Java数据结构之二叉查找树的实现
目录
- 定义
- 节点结构
- 查找算法
- 插入算法
- 删除算法
- 完整代码
定义
二叉查找树(亦称二叉搜索树、二叉排序树)是一棵二叉树,且各结点关键词互异,其中根序列按其关键词递增排列。
等价描述:二叉查找树中任一结点 P,其左子树中结点的关键词都小于 P 的关键词,右子树中结点的关键词都大于 P 的关键词,且结点 P 的左右子树也都是二叉查找树

节点结构

:one: key:关键字的值
:two: value:关键字的存储信息
:three: left:左节点的引用
:four: right:右节点的引用
class BSTNode<K extends Comparable<K>,V>{
public K key;
public V value;
public BSTNode<K,V> left;
public BSTNode<K,V> right;
}
为了代码简洁,本文不考虑属性的封装,一律设为 public
查找算法
思想:利用二叉查找树的特性,左子树值小于根节点值,右子树值大于根节点值,从根节点开始搜索
- 如果目标值等于某节点值,返回该节点
- 如果目标值小于某节点值,搜索该节点的左子树
- 如果目标值大于某节点值,搜索该节点的右子树
:one: 递归版本
public BSTNode<K, V> searchByRecursion(K key) {
return searchByRecursion(root, key);
}
private BSTNode<K, V> searchByRecursion(BSTNode<K, V> t, K key) {
if (t == null || t.key == key) return t;
else if (key.compareTo(t.key) < 0) return searchByRecursion(t.left, key);
else return searchByRecursion(t.right, key);
}
:two: 迭代版本
public BSTNode<K,V> searchByIteration(K key) {
BSTNode<K,V> p = this.root;
while(p != null) {
if(key.compareTo(p.key) < 0) p = p.left;
else if(key.compareTo(p.key) > 0) p = p.right;
else return p;
}
return null;
}
插入算法
- 在以
t为根的二叉查找树中插入关键词为key的结点 - 在
t中查找key,在查找失败处插入
:one: 递归版本
public void insertByRecursion(K key, V value) {
this.root = insertByRecursion(root, key, value);
}
private BSTNode<K, V> insertByRecursion(BSTNode<K, V> t, K key, V value) {
if (t == null) {
return new BSTNode<>(key, value);
}
else if (key.compareTo(t.key) < 0) t.left = insertByRecursion(t.left, key, value);
else if (key.compareTo(t.key) > 0) t.right = insertByRecursion(t.right, key, value);
else {
t.value = value; // 如果二叉查找树中已经存在关键字,则替换该结点的值
}
return t;
}
:two: 迭代版本
public void insertByIteration(K key, V value) {
BSTNode<K, V> p = root;
if (p == null) {
root = new BSTNode<>(key, value);
return;
}
BSTNode<K, V> pre = null;
while (p != null) {
pre = p;
if (key.compareTo(p.key) < 0) p = p.left;
else if (key.compareTo(p.key) > 0) p = p.right;
else {
p.value = value; // 如果二叉查找树中已经存在关键字,则替换该结点的值
return;
}
}
if(key.compareTo(pre.key) < 0) {
pre.left = new BSTNode<>(key, value);
} else {
pre.right = new BSTNode<>(key, value);
}
}
删除算法
在以 t 为根的二叉查找树中删除关键词值为 key 的结点
在 t 中找到关键词为 key 的结点,分三种情况删除 key
1.若 key 是叶子节点,则直接删除
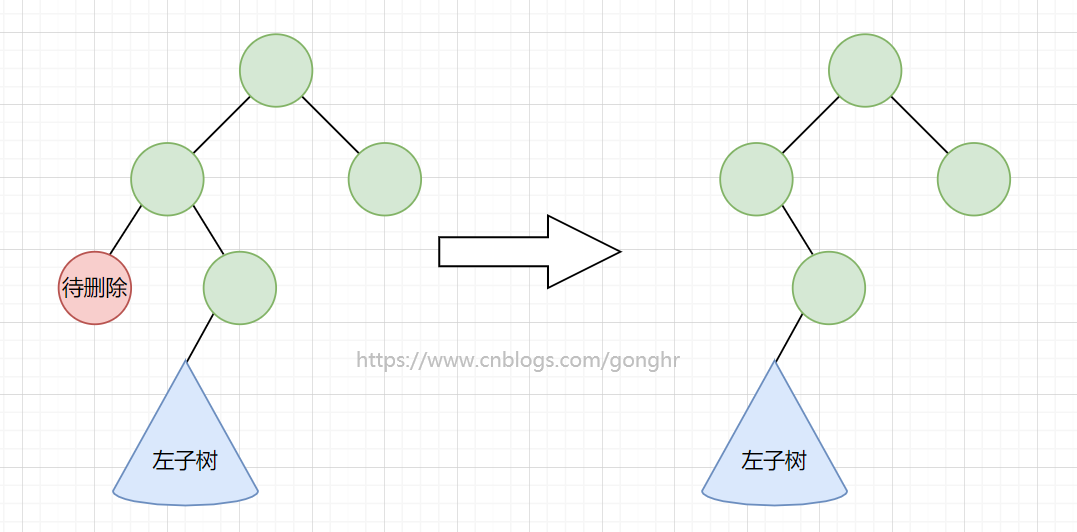
2.若 key 只有一棵子树,则子承父业

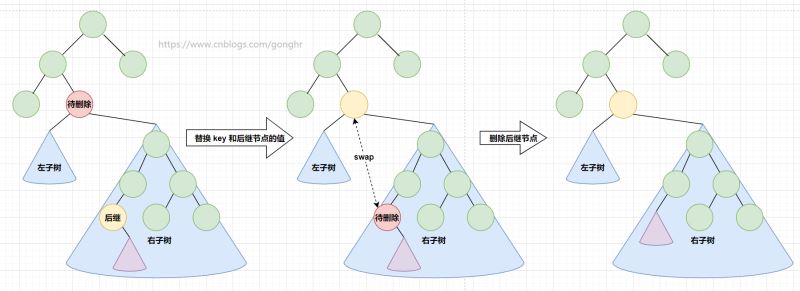
3.若 key 既有左子树也有右子树,则找到 key 的后继结点,替换 key 和后继节点的值,然后删除后继节点(后继节点只有一棵子树,转化为第二种情况)。
后继结点是当前结点的右子树的最左结点,如果右子树没有左子树,则后继节点就是右子树的根节点。

public void removeByRecursion(K key) {
this.root = removeByRecursion(root, key);
}
private BSTNode<K, V> removeByRecursion(BSTNode<K, V> t, K key) {
if(t == null) return root;
