Python Charles抓包配置实现流程图解
配置
大佬的博客真的很详细很详细,我就不重复造轮子了,看这里
补充解释

在这一步疑问很多,大佬说的不是很详细,就由我来补充下吧~
在PC端Charles这样点击:
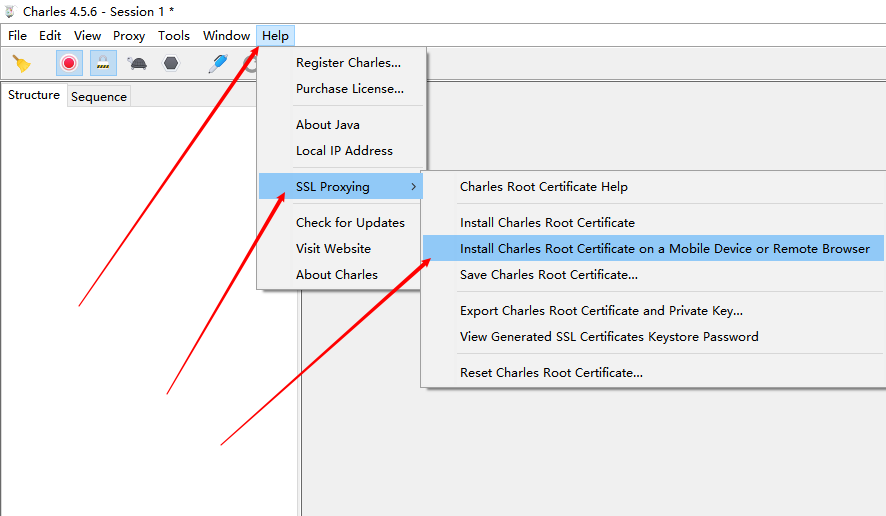
之后会这样提示:我们要记住图中的红色方框圈起来的!

第一个是手机代理IP和端口号!第二个是移动端证书下载网址
移动端证书配置
2.1 首先连接到电脑的WiFi(和电脑同一WiFi或电脑的热点都可以)

2.2 点击进行配置代理
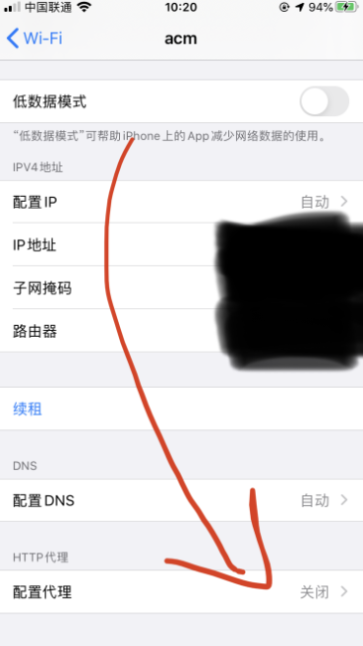
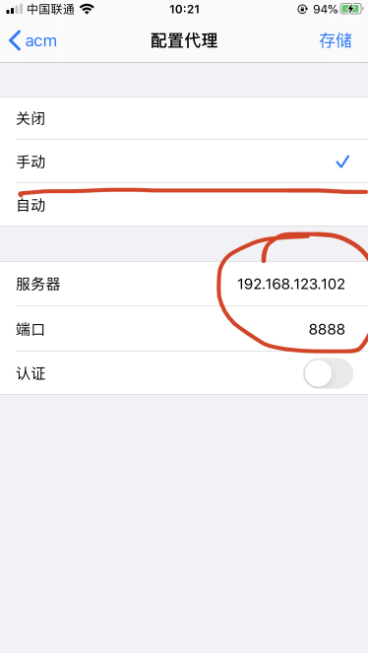
最后点击存储,之后会出现PC端会这样提示,记住不要回车!!!因为默认是Deny(拒绝) 要点击Allow(允许)!!!
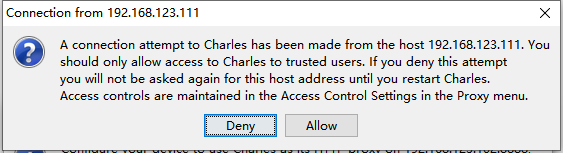
2.3 **配置证书(重要!!!)**
用浏览器访问chls.pro/ssl

