手把手带你用python爬取小姐姐私房照
目录
- 如何用Python搞到小姐姐私房照
- 目标站点
- 开发环境
- 效果预览
- 正式教程
- 一、第三方库安装
- 二、爬虫的基本套路
- 分析目标站点
- 请求网站获取数据
- 解析数据
- 保存数据
- 写在最后
如何用Python搞到小姐姐私房照
本文纯技术角度出发,教你如何用Python爬虫获取百度图库海量照片——技术无罪。
学会获取小姐姐私房照同理可得也能获取其他的照片,技术原理是一致的。
目标站点
百度图片使用关键字搜索 小姐姐私房照
https://image.baidu.com/
开发环境
- 系统:Windows10 64位
- Python版本:Python3.6.5(Python3以上版本即可)
- IDE:Pycharm(非必须,其实你完全可以记事本写代码)
- 第三方库:requests、jsonpath
效果预览
网页私房照

代码爬取效果

正式教程
一、第三方库安装
在确保你正确安装了Python解释器之后,我们还需要安装几个第三方库,命令如下**[在终端中安装即可]**:
HTTP请求库:
pip3 install requests
JSON数据解析库:
pip3 install jsonpath
二、爬虫的基本套路
- 不管是爬取哪类网站,在爬虫中基本都遵循以下的基本套路:
请求数据 → 获取响应内容 → 解析内容 → 保存数据

- 当然,以上步骤是代码的编写思路,实际操作中应该还要添加一个前置步骤,所以完整流程如下:
分析目标站点 → 请求网站获取数据 → 解析内容 → 保存数据
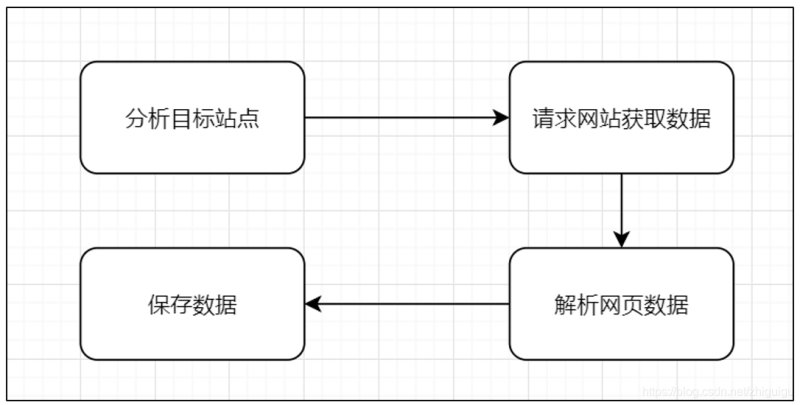
分析目标站点
快速的分析目标站点就很容易发现百度图库的图片资源是通过AJAX加载的,所以我们要请求的链接并非浏览器地址栏链接,而是ajax加载的数据包的资源路径,如图:

那么问题来了,如何获取到这些数据包的地址?其实很简单,如图所示:

请求网站获取数据
编写代码请求资源,这里有一点需要注意:请求头必须携带,否则有可能请求失败导致报错。
import requests # 导包
# 构建请求头,把爬虫程序伪装成正常的浏览器用户
headers = {
'sec-fetch-dest': 'image',
'Host': 'image.baidu.com',
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/89.0.4389.82 Safari/537.36 Edg/89.0.774.50',
}
# 资源包的url链接
url = 'https://image.baidu.com/search/acjson?tn=resultjson_com&logid=10913526997707526921&ipn=rj&ct=201326592&is=&fp=result&queryWord=%E5%B0%8F%E5%A7%90%E5%A7%90%E7%A7%81%E6%88%BF%E7%85%A7&cl=2&lm=-1&ie=utf-8&oe=utf-8&adpicid=&st=-1&z=&ic=&hd=&latest=©right=&word=%E5%B0%8F%E5%A7%90%E5%A7%90%E7%A7%81%E6%88%BF%E7%85%A7&s=&se=&tab=&width=&height=&face=0&istype=2&qc=&nc=1&fr=&expermode=&force=&pn=210&rn=30&gsm=d2&1616553658252='
# 构建请求
response = requests.get(url,headers=headers)
# 查看状态码
print(response.status_code)
# 获取原始数据
response.json()
解析数据
上述代码最终获取到的数据是json数据,也就是我们Python中常说的字典,它长这样:
{
"queryEnc":"%D0%A1%BD%E3%BD%E3%CB%BD%B7%BF%D5%D5",
"queryExt":"小姐姐私房照",
"listNum":758,
"displayNum":8392,
"gsm":"f0",
"bdFmtDispNum":"约8,390",
"bdSearchTime":"",
"isNeedAsyncRequest":0,
"bdIsClustered":"1",
"data":[
Object{...}, # 没张私房照对应的详细信息,其中就有图片的URL
Object{...},
···
}
既然它是一个字典,我们当然是可以使用Python中的键值索引方式获取到想要的数据,但是此方法太笨,这里介绍一种更加高明的方式,使用jsonpath解析数据
# 这一行代码便可以获取到所有图片的URL,返回的是一个列表,遍历即可拿到每一个URL imgs = jsonpath.jsonpath(json_data, '$..middleURL')
使用requests请求图片URL,获取图片数据
image_data = requests.get(page_url).content
保存数据
使用Python中的文件对象,保存图片,图片名字使用时间戳命名,避免图片重名
with open('imgs/' + datetime.now().strftime("%Y%m%d%H%M%S%f") + '.jpg', 'wb') as f:
f.write(image_data)
写在最后
到这整个儿爬虫程序就写完了。
当然,当前的这个只能爬取一个资源包中的数据,要爬取多个资源包或者说全部资源包的数据也是很简单的,只需要分析分析资源包的URL变化规律就不难发现其中的某个关键字变化,灵活改变该关键字就可以不断爬取。
文章正文到这里已经结束了,只是想感谢一些阅读我文章的人。
我退休后一直在学习如何写文章,说实在的,每次我在后台看到一些读者的回应就会觉得很欣慰,于是我想把我收藏的一些编程干货贡献给大家,回馈每一个读者,希望能帮到你们。
到此这篇关于手把手带你用python爬取小姐姐私房照的文章就介绍到这了,更多相关python爬取图片内容请搜索我们以前的文章或继续浏览下面的相关文章希望大家以后多多支持我们!
相关推荐
-