else if(t.key.compareTo(key) < 0) t.right = removeByRecursion(t.right, key); // key大,递归处理右子树
else if(t.key.compareTo(key) > 0) t.left = removeByRecursion(t.left, key); // key小,递归处理左子树
else {
if(t.right == null) return t.left; // 情况一、二一起处理
if(t.left == null) return t.right; // 情况一、二一起处理
BSTNode<K, V> node = t.right; // 情况三:右子树没有左子树
if (node.left == null) {
node.left = t.left;
} else { // 情况三:右子树有左子树
BSTNode<K, V> pre = null;
while (node.left != null) {
pre = node;
node = node.left;
}
t.key = node.key;
t.value = node.value;
pre.left = node.right;
}
}
return t;
}
完整代码
class BSTNode<K extends Comparable<K>, V> {
public K key;
public V value;
public BSTNode<K, V> left;
public BSTNode<K, V> right;
public BSTNode(K key, V value) {
this.key = key;
this.value = value;
}
}
class BSTree<K extends Comparable<K>, V> {
public BSTNode<K, V> root;
private void inorder(BSTNode<K, V> root) {
if (root != null) {
inorder(root.left);
System.out.print("(key: " + root.key + " , value: " + root.value + ") ");
inorder(root.right);
}
}
private void preorder(BSTNode<K, V> root) {
if (root != null) {
System.out.print("(key: " + root.key + " , value: " + root.value + ") ");
preorder(root.left);
preorder(root.right);
}
}
private void postorder(BSTNode<K, V> root) {
if (root != null) {
postorder(root.left);
postorder(root.right);
System.out.print("(key: " + root.key + " , value: " + root.value + ") ");
}
}
public void postorderTraverse() {
System.out.print("后序遍历:");
postorder(root);
System.out.println();
}
public void preorderTraverse() {
System.out.print("先序遍历:");
preorder(root);
System.out.println();
}
public void inorderTraverse() {
System.out.print("中序遍历:");
inorder(root);
System.out.println();
}
public BSTNode<K, V> searchByRecursion(K key) {
return searchByRecursion(root, key);
}
private BSTNode<K, V> searchByRecursion(BSTNode<K, V> t, K key) {
if (t == null || t.key == key) return t;
else if (key.compareTo(t.key) < 0) return searchByRecursion(t.left, key);
else return searchByRecursion(t.right, key);
}
public BSTNode<K, V> searchByIteration(K key) {
BSTNode<K, V> p = this.root;
while (p != null) {
if (key.compareTo(p.key) < 0) p = p.left;
else if (key.compareTo(p.key) > 0) p = p.right;
else return p;
}
return null;
}
public void insertByRecursion(K key, V value) {
this.root = insertByRecursion(root, key, value);
}
private BSTNode<K, V> insertByRecursion(BSTNode<K, V> t, K key, V value) {
if (t == null) {
return new BSTNode<>(key, value);
} else if (key.compareTo(t.key) < 0) t.left = insertByRecursion(t.left, key, value);
else if (key.compareTo(t.key) > 0) t.right = insertByRecursion(t.right, key, value);
