Python实现笑脸检测+人脸口罩检测功能
目录
- 一、人脸图像特征提取方法
- 二、对笑脸数据集genki4k进行训练和测试(包括SVM、CNN),输出模型训练精度和测试精度(F1-score和ROC),实现检测图片笑脸和实时视频笑脸检测
- (一)环境、数据集准备
- (二)训练笑脸数据集genki4k
- (三)图片笑脸检测
- (四)实时视频笑脸检测
- 三、将笑脸数据集换成人脸口罩数据集,并对口罩数据集进行训练,编写程序实现人脸口罩检测
- (一)训练人脸口罩数据集
- (二)编程实现人脸口罩检测
一、人脸图像特征提取方法
https://www.jb51.net/article/219446.htm
二、对笑脸数据集genki4k进行训练和测试(包括SVM、CNN),输出模型训练精度和测试精度(F1-score和ROC),实现检测图片笑脸和实时视频笑脸检测
(一)环境、数据集准备
本文操作在Jupyter notebook平台进行,需要安装tensorflow、Keras库、Dlib库、和opencv-python等。
1、安装tensorflow、Keras库
https://www.jb51.net/article/219425.htm
2、win10 + anaconda3 + python3.6 安装tensorflow + keras的步骤详解
https://www.jb51.net/article/171039.htm
3、笑脸数据集下载
笑脸数据集下载链接: http://xiazai.jb51.net/202108/yuanma/smils_jb51.rar
(二)训练笑脸数据集genki4k
1、首先导入Keras库
import keras keras.__version__

2、读取笑脸数据集,然后将训练的数据和测试数据放入对应的文件夹
import os, shutil # The path to the directory where the original # dataset was uncompressed original_dataset_dir = 'C:\\Users\\asus\\Desktop\\test\\genki4k' # The directory where we will # store our smaller dataset base_dir = 'C:\\Users\\asus\\Desktop\\test\\smile_and_nosmile' os.mkdir(base_dir) # Directories for our training, # validation and test splits train_dir = os.path.join(base_dir, 'train') os.mkdir(train_dir) validation_dir = os.path.join(base_dir, 'validation') os.mkdir(validation_dir) test_dir = os.path.join(base_dir, 'test') os.mkdir(test_dir) # Directory with our training smile pictures train_smile_dir = os.path.join(train_dir, 'smile') os.mkdir(train_smile_dir) # Directory with our training nosmile pictures train_nosmile_dir = os.path.join(train_dir, 'nosmile') os.mkdir(train_nosmile_dir) # Directory with our validation smile pictures validation_smile_dir = os.path.join(validation_dir, 'smile') os.mkdir(validation_smile_dir) # Directory with our validation nosmile pictures validation_nosmile_dir = os.path.join(validation_dir, 'nosmile') os.mkdir(validation_nosmile_dir) # Directory with our validation smile pictures test_smile_dir = os.path.join(test_dir, 'smile') os.mkdir(test_smile_dir) # Directory with our validation nosmile pictures test_nosmile_dir = os.path.join(test_dir, 'nosmile') os.mkdir(test_nosmile_dir)

3、将笑脸图片和非笑脸图片放入对应文件夹
在上面程序中生成了一个名为smile_and_nosmile的文件夹,里面有三个子文件,分别存放训练、测试、验证数据,在这三个文件夹下还有smile和nosmile文件夹,我们需要将笑脸图片放入smile文件夹,将非笑脸图片放入nosmile文件夹。