允许下载
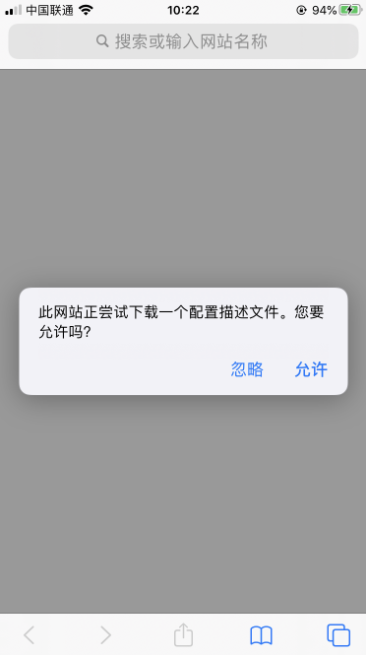
然后去设置->通用->描述文件 安装代理证书

最后去设置->关于本机->证书信任设置 点击完全信任!
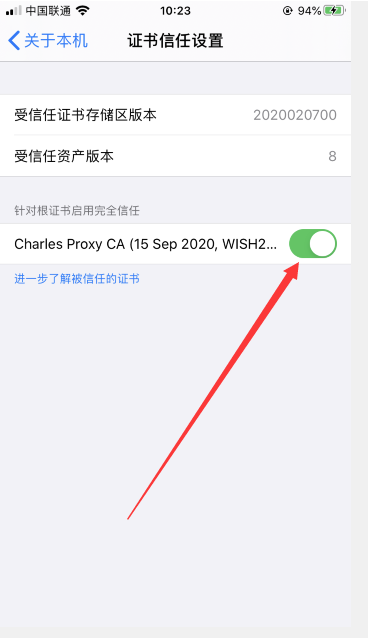
至此,Charles配置完毕!撒花花!
以上就是本文的全部内容,希望对大家的学习有所帮助,也希望大家多多支持我们。
相关推荐
-
Python3自定义http/https请求拦截mitmproxy脚本实例
脚本内容 代码如下: from mitmproxy import http, ctx from multiprocessing import Lock class Filter: def __init__(self, filter_info): self.log_info = "" self.mutex = Lock() self.filter_info = filter_info self.response_file = None self.switch_on = False sel
-
Python抓包程序mitmproxy安装和使用过程图解
一.介绍说明 mitmproxy是一个支持HTTP和HTTPS的抓包程序,有类似Fiddler.Charles的功能,只不过它是一个控制台的形式操作. mitmproxy还有两个关联组件.一个是mitmdump,它是mitmproxy的命令行接口,利用它我们可以对接Python脚本,用Python实现监听后的处理.另一个是mitmweb,它是一个Web程序,通过它我们可以清楚观察mitmproxy捕获的请求. mitmproxy的功能: 1.拦截HTTP和HTTPS请求和响应 2.保存HTTP会
-
python使用mitmproxy抓取浏览器请求的方法
最近要写一款基于被动式的漏洞扫描器,因为被动式是将我们在浏览器浏览的时候所发出的请求进行捕获,然后交给扫描器进行处理,本来打算自己写这个代理的,但是因为考虑到需要抓取https,所以最后找到Mitmproxy这个程序. 安装方法: pip install mitmproxy 接下来通过一个案例程序来了解它的使用,下面是目录结构 sproxy |utils |__init__.py |parser.py |sproxy.py sproxy.py代码 #coding=utf-8 from pprin
-

