SQL写法--行行比较
目录
- 环境准备
- 需求背景
- 循环查询
- 混查过滤
- 行行比较
- 总结
环境准备
数据库版本:MySQL 5.7.20-log
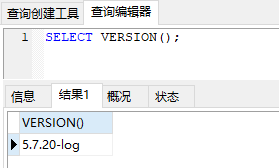
建表 SQL
DROP TABLE IF EXISTS `t_ware_sale_statistics`; CREATE TABLE `t_ware_sale_statistics` ( `id` bigint(20) NOT NULL AUTO_INCREMENT COMMENT '主键id', `business_id` bigint(20) NOT NULL COMMENT '业务机构编码', `ware_inside_code` bigint(20) NOT NULL COMMENT '商品自编码', `weight_sale_cnt_day` double(16,4) DEFAULT NULL COMMENT '平均日销量', `last_thirty_days_sales` double(16,4) DEFAULT NULL COMMENT '最近30天销量', `last_sixty_days_sales` double(16,4) DEFAULT NULL COMMENT '最近60天销量', `last_ninety_days_sales` double(16,4) DEFAULT NULL COMMENT '最近90天销量', `same_period_sale_qty_thirty` double(16,4) DEFAULT NULL COMMENT '去年同期30天销量', `same_period_sale_qty_sixty` double(16,4) DEFAULT NULL COMMENT '去年同期60天销量', `same_period_sale_qty_ninety` double(16,4) DEFAULT NULL COMMENT '去年同期90天销量', `create_user` bigint(20) DEFAULT NULL COMMENT '创建人', `create_time` datetime NOT NULL DEFAULT CURRENT_TIMESTAMP COMMENT '创建时间', `modify_user` bigint(20) DEFAULT NULL COMMENT '最终修改人', `modify_time` datetime NOT NULL DEFAULT CURRENT_TIMESTAMP ON UPDATE CURRENT_TIMESTAMP COMMENT '最终修改时间', `is_delete` tinyint(2) DEFAULT '2' COMMENT '是否删除,1:是,2:否', PRIMARY KEY (`id`) USING BTREE, KEY `idx_business_ware` (`business_id`,`ware_inside_code`) USING BTREE ) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4 ROW_FORMAT=DYNAMIC COMMENT='商品销售统计';

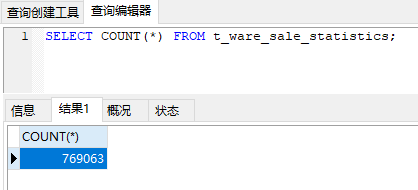
初始化数据
准备了769063条数据
需求背景
业务机构下销售商品,同个业务机构可以销售不同的商品,同个商品可以在不同的业务机构销售,也就说:业务机构与商品是多对多的关系
假设现在有 n 个机构,每个机构下有几个商品,如何查询出这几个门店下各自商品的销售情况?
具体点,类似如下
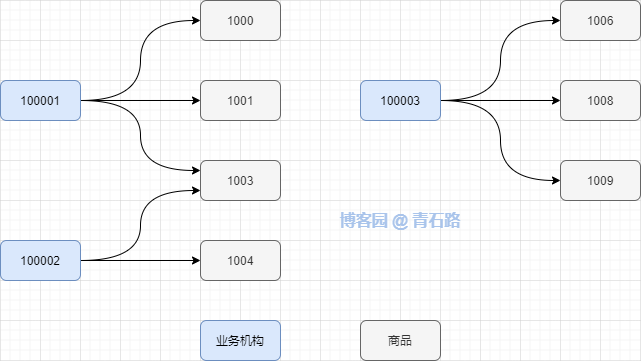
如何查出100001下商品1000、1001、1003、100002下商品1003、1004、100003下商品1006、1008、1009的销售情况
相当于是双层列表(业务机构列表中套商品列表)的查询;业务机构列表和商品列表都不是固定的,而是动态的
那么问题就是:如何查询多个业务机构下,某些商品的销售情况
(问题经我一描述,可能更模糊了,大家明白意思了就好!)
循环查询
这个很容易想到,在代码层面循环业务机构列表,每个业务机构查一次数据库,伪代码如下:

具体的 SQL 类似如下
SQL 能走索引

实现简单,也好理解,SQL 也能走索引,一切看起来似乎很完美
然而现实是:部门开发规范约束,不能循环查数据库
哦豁,这种方式只能放弃,另寻其他方式了
OR 拼接
通过MyBatis的动态 SQL功能,进行 SQL 拼接,类似如下