3、打印每个数据集文件中的笑脸和非笑脸图片数
print('total training smile images:', len(os.listdir(train_smile_dir)))
print('total training nosmile images:', len(os.listdir(train_nosmile_dir)))
print('total validation smile images:', len(os.listdir(validation_smile_dir)))
print('total validation nosmile images:', len(os.listdir(validation_nosmile_dir)))
print('total test smile images:', len(os.listdir(test_smile_dir)))
print('total test nosmile images:', len(os.listdir(test_nosmile_dir)))
4、构建小型卷积网络
我们已经为MNIST构建了一个小型卷积网,所以您应该熟悉它们。我们将重用相同的通用结构:我们的卷积网将是一个交替的Conv2D(激活relu)和MaxPooling2D层的堆栈。然而,由于我们处理的是更大的图像和更复杂的问题,因此我们将使我们的网络相应地更大:它将有一个更多的Conv2D + MaxPooling2D阶段。这样既可以扩大网络的容量,又可以进一步缩小特征图的大小,这样当我们到达平坦层时,特征图就不会太大。在这里,由于我们从大小为150x150的输入开始(有点随意的选择),我们在Flatten层之前得到大小为7x7的feature map。
注意:feature map的深度在网络中逐渐增加(从32到128),而feature map的大小在减少(从148x148到7x7)。这是你会在几乎所有convnets中看到的模式。由于我们解决的是一个二元分类问题,我们用一个单一单元(一个大小为1的稠密层)和一个s型激活来结束网络。这个单元将对网络正在查看一个类或另一个类的概率进行编码。
from keras import layers
from keras import models
model = models.Sequential()
model.add(layers.Conv2D(32, (3, 3), activation='relu',
input_shape=(150, 150, 3)))
model.add(layers.MaxPooling2D((2, 2)))
model.add(layers.Conv2D(64, (3, 3), activation='relu'))
model.add(layers.MaxPooling2D((2, 2)))
model.add(layers.Conv2D(128, (3, 3), activation='relu'))
model.add(layers.MaxPooling2D((2, 2)))
model.add(layers.Conv2D(128, (3, 3), activation='relu'))
model.add(layers.MaxPooling2D((2, 2)))
model.add(layers.Flatten())
model.add(layers.Dense(512, activation='relu'))
model.add(layers.Dense(1, activation='sigmoid'))
让我们来看看要素地图的尺寸是如何随每个连续图层而变化的
model.summary()

让我们来看看特征地图的尺寸是如何随着每一个连续的层:为我们编译步骤,我们将一如既往地使用RMSprop优化器。由于我们用一个单一的乙状结肠单元结束我们的网络,我们将使用二进制交叉熵作为我们的损失
from keras import optimizers
model.compile(loss='binary_crossentropy',
optimizer=optimizers.RMSprop(lr=1e-4),
metrics=['acc'])
5、数据预处理
在将数据输入到我们的网络之前,应该将数据格式化为经过适当预处理的浮点张量。目前,我们的数据以JPEG文件的形式保存在硬盘上,因此将其导入网络的步骤大致如下:
- 读取图片文件
- 解码JPEG内容到RBG像素网格
- 把它们转换成浮点张量
- 将像素值(从0到255)缩放到[0,1]区间
from keras.preprocessing.image import ImageDataGenerator
# All images will be rescaled by 1./255
train_datagen = ImageDataGenerator(rescale=1./255)
test_datagen = ImageDataGenerator(rescale=1./255)
train_generator = train_datagen.flow_from_directory(
# This is the target directory
train_dir,
# All images will be resized to 150x150
target_size=(150, 150),
batch_size=20,
# Since we use binary_crossentropy loss, we need binary labels
class_mode='binary')
validation_generator = test_datagen.flow_from_directory(
validation_dir,
target_size=(150, 150),
batch_size=20,
class_mode='binary')
让我们看看其中一个生成器的输出:它生成150×150 RGB图像的批次(Shape(20,150,150,3))和二进制标签(Shape(20,))。20是每批样品的数量(批次大小)。注意,生成器无限期地生成这些批:它只是无休止地循环目标文件夹中的图像。因此,我们需要在某个点中断迭代循环。
for data_batch, labels_batch in train_generator:
print('data batch shape:', data_batch.shape)
print('labels batch shape:', labels_batch.shape)
break

使用生成器使我们的模型适合于数据
history = model.fit_generator(
train_generator,
steps_per_epoch=100,
epochs=30,
validation_data=validation_generator,
validation_steps=50)

