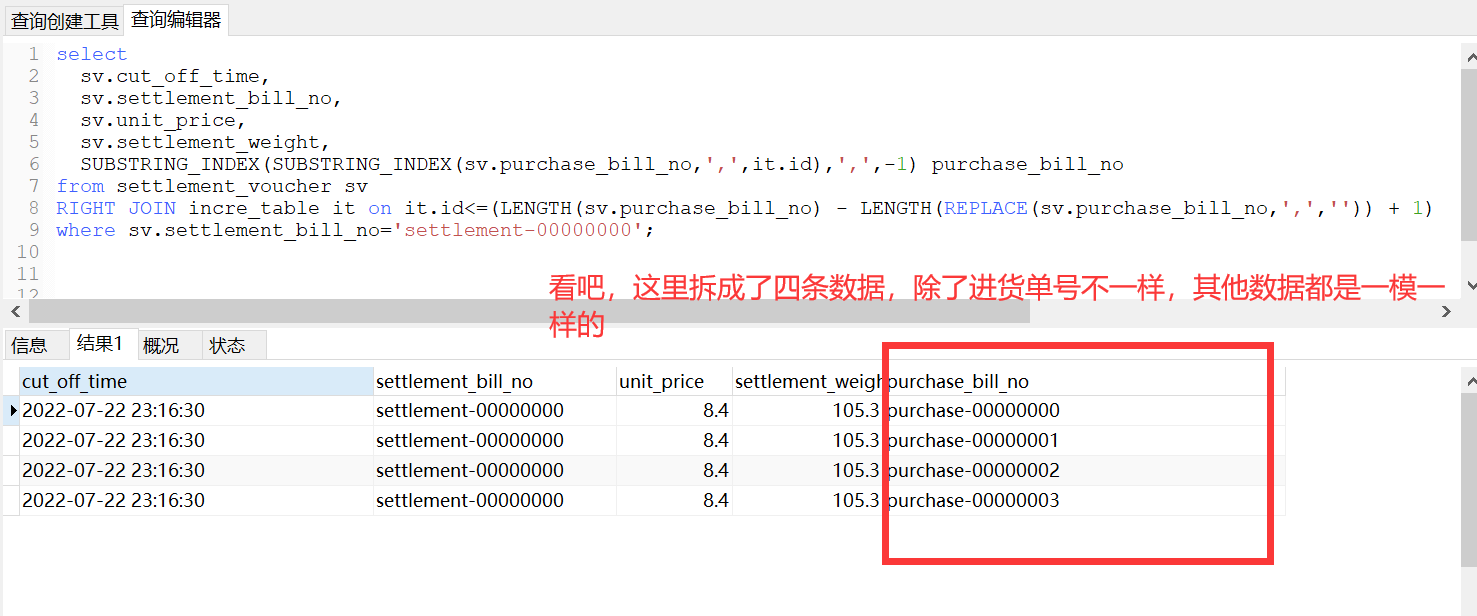
先来看看怎么把一条进货结算单数据拆分成多条:
select sv.cut_off_time, sv.settlement_bill_no, sv.unit_price, sv.settlement_weight, SUBSTRING_INDEX(SUBSTRING_INDEX(sv.purchase_bill_no,',',it.id),',',-1) purchase_bill_no from settlement_voucher sv RIGHT JOIN incre_table it on it.id<=(LENGTH(sv.purchase_bill_no) - LENGTH(REPLACE(sv.purchase_bill_no,',','')) + 1) where sv.settlement_bill_no='settlement-00000000';
来解释一下这个骚操作:
- 首先我创建了一个只有id的表
incre_table,插入了十条数据,并且这十条数据必须是1-10。 - 然后我使用
settlement_voucher右连接了incre_table,并且只取incre_table中id小于或等于进货单数量的数据。这样就控制了这条SQL应该查询多少条数据(就刚好是一个进货结算单对应的进货单条数)。 - 然后使用
SUBSTRING_INDEX去一个一个拆分settlement_voucher表中的进货单号
这套SQL执行的结果就是:
综合起来,就写好了第二版SQL:
select GROUP_CONCAT(po.purchase_time) as 进货时间, AVG(IFNULL(po.purchase_pre_unit_price,0)) as 进货均价, t.settlement_bill_no as 