具体的 SQL 类似如下
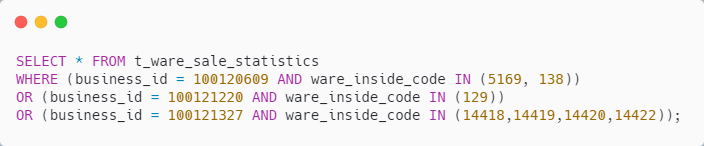
SQL 也能走索引

实现简单,也好理解,SQL 也能走索引,而且只查询一次数据库,貌似可行
唯一可惜的是:有点费 OR,如果业务机构比较多,那 SQL 会比较长
作为候选人之一吧,我们接着往下看
混查过滤
同样是利用Mybatis的动态 SQL,将business_id列表拼在一起、ware_inside_code拼在一起,类似如下

具体的 SQL 类似如下

SQL 也能走索引

实现简单,也好理解,SQL 也能走索引,而且只查询一次数据库,似乎可行
但是:查出来的结果集大于等于我们想要的结果集,你品,你细品!
所以还需要对查出来的结果集进行一次过滤,过滤出我们想要的结果集
姑且也作为候选人之一吧,我们继续往下看
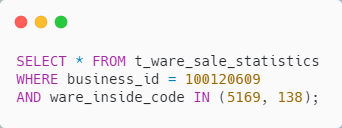
行行比较
SQL-92 中加入了行与行比较的功能,这样一来,比较谓词 = 、< 、> 和 IN 谓词的参数就不再只是标量值了,还可以是值列表了
当然,还是得用到Mybatis的动态 SQL,类似如下

具体的 SQL 类似如下

SQL 同样能走索引

实现简单,SQL 也能走索引,而且只查询一次数据库,感觉可行
只是:有点不好理解,因为我们平时这么用的少,所以这种写法看起来很陌生
另外,行行比较是 SQL 规范,不是某个关系型数据库的规范,也就说关系型数据库都应该支持这种写法
总结
1、最后选择了 行行比较 这种方式来实现了需求
别问我为什么,问就是逼格高!
2、某一个需求的实现往往有很多种方式,我们需要结合业务以及各种约束综合考虑,选择最合适的那个
3、行行比较是 SQL-92 中引入的,SQL-92 是 1992 年制定的规范
行行比较不是新特性,而是很早就存在的基础功能!
参考
《SQL进阶教程》
神奇的 SQL 之 MySQL 执行计划 → EXPLAIN,让我们了解 SQL 的执行过程!
到此这篇关于SQL写法--行行比较的文章就介绍到这了,更多相关SQL 行行比较内容请搜索我们以前的文章或继续浏览下面的相关文章希望大家以后多多支持我们!
相关推荐
-