Python爬取网站图片并保存的实现示例
先看看结果吧,去bilibili上拿到的图片=-= 第一步,导入模块 import requests from bs4 import BeautifulSoup requests用来请求html页面,BeautifulSoup用来解析html 第二步,获取目标html页面 hd = {'user-agent': 'chrome/10'} # 伪装自己是个(chrome)浏览器=-= def download_all_html(): try: url = 'https://www.bilibili
-
Python使用xpath实现图片爬取
高性能异步爬虫 目的:在爬虫中使用异步实现高性能的数据爬取操作 异步爬虫的方式: - 多线程.多进程(不建议): 好处:可以为相关阻塞的操作单独开启多线程或进程,阻塞操作就可以异步执行; 弊端:无法无限制的开启多线程或多进程. - 线程池.进程池(适当的使用): 好处:我们可以降低系统对进程或线程创建和销毁的一个频率,从而很好的降低系统的开销: 弊端:池中线程或进程的数据是有上限的. 代码如下 # _*_ coding:utf-8 _*_ """ @FileName :6.4
-
Python爬虫实战之使用Scrapy爬取豆瓣图片
使用Scrapy爬取豆瓣某影星的所有个人图片 以莫妮卡·贝鲁奇为例 1.首先我们在命令行进入到我们要创建的目录,输入 scrapy startproject banciyuan 创建scrapy项目 创建的项目结构如下 2.为了方便使用pycharm执行scrapy项目,新建main.py from scrapy import cmdline cmdline.execute("scrapy crawl banciyuan".split()) 再edit configuration 然后
-
python制作微博图片爬取工具
有小半个月没有发博客了,因为一直在研究python的GUI,买了一本书学习了一些基础,用我所学做了我的第一款GUI--微博图片爬取工具.本软件源代码已经放在了博客中,另外软件已经打包好上传到网盘中以供下载学习. 一.准备工作 本次要用到以下依赖库:re json os random tkinter threading requests PIL 其中后两个需要安装后使用 二.预览 1.启动 2.运行中 3.结果 这里只将拿一张图片作为展示. 三.设计流程 设计流程分为总体设计和详细设计,这里我会使
-
Python爬虫之教你利用Scrapy爬取图片
Scrapy下载图片项目介绍 Scrapy是一个适用爬取网站数据.提取结构性数据的应用程序框架,它可以通过定制化的修改来满足不同的爬虫需求. 使用Scrapy下载图片 项目创建 首先在终端创建项目 # win4000为项目名 $ scrapy startproject win4000 该命令将创建下述项目目录. 项目预览 查看项目目录 win4000 win4000 spiders __init__.py __init__.py items.py middlewares.py pipelines
-
python绕过图片滑动验证码实现爬取PTA所有题目功能 附源码
最近学了python爬虫,本着学以致用的态度去应用在生活中.突然发现算法的考试要来了,范围就是PTA刷过的题.让我一个个复制粘贴?不可能,必须爬它! 先开页面,人傻了,PTA的题目是异步加载的,爬了个寂寞(空数据).AJAX我又不熟,突然想到了selenium. selenium可以模拟人的操作让浏览器自动执行动作,具体的自己去了解,不多说了.干货来了: 登录界面有个图片的滑动验证码 破解它的最好方式就是用opencv,opencv巨强,自己了解. 思路开始: 1.将背景图片和可滑动的图片下载
-
利用python批量爬取百度任意类别的图片的实现方法
利用python批量爬取百度任意类别的图片时: (1):设置类别名字. (2):设置类别的数目,即每一类别的的图片数量. (3):编辑一个txt文件,命名为name.txt,在txt文件中输入类别,此类别即为关键字.并将txt文件与python源代码放在同一个目录下. python源代码: # -*- coding: utf-8 -*- """ Created on Sun Sep 13 21:35:34 2020 @author: ydc """
-
Python3直接爬取图片URL并保存示例
有时候我们会需要从网络上爬取一些图片,来满足我们形形色色直至不可描述的需求. 一个典型的简单爬虫项目步骤包括两步:获取网页地址和提取保存数据. 这里是一个简单的从图片url收集图片的例子,可以成为一个小小的开始. 获取地址 这些图片的URL可能是连续变化的,如从001递增到099,这种情况可以在程序中将共同的前面部分截取,再在最后递增并字符串化后循环即可. 抑或是它们的URL都保存在某个文件中,这时可以读取到列表中: def getUrls(path): urls = [] with open(
-
python爬取某网站原图作为壁纸
不得不说 python真是一个神奇的东西,学三天就能爬网站 真香 完整代码 # -*- coding: utf-8 -*- """ Created on Wed May 26 17:53:13 2021 @author: 19088 """ import urllib.request import os import pickle import re import random import sys #获取http代理 class getHttp
-
Python Scrapy图片爬取原理及代码实例
1.在爬虫文件中只需要解析提取出图片地址,然后将地址提交给管道 在管道文件对图片进行下载和持久化存储 class ImgSpider(scrapy.Spider): name = 'img' # allowed_domains = ['www.xxx.com'] start_urls = ['http://www.521609.com/daxuemeinv/'] url = 'http://www.521609.com/daxuemeinv/list8%d.html' pageNum = 1 d