Python获取江苏疫情实时数据及爬虫分析
目录
- 1.引言
- 2.获取目标网站
- 3.爬取目标网站
- 4.解析爬取内容
- 4.1. 解析全国今日总况
- 4.2. 解析全国各省份疫情情况
- 4.3. 解析江苏各地级市疫情情况
- 5.结果可视化
- 6. 代码
- 7. 参考
1.引言
最近江苏南京、湖南张家界陆续爆发疫情,目前已波及8省22市,全国共有2个高风险地区,52个中风险地区。身在南京,作为兢兢业业的打工人,默默地成为了“苏打绿”。为了关注疫情状况,今天我们用python来爬一爬疫情的实时数据。
2.获取目标网站
为了使用python来获取疫情数据,我们需要找一个疫情实时追踪数据发布网站,国内比较有名的是腾讯新闻、网易新闻等,这些网站疫情内容都大同小异,主要包括国内疫情、海外疫情,每日新增确诊趋势,疫苗接种情况等,这里我们选用腾讯新闻疫情发布页来进行数据爬取分析。

网站分析:
- 使用chrome浏览器 打开疫情发布页网址 ,如上图所示
- 我们按F12 进入开发者模式,按 ctrl+R 刷新页面
- 在Network下找到 getOnsInfo?name=disease_h5列,获得爬取目标网址

3.爬取目标网站
我们写爬虫爬取网站数据,需要安装request库,安装命令如下:
pip3 install requests
只需要三行代码就可以获取该网页内容,代码如下:
url = 'https://view.inews.qq.com/g2/getOnsInfo?name=disease_h5' req = requests.get(url=url) content = json.loads(req.text)
打印爬去结果如下:
4.解析爬取内容
上述网站内容我们虽然爬取成功,接下来我们需要对爬取的结果进行解析,从中找出我们感兴趣的部分。
4.1. 解析全国今日总况

相应的解析代码如下:
def get_all_china(content):
tmp_data = content["data"]
area_data = json.loads(tmp_data)["areaTree"]
country = area_data[0]
country_list = []
name = country["name"]
today_confirm = country["today"]["confirm"]
now_confirm = country["total"]["nowConfirm"]
total_confirm = country["total"]["confirm"]
total_heal = country["total"]["heal"]
country_list.append([name, today_confirm, now_confirm, total_confirm, total_heal])
return country_list
打印结果如下:

输出太丑了,这里使用PrettyTable库对输出进行美化,代码如下:
def format_list_prettytable(title,province_list):
table = PrettyTable(title)
for province in province_list:
table.add_row(province)
table.border = True
return table
结果如下:
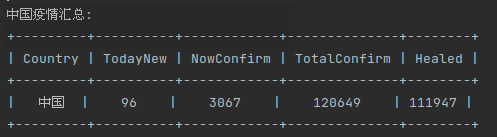
4.2. 解析全国各省份疫情情况
依次类推,可解析全国各省市疫情情况,代码如下:
def get_all_province(content):
tmp_data = content["data"]
area_data = json.loads(tmp_data)["areaTree"]
data = area_data[0]['children']
province_list = []
for province in data:
name = province["name"]
today_confirm = province["today"]["confirm"]
now_confirm = province["total"]["nowConfirm"]
total_confirm = province["total"]["confirm"]
total_heal = province["total"]["heal"]
province_list.append([name, today_confirm, now_confirm, total_confirm, total_heal])
return province_list
结果如下:

4.3. 解析江苏各地级市疫情情况
最后,我们获取江苏省各地级市的疫情数据,代码如下:
def parse_jiangsu_province(content,key_province):
tmp_data = content["data"]
area_data = json.loads(tmp_data)["areaTree"]
data = area_data[0]['children']
city_list = []
for province in data:
name = province["name"]
if name == key_province:
children_list = province["children"]
for children in children_list:
city = children["name"]
today_new = children["today"]["confirm"]
now_confirm = children["total"]["nowConfirm"]
total_confirm = children["total"]["confirm"]
total_heal = children["total"]["heal"]
city_list.append([city, today_new, now_confirm, total_confirm, total_heal])
return city_list
结果如下:

5.结果可视化
使用matplotlib对上述爬去的江苏各地级市疫情分布可视化,得到结果如下:
今日新增可视化结果如下:
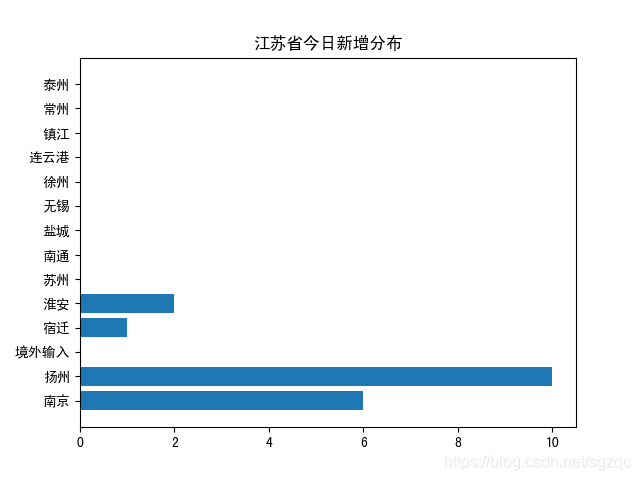
现有确诊可视化结果如下:

从上述图表可以看出,今日疫情已扩散至扬州,扬州今日新增感染人数最多,需引起重视。
6. 代码
完整代码
https://github.com/sgzqc/wechat/tree/main/20210731
7. 参考
链接一
到此这篇关于Python获取江苏疫情实时数据及爬虫分析的文章就介绍到这了,更多相关Python江苏疫情内容请搜索我们以前的文章或继续浏览下面的相关文章希望大家以后多多支持我们!
相关推荐
-

Python抓新型冠状病毒肺炎疫情数据并绘制全国疫情分布的代码实例
运行结果(2020-2-4日数据) 数据来源 news.qq.com/zt2020/page/feiyan.htm 抓包分析 日报数据格式 "chinaDayList": [{ "date": "01.13", "confirm": "41", "suspect": "0", "dead": "1", "heal&qu
-
python 爬取疫情数据的源码
疫情数据 程序源码 // An highlighted block import requests import json class epidemic_data(): def __init__(self, province): self.url = url self.header = header self.text = {} self.province = province # self.r=None def down_page(self): r = requests.get(url=url
-
使用Python制作新型冠状病毒实时疫情图
最近一周每天早上起来第一件事,就是打开新闻软件看疫情相关的新闻.了解下自己和亲友所在城市的确诊人数,但纯数字还是缺乏一个直观的概念.那我们来做一个吧. 至于数据,从各大网站的实时疫情页面就可以拿到.以某网站为例,用requests拿到html后,发现并没有数据.不要慌,那证明是个javascript渲染的页面,即使是javascript也是需要从后台取数据的.打开Chrome开发者工具,点开network,刷新页面,点击各个请求,肯定有一个是取json的. 注意这里的返回数据是包含在一个js变量
-
Python 写了个新型冠状病毒疫情传播模拟程序
病毒扩散仿真程序,用 python 也可以. 概述 事情是这样的,B 站 UP 主 @ele 实验室,写了一个简单的疫情传播仿真程序,告诉大家在家待着的重要性,视频相信大家都看过了,并且 UP 主也放出了源码. 因为是 Java 开发的,所以开始我并没有多加关注.后来看到有人解析代码,发现我也能看懂,然后就琢磨用 Python 应该怎么实现. Java 版程序浅析 一个人就是 1 个(x, y)坐标点,并且每个人有一个状态. public class Person extends Point {
-
Python爬取腾讯疫情实时数据并存储到mysql数据库的示例代码
思路: 在腾讯疫情数据网站F12解析网站结构,使用Python爬取当日疫情数据和历史疫情数据,分别存储到details和history两个mysql表. ①此方法用于爬取每日详细疫情数据 import requests import json import time def get_details(): url = 'https://view.inews.qq.com/g2/getOnsInfo?name=disease_h5&callback=jQuery3410284820553141302
-
Python绘制全球疫情变化地图的实例代码
目前全球疫情仍然比较严重,为了能清晰地看到疫情爆发以来至现在全球疫情的变化趋势,我绘制了一张疫情变化地图. 废话不多说,先上图 下面就来重点介绍下上面这张图的绘制过程,主要分为以下三个步骤: 数据收集 数据处理 画图 下面一个一个来说. 数据收集 这是万里长城的第一步,俗话说"巧妇难为无米之炊",既然是变化图,当然需要每个国家.每天的现有确诊病例数.好在现在各大网站都有疫情相关的专题页,我们可以直接抓数据.以网易为例 我们选择 XHR,重新刷新下网页可以看到有几个接口,其中 list-
-
Python实现疫情通定时自动填写功能(附代码)
自疫情始,学校就要求学生每天在学校内系统填写个人每日疫情相关情况,称为疫情通. 但是,由于个人原因,出现了下图情况. 记性太差,人又懒,于是决定用Python实现自动化定时任务. 1.核心模块 打开IEChrome. 打开网页按下F12拿到请求头和请求体. (假装此处有图片) Pycharm启动! 根据拿到的请求头和请求体,完成核心代码编写. url = "https://xxcapp.xidian.edu.cn/ncov/wap/default/save" headers = {'C
-
Python获取江苏疫情实时数据及爬虫分析
目录 1.引言 2.获取目标网站 3.爬取目标网站 4.解析爬取内容 4.1. 解析全国今日总况 4.2. 解析全国各省份疫情情况 4.3. 解析江苏各地级市疫情情况 5.结果可视化 6. 代码 7. 参考 1.引言 最近江苏南京.湖南张家界陆续爆发疫情,目前已波及8省22市,全国共有2个高风险地区,52个中风险地区.身在南京,作为兢兢业业的打工人,默默地成为了"苏打绿".为了关注疫情状况,今天我们用python来爬一爬疫情的实时数据. 2.获取目标网站 为了使用python来获取疫情
