Python机器学习入门(四)选择模型
目录
- 1.数据分离与验证
- 1.1分离训练数据集和评估数据集
- 1.2K折交叉验证分离
- 1.3弃一交叉验证分离
- 1.4重复随机分离评估数据集与训练数据集
- 2.算法评估
- 2.1分类算法评估
- 2.1.1分类准确度
- 2.1.2分类报告
- 2.2回归算法评估
- 2.2.1平均绝对误差
- 2.2.2均方误差
- 2.2.3判定系数(
)
- 总结
1.数据分离与验证
要知道算法模型对未知的数据表现如何,最好的评估办法是利用已经明确知道结果的数据运行生成的算法模型进行验证。此外还可以使用新的数据来评估算法模型。
在评估机器学习算法时,不将训练集直接作为评估数据集最直接的原因就是过度拟合。过度拟合是指为了得到一致性假设而变得过度严格,简单来说就是指模型仅对训练数据有较好的效果,而对于新数据则适应性很差。
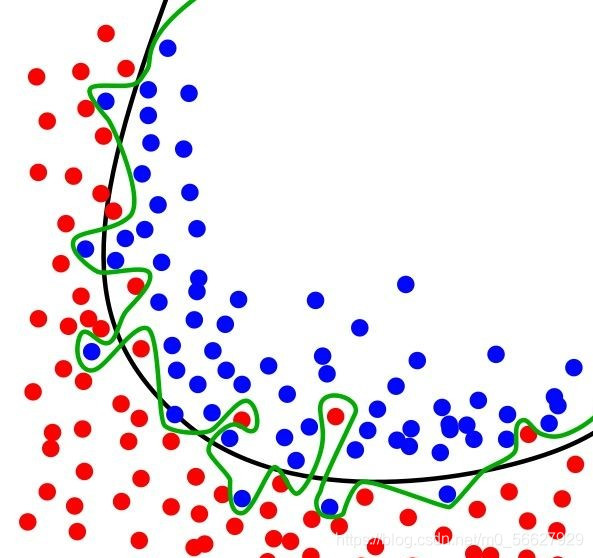
如图所示是一个分类实例,绿色曲线表示过拟合,黑色曲线表示正常模型。可以看到过拟合模型仅对当前数据表现较好,而对新数据适应性明显不如正常模型。
接下来将讲解四种不同的分离数据集的方法,用来分离训练集和评估集,并用其评估算法模型。
1.1分离训练数据集和评估数据集
可以简单地将原始数据集分为两部分,第一部分用来训练算法生成模型,第二部分通过模型来预测结果,并于已知的结果进行比较,来评估算法模型的准确度。
from pandas import read_csv
from sklearn.model_selection import train_test_split
from sklearn.linear_model import LogisticRegression
from sklearn.model_selection import KFold
from sklearn.model_selection import cross_val_score
from sklearn.linear_model import LogisticRegression
from sklearn.model_selection import LeaveOneOut
from sklearn.model_selection import ShuffleSplit
filename = 'pima_data.csv'
names = ['preg', 'plas', 'pres', 'skin', 'test', 'mass', 'pedi', 'age', 'class']
data = read_csv(filename, names=names)
# print(data.head(10))
array = data.values
X = array[:, 0:8]
Y = array[:, 8]
test_size = 0.33
seed = 4
X_train, X_test, Y_train, Y_test = train_test_split(X, Y, test_size=test_size, random_state=seed)
model = LogisticRegression(max_iter=3000)
model.fit(X_train, Y_train)
result = model.score(X_test, Y_test)
print("算法评估结果:%3f%%" % (result * 100))
执行后得到的结果约为80%。为了让算法模型具有良好的可复用性,在指定了分离数据大小的同时,还指定了随机粒度(seed=4),将数据随即进行分离。通过指定随机的粒度,可以确保每次执行程序得到相同的结果,这有助于比较两个不同的算法生成模型的结果。
算法评估结果:80.314961%
1.2K折交叉验证分离
K折交叉验证是将原始数据分成K组(一般是均分),将第一部分作为测试集,其余作为训练集,训练模型,计算模型在测试集上的准确率,每次用不同部分作为测试集,重复上述步骤K次,最后将平均准确率作为最终的模型准确率。
# K折交叉验证分离
num_folds = 10
seed = 7
kfold = KFold(n_splits=num_folds, random_state=seed,shuffle=True)
model = LogisticRegression(max_iter=3000)
result = cross_val_score(model, X, Y, cv=kfold)
print("算法评估结果:%.3f%% (%.3f%%)" % (result.mean() * 100, result.std() * 100))
执行后得到评估得分及标准方差。
算法评估结果:77.216% (4.968%)
1.3弃一交叉验证分离
相较于K折交叉验证分离,弃一交叉验证有显著优点:
- 每一回合中几乎所有样本你皆用于训练模型,因此最接近原始样本的分布,这样评估所得的结果比较可靠。
- 实验过程中没有随机因素会影响实验数据,确保实验过程可重复。
但弃一交叉验证计算成本高,当原始数据样本数量多时,弃一交叉验证需要花费大量时间完成评估。
# 弃一交叉验证分离
# 计算量非常大!!
loocv = LeaveOneOut()
model = LogisticRegression(max_iter=3000)
result = cross_val_score(model,X,Y,cv = loocv)
print("算法评估结果:%.3f%% (%.3f%%)"% (result.mean()*100,result.std()*100))
运算得出的标准方差与K折交叉验证有较大差距。
算法评估结果:77.604% (41.689%)
1.4重复随机分离评估数据集与训练数据集
另外一种K折交叉验证的用途是随即分离数据为训练数据集和评估数据集。
n_splits = 10
test_size = 0.33
seed = 7
kfold = ShuffleSplit(n_splits=n_splits, test_size=test_size, random_state=seed)
model = LogisticRegression(max_iter=3000)
result = cross_val_score(model, X, Y, cv=kfold)
print("算法评估结果:%.3f%% (%.3f%%)" % (result.mean() * 100, result.std() * 100))
算法评估结果:76.535% (2.235%)
2.算法评估
2.1分类算法评估
2.1.1分类准确度
分类准确度就是算法自动分类正确的样本数除以所有的样本数得出的结果。准确度是一个很好、很直观的评价指标,但是有时候准确度高并不代表算法就一定好。
from pandas import read_csv
import pandas as pd
from sklearn.model_selection import KFold
from sklearn.model_selection import cross_val_score
#分类准确度
filename = 'pima_data.csv'
names = ['preg', 'plas', 'pres', 'skin', 'test', 'mass', 'pedi', 'age', 'class']
data = read_csv(filename,names=names)
#print(data.head(10))
#将数据分为输入数据和输出结果
array = data.values
X = array[:,0:8]
Y = array[:,8]
num_folds = 10
seed = 7
kfold = KFold(n_splits=num_folds,random_state=seed,shuffle=True)
model = LogisticRegression(max_iter=3000)
result = cross_val_score(model, X,Y,cv=kfold)
print("算法评估结果准确度:%.3f(%.3f)" % (result.mean(),result.std()))
算法评估结果准确度:0.772(0.050)
2.1.2分类报告
在scikit-learn中提供了一个非常方便的工具,可以给出对分类问题的评估报告,Classification__report()方法能够给出precision,recall,F1-score,support。
from pandas import read_csv import pandas as pd from sklearn.model_selection import KFold from sklearn.metrics import classification_report #分类准确度 filename = 'pima_data.csv' names = ['preg', 'plas', 'pres', 'skin', 'test', 'mass', 'pedi', 'age', 'class'] data = read_csv(filename,names=names) print(data.head(10)) #将数据分为输入数据和输出结果 array = data.values X = array[:,0:8] Y = array[:,8] num_folds = 10 seed = 7 kfold = KFold(n_splits=num_folds,random_state=seed,shuffle=True) model = LogisticRegression(max_iter=3000) model.fit(X_train,Y_train) predicted = model.predict(X_test) report = classification_report(Y_test, predicted) print(report)
precision recall f1-score support
