C++手写内存池的案例详解
引言
使用new expression为类的多个实例分配动态内存时,cookie导致内存利用率可能不高,此时我们通过实现类的内存池来降低overhead。从不成熟到巧妙优化的内存池,得益于union的分时复用特性,内存利用率得到了提高。
原因
在实例化某个类的对象时(在heap而不是stack中),若不使用array new,则每次实例化时都要调用一次内存分配函数,类的每个实例在内存中都有上下两个cookie,从而降低了内存的利用率。然而,array new也有先天的缺陷,即只能调用默认无参构造函数,这对于很多没有提供无参构造函数的类来说是不合适的。
因此,我们可以对于一个没有实例化的类第一次实例化时,先分配一大块内存(内存池),这一大块内存记录在类中,只有上下两个cookie,能够容纳多个实例。后续实例化时,若内存池中还有剩余内存,则不必申请内存分配,只在内存池中分配。内存回收时,将实例所占用的内存回收到内存池中。若内存池中无内存,则再申请分配大块内存。
脱裤子放屁方案
我们以链表的形式组织内存池,内存池中每个一个链表是一个小桶,这个桶中装我们实例化的对象。
内存池链表的头结点记录在类中,即以class staic变量的形式存储。组织形式如下:

实现代码如下:
#include <iostream>
using namespace std;
class DemoClass{
public:
DemoClass() = default;
DemoClass(int i):data(i){}
static void* operator new(size_t size);
static void operator delete(void *);
virtual ~DemoClass(){}
private:
DemoClass *next;
int data;
static DemoClass *freeMemHeader;
static const size_t POOL_SIZE;
};
DemoClass * DemoClass::freeMemHeader = nullptr;
const size_t DemoClass::POOL_SIZE = 24;//设定内存池能容纳24个DemoClass对象
void* DemoClass::operator new(size_t size){
DemoClass* p;
if(!freeMemHeader){//freeMemHeader为空,内存池中无空间,分配内存
size_t pool_mem_bytes = size * POOL_SIZE;//内存池的字节大小 = 每个实例的大小(字节数)* 内存池中能容纳的最大实例数
freeMemHeader = reinterpret_cast<DemoClass*>(new char[pool_mem_bytes]);//new char[]分配pool_mem_bytes个字节,因为每个char占用1个字节
cout << "Info:向操作系统申请了" << pool_mem_bytes << "字节的内存。" << endl;
for(int i = 0;i < POOL_SIZE - 1; ++i){//将内存池中POOL_SIZE个小块内存,串起来。
freeMemHeader[i].next = &freeMemHeader[i + 1];
}
freeMemHeader[POOL_SIZE - 1].next = nullptr;
}
p = freeMemHeader;//取内存池(链表)的头部,分配给要实例化的对象
cout << "Info:从内存池中取了" << size << "字节的内存。" << endl;
freeMemHeader = freeMemHeader -> next;//从内存池中删去取出的那一小块地址,即更新内存池
p -> next = nullptr;
return p;
}
void DemoClass::operator delete(void* p){
DemoClass* tmp = (DemoClass*) p;
tmp -> next = freeMemHeader;
freeMemHeader = tmp;
}
测试代码如下:
int main(int argc, char* argv[]){
cout << "sizeof(DemoClass):" << sizeof(DemoClass) << endl;
size_t N = 32;
DemoClass* demos[N];
for(int i = 0; i < N; ++i){
demos[i] = new DemoClass(i);
cout << "address of the ith demo:" << demos[i] << endl;
cout << endl;
}
return 0;
}
其结果如下:

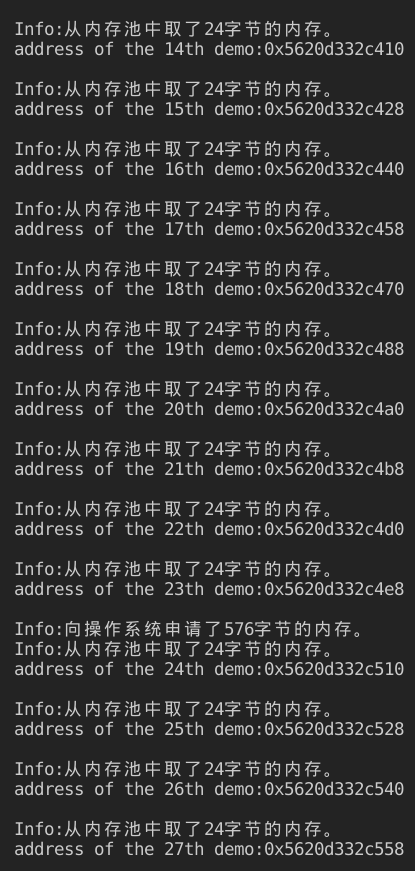
可以看到每个DemoClass的实例大小为24字节,内存池一次从操作系统中申请了576个字节的内存,这些内存可以容纳24个实例。上面显示出了每个实例的内存地址,内存池中相邻实例的内存首地址之差为24,即实例的大小,证明了一个内存池的实例之间确实没有cookie。
当内存池中内存用完后,又向操作系统申请了576个字节的内存。
由此,只有每个内存池两侧有cookie,而内存池中的实例不存在cookie,相比于每次调用new expression实例化对象都有cookie,内存池的组织形式确实在形式上提高了内存利用率。
那么,有什么问题么?