结算单号, AVG(IFNULL(t.unit_price,0)) as 结算均价, any_value(t.cut_off_time) as 结算时间, any_value(invoice_tmp.invoice_code) as 发票代码, any_value(invoice_tmp.invoice_number) as 发票号码 from ( select sv.cut_off_time, sv.settlement_bill_no, sv.unit_price, sv.settlement_weight, SUBSTRING_INDEX(SUBSTRING_INDEX(sv.purchase_bill_no,',',it.id),',',-1) purchase_bill_no from settlement_voucher sv RIGHT JOIN incre_table it on it.id<=(LENGTH(sv.purchase_bill_no) - LENGTH(REPLACE(sv.purchase_bill_no,',','')) + 1) ) t left join purchase_order po on po.purchase_bill_no = t.purchase_bill_no left join ( select sir.settlement_bill_no, GROUP_CONCAT(i.invoice_number) invoice_number, GROUP_CONCAT(i.invoice_code) invoice_code from settlement_invoice_relation sir, invoice i where sir.invoice_code = i.invoice_code and sir.invoice_number = i.invoice_number group by sir.settlement_bill_no ) invoice_tmp on invoice_tmp.settlement_bill_no = t.settlement_bill_no where 1=1 -- and t.settlement_bill_no='settlement-00000000' and po.purchase_time >='2022-07-01 00:00:00' and po.purchase_time <='2022-07-23 23:59:59' group by t.settlement_bill_no;
测试查询数据结果肯定是没有问题的哦!!!
好的,到这里终于把所有用到FIND_IN_SET的地方去掉了,这时看索引就有意义了!
看看执行计划吧:
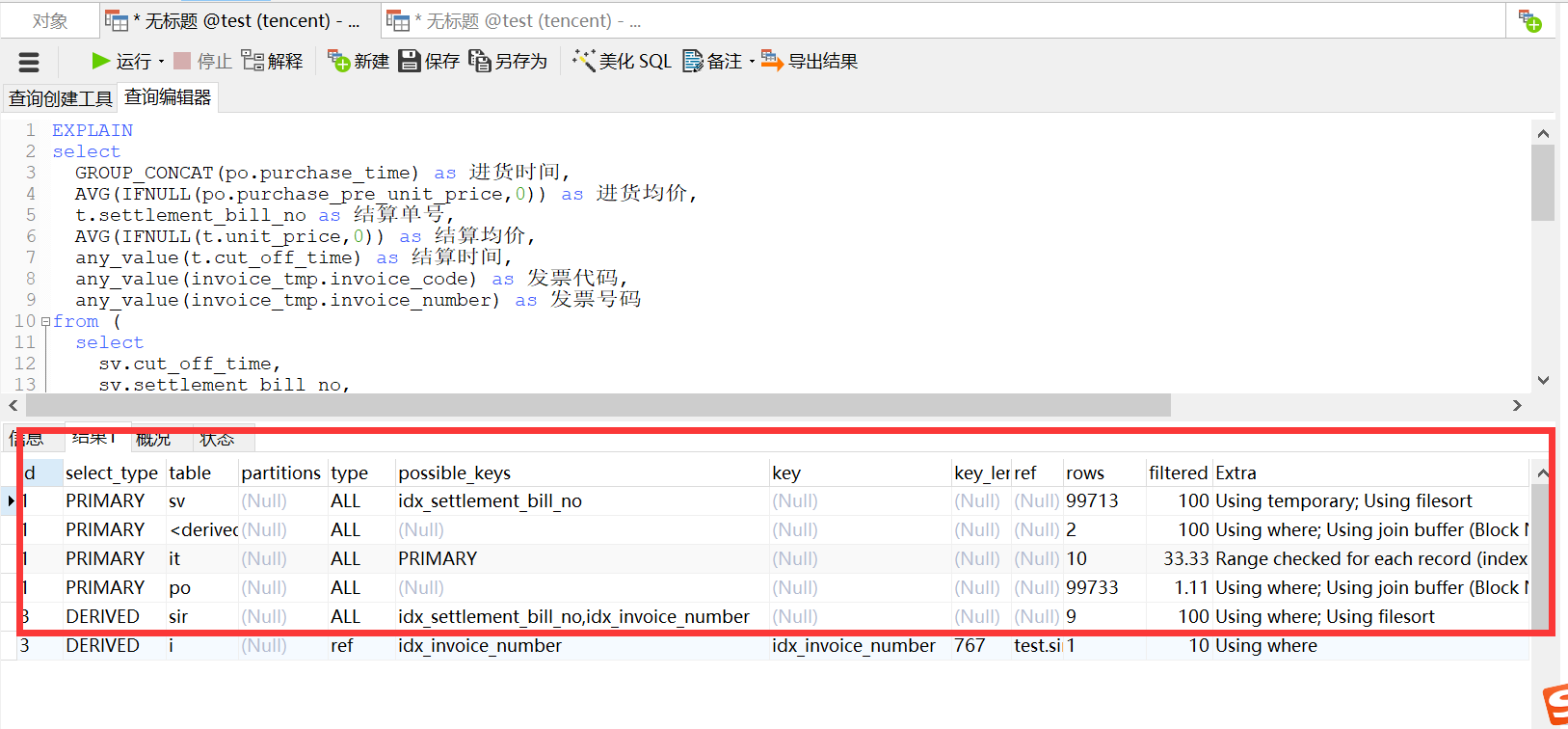
阿西巴,一堆的全表扫描,看看上面第二版SQL,发现进货表(purchase_order)的purchase_bill_no字段是应该走索引的,按道理这个字段一般设计表的时候就应该已经加索引了,但是我以为只是我以为,它确实没加索引,好的,那就给它加上索引吧:
create index idx_purchase_bill_no on purchase_order(purchase_bill_no);
加完是这个索引后,再看看执行计划:
purchase_order表的purchase_bill_no已经走了索引,但是settlement_invoice_relation咋不走索引,它是有两个索引的。。。。。。

再看看在我的垃圾服务器上执行,看能不能执行出来:
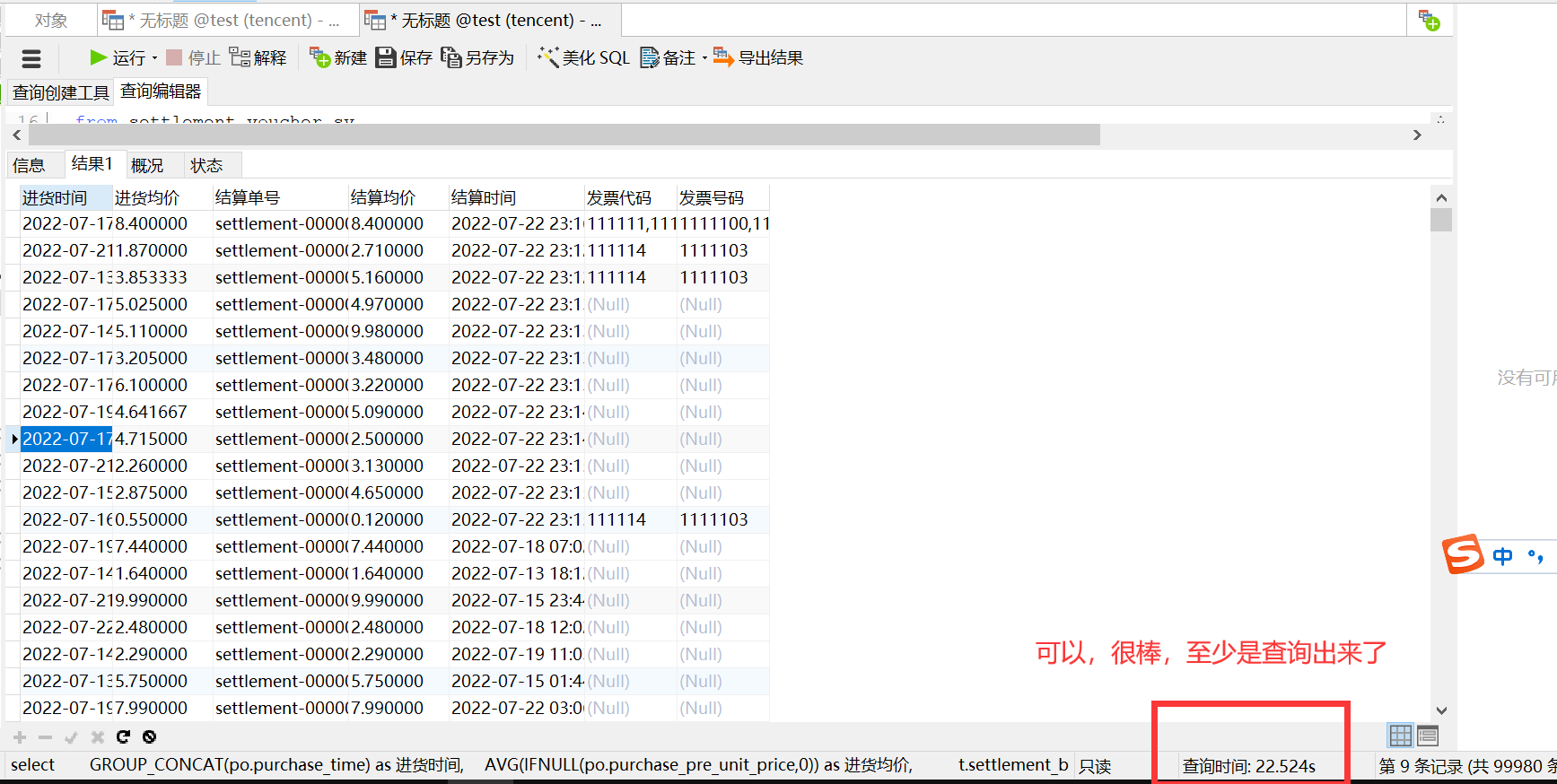
好了,为了让settlement_invoice_relation表的查询也走索引,开始下一轮的SQL优化
4.3 第三版