0.0 0.84 0.87 0.86 171
1.0 0.71 0.66 0.69 83
accuracy 0.80 254
macro avg 0.78 0.77 0.77 254
weighted avg 0.80 0.80 0.80 254
2.2回归算法评估
回归算法评估将使用波士顿房价(Boston House Price)数据集。可通过百度网盘下载
链接:https://pan.baidu.com/s/1uyDiXDC-ixfBIYmTU9rrAQ
提取码:eplz
2.2.1平均绝对误差
平均绝对误差是所有单个观测值与算术平均值偏差绝对值的平均值。平均绝对误差相比于平均误差能更好地反映预测值误差的实际情况。
cross_val_score中的scoring参数详解可见官方开发文档
https://scikit-learn.org/stable/modules/model_evaluation.html#scoring-parameter
from pandas import read_csv
from sklearn.model_selection import KFold
from sklearn.model_selection import cross_val_score
from sklearn.linear_model import LinearRegression
filename = 'housing.csv'
names = ['CRIM','ZN','INDUS','CHAS','NOX','RM','AGE','DIS','RAD','TAX','PRTATIO','B','LSTAT','MEDV']
data = read_csv(filename,names=names,delim_whitespace=True)
array = data.values
X = array[:,0:13]
Y = array[:,13]
n_splits = 10
seed = 7
kfold = KFold(n_splits=n_splits,random_state=seed,shuffle=True)
model = LinearRegression()
#平均绝对误差
scoring = 'neg_mean_absolute_error'
result = cross_val_score(model, X, Y, cv=kfold, scoring=scoring)
print('MAE:%.3f(%.3f)'% (result.mean(),result.std()))
MAE:-3.387(0.667)
2.2.2均方误差
均方误差是衡量平均误差的方法,可以评价数据的变化程度。均方根误差是均方误差的算术平均跟。均方误差越小,说明用该预测模型描述实验数据准确度越高。
#均方误差
scoring = 'neg_mean_squared_error'
result = cross_val_score(model, X, Y, cv=kfold, scoring=scoring)
print('MSE:%.3f(%.3f)'% (result.mean(),result.std()))
MSE:-23.747(11.143)
2.2.3判定系数()
判定系数(coefficient of determination),也叫可决系数或决定系数,是指在线性回归中,回归平方和与总离差平方和之比值,其数值等于相关系数的平方。
#决定系数
scoring = 'r2'
result = cross_val_score(model, X, Y, cv=kfold, scoring=scoring)
print('R2:%.3f(%.3f)'% (result.mean(),result.std()))
R2:0.718(0.099)
总结
K折交叉验证是用来评估机器学习算法的黄金准则。黄金准则为:当不知如何选择分离数据集的方法时,选择K折交叉验证来分离数据集;当不知如何设定K值时,将K设为10。
到此这篇关于Python机器学习入门(四)选择模型的文章就介绍到这了,更多相关Python机器学习内容请搜索我们以前的文章或继续浏览下面的相关文章希望大家以后多多支持我们!
相关推荐
-

Python机器学习入门(五)算法审查
目录 1.审查分类算法 1.1线性算法审查 1.1.1逻辑回归 1.1.2线性判别分析 1.2非线性算法审查 1.2.1K近邻算法 1.2.2贝叶斯分类器 1.2.4支持向量机 2.审查回归算法 2.1线性算法审查 2.1.1线性回归算法 2.1.2岭回归算法 2.1.3套索回归算法 2.1.4弹性网络回归算法 2.2非线性算法审查 2.2.1K近邻算法 2.2.2分类与回归树 2.2.3支持向量机 3.算法比较 总结 程序测试是展现BUG存在的有效方式,但令人绝望的是它不足以展现其缺位. --
-
Python机器学习入门(三)数据准备
目录 1.数据预处理 1.1调整数据尺度 1.2正态化数据 1.3标准化数据 1.4二值数据 2.数据特征选定 2.1单变量特征选定 2.2递归特征消除 2.3数据降维 2.4特征重要性 总结 特征选择时困难耗时的,也需要对需求的理解和专业知识的掌握.在机器学习的应用开发中,最基础的是特征工程. --吴恩达 1.数据预处理 数据预处理需要根据数据本身的特性进行,有缺失的要填补,有无效的要剔除,有冗余维的要删除,这些步骤都和数据本身的特性紧密相关. 1.1调整数据尺度 如果数据的各个属性按照不同的
