快速部署 Scrapy项目scrapyd的详细流程
快速部署 Scrapy项目 scrapyd
给服务端 install scrapyd
pip install scrapyd -i https://pypi.tuna.tsinghua.edu.cn/simple
运行
scrapyd

修改配置项 , 以便远程访问
使用Ctrl +c 停止 上一步的运行的scrapyd
在要运行scrapyd 命令的路径下,新建文件scrapyd.cnf 文件
输入以下内容
[scrapyd]
# 网页和Json服务监听的IP地址,默认为127.0.0.1(只有改成0.0.0.0 才能在别的电脑上能够访问scrapyd运行之后的服务器)
bind_address = 0.0.0.0
# 监听的端口,默认为6800
http_port = 6800
# 是否打开debug模式,默认为off
debug = off
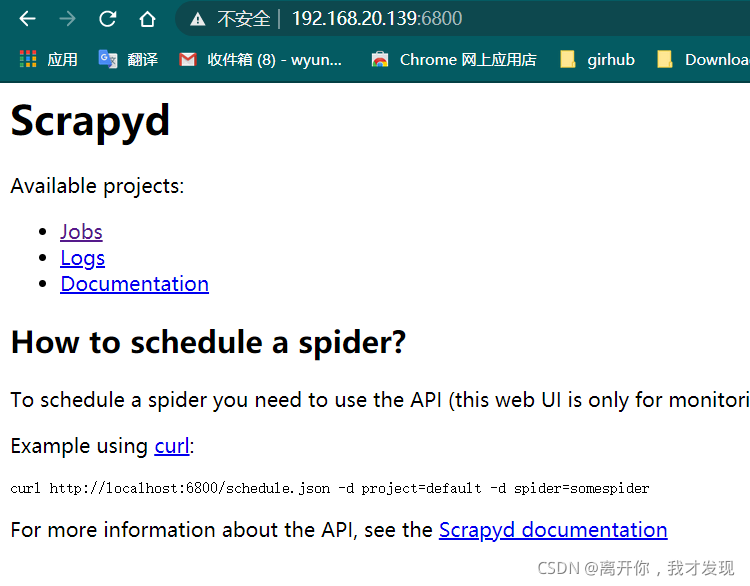
在客户端 install scrapyd-client
1. 安装 scrapy-client 命令如下
pip install scrapyd-client -i https://pypi.tuna.tsinghua.edu.cn/simple
配置Scrapy 项目
修改 scrapy.cfg 文件

1 检查配置
scrapyd-deploay -l
发布scrapy项目到scrapyd所在的服务器(此时爬虫未运行)
# scrapyd-deploy <target> -p <project> --version <version> # taget : 就是前面配置文件里的deploy后面的的target名字,例如 ubuntu1 # project: 可以随意定义, 建议与 scrapy 爬虫项目名相同 # version: 自定义版本号 不写的话默认为当前时间戳, 一般不写 scrapyd-deploy ubuntu-1 -p douban
注意
爬虫目录下不要放无关的py文件,放无关的py文件会导致发布失败,但是当爬虫发布成功后,会在当前目录生成一个setup.py文件,可以删除掉。
4.发送运行爬虫命令
curl http://10.211.55.5:6800/schedule.json -d project=douban -d spider=top250
5.停止爬虫
curl http://ip:6800/cancel.json -d project=项目名 -d job=任务的id值

curl http://10.211.55.5:6800/cancel.json -d project=douban -d job=121cc034388a11ebb1a7001c42d0a249

注意
- 如果scrapy项目代码,修改了,只需要重新发布到scrapyd所在服务器即可
- 如果scrapy项目暂停了,可以再次通过
curl的方式发送命令让其“断点续爬”
Scrapy项目部署-图形化操作Gerapy
一,说明
Gerapy 是一款国人开发的爬虫管理软件(有中文界面)是一个管理爬虫项目的可视化工具,把项目部署到管理的操作全部变为交互式,实现批量部署,更方便控制、管理、实时查看结果。
gerapy和scrapyd的关系就是,我们可以通过gerapy中配置scrapyd后,不使用命令,直接通过图形化界面开启爬虫。
二,安装
命令 (安装在 爬虫代码 上传端)
pip install gerapy -i https://pypi.tuna.tsinghua.edu.cn/simple
测试

三,使用
创建一个gerapy工作目录
gerapy init
生成文件夹,如下

创建splite 数据库, 存放部署scrapy 项目版本
gerapy migrate
创建成功之后,用tree命令,查看当前的文件列表
创建用户密码

启动服务
gerapy runserver
到此这篇关于快速部署 Scrapy项目 scrapyd的文章就介绍到这了,更多相关Scrapy项目 scrapyd内容请搜索我们以前的文章或继续浏览下面的相关文章希望大家以后多多支持我们!
相关推荐
-
scrapyd schedule.json setting 传入多个值问题
使用案例: import requests adder='http://127.0.0.1:6800' data = { 'project':'v1', 'version':'12379', 'setting':['ROBOTSTXT_OBEY=True','CONCURRENT_REQUESTS=32'] } resp = requests.post(adder,data=data) 问题解决思路: 版本1.2文档中: ◦setting (string, optional) - a Scrap
-