else {
t.value = value;
}
return t;
}
public void insertByIteration(K key, V value) {
BSTNode<K, V> p = root;
if (p == null) {
root = new BSTNode<>(key, value);
return;
}
BSTNode<K, V> pre = null;
while (p != null) {
pre = p;
if (key.compareTo(p.key) < 0) p = p.left;
else if (key.compareTo(p.key) > 0) p = p.right;
else {
p.value = value; // 如果二叉查找树中已经存在关键字,则替换该结点的值
return;
}
}
if (key.compareTo(pre.key) < 0) {
pre.left = new BSTNode<>(key, value);
} else {
pre.right = new BSTNode<>(key, value);
}
}
public void removeByRecursion(K key) {
this.root = removeByRecursion(root, key);
}
private BSTNode<K, V> removeByRecursion(BSTNode<K, V> t, K key) {
if(t == null) return root;
else if(t.key.compareTo(key) < 0) t.right = removeByRecursion(t.right, key); // key大,递归处理右子树
else if(t.key.compareTo(key) > 0) t.left = removeByRecursion(t.left, key); // key小,递归处理左子树
else {
if(t.right == null) return t.left; // 情况一、二一起处理
if(t.left == null) return t.right; // 情况一、二一起处理
BSTNode<K, V> node = t.right; // 情况三:右子树没有左子树
if (node.left == null) {
node.left = t.left;
} else { // 情况三:右子树有左子树
BSTNode<K, V> pre = null;
while (node.left != null) {
pre = node;
node = node.left;
}
t.key = node.key;
t.value = node.value;
pre.left = node.right;
}
}
return t;
}
}
:bug: 方法测试:
public class Main {
public static void main(String[] args) {
BSTree<Integer, Integer> tree = new BSTree<>();
// tree.insertByRecursion(1, 1);
// tree.insertByRecursion(5, 1);
// tree.insertByRecursion(2, 1);
// tree.insertByRecursion(4, 1);
// tree.insertByRecursion(3, 1);
// tree.insertByRecursion(1, 2);
tree.insertByIteration(1, 1);
tree.insertByIteration(5, 1);
tree.insertByIteration(2, 1);
tree.insertByIteration(4, 1);
tree.insertByIteration(3, 1);
tree.insertByIteration(1, 5);
tree.removeByRecursion(4);
tree.inorderTraverse();
tree.postorderTraverse();
tree.preorderTraverse();
BSTNode<Integer, Integer> node = tree.searchByIteration(1);
System.out.println(node.key + " " + node.value);
}
}
中序遍历:(key: 1 , value: 5) (key: 2 , value: 1) (key: 3 , value: 1) (key: 5 , value: 1)
后序遍历:(key: 3 , value: 1) (key: 2 , value: 1) (key: 5 , value: 1) (key: 1 , value: 5)
先序遍历:(key: 1 , value: 5) (key: 5 , value: 1) (key: 2 , value: 1) (key: 3 , value: 1)
1 5
以上就是Java数据结构之二叉查找树的实现的详细内容,更多关于Java二叉查找树的资料请关注我们其它相关文章!
相关推荐
-
Java二叉搜索树遍历操作详解【前序、中序、后序、层次、广度优先遍历】
本文实例讲述了Java二叉搜索树遍历操作.分享给大家供大家参考,具体如下: 前言:在上一节Java二叉搜索树基础中,我们对树及其相关知识做了了解,对二叉搜索树做了基本的实现,下面我们继续完善我们的二叉搜索树. 对于二叉树,有深度遍历和广度遍历,深度遍历有前序.中序以及后序三种遍历方法,广度遍历即我们寻常所说的层次遍历,如图: 因为树的定义本身就是递归定义,所以对于前序.中序以及后序这三种遍历我们使用递归的方法实现,而对于广度优先遍历需要选择其他数据结构实现,本例中我们使用队列来实现广度优先遍历.