-
Python机器学习入门(二)数据理解
目录 1.数据导入 1.1使用标准Python类库导入数据 1.2使用Numpy导入数据 1.3使用Pandas导入数据 2.数据理解 2.1数据基本属性 2.1.1查看前10行数据 2.1.2查看数据维度,数据属性和类型: 2.1.3查看数据描述性统计 2.2数据相关性和分布分析 2.2.1数据相关矩阵 2.2.2数据分布分析 3.数据可视化 3.1单一图表 3.1.1直方图 3.1.2密度图 3.1.3箱线图 3.2多重图表 3.2.1相关矩阵图 3.2.2散点矩阵图 总结 统计学是什么?概
-
Python机器学习入门(一)序章
目录 前言 写在前面 1.什么是机器学习? 1.1 监督学习 1.2无监督学习 2.Python中的机器学习 3.必须环境安装 Anacodna安装 总结 前言 每一次变革都由技术驱动.纵观人类历史,上古时代,人类从采集狩猎社会,进化为农业社会:由农业社会进入到工业社会:从工业社会到现在信息社会.每一次变革,都由新技术引导. 在历次的技术革命中,一个人.一家企业,甚至一个国家,可以选择的道路只有两条:要么加入时代的变革,勇立潮头:要么徘徊观望,抱憾终生. 要想成为时代弄潮儿,就要积极拥抱这次智能
-
Python机器学习入门(六)优化模型
目录 1.集成算法 1.1袋装算法 1.1.1袋装决策树 1.1.2随机森林 1.1.3极端随机树 1.2提升算法 1.2.1AdaBoost 1.2.2随机梯度提升 1.3投票算法 2.算法调参 2.1网络搜索优化参数 2.2随机搜索优化参数 总结 有时提升一个模型的准确度很困难.你会尝试所有曾学习过的策略和算法,但模型正确率并没有改善.这时你会觉得无助和困顿,这也正是90%的数据科学家开始放弃的时候.不过,这才是考验真正本领的时候!这也是普通的数据科学家和大师级数据科学家的差距所在. 1.集
-
Python机器学习入门(四)选择模型
目录 1.数据分离与验证 1.1分离训练数据集和评估数据集 1.2K折交叉验证分离 1.3弃一交叉验证分离 1.4重复随机分离评估数据集与训练数据集 2.算法评估 2.1分类算法评估 2.1.1分类准确度 2.1.2分类报告 2.2回归算法评估 2.2.1平均绝对误差 2.2.2均方误差 2.2.3判定系数() 总结 1.数据分离与验证 要知道算法模型对未知的数据表现如何,最好的评估办法是利用已经明确知道结果的数据运行生成的算法模型进行验证.此外还可以使用新的数据来评估算法模型. 在评估机器学习
-
Python机器学习入门(四)之Python选择模型
目录 1.数据分离与验证 1.1分离训练数据集和评估数据集 1.2K折交叉验证分离 1.3弃一交叉验证分离 1.4重复随机分离评估数据集与训练数据集 2.算法评估 2.1分类算法评估 2.1.1分类准确度 2.1.2分类报告 2.2回归算法评估 2.2.1平均绝对误差 2.2.2均方误差 2.2.3判定系数() 1.数据分离与验证 要知道算法模型对未知的数据表现如何,最好的评估办法是利用已经明确知道结果的数据运行生成的算法模型进行验证.此外还可以使用新的数据来评估算法模型. 在评估机器学习算法时
-
Python机器学习入门(六)之Python优化模型
目录 1.集成算法 1.1袋装算法 1.1.1袋装决策树 1.1.2随机森林 1.1.3极端随机树 1.2提升算法 1.2.1AdaBoost 1.2.2随机梯度提升 1.3投票算法 2.算法调参 2.1网络搜索优化参数 2.2随机搜索优化参数 总结 有时提升一个模型的准确度很困难.你会尝试所有曾学习过的策略和算法,但模型正确率并没有改善.这时你会觉得无助和困顿,这也正是90%的数据科学家开始放弃的时候.不过,这才是考验真正本领的时候!这也是普通的数据科学家和大师级数据科学家的差距所在. 1.集
-
Python机器学习入门(五)之Python算法审查
目录 1.审查分类算法 1.1线性算法审查 1.1.1逻辑回归 1.1.2线性判别分析 1.2非线性算法审查 1.2.1K近邻算法 1.2.2贝叶斯分类器 1.2.3分类与回归树 1.2.4支持向量机 2.审查回归算法 2.1线性算法审查 2.1.1线性回归算法 2.1.2岭回归算法 2.1.3套索回归算法 2.1.4弹性网络回归算法 2.2非线性算法审查 2.2.1K近邻算法 2.2.2分类与回归树 2.2.3支持向量机 3.算法比较 总结 程序测试是展现BUG存在的有效方式,但令人绝望的是它
-
Python机器学习入门(三)之Python数据准备
目录 1.数据预处理 1.1调整数据尺度 1.2正态化数据 1.3标准化数据 1.4二值数据 2.数据特征选定 2.1单变量特征选定 2.2递归特征消除 2.3数据降维 2.4特征重要性 总结 特征选择时困难耗时的,也需要对需求的理解和专业知识的掌握.在机器学习的应用开发中,最基础的是特征工程. --吴恩达 1.数据预处理 数据预处理需要根据数据本身的特性进行,有缺失的要填补,有无效的要剔除,有冗余维的要删除,这些步骤都和数据本身的特性紧密相关. 1.1调整数据尺度 如果数据的各个属性按照不同的