sizeof(DemoClass)等于24:
- int data数据域占4个字节
- 两个构造函数一个析构函数各占4字节,共12字节
- 额外的指针DemoClass*,在64位机器上,占8个字节
这样一个DemoClass的大小确实是24字节。wait,what?
我们为了解决cookie带来的内存浪费,引入了指针next,但却又引入了8个字节的overhead,脱裤子放屁,多此一举?
这样看来确实没有达到要求,但至少为我们提供了一种思路,不是么?
分时复用改进方案
首先我们先回忆下c++ 中的Union:
在任意时刻,联合中只能有一个数据成员可以有值。当给联合中某个成员赋值之后,该联合中的其它成员就变成未定义状态了。
结合我们之前不成熟的内存池,我们发现,当内存池中的桶还没有被分配给实例时,只有next域有用,而当桶被分配给实例后,next域就没什么用了;当桶被回收时,数据域变无用而next指针又需要用到。这不正是union的特性么?
看一下代码实现:
#include <iostream>
using namespace std;
class DemoClass{
public:
DemoClass() = default;
DemoClass(int i, double p){
data.num = i;
data.price = p;
}
static void* operator new(size_t size);
static void operator delete(void *);
virtual ~DemoClass(){}
private:
struct DemoData{
int num;
double price;
};
private:
static DemoClass *freeMemHeader;
static const size_t POOL_SIZE;
union {
DemoClass *next;
DemoData data;
};
};
DemoClass * DemoClass::freeMemHeader = nullptr;
const size_t DemoClass::POOL_SIZE = 24;//设定内存池能容纳24个DemoClass对象
void* DemoClass::operator new(size_t size){
DemoClass* p;
if(!freeMemHeader){//freeMemHeader为空,内存池中无空间,分配内存
size_t pool_mem_bytes = size * POOL_SIZE;//内存池的字节大小 = 每个实例的大小(字节数)* 内存池中能容纳的最大实例数
freeMemHeader = reinterpret_cast<DemoClass*>(new char[pool_mem_bytes]);//new char[]分配pool_mem_bytes个字节,因为每个char占用1个字节
cout << "Info:向操作系统申请了" << pool_mem_bytes << "字节的内存。" << endl;
for(int i = 0;i < POOL_SIZE - 1; ++i){//将内存池中POOL_SIZE个小块内存,串起来。
freeMemHeader[i].next = &freeMemHeader[i + 1];
}
freeMemHeader[POOL_SIZE - 1].next = nullptr;
}
p = freeMemHeader;//取内存池(链表)的头部,分配给要实例化的对象
cout << "Info:从内存池中取了" << size << "字节的内存。" << endl;
freeMemHeader = freeMemHeader -> next;//从内存池中删去取出的那一小块地址,即更新内存池
p -> next = nullptr;
return p;
}
void DemoClass::operator delete(void* p){
DemoClass* tmp = (DemoClass*) p;
tmp -> next = freeMemHeader;
freeMemHeader = tmp;
}
对比前一种实现代码,只是构造函数、数据域和指针域的组织形式发生了变化:
- 由于数据域增加了price项,构造函数中也增加了对应的参数
- 数据域被集成定义成一个类自定义struct类型
- 数据域和指针域被组织为union
测试代码依旧:
int main(int argc, char* argv[]){
cout << "sizeof(DemoClass):" << sizeof(DemoClass) << endl;
size_t N = 32;