这里使用fit_generator方法来完成此操作,对于我们这样的数据生成器,它相当于fit方法。它期望Python生成器作为第一个参数,它将无限期地生成成批的输入和目标,就像我们的示例一样。因为数据是不断生成的,所以在宣告一个纪元结束之前,生成器需要知道示例从生成器中抽取多少样本。这就是steps_per_epoch参数的作用:在从生成器中绘制完steps_per_epoch批处理之后,即在运行完steps_per_epoch梯度下降步骤之后,拟合过程将转到下一个epoch。在我们的例子中,批次是20个样本大,所以在我们看到2000个样本的目标之前将需要100个批次。
在使用fit_generator时,可以传递validation_data参数,就像fit方法一样。重要的是,允许这个参数本身是一个数据生成器,但是它也可以是Numpy数组的元组。如果您传递一个生成器作为validation_data,那么这个生成器将会不断生成成批的验证数据,因此您还应该指定validation_steps参数,它告诉流程从验证生成器提取多少批来进行评估。
保存模型
model.save('C:\\Users\\asus\\Desktop\\test\\smile_and_nosmile.h5')
在训练和验证数据上绘制模型的损失和准确性
import matplotlib.pyplot as plt
acc = history.history['acc']
val_acc = history.history['val_acc']
loss = history.history['loss']
val_loss = history.history['val_loss']
epochs = range(len(acc))
plt.plot(epochs, acc, 'bo', label='Training acc')
plt.plot(epochs, val_acc, 'b', label='Validation acc')
plt.title('Training and validation accuracy')
plt.legend()
plt.figure()
plt.plot(epochs, loss, 'bo', label='Training loss')
plt.plot(epochs, val_loss, 'b', label='Validation loss')
plt.title('Training and validation loss')
plt.legend()
plt.show()
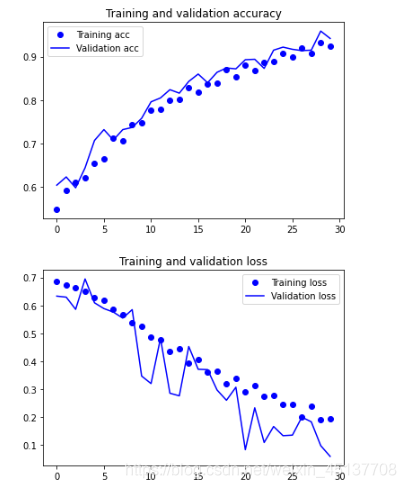
这些图具有过拟合的特点。我们的训练精度随着时间线性增长,直到接近100%,而我们的验证精度停留在70-72%。我们的验证损失在5个epoch后达到最小,然后停止,而训练损失继续线性下降,直到接近0。
6、数据增强
过度拟合是由于可供学习的样本太少,使我们无法训练一个模型来泛化到新的数据。给定无限的数据,我们的模型将暴露于手头数据分布的每一个可能方面:我们永远不会过度拟合。数据增强采用的方法是从现有的训练样本中生成更多的训练数据,方法是通过一系列随机变换来“增强”样本,从而产生看上去可信的图像。我们的目标是在训练时,我们的模型不会两次看到完全相同的图像。这有助于将模型暴露于数据的更多方面,并更好地泛化。
datagen = ImageDataGenerator(
rotation_range=40,
width_shift_range=0.2,
height_shift_range=0.2,
shear_range=0.2,
zoom_range=0.2,
horizontal_flip=True,
fill_mode='nearest')
- rotation_range是一个角度值(0-180),在这个范围内可以随机旋转图片
- width_shift和height_shift是范围(作为总宽度或高度的一部分),在其中可以随机地垂直或水平地转换图片
- shear_range用于随机应用剪切转换
- zoom_range用于在图片内部随机缩放
- horizontal_flip是用于水平随机翻转一半的图像——当没有假设水平不对称时(例如真实世界的图片)
- fill_mode是用于填充新创建像素的策略,它可以在旋转或宽度/高度移动之后出现。
查看增强后的图像
# This is module with image preprocessing utilities
from keras.preprocessing import image
fnames = [os.path.join(train_smile_dir, fname) for fname in os.listdir(train_smile_dir)]
# We pick one image to "augment"
img_path = fnames[3]
# Read the image and resize it
img = image.load_img(img_path, target_size=(150, 150))
# Convert it to a Numpy array with shape (150, 150, 3)
x = image.img_to_array(img)
# Reshape it to (1, 150, 150, 3)
x = x.reshape((1,) + x.shape)
# The .flow() command below generates batches of randomly transformed images.
# It will loop indefinitely, so we need to `break` the loop at some point!
i = 0
for batch in datagen.flow(x, batch_size=1):
plt.figure(i)
imgplot = plt.imshow(image.array_to_img(batch[0]))
i += 1
if i % 4 == 0:
break
plt.show()