MySQL/MariaDB中如何支持全部的Unicode
目录 utf8mb4介绍 utf8字节数超出的报错 utf8mb4支持 将默认字符编码设置为utf8mb4,及对应排序规则. 查看当前编码 修改MySQL/Mariadb的配置文件,将utf8编码改为utf8mb4 重启MySQL/MariaDB 再次查看字符集和排序规则 character_set_filesystem和character_set_system的说明 关于字符集设置的其他参考 现有数据库切换字符集到utf8mb4的完整过程 参考 永远不要在 MySQL 中使用 utf8,并且始
-
SQL insert into语句写法讲解
方式1. INSERT INTO t1(field1,field2) VALUE(v001,v002); 明确只插入一条Value 方式2. INSERT INTO t1(field1,field2) VALUES(v101,v102),(v201,v202),(v301,v302),(v401,v402); 在插入批量数据时 方式2 优于 方式1. [特注]当 id 为自增,即 id INT PRIMARY KEY AUTO_INCREMENT 时,执行 insert into 语句,需要
-
mysql IS NULL使用索引案例讲解
简介 mysql的sql查询语句中使用is null.is not null.!=对索引并没有任何影响,并不会因为where条件中使用了is null.is not null.!=这些判断条件导致索引失效而全表扫描. mysql官方文档也已经明确说明is null并不会影响索引的使用. MySQL can perform the same optimization on col_name IS NULL that it can use for col_name = constant_value.
-
常用SQL功能语句
1.调整内存 sp_configure 'show advanced options',1 GO RECONFIGURE Go sp_configure 'awe enabled', 1 GO RECONFIGURE Go sp_configure 'min server memory',1024 Go sp_configure 'max server memory',3072 GO RECONFIGURE Go PS: OS需要打开AWE 即在boot.ini里 添加 /3G 或者 /PAE
-
SQL写法--行行比较
目录 环境准备 需求背景 循环查询 混查过滤 行行比较 总结 环境准备 数据库版本:MySQL 5.7.20-log 建表 SQL DROP TABLE IF EXISTS `t_ware_sale_statistics`; CREATE TABLE `t_ware_sale_statistics` ( `id` bigint(20) NOT NULL AUTO_INCREMENT COMMENT '主键id', `business_id` bigint(20) NOT NULL COMMENT
-
Mybatis批量操作sql写法示例(批量新增、更新)
在使用foreach时,collection属性值的三种情况: 如果传入的参数类型为List时,collection的默认属性值为list,同样可以使用@Param注解自定义keyName; 如果传入的参数类型为array时,collection的默认属性值为array,同样可以使用@Param注解自定义keyName; 如果传入的参数类型为Map时,collection的属性值可为三种情况: 1.遍历map.keys; 2.遍历map.values; 3.遍历map.entrySet() 批量
-
Oracle数仓中判断时间连续性的几种SQL写法示例
零.需求介绍 现有一张表数据如下: 此表是一张镜像表,policyno列代表一个保单号,state列代表这个保单号在snapdate当天的最后一次状态(state每天可能会变很多次,镜像表只保留snapdate时间点凌晨的最后一次状态),snapdate代表当天做镜像的时间,现在有个需求,我们想取出来这个保单号连续保持某个状态的起止时间,例如: 保单号sm1保持状态1的起止时间为2021020120210202,然后在20210203时候变成了状态2,又在20210204时候变成了状态3,最终又
-
SQL Server中参数化SQL写法遇到parameter sniff ,导致不合理执行计划重用的快速解决方法
parameter sniff问题是重用其他参数生成的执行计划,导致当前参数采用该执行计划非最优化的现象.想必熟悉数据的同学都应该知道,产生parameter sniff最典型的问题就是使用了参数化的SQL(或者存储过程中使用了参数化)写法,如果存在数据分布不均匀的情况下,正常情况下生成的执行计划,在传入在分布数据较多的参数的情况下,重用了正常参数生成的执行计划,而这种缓存的执行计划并非适合当前参数的一种情况. 这种情况,在实际业务中,出现的频率还是比较高的,因为存储过程一般都是采用参数化的写法
-
这种sql写法真的会导致索引失效吗
前言 网上经常能看到一些文章总结在 mysql 中不能命中索引的各种情况,其中有一种说法就是指使用了 or 的语句都不能命中索引. 这种说法其实是不够正确的,正确的结论应该是,从 mysql5.0 后,如果在 or 连接的字段上都有独立的索引的话,是可以命中索引的,这里就是用到了 index_merge 特性. 在 mysql5.0 版本以前一条 sql 只能选择使用一个索引,而且如果 sql 中使用了 or 关键字,那么已有的索引就会失效,会走全表扫描.因为无论走哪个索引,mysql 都不能一
-
MyBatis中关于SQL的写法总结
目录 一.MyBatis – if 语句 二.MyBatis --choose 语句 三.MyBatis – trim 四.MyBatis – where 五.MyBatis – set 六.MyBatis – foreach 七.MyBatis – concat 八.MyBatis – sql片段 最近MyBatis使用较多,在这里简单总结一下MyBatis的sql写法 说简单一点mybatis就是写原⽣sql,官方都说了 mybatis 的动态sql语句是基于OGNL表达式的.可以方便的在
-
Oracle SQL tuning 数据库优化步骤分享(图文教程)
SQL Turning 是Quest公司出品的Quest Central软件中的一个工具.Quest Central是一款集成化.图形化.跨平台的数据库管理解决方案,可以同时管理 Oracle.DB2 和 SQL server 数据库. 一.SQL Tuning for SQL Server简介 SQL语句的优化对发挥数据库的最佳性能非常关键.然而不幸的是,应用优化通常由于时间和资源的因素而被忽略.SQL Tuning (SQL优化)模块可以对比和评测特定应用中SQL语句的运行性能,提出智能化的
-
详解Java的MyBatis框架中SQL语句映射部分的编写
1.resultMap SQL 映射XML 文件是所有sql语句放置的地方.需要定义一个workspace,一般定义为对应的接口类的路径.写好SQL语句映射文件后,需要在MyBAtis配置文件mappers标签中引用,例如: <mappers> <mapper resource="com/liming/manager/data/mappers/UserMapper.xml" /> <mapper resource="com/liming/mana
-
查询mysql中执行效率低的sql语句的方法
一些小技巧1. 如何查出效率低的语句?在MySQL下,在启动参数中设置 --log-slow-queries=[文件名],就可以在指定的日志文件中记录执行时间超过long_query_time(缺省为10秒)的SQL语句.你也可以在启动配置文件中修改long query的时间,如: 复制代码 代码如下: # Set long query time to 8 seconds long_query_time=8 2. 如何查询某表的索引?可使用SHOW INDEX语句,如: 复制代码 代码如下
-
SQL判断语句用法和多表查询
1.格式化时间sql语句 本例中本人随便做了两张表,和实际不是很相符,只是想说明sql语句的写法. 例1表格式如下: 需求:查询出本表,但需要使time字段的时间格式为yyyy-MM-dd,比如:2013-08-13 sql写法: SELECT u.id,u.userId,u.timeType,DATE_FORMAT(time,'%Y-%m-%d') AS time,secondId FROM `user` u 运行结果: 2.多表查询(三表查询) 例二三表结构如下: 需求:查询出主表,要求在主