DemoClass* demos[N];
for(int i = 0; i < N; ++i){
demos[i] = new DemoClass(i, i * i);
cout << "address of the " << i << "th demo:" << demos[i] << endl;
cout << endl;
}
return 0;
}
结果:


可以看到每个DemoClass的实例大小为24字节,一个内存池的实例之间没有cookie。
分析一下sizeof(DemoClass)等于24的缘由:
- data数据域占12个字节(int 4字节、double 8字节)。
- 两个构造函数一个析构函数各占4字节,共12字节。
- 指针DemoClass,在64位机器上,占8个字节,但由于和数据域使用了union,data数据域12个字节中的前8个字节在适当的时机被看作DemoClass,而不占用额外空间,消除了overhead。
这样一个DemoClass的大小确实是24字节。利用union的分时复用特性,我们消除了初步方案中指针带来的脱裤子放屁效果。
另外的思考
细心的读者可能会发现,前面的那两种方案都有共同的小缺陷,即当程序一直实例化而不析构时,内存池会向操作系统申请多次大块内存,而当这些对象一起回收时,内存池中的剩余桶数会远大于设定的POOL_SIZE的大小,这个峰值多大取决于类实例化和回收的时机。
另外,内存池中的内存暂时不会回收给操作系统,峰值很大可能会对内存分配带来一些影响,不过这却不属于内存泄漏。在以后的文章中,我们可能会讨论一些性能更好的内存分配方案。
参考资料
[1] Effective C++ 3/e
[2] C++ Primer 5/e
[3] 侯捷老师的内存管理课程
到此这篇关于C++手写内存池的文章就介绍到这了,更多相关C++内存池内容请搜索我们以前的文章或继续浏览下面的相关文章希望大家以后多多支持我们!
相关推荐
-

C++高并发内存池的整体设计和实现思路
目录 一.整体设计 1.需求分析 2.总体设计思路 3.申请内存流程图 二.详细设计 1.各个模块内部结构详细剖析 2.设计细节 三.测试 一.整体设计 1.需求分析 池化技术是计算机中的一种设计模式,内存池是常见的池化技术之一,它能够有效的提高内存的申请和释放效率以及内存碎片等问题,但是传统的内存池也存在一定的缺陷,高并发内存池相对于普通的内存池它有自己的独特之处,解决了传统内存池存在的一些问题. 附:实现一个内存池管理的类方法 1)直接使用new/delete.malloc/free存在的问
-
C++内存池的简单实现
目录 一.内存池基础知识 1.什么是内存池 1.1 池化技术 1.2 内存池 2.内存池的作用 2.1 效率问题 2.2 内存碎片 3.内存池技术的演进 二.简易内存池原理 1.整体设计 1.1 内存池结构 1.2 申请内存 1.3 释放内存 2.详细剖析 2.1 blockNode结构 2.2 单个对象的大小 3.性能比较 三.简易内存池完整源码 一.内存池基础知识 1.什么是内存池 1.1 池化技术 池化技术是计算机中的一种设计模式,主要是指:将程序中经常要使用的计算机资源预先申请出来,由程
-
C++手写内存池的案例详解
引言 使用new expression为类的多个实例分配动态内存时,cookie导致内存利用率可能不高,此时我们通过实现类的内存池来降低overhead.从不成熟到巧妙优化的内存池,得益于union的分时复用特性,内存利用率得到了提高. 原因 在实例化某个类的对象时(在heap而不是stack中),若不使用array new,则每次实例化时都要调用一次内存分配函数,类的每个实例在内存中都有上下两个cookie,从而降低了内存的利用率.然而,array new也有先天的缺陷,即只能调用默认无参构造
-
python爬虫线程池案例详解(梨视频短视频爬取)
python爬虫-梨视频短视频爬取(线程池) 示例代码 import requests from lxml import etree import random from multiprocessing.dummy import Pool # 多进程要传的方法,多进程pool.map()传的第二个参数是一个迭代器对象 # 而传的get_video方法也要有一个迭代器参数 def get_video(dic): headers = { 'User-Agent':'Mozilla/5.0 (Wind
-
C# String字符串案例详解