-
Python实现监控远程主机实时数据的示例详解
目录 0 简述 1 程序说明文档 1.1 服务端 1.2 客户端 2 代码 0 简述 实时监控应用程序,使用Python的Socket库和相应的第三方库来监控远程主机的实时数据,比如CPU使用率.内存使用率.网络带宽等信息.可以允许多个用户同时访问服务端.注:部分指令响应较慢,请耐心等待. 1 程序说明文档 1.1 服务端 本程序为一个基于TCP协议的服务端程序,可以接收客户端发送的指令并执行相应的操作,最终将操作结果返回给客户端.程序运行在localhost(即本机)的8888端口. 主要功能
-
python获取全国最新省市区数据并存入表实例代码
本文通过调取高德行政区划查询接口,获取最新的数据信息(省.市.区.经纬度.行政级别.城市编码.行政编码等),并通过mysql.connector存入mysql数据库 表结构设计如下: CREATE TABLE `districts` ( `districtId` int(11) NOT NULL AUTO_INCREMENT, `districtPid` int(11) DEFAULT NULL COMMENT '上级ID', `name` varchar(32) DEFAULT NULL CO
-
利用Python 爬取股票实时数据详情
东方财富网地址如下: http://quote.eastmoney.com/center/gridlist.html#hs_a_board 我们通过点击该网站的下一页发现,网页内容有变化,但是网站的 URL 却不变,也就是说这里使用了 Ajax 技术,动态从服务器拉取数据,这种方式的好处是可以在不重新加载整幅网页的情况下更新部分数据,减轻网络负荷,加快页面加载速度. 我们通过 F12 来查看网络请求情况,可以很容易的发现,网页上的数据都是通过如下地址请求的 http://38.push2.eas
-
Python获取时光网电影数据的实例代码
目录 一.前言 二.准备 2.1 安装库 2.2 原理介绍 三.实例 3.1 完整代码 一.前言 有时候觉得电影真是人类有史以来最伟大的发明,我喜欢看电影,看电影可以让我们增长见闻,学习知识.从某种角度上而言,电影凭借自身独有的魅力大大延长了人类的”寿命”.一部电影如同一本故事书,我可以沉迷到其中,来的一个新的世界,跟着电影主角去经历去感悟.而好的电影是需要慢慢品尝的,不仅提供了各种视觉刺激和情感体验,更能带来思考点,也让我可以懂得在现实生活中穷尽一生也无法明白的道理.电影比书本更直接.更有趣.
-
Python实现爬取天气数据并可视化分析
目录 核心功能设计 实现步骤 爬取数据 风向风级雷达图 温湿度相关性分析 24小时内每小时时段降水 24小时累计降雨量 今天我们分享一个小案例,获取天气数据,进行可视化分析,带你直观了解天气情况! 核心功能设计 总体来说,我们需要先对中国天气网中的天气数据进行爬取,保存为csv文件,并将这些数据进行可视化分析展示. 拆解需求,大致可以整理出我们需要分为以下几步完成: 1.通过爬虫获取中国天气网7.20-7.21的降雨数据,包括城市,风力方向,风级,降水量,相对湿度,空气质量. 2.对获取的天气数
-
python中scrapy处理项目数据的实例分析
在我们处理完数据后,习惯把它放在原有的位置,但是这样也会出现一定的隐患.如果因为新数据的加入或者其他种种原因,当我们再次想要启用这个文件的时候,小伙伴们就会开始着急却怎么也翻不出来,似乎也没有其他更好的搜集办法,而重新进行数据整理显然是不现实的.下面我们就一起看看python爬虫中scrapy处理项目数据的方法吧. 1.拉取项目 $ git clone https://github.com/jonbakerfish/TweetScraper.git $ cd TweetScraper/ $ pi
-
如何利用Python获取鼠标的实时位置
目录 安装 pyautogui鼠标操作样例 Python获取鼠标实时位置具体实现 结果展示 总结 使用Python的第三方库pyautogui,PyAutoGUI是一个纯Python的GUI自动化工具,其目的是可以用程序自动控制鼠标和键盘操作,多平台支持(Windows,OS X,Linux). 安装 pip install pyautogui pyautogui鼠标操作样例 import pyautogui # 获取当前屏幕分辨率 screenWidth, screenHeight = pya
-
js下获取div中的数据的原理分析
关于从中学到的知识: document.getelementbyid("ddhdh").innerHTML 可以获取到div中的全部数据,包括标签...但是只是在IE和OPERA中使用 document.getelementbyid("ddhdh").innerTEXT 可以获取到div中的文本数据,不会获取到标签...但是只是在IE和OPERA中使用 document.getElementById("text").textContent 用于在