如果我们使用这种数据增加配置训练一个新的网络,我们的网络将永远不会看到两次相同的输入。然而,它看到的输入仍然是高度相关的,因为它们来自少量的原始图像——我们不能产生新的信息,我们只能混合现有的信息。因此,这可能还不足以完全消除过度拟合。
为了进一步对抗过拟合,我们还将在我们的模型中增加一个Dropout层,就在密集连接分类器之前:
model = models.Sequential()
model.add(layers.Conv2D(32, (3, 3), activation='relu',
input_shape=(150, 150, 3)))
model.add(layers.MaxPooling2D((2, 2)))
model.add(layers.Conv2D(64, (3, 3), activation='relu'))
model.add(layers.MaxPooling2D((2, 2)))
model.add(layers.Conv2D(128, (3, 3), activation='relu'))
model.add(layers.MaxPooling2D((2, 2)))
model.add(layers.Conv2D(128, (3, 3), activation='relu'))
model.add(layers.MaxPooling2D((2, 2)))
model.add(layers.Flatten())
model.add(layers.Dropout(0.5))
model.add(layers.Dense(512, activation='relu'))
model.add(layers.Dense(1, activation='sigmoid'))
model.compile(loss='binary_crossentropy',
optimizer=optimizers.RMSprop(lr=1e-4),
metrics=['acc'])
用数据增强和退出来训练我们的网络:
train_datagen = ImageDataGenerator(
rescale=1./255,
rotation_range=40,
width_shift_range=0.2,
height_shift_range=0.2,
shear_range=0.2,
zoom_range=0.2,
horizontal_flip=True,)
# Note that the validation data should not be augmented!
test_datagen = ImageDataGenerator(rescale=1./255)
train_generator = train_datagen.flow_from_directory(
# This is the target directory
train_dir,
# All images will be resized to 150x150
target_size=(150, 150),
batch_size=32,
# Since we use binary_crossentropy loss, we need binary labels
class_mode='binary')
validation_generator = test_datagen.flow_from_directory(
validation_dir,
target_size=(150, 150),
batch_size=32,
class_mode='binary')
history = model.fit_generator(
train_generator,
steps_per_epoch=100,
epochs=100,
validation_data=validation_generator,
validation_steps=50)

这里程序会跑很久,我跑了几个小时,用GPU跑会快很多很多。
保存模型在convnet可视化部分使用:
model.save('C:\\Users\\asus\\Desktop\\test\\smile_and_nosmile_1.h5')
再看一次结果
acc = history.history['acc']
val_acc = history.history['val_acc']
loss = history.history['loss']
val_loss = history.history['val_loss']
epochs = range(len(acc))
plt.plot(epochs, acc, 'bo', label='Training acc')
plt.plot(epochs, val_acc, 'b', label='Validation acc')
plt.title('Training and validation accuracy')
plt.legend()
plt.figure()
plt.plot(epochs, loss, 'bo', label='Training loss')
plt.plot(epochs, val_loss, 'b', label='Validation loss')
plt.title('Training and validation loss')
plt.legend()
plt.show()