就不在下面去聚合获取invoice_code和invoice_number了,在上面来聚合,至于要以这两个字段作为查询条件,那可以把下面这条SQL再包一层,作为一个临时表再查询一遍,这里就不演示了
select GROUP_CONCAT(po.purchase_time) as 进货时间, AVG(IFNULL(po.purchase_pre_unit_price,0)) as 进货均价, t.settlement_bill_no as 结算单号, AVG(IFNULL(t.unit_price,0)) as 结算均价, any_value(t.cut_off_time) as 结算时间, GROUP_CONCAT(DISTINCT invoice_tmp.invoice_code) as 发票代码, GROUP_CONCAT(DISTINCT invoice_tmp.invoice_number) as 发票号码 from ( select sv.cut_off_time, sv.settlement_bill_no, sv.unit_price, sv.settlement_weight, SUBSTRING_INDEX(SUBSTRING_INDEX(sv.purchase_bill_no,',',it.id),',',-1) purchase_bill_no from settlement_voucher sv RIGHT JOIN incre_table it on it.id<=(LENGTH(sv.purchase_bill_no) - LENGTH(REPLACE(sv.purchase_bill_no,',','')) + 1) ) t left join purchase_order po on po.purchase_bill_no = t.purchase_bill_no left join ( select sir.settlement_bill_no, i.invoice_number, i.invoice_code from settlement_invoice_relation sir, invoice i where sir.invoice_code = i.invoice_code and sir.invoice_number = i.invoice_number ) invoice_tmp on invoice_tmp.settlement_bill_no = t.settlement_bill_no where 1=1 -- and t.settlement_bill_no='settlement-00000000' and po.purchase_time >='2022-07-01 00:00:00' and po.purchase_time <='2022-07-23 23:59:59' group by t.settlement_bill_no;
再看看执行计划:
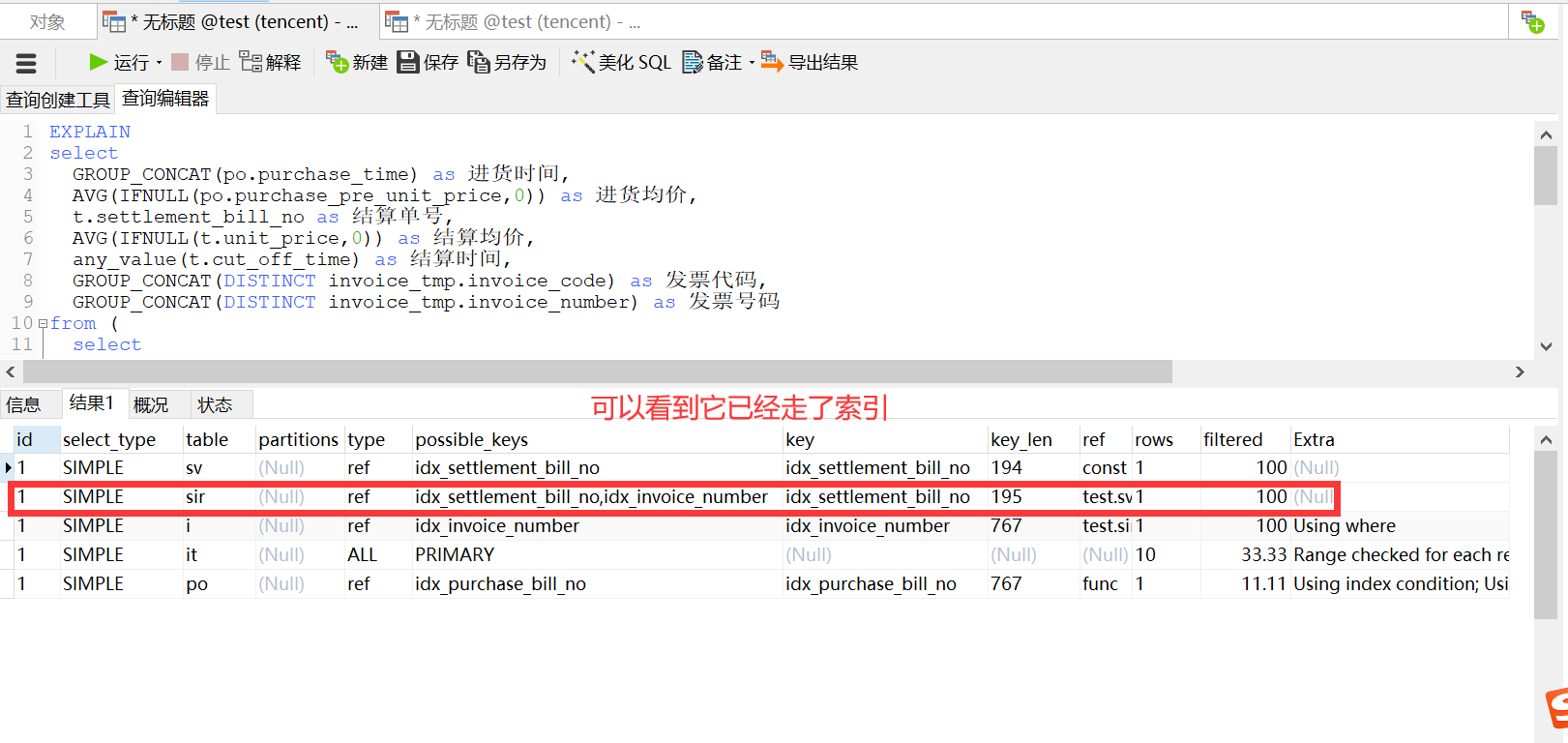
这时,基本优化结束,再看看在我的垃圾服务器上跑出的结果:
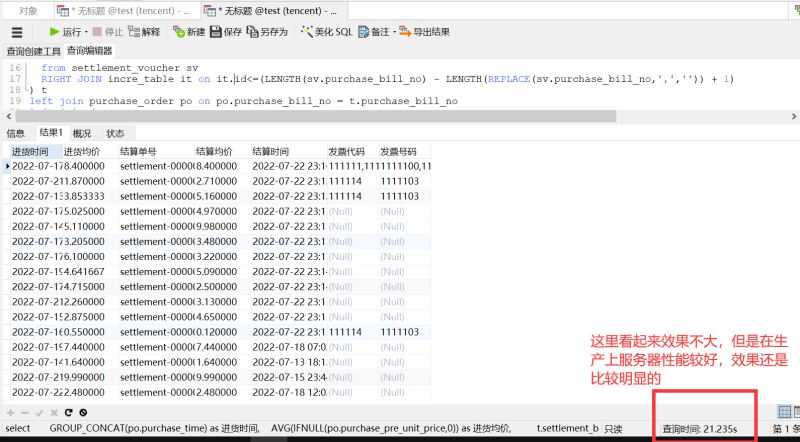
到这里,基本上生产上是可以在三秒以内查询出来了,本次SQL优化就到此结束了!!!
但是,其实还是可以继续优化的,但是设计到系统改的地方比较多了,影响面比较大,这里就说一下思路,暂时不能实践:
可以把进货单表purchase_order和进货结算单表settlement_voucher之间,建立一个中间表,实现多对多的关系,再加以索引,应该会更快,而且可以一劳永逸,以后这种关联都会比较方便了!
总结
到此这篇关于一次SQL优化实战的文章就介绍到这了,更多相关SQL优化实战内容请搜索我们以前的文章或继续浏览下面的相关文章希望大家以后多多支持我们!
