Python合并pdf文件的工具
如果你需要一个PDF文件合并工具,那么本文章完全可以满足您的要求。哈喽,大家好呀,这里是滑稽研究所。不多废话,本期我们利用Python合并把多个pdf文件合并为一个。我们提前准备了5个pdf文件,来验证代码。
源代码:
import os
from PyPDF2 import PdfFileReader, PdfFileWriter
# 使用os模块的walk函数,搜索出指定目录下的全部PDF文件
# 获取同一目录下的所有PDF文件的绝对路径
def getFileName(filedir):
file_list = [os.path.join(root, filespath) \
for root, dirs, files in os.walk(filedir) \
for filespath in files \
if str(filespath).endswith('pdf')
]
return file_list if file_list else []
# 合并同一目录下的所有PDF文件
def MergePDF(filepath, outfile):
output = PdfFileWriter()
outputPages = 0
pdf_fileName = getFileName(filepath)
if pdf_fileName:
for pdf_file in pdf_fileName:
print("路径:%s"%pdf_file)
# 读取源PDF文件
input = PdfFileReader(open(pdf_file, "rb"))
# 获得源PDF文件中页面总数
pageCount = input.getNumPages()
outputPages += pageCount
print("页数:%d"%pageCount)
# 分别将page添加到输出output中
for iPage in range(pageCount):
output.addPage(input.getPage(iPage))
print("合并后的总页数:%d."%outputPages)
# 写入到目标PDF文件
outputStream = open(os.path.join(filepath, outfile), "wb")
output.write(outputStream)
outputStream.close()
print("PDF文件合并完成!")
else:
print("没有可以合并的PDF文件!")
# 主函数
def main():
file_dir = input('请输入存有Pdf的文件夹').replace('/','//')# 存放PDF的原文件夹
outfile = "pick_me.pdf" # 输出的PDF文件的名称
MergePDF(file_dir, outfile)
print('done')
main()
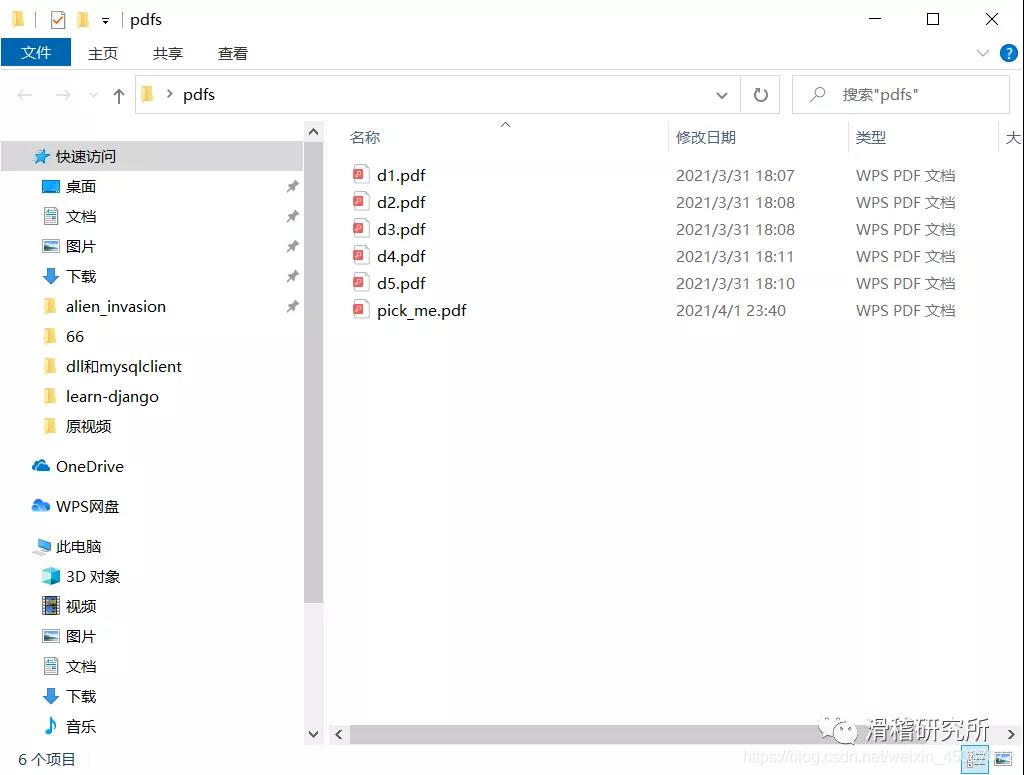