快速部署 Scrapy项目scrapyd的详细流程
快速部署 Scrapy项目 scrapyd 给服务端 install scrapyd pip install scrapyd -i https://pypi.tuna.tsinghua.edu.cn/simple 运行 scrapyd 修改配置项 , 以便远程访问 使用Ctrl +c 停止 上一步的运行的scrapyd 在要运行scrapyd 命令的路径下,新建文件scrapyd.cnf 文件 输入以下内容 [scrapyd] # 网页和Json服务监听的IP地址,默认为127.0.0.1(只
-
Docker快速部署SpringBoot项目介绍
1.安装 Docker 首先打开linux环境,输入以下命令进行安装: 安装 yum install docker 检查是否安装成功 docker --version #启动 systemctl start docker 如果下载很慢,可以切换到国内的阿里云镜像,进行下载: 换镜像源 sudo vim /etc/docker/daemon.json 内容如下: { "registry-mirrors": ["https://m9r2r2uj.mirror.aliyuncs.c
-
在Docker快速部署Node.js应用的详细步骤
一.前言 可能还有一些同学不了解docker这个项目,docker是由go语言编写的,一个快速部署的轻量级虚拟技术项目,他允许开发人员将自己的程序和运行环境一起打包,制作成一个docker的image(镜像),这样部署到服务器上,也只需要下载这个image就可以将程序跑起来,免去每次都安装各种依赖和环境的麻烦,还能够做到应用程序之间的隔离 二.实现准备 我会先创建一个简单的Node.js web app,来构建一个镜像.然后基于这个Image运行一个container.从而实现快速部署. 由于网
-
pycharm部署django项目到云服务器的详细流程
目录 前言 1-下载python3.8压缩包 2-解压缩安装包 3-安装依赖工具 4-安装python3.8 6-修改yum配置文件 7-配置python 8-检验配置结果 9-上传并部署Django项目 前言 大家想一想,如果要在一台电脑上运行python程序需要些什么工具呢? 显而易见,我们需要在电脑上安装python应用,配置python环境等等.那么如果我们需要在云服务器上运行python程序的话要怎么做呢?相信大家已经想到了,就是照葫芦画瓢,在云服务器上做相同的工作就好了. 1-下载p
-
一篇文章快速掌握Nginx部署前端项目(Nginx安装配置及部署都非常详细!)
目录 前言: Nginx的三个作用: 负载均衡: 反向代理: 动静分离: Nginx的下载安装(Linux环境下) Nginx的使用 三.部署前端项目 总结 前言: 之前在Linux系统中部署了后端项目,今天继续来给大家分享如何部署前端项目. 涉及到了Nginx的简单介绍以及Nginx如何安装及配置并且能够部署前端项目 Nginx是一个轻量级的反向代理web服务器,在当今应用地非常广泛,特别是前后端分离的情况下. Nginx的三个作用: 负载均衡: 当我们的单个项目访问量达到了单个tomcat无
-
docker maven plugin快速部署微服务的详细流程
目录 一.前置条件 二.部署方法 1.开放远程部署端口 3.修改application文件 4.打包上传并创建镜像 5.启动容器 三.总结 一.前置条件 linux下装好docker并启动 1.使用国内 daocloud 一键安装命令 curl -sSL https://get.daocloud.io/docker | sh 2.启动docker systemctl start docker.service 二.部署方法 1.开放远程部署端口 <1>修改 docker 的配置文件 /lib/s
-
SpringBoot应用快速部署到K8S的详细教程
欢迎访问我的GitHub https://github.com/zq2599/blog_demos 内容: 所有原创文章分类汇总及配套源码,涉及Java.Docker.Kubernetes.DevOPS等: 背景 对于生产环境,我们一般会用CI&&CD工具完成整个构建和部署,因此本文不适合生产环境:对于学习和开发环境,我们频繁修改代码,又想快速见到效果,本文就是针对这种场景的: 内容简介 如果您正在开发SpringBoot应用,并且应用部署在K8S环境,可以参考本文将应用快速部署到K8S环
-
CentOS下宝塔部署Django项目的详细教程
基础环境 装好宝塔服务 宝塔里装好[Python项目管理器] 宝塔里装好[Nginx] 把Django项目代码发到服务器 把代码放到服务器上有两种方法: 方法一:服务器上安装Git,通过Git Clone代码到服务器上 方法二:通过宝塔的FTP工具把代码上传上去 注意: 在目录:/www/wwwroot/下新建一个文件夹, 把代码需要放到新建的目录中 创建Python(Django)项目 现在我们开始创建 python 项目.打开首页的 python 项目管理器,点击 添加项目.填充数据: *
-
centos8使用Docker部署Django项目的详细教程
引言 在本文中将介绍在Docker中通过django + uwsgi + nginx部署方式部署Django项目, 由于记录的是学习过程,使用的都是目前较高的版本. python 版本为3.8.3 django 版本为3.0.6 nginx 版本为1.17.10 好了简单的介绍之后,就进入正题了. 创建一个工作目录 创建一个工作目录用来存放项目,和Dockerfile等文件. mkdir uwsgidocker 简单说明一下各个文件 docker-compose.yml: Docker
-
宝塔面板成功部署Django项目流程(图文)
上线 Django 项目记录,超简单,避免无意义的踩坑! 第一步:安装python管理器 在宝塔在线面板安装" python项目管理器 " 第二步:安装适配python版本 因为服务器 centos7 系统默认的 python 版本是 2.7 而我们项目是基于最新版 Django 来开发的,本地环境是 python2.7 的,为了尽量保证环境的相似,避免踩无意义的坑. 第三步:导出项目包到requirments.txt python 的安装时间比较长,所以先做一些别的工作,同时在 在本