-

利用java实现二叉搜索树
二叉搜索树的定义 它是一颗二叉树 任一节点的左子树上的所有节点的值一定小于该节点的值 任一节点的右子树上的所有节点的值一定大于该节点的值 特点: 二叉搜索树的中序遍历结果是有序的(升序)! 实现一颗二叉搜索树 实现二叉搜索树,将实现插入,删除,查找三个方面 二叉搜索树的节点是不可以进行修改的,如果修改,则可能会导致搜索树的错误 二叉搜索树的定义类 二叉搜索树的节点类 -- class Node 二叉搜索树的属性:要找到一颗二叉搜索树只需要知道这颗树的根节点. public class BST {
-
java 二叉查找树实例代码
java 二叉查找树实例代码 1.左边<中间<右边 2.前序遍历 左中右 3.中序遍历 中左右 4.后序遍历 左右中 public class BinaryTree { // 二叉树的根节点 public TreeNode rootNode ; // 记录搜索深度 public int count; /** * 利用传入一个数组来建立二叉树 */ public BinaryTree(int[] data) { for (int i = 0; i < data. length; i++)
-
java二叉查找树的实现代码
本文实例为大家分享了java二叉查找树的具体代码,供大家参考,具体内容如下 package 查找; import edu.princeton.cs.algs4.Queue; import edu.princeton.cs.algs4.StdOut; public class BST<Key extends Comparable<Key>, Value> { private class Node { private Key key; // 键 private Value value;
-
java基础二叉搜索树图文详解
目录 概念 直接实践 准备工作:定义一个树节点的类,和二叉搜索树的类. 搜索二叉树的查找功能 搜索二叉树的插入操作 搜索二叉树删除节点的操作-难点 性能分析 总程序-模拟实现二叉搜索树 和java类集的关系 总结 概念 二叉搜索树又称二叉排序树,它或者是一棵空树,或者是具有以下性质的二叉树:1.若它的左子树不为空,则左子树上所有节点的值都小于根结点的值.2.若它的右子树不为空,则右子树上所有节点的值都大于根结点的值.3.它的左右子树也分别为二叉搜索树 直接实践 准备工作:定义一个树节点的类,和二
-
java实现 二叉搜索树功能
一.概念 二叉搜索树也成二叉排序树,它有这么一个特点,某个节点,若其有两个子节点,则一定满足,左子节点值一定小于该节点值,右子节点值一定大于该节点值,对于非基本类型的比较,可以实现Comparator接口,在本文中为了方便,采用了int类型数据进行操作. 要想实现一颗二叉树,肯定得从它的增加说起,只有把树构建出来了,才能使用其他操作. 二.二叉搜索树构建 谈起二叉树的增加,肯定先得构建一个表示节点的类,该节点的类,有这么几个属性,节点的值,节点的父节点.左节点.右节点这四个属性,代码如下 sta
-
Java数据结构之二叉查找树的实现
目录 定义 节点结构 查找算法 插入算法 删除算法 完整代码 定义 二叉查找树(亦称二叉搜索树.二叉排序树)是一棵二叉树,且各结点关键词互异,其中根序列按其关键词递增排列. 等价描述:二叉查找树中任一结点 P,其左子树中结点的关键词都小于 P 的关键词,右子树中结点的关键词都大于 P 的关键词,且结点 P 的左右子树也都是二叉查找树 节点结构 :one: key:关键字的值 :two: value:关键字的存储信息 :three: left:左节点的引用 :four: right:右节点的引用
-
Java数据结构之平衡二叉树的实现详解
目录 定义 结点结构 查找算法 插入算法 LL 型 RR 型 LR 型 RL 型 插入方法 删除算法 概述 实例分析 代码 完整代码 定义 动机:二叉查找树的操作实践复杂度由树高度决定,所以希望控制树高,左右子树尽可能平衡. 平衡二叉树(AVL树):称一棵二叉查找树为高度平衡树,当且仅当或由单一外结点组成,或由两个子树形 Ta 和 Tb 组成,并且满足: |h(Ta) - h(Tb)| <= 1,其中 h(T) 表示树 T 的高度 Ta 和 Tb 都是高度平衡树 即:每个结点的左子树和右子树的高
-
Java数据结构与算法入门实例详解