相关推荐
-
SQL语句优化方法30例(推荐)
1. /*+ALL_ROWS*/ 表明对语句块选择基于开销的优化方法,并获得最佳吞吐量,使资源消耗最小化. 例如: SELECT /*+ALL+_ROWS*/ EMP_NO,EMP_NAM,DAT_IN FROM BSEMPMS WHERE EMP_NO='SCOTT'; 2. /*+FIRST_ROWS*/ 表明对语句块选择基于开销的优化方法,并获得最佳响应时间,使资源消耗最小化. 例如: SELECT /*+FIRST_ROWS*/ EMP_NO,EMP_NAM,DAT_IN FROM BS
-
SQL 优化经验总结34条
(1) 选择最有效率的表名顺序(只在基于规则的优化器中有效): ORACLE 的解析器按照从右到左的顺序处理FROM子句中的表名,FROM子句中写在最后的表(基础表 driving table)将被最先处理,在FROM子句中包含多个表的情况下,你必须选择记录条数最少的表作为基础表.如果有3个以上的表连接查询, 那就需要选择交叉表(intersection table)作为基础表, 交叉表是指那个被其他表所引用的表. (2) WHERE子句中的连接顺序.: ORACLE采用自下而上的顺序解析WHE
-
SQL语句优化之JOIN和LEFT JOIN 和 RIGHT JOIN语句的优化
在数据库的应用中,我们经常需要对数据库进行多表查询,然而当数据量非常大时多表查询会对执行效率产生非常大的影响,因此我们在使用JOIN和LEFT JOIN 和 RIGHT JOIN语句时要特别注意: SQL语句的join原理: 数据库中的join操作,实际上是对一个表和另一个表的关联,而很多错误理解为,先把这两个表来一个迪卡尔积,然后扔到内存,用where和having条件来慢慢筛选,其实数据库没那么笨的,那样会占用大量的内存,而且效率不高,比如,我们只需要的一个表的一些行和另一个表的一些行,如果
-
SQL优化之针对count、表的连接顺序、条件顺序、in及exist的优化
本文详述了SQL优化中针对count.表的连接顺序.条件顺序.in及exist的优化,非常具有实用价值!详述如下: 一.关于count 看过一些网上关于count(*)和count(列)的文章,count(列)的效率一定比count(*)高吗? 其实个人觉得count(*)和count(列)根本就没有可比性,count(*)统计的是表里面的总条数,而count(列)统计的是当列的非空记录条数. 不过我们可以通过实验来比较一下: 首先创建测试表: drop table test purge; cr
-
sql语句优化之用EXISTS替代IN、用NOT EXISTS替代NOT IN的语句
在许多基于基础表的查询中,为了满足一个条件,往往需要对另一个表进行联接.在这种情况下, 使用EXISTS(或NOT EXISTS)通常将提高查询的效率.在子查询中,NOT IN子句将执行一个内部的排序和合并.无论在哪种情况下,NOT IN都是最低效的 (因为它对子查询中的表执行了一个全表遍历).为了避免使用NOT IN ,我们可以把它改写成外连接(Outer Joins)或NOT EXISTS. 如 我要查询 Sendorder表中的冗余数据(没有和reg_person或worksite相连的数
-
SQL 优化
(一)深入浅出理解索引结构 实际上,您可以把索引理解为一种特殊的目录.微软的SQL SERVER提供了两种索引:聚集索引(clustered index,也称聚类索引.簇集索引)和非聚集索引(nonclustered index,也称非聚类索引.非簇集索引).下面,我们举例来说明一下聚集索引和非聚集索引的区别: 其实,我们的汉语字典的正文本身就是一个聚集索引.比如,我们要查"安"字,就会很自然地翻开字典的前几页,因为"安"的拼音是"an",而按照
-

记一次SQL优化的实战记录
目录 前言 1. 创建表 2. 需求 3. 给表插入数据 4. 开始根据需求写SQL 4.1 第一版 4.2 第二版 4.3 第三版 总结 前言 昨天(2022-7-22)上线了我的一个功能,测试环境数据量较小,问题不大,但是上生产之后,直接卡死了,然后就开始了这么一次SQL优化,这里记录一下. 不太方便透露公司的表结构,这里我自己建了几张表,模拟一下就可以了. 肯定有杠精要说表可以不这样设计了,但是事实现在系统就是这样设计的,如果想改动表设计,影响面就太大了(我们急着上线哦).当然,本文的后面