使用Python实现windows下的抓包与解析
系统环境:windows7,选择windows系统是因为我对自己平时日常机器上的流量比较感兴趣 python环境:python2.7 ,这里不选择python3的原因,是因为接下来要用到的scapy包在python3中安装较于python2要麻烦得多.如果你习惯于用python3,数据包的分析完全可以放在3下面做,因为抓包和分析是两个完全独立的过程. 需要的python包:scapy和dpkt 抓包代码: from scapy.sendrecv import sniff from scapy.u
-
Python如何爬取微信公众号文章和评论(基于 Fiddler 抓包分析)
背景说明 感觉微信公众号算得是比较难爬的平台之一,不过一番折腾之后还是小有收获的.没有用Scrapy(估计爬太快也有反爬限制),但后面会开始整理写一些实战出来.简单介绍下本次的开发环境: python3 requests psycopg2 (操作postgres数据库) 抓包分析 本次实战对抓取的公众号没有限制,但不同公众号每次抓取之前都要进行分析.打开Fiddler,将手机配置好相关代理,为避免干扰过多,这里给Fiddler加个过滤规则,只需要指定微信域名mp.weixin.qq.com就好:
-
python调用tcpdump抓包过滤的方法
本文实例为大家分享了python调用tcpdump抓包过滤的具体代码,供大家参考,具体内容如下 之前在linux用python脚本写一个抓包分析小工具,实在不想用什么libpcap.pypcap所以,简单来了个tcpdump加grep搞定.基本思路是分别起tcpdump和grep两个进程,进程直接通过pipe交换数据,简单代码如下: #! /usr/bin/python def tcpdump(): import subprocess, fcntl, os # sudo tcpdump -i e
-
python实现linux下抓包并存库功能
最近项目需要抓包功能,并且抓包后要对数据包进行存库并分析.抓包想使用tcpdump来完成,但是tcpdump抓包之后只能保存为文件,我需要将其保存到数据库.想来想去shell脚本似乎不太好实现,于是用了比较热门的python来实现.不得不说,python丰富的第三方库确实是很强大,下面是具体的功能代码. from apscheduler.scheduler import Scheduler import os import sys import time import MySQLdb impor
-
Python3爬虫mitmproxy的安装步骤
mitmproxy是一个支持HTTP和HTTPS的抓包程序,类似Fiddler.Charles的功能,只不过它通过控制台的形式操作. 此外,mitmproxy还有两个关联组件,一个是mitmdump,它是mitmproxy的命令行接口,利用它可以对接Python脚本,实现监听后的处理:另一个是mitmweb,它是一个Web程序,通过它以清楚地观察到mitmproxy捕获的请求. 本节中,我们就来了解一下mitmproxy.mitmdump和mitmweb的安装方式. 1. 相关链接 GitHub
-
python如何利用Mitmproxy抓包
一.使用 安装 pip install mitmproxy mitmproxy 是具有控制台界面的交互式,支持SSL的拦截代理 mitmdump是mitmproxy的命令行版本.想想tcpdump为HTTP mitmweb 是一个基于web的界面,适用于mitmproxy mitmproxy(mac).mitmdump.mitmweb(win) 这三个命令中的任意一个即可 mitmweb -s mitm.py 命令行启动默认端口8080 mitmweb -p 8888 -s mitm.py 指定
-
Python爬虫谷歌Chrome F12抓包过程原理解析
浏览器打开网页的过程就是爬虫获取数据的过程,两者是一样一样的.浏览器渲染的网页是丰富多彩的数据集合,而爬虫得到的是网页的源代码htm有时候,我们不能在网页的html代码里面找到想要的数据,但是浏览器打开的网页上面却有这些数据.这就是浏览器通过ajax技术异步加载(偷偷下载)了这些数据. 大家禁不住要问:那么该如何看到浏览器偷偷下载的那些数据呢? 答案就是谷歌Chrome浏览器的F12快捷键,也可以通过鼠标右键菜单"检查"(Inspect)打开Chrome自带的开发者工具,开发者工具会出
-
python 抓包保存为pcap文件并解析的实例
首先是抓包,使用scapy模块, sniff()函数 在其中参数为本地文件路径时,操作为打开本地文件 若参数为BPF过滤规则和回调函数,则进行Sniff,回调函数用于对Sniff到的数据包进行处理 import os from scapy.all import * pkts=[] count=0 pcapnum=0 filename='' def test_dump_file(dump_file): print "Testing the dump file..." if os.path
-
python代理工具mitmproxy使用指南
前言 mitmproxy 是 man-in-the-middle proxy 的简称,译为中间人代理工具,可以用来拦截.修改.保存 HTTP/HTTPS 请求.以命令行终端形式呈现,操作上类似于Vim,同时提供了 mitmweb 插件,是类似于 Chrome 浏览器开发者模式的可视化工具. 它是基于Python开发的开源工具,最重要的是它提供了Python API,你完全可以通过Python代码来控制请求和响应,这是其它工具所不能做到的,这点也是我喜欢这个工具的原因之一. 安装 sudo pip