由于数据的增加和遗漏,我们不再过度拟合:训练曲线相当紧密地跟踪验证曲线。我们现在能够达到82%的精度,相对于非正则化模型有15%的改进。通过进一步利用正则化技术和调整网络参数(比如每个卷积层的滤波器数量,或者网络中的层数),我们可能能够获得更好的精度,可能达到86-87%。
7、优化提高笑脸图像分类模型精度
构建卷积网络
from keras import layers
from keras import models
from keras import optimizers
model = models.Sequential()
#输入图片大小是150*150 3表示图片像素用(R,G,B)表示
model.add(layers.Conv2D(32, (3,3), activation='relu', input_shape=(150 , 150, 3)))
model.add(layers.MaxPooling2D((2,2)))
model.add(layers.Conv2D(64, (3,3), activation='relu'))
model.add(layers.MaxPooling2D((2,2)))
model.add(layers.Conv2D(128, (3,3), activation='relu'))
model.add(layers.MaxPooling2D((2,2)))
model.add(layers.Conv2D(128, (3,3), activation='relu'))
model.add(layers.MaxPooling2D((2,2)))
model.add(layers.Flatten())
model.add(layers.Dense(512, activation='relu'))
model.add(layers.Dense(1, activation='sigmoid'))
model.compile(loss='binary_crossentropy', optimizer=optimizers.RMSprop(lr=1e-4),
metrics=['acc'])
model.summary()

(三)图片笑脸检测
# 单张图片进行判断 是笑脸还是非笑脸
import cv2
from keras.preprocessing import image
from keras.models import load_model
import numpy as np
model = load_model('smile_and_nosmile_1.h5')
img_path='C:\\Users\\asus\\Desktop\\test\\genki4k\\file2227.jpg'
img = image.load_img(img_path, target_size=(150, 150))
#img1 = cv2.imread(img_path,cv2.IMREAD_GRAYSCALE)
#cv2.imshow('wname',img1)
#cv2.waitKey(0)
#print(img.size)
img_tensor = image.img_to_array(img)/255.0
img_tensor = np.expand_dims(img_tensor, axis=0)
prediction =model.predict(img_tensor)
print(prediction)
if prediction[0][0]>0.5:
result='smile'
else:
result='nosmile'
print(result)


结果正确,错误率在0.0883181左右,反复找图片尝试,结果都是正确的。
(四)实时视频笑脸检测
import cv2
from keras.preprocessing import image
from keras.models import load_model
import numpy as np
import dlib
from PIL import Image
model = load_model('smile_and_nosmile_1.h5')
detector = dlib.get_frontal_face_detector()
video=cv2.VideoCapture(0)
font = cv2.FONT_HERSHEY_SIMPLEX
def rec(img):
gray=cv2.cvtColor(img,cv2.COLOR_BGR2GRAY)
dets=detector(gray,1)
if dets is not None:
for face in dets:
left=face.left()
top=face.top()
right=face.right()
bottom=face.bottom()
cv2.rectangle(img,(left,top),(right,bottom),(0,255,0),2)
img1=cv2.resize(img[top:bottom,left:right],dsize=(150,150))
img1=cv2.cvtColor(img1,cv2.COLOR_BGR2RGB)
img1 = np.array(img1)/255.
img_tensor = img1.reshape(-1,150,150,3)
prediction =model.predict(img_tensor)
print(prediction)
if prediction[0][0]<0.5:
result='nosmile'
else:
result='smile'
cv2.putText(img, result, (left,top), font, 2, (0, 255, 0), 2, cv2.LINE_AA)
cv2.imshow('smile detector', img)
while video.isOpened():
res, img_rd = video.read()
if not res:
break
rec(img_rd)
if cv2.waitKey(1) & 0xFF == ord('q'):
break
video.release()
cv2.destroyAllWindows()