-
隐式转换引起的sql慢查询实战记录
引言 实在很无语呀,遇到一个mysql隐式转换问题,问了周边的dba大拿该问题,他们居然反问我,你连这个也不知道?白白跟他们混了那么长 尼玛,我还真不知道.罪过罪过-. 问题是这样的,一个字段叫task_id, 本身是varchar字符串类型,但是因为老系统时间太长了,我以为是int或者bigint,所以直接在代码写sql跑数据,结果等了好久就是没有反应,感觉要坏事呀.在mysql processlist里看到了该sql语句,直接kill掉. 该字段是有索引的,并且他的sql选择性很高,索引
-
关于Swagger优化的实战记录
目录 背景 探察&解决 一.先看看v1加载慢,却要加载两次. 二.接下来处理v1加载慢 三.将需返回json数据 四.修改Swagger页面 结语 背景 尽管.net6已经发布很久了,但是公司的项目由于种种原因依旧基于.net Framework.伴随着版本迭代,后端的api接口不断增多,每次在联调的时候,前端开发叫苦不迭:“小胖,你们的swagger页面越来越卡了,快优化优化!”. 先查看swagger页面加载耗时: 以上分别是: v1加载了两次 重新编译程序后打开swagger页面,加载v1
-
sql优化实战 把full join改为left join +union all(从5分钟降为10秒)
今天收到一个需求,要改写一个报表的逻辑,当改完之后,再次运行,发现运行超时. 因为特殊原因,无法访问客户的服务器,没办法查看sql的执行计划.没办法知道表中的索引情况,所以,尝试从语句的改写上来优化. 一.原始语句如下: select isnull(vv.customer_id,v.customer_id) as customer_id, isnull(vv.business_date,replace(v.business_date,'-','')) as business_date, v.pr
-
MySQL实战记录之如何快速定位慢SQL
目录 开启慢查询日志 系统变量 修改配置文件 设置全局变量 分析慢查询日志 mysqldumpslow pt-query-digest 用法实战 总结 开启慢查询日志 在项目中我们会经常遇到慢查询,当我们遇到慢查询的时候一般都要开启慢查询日志,并且分析慢查询日志,找到慢sql,然后用explain来分析 系统变量 MySQL和慢查询相关的系统变量如下 参数 含义 slow_query_log 是否启用慢查询日志, ON为启用,OFF为没有启用,默认为OFF log_output 日志输出位置,默
-
揭秘SQL优化技巧 改善数据库性能
优化目标 1.减少 IO 次数 IO永远是数据库最容易瓶颈的地方,这是由数据库的职责所决定的,大部分数据库操作中超过90%的时间都是 IO 操作所占用的,减少 IO 次数是 SQL 优化中需要第一优先考虑,当然,也是收效最明显的优化手段. 2.降低CPU计算 除了 IO 瓶颈之外,SQL优化中需要考虑的就是CPU运算量的优化了.order by, group by,distinct - 都是消耗 CPU 的大户(这些操作基本上都是 CPU 处理内存中的数据比较运算).当我们的 IO 优化做到一定
-
SQL优化经验总结
一. 优化SQL步骤 1. 通过 show status和应用特点了解各种 SQL的执行频率 通过 SHOW STATUS 可以提供服务器状态信息,也可以使用 mysqladmin extende d-status 命令获得. SHOW STATUS 可以根据需要显示 session 级别的统计结果和 global级别的统计结果. 如显示当前session: SHOW STATUS like "Com_%"; 全局级别:show global status; 以下几个参数
-
详细聊聊MySQL中慢SQL优化的方向
目录 前言 SQL语句优化 记录慢查询SQL 如何修改配置 查看慢查询日志 查看SQL执行计划 如何使用 SQL编写优化 为何要对慢SQL进行治理 总结 前言 影响一个系统的运行速度的原因有很多,是多方面的,甚至可能是偶然性的,或前端,或后端,或数据库,或中间件,或服务器,或网络等等等等,真正的去定位一个问题需要对系统有一定的认知,可以根据自身的判断去缩小问题范围. 今天不说其他的优化,单独把数据库的优化拿出来说几个优化方向. 跟系统的优化方向一样,数据库的优化,同样也是多方面的,其中涵盖着SQ