第一部分:Java数据结构 要理解Java数据结构,必须能清楚何为数据结构? 数据结构: Data_Structure,它是储存数据的一种结构体,在此结构中储存一些数据,而这些数据之间有一定的关系. 而各数据元素之间的相互关系,又包括三个组成成分,数据的逻辑结构,数据的存储结构和数据运算结构. 而一个数据结构的设计过程分成抽象层.数据结构层和实现层. 数据结构在Java的语言体系中按逻辑结构可以分为两大类:线性数据结构和非线性数据结构. 一.Java数据结构之:线性数据结构 线性数据结构:常见的
-
Java数据结构学习之树
一.树 1.1 概念 与线性表表示的一一对应的线性关系不同,树表示的是数据元素之间更为复杂的非线性关系. 直观来看,树是以分支关系定义的层次结构. 树在客观世界中广泛存在,如人类社会的族谱和各种社会组织机构都可以用树的形象来表示. 简单来说,树表示的是1对多的关系. 定义(逻辑结构): 树(Tree)是n( n>=0 )个结点的有限集合,没有结点的树称为空树,在任意一颗非空树中: 有且仅有一个特定的称为根(root)的结点 . 当n>1的时,其余结点可分为 m( m>0 ) 个互不相交的
-
Java数据结构之实现跳表
1.跳表的定义 跳跃表是一种随机化数据结构,基于并联的链表,其效率可比拟于二叉查找树(对于大多数操作需要O(log n)平均时间),并且对并发算法友好. SkipList(跳表)是一种可以代替平衡树的数据结构,默认是按照Key值升序的.SkipList让已排序的数据分布在多层链表中,以0-1随机数决定一个数据的向上攀升与否,通过"空间来换取时间"的一个算法,在每个节点中增加了向前的指针,在插入.删除.查找时可以忽略一些不可能涉及到的结点,从而提高了效率. 在Java的API中已经有了实
-
Java数据结构之二叉排序树的实现
目录 1 二叉排序树的概述 2 二叉排序树的构建 2.1 类架构 2.2 查找的方法 2.3 插入的方法 2.4 查找最大值和最小值 2.5 删除的方法 3 二叉排序树的总结 1 二叉排序树的概述 本文没有介绍一些基础知识.对于常见查找算法,比如顺序查找.二分查找.插入查找.斐波那契查找还不清楚的,可以看这篇文章:常见查找算法详解以及Java代码的实现. 假设查找的数据集是普通的顺序存储,那么插入操作就是将记录放在表的末端,给表记录数加一即可,删除操作可以是删除后,后面的记录向前移,也可以是要删
-
Java 数据结构与算法系列精讲之红黑树
目录 概述 红黑树 红黑树的实现 Node类 添加元素 左旋 右旋 完整代码 概述 从今天开始, 小白我将带大家开启 Java 数据结构 & 算法的新篇章. 红黑树 红黑树 (Red Black Tree) 是一种自平衡二叉查找树. 如图: 红黑树的特征: 研究红黑树的每个节点都是由颜色的, 非黑即红 根节点为黑色 每个叶子节点都是黑色的 如果一个子节点是红色的, 那么它的孩子节点都是黑色的 从任何一个节点到叶子节点, 经过的黑色节点是一样的 红黑树的实现 Node 类 // Node类 pri
-
Java数据结构超详细分析二叉搜索树
目录 1.搜索树的概念 2.二叉搜索树的简单实现 2.1查找 2.2插入 2.3删除 2.4修改 3.二叉搜索树的性能 1.搜索树的概念 二叉搜索树是一种特殊的二叉树,又称二叉查找树,二叉排序树,它有几个特点: 如果左子树存在,则左子树每个结点的值均小于根结点的值. 如果右子树存在,则右子树每个结点的值均大于根结点的值. 中序遍历二叉搜索树,得到的序列是依次递增的. 二叉搜索树的左右子树均为二叉搜索树. 二叉搜索树的结点的值不能发生重复. 2.二叉搜索树的简单实现 我们来简单实现以下搜索树,就不
-
Java数据结构之红黑树的原理及实现
目录 为什么要有红黑树这种数据结构 红黑树的简介 红黑树的基本操作之旋转 红黑树之添加元素 红黑树之删除结点 删除结点没有儿子的情况 删除结点仅有一个儿子结点的情况 删除结点有两个儿子结点 红黑树动态可视化网站 红黑树参考代码 为什么要有红黑树这种数据结构 我们知道ALV树是一种严格按照定义来实现的平衡二叉查找树,所以它查找的效率非常稳定,为O(log n),由于其严格按照左右子树高度差不大于1的规则,插入和删除操作中需要大量且复杂的操作来保持ALV树的平衡(左旋和右旋),因此ALV树适用于大量
-
Java数据结构之有效队列定义与用法示例
本文实例讲述了Java数据结构之有效队列定义与用法.分享给大家供大家参考,具体如下: /** * @描述 有序对列 * 从任何位置插入数据都是有序的 * @项目名称 Java_DataStruct * @包名 com.java.stack * @类名 Queue * @author chenlin */ public class SequeQueue { private long[] arr; private int maxSize;// 最大空间 private int len;// 有效长度