视频检测正确,就是背景太黑了…
三、将笑脸数据集换成人脸口罩数据集,并对口罩数据集进行训练,编写程序实现人脸口罩检测
(一)训练人脸口罩数据集
人脸口罩数据集下载链接:
http://xiazai.jb51.net/202108/yuanma/mask_jb51.rar
训练人脸口罩数据集和训练笑脸数据集一样,只需改一下和相应的变量名和数据集。
(二)编程实现人脸口罩检测
import cv2
from keras.preprocessing import image
from keras.models import load_model
import numpy as np
import dlib
from PIL import Image
model = load_model('mask_and_nomask.h5')
detector = dlib.get_frontal_face_detector()
video=cv2.VideoCapture(0)
font = cv2.FONT_HERSHEY_SIMPLEX
def rec(img):
gray=cv2.cvtColor(img,cv2.COLOR_BGR2GRAY)
dets=detector(gray,1)
if dets is not None:
for face in dets:
left=face.left()
top=face.top()
right=face.right()
bottom=face.bottom()
cv2.rectangle(img,(left,top),(right,bottom),(0,255,0),2)
img1=cv2.resize(img[top:bottom,left:right],dsize=(150,150))
img1=cv2.cvtColor(img1,cv2.COLOR_BGR2RGB)
img1 = np.array(img1)/255.
img_tensor = img1.reshape(-1,150,150,3)
prediction =model.predict(img_tensor)
print(prediction)
if prediction[0][0]>0.5:
result='nomask'
else:
result='mask'
cv2.putText(img, result, (left,top), font, 2, (0, 255, 0), 2, cv2.LINE_AA)
cv2.imshow('mask detector', img)
while video.isOpened():
res, img_rd = video.read()
if not res:
break
rec(img_rd)
if cv2.waitKey(1) & 0xFF == ord('q'):
break
video.release()
cv2.destroyAllWindows()
运行结果:
不戴口罩

戴口罩

人脸口罩检测正确!
虽然人脸口罩检测正确,但是精度还是不高,因为我的数据集里面戴口罩得的图像太少了,朋友们可以多找一些戴口罩的图片以提高精度,后续我也会不断完善~
到此这篇关于Python实现笑脸检测+人脸口罩检测的文章就介绍到这了,更多相关Python人脸口罩检测内容请搜索我们以前的文章或继续浏览下面的相关文章希望大家以后多多支持我们!
相关推荐
-
python 利用turtle库绘制笑脸和哭脸的例子
我就废话不多说了,直接上代码吧! import turtle turtle.pensize(5) turtle.pencolor("yellow") turtle.fillcolor("red") turtle.penup() turtle.goto(0,-200) turtle.pendown() turtle.circle(200) turtle.penup() turtle.goto(-100,50) turtle.pendown() turtle.begin
-