string是一种很特殊的数据类型,它既是基元类型又是引用类型,在编译以及运行时,.Net都对它做了一些优化工作,正式这些优化工作有时会迷惑编程人员,使string看起来难以琢磨.这篇文章共四节,来讲讲关于string的陌生一面. 一.恒定的字符串 要想比较全面的了解stirng类型,首先要清楚.Net中的值类型与引用类型. 在C#中,以下数据类型为值类型: bool.byte.char.enum.sbyte以及数字类型(包括可空类型) 以下数据类型为引用类型: class.interface
-
Java JNDI案例详解
JNDI的理解 JNDI是 Java 命名与文件夹接口(Java Naming and Directory Interface),在J2EE规范中是重要的规范之中的一个,不少专家觉得,没有透彻理解JNDI的意义和作用,就没有真正掌握J2EE特别是EJB的知识. 那么,JNDI究竟起什么作用?//带着问题看文章是最有效的 要了解JNDI的作用,我们能够从"假设不用JNDI我们如何做?用了JNDI后我们又将如何做?"这个问题来探讨. 没有JNDI的做法: 程序猿开发时,知道要开发訪
-
Android Intent与IntentFilter案例详解
1. 前言 在Android中有四大组件,这些组件中有三个组件与Intent相关,可见Intent在Android整个生态中的地位高度.Intent是信息的载体,用它可以去请求组件做相应的操作,但是相对于这个功能,Intent本身的结构更值得我们去研究. 2. Intent与组件 Intent促进了组件之间的交互,这对于开发者非常重要,而且它还能做为消息的载体,去指导组件做出相应的行为,也就是说Intent可以携带数据,传递给Activity/Service/Broa
-
Android Handler使用案例详解
什么是Handler? Handler可以发送和处理消息对象或Runnable对象,这些消息对象和Runnable对象与一个线程相关联.每个Handler的实例都关联了一个线程和线程的消息队列.当创建了一个Handler对象时,一个线程或消息队列同时也被创建,该Handler对象将发送和处理这些消息或Runnable对象. handler类有两种主要用途: 执行Runnable对象,还可以设置延迟. 两个线程之间发送消息,主要用来给主线程发送消息更新UI. 为什么要用Handler 解决多线程并
-
C# ThreadPool之QueueUserWorkItem使用案例详解
先看代码: //设置可以同时处于活动状态的线程池的请求数目. bool pool = ThreadPool.SetMaxThreads(8, 8); if (pool) { ThreadPool.QueueUserWorkItem(o => this.DoSomethingLong("参数1")); ThreadPool.QueueUserWorkItem(o => this.DoSomethingLong("参数2")); ThreadPool.Que
-
Java 处理高并发负载类优化方法案例详解
java处理高并发高负载类网站中数据库的设计方法(java教程,java处理大量数据,java高负载数据) 一:高并发高负载类网站关注点之数据库 没错,首先是数据库,这是大多数应用所面临的首个SPOF.尤其是Web2.0的应用,数据库的响应是首先要解决的. 一般来说MySQL是最常用的,可能最初是一个mysql主机,当数据增加到100万以上,那么,MySQL的效能急剧下降.常用的优化措施是M-S(主-从)方式进行同步复制,将查询和操作和分别在不同的服务器上进行操作.我推荐的是M-M-Slaves
-
Java 高并发的三种实现案例详解
提到锁,大家肯定想到的是sychronized关键字.是用它可以解决一切并发问题,但是,对于系统吞吐量要求更高的话,我们这提供几个小技巧.帮助大家减小锁颗粒度,提高并发能力. 初级技巧-乐观锁 乐观锁使用的场景是,读不会冲突,写会冲突.同时读的频率远大于写. 悲观锁的实现: 悲观的认为所有代码执行都会有并发问题,所以将所有代码块都用sychronized锁住 乐观锁的实现: 乐观的认为在读的时候不会产生冲突为题,在写时添加锁.所以解决的应用场景是读远大于写时的场景. 中级技巧-String.i
-
Java Spring之@Async原理案例详解
目录 前言 一.如何使用@Async 二.源码解读 总结 前言 用过Spring的人多多少少也都用过@Async注解,至于作用嘛,看注解名,大概能猜出来,就是在方法执行的时候进行异步执行. 一.如何使用@Async 使用@Async注解主要分两步: 1.在配置类上添加@EnableAsync注解 @ComponentScan(value = "com.wang") @Configuration @EnableAsync public class AppConfig { } 2.在想要异