python使用pygame实现笑脸乒乓球弹珠球游戏
今天我们用python和pygame实现一个乒乓球的小游戏,或者叫弹珠球游戏. 笑脸乒乓球游戏功能介绍 乒乓球游戏功能如下: 乒乓球从屏幕上方落下,用鼠标来移动球拍,使其反弹回去,并获得得分,如果没有接到该球,则失去一条命.玩家有一定数量的命如5. 游戏设计思路 根据游戏规则,我们需要 1.初始化游戏环境 2.画出乒乓球,球拍等 3.设置乒乓球的运动,并监听鼠标,以移动球拍 4.判断乒乓球被接住与否 5.游戏是否结束,是否再玩. 代码实现 import pygame pygame.init()
-
python基于Opencv实现人脸口罩检测
一.开发环境 python 3.6.6 opencv-python 4.5.1 二.设计要求 1.使用opencv-python对人脸口罩进行检测 三.设计原理 设计流程图如图3-1所示, 图3-1 口罩检测流程图 首先进行图片的读取,使用opencv的haar鼻子特征分类器,如果检测到鼻子,则证明没有戴口罩.如果检测到鼻子,接着使用opencv的haar眼睛特征分类器,如果没有检测到眼睛,则结束.如果检测到眼睛,则把RGB颜色空间转为HSV颜色空间.进行口罩区域的检测.口罩区域检测流程是首先把
-
Python实现笑脸检测+人脸口罩检测功能
目录 一.人脸图像特征提取方法 二.对笑脸数据集genki4k进行训练和测试(包括SVM.CNN),输出模型训练精度和测试精度(F1-score和ROC),实现检测图片笑脸和实时视频笑脸检测 (一)环境.数据集准备 (二)训练笑脸数据集genki4k (三)图片笑脸检测 (四)实时视频笑脸检测 三.将笑脸数据集换成人脸口罩数据集,并对口罩数据集进行训练,编写程序实现人脸口罩检测 (一)训练人脸口罩数据集 (二)编程实现人脸口罩检测 一.人脸图像特征提取方法 https://www.jb51.ne
-
python版opencv摄像头人脸实时检测方法
OpenCV版本3.3.0,注意模型文件的路径要改成自己所安装的opencv的模型文件的路径,路径不对就会报错,一般在opencv-3.3.0/data/haarcascades 路径下 import numpy as np import cv2 face_cascade = cv2.CascadeClassifier('haarcascade_frontalface_default.xml') cap = cv2.VideoCapture(0) while True: ret,img = ca
-
Python+MediaPipe实现检测人脸功能详解
目录 MediaPipe概述 人脸检测 MediaPipe概述 谷歌开源MediaPipe于2019年6月首次推出.它的目标是通过提供一些集成的计算机视觉和机器学习功能,使我们的生活变得轻松. MediaPipe是用于构建多模态(例如视频.音频或任何时间序列数据).跨平台(即eAndroid.IOS.web.边缘设备)应用ML管道的框架. Mediapipe还促进了机器学习技术在各种不同硬件平台上的演示和应用程序中的部署. 应用 人脸检测 多手跟踪 头发分割 目标检测与跟踪 目标:三维目标检测与
-
Python基于OpenCV实现人脸检测并保存
本文实例为大家分享了Python基于OpenCV实现人脸检测,并保存的具体代码,供大家参考,具体内容如下 安装opencv 如果安装了pip的话,Opencv的在windows的安装可以直接通过cmd命令pip install opencv-python(只需要主要模块),也可以输入命令pip install opencv-contrib-python(如果需要main模块和contrib模块) 详情可以点击此处 导入opencv import cv2 所有包都包含haarcascade文件.这
-
python+mediapipe+opencv实现手部关键点检测功能(手势识别)
目录 一.mediapipe是什么? 二.使用步骤 1.引入库 2.主代码 3.识别结果 补充: 一.mediapipe是什么? mediapipe官网 二.使用步骤 1.引入库 代码如下: import cv2 from mediapipe import solutions import time 2.主代码 代码如下: cap = cv2.VideoCapture(0) mpHands = solutions.hands hands = mpHands.Hands() mpDraw = so
-
Python OpenCV调用摄像头检测人脸并截图
本文实例为大家分享了Python OpenCV调用摄像头检测人脸并截图的具体代码,供大家参考,具体内容如下 注意:需要在python中安装OpenCV库,同时需要下载OpenCV人脸识别模型haarcascade_frontalface_alt.xml,模型可在OpenCV-PCA-KNN-SVM_face_recognition中下载. 使用OpenCV调用摄像头检测人脸并连续截图100张 #-*- coding: utf-8 -*- # import 进openCV的库 import cv2
-
Python环境使用OpenCV检测人脸实现教程
一.文章概述 本文将要讲述的是Python环境下如何用OpenCV检测人脸,本文的主要内容分为: 1.检测图片中的人脸 2.实时检测视频中出现的人脸 3.用运设备的摄像头实时检测人脸 二:准备工作 提前做的准备: 安装好Python3 下载安装OpenCV库,方法是 pip install opencv-python -i https://mirrors.aliyun.com/pypi/simple/ --trusted-host=mirrors.aliyun.com/pypi/simple 下
-
python使用dlib进行人脸检测和关键点的示例
#!/usr/bin/env python # -*- coding:utf-8-*- # file: {NAME}.py # @author: jory.d # @contact: dangxusheng163@163.com # @time: 2020/04/10 19:42 # @desc: 使用dlib进行人脸检测和人脸关键点 import cv2 import numpy as np import glob import dlib FACE_DETECT_PATH = '/home/b
-
python中watchdog文件监控与检测上传功能
引言 上一篇介绍完了观察者模式的原理,本篇想就此再介绍一个小应用,虽然我也就玩了一下午,是当时看observer正好找到的,以及还有Django-observer,但Django很久没用了,所以提下这个作为一个笔记. watchdog介绍 Watchdog的中文的"看门狗",有保护的意思.最早引入Watchdog是在单片机系统中,由于单片机的工作环境容易受到外界磁场的干扰,导致程序"跑飞",造成整个系统无法正常工作,因此,引入了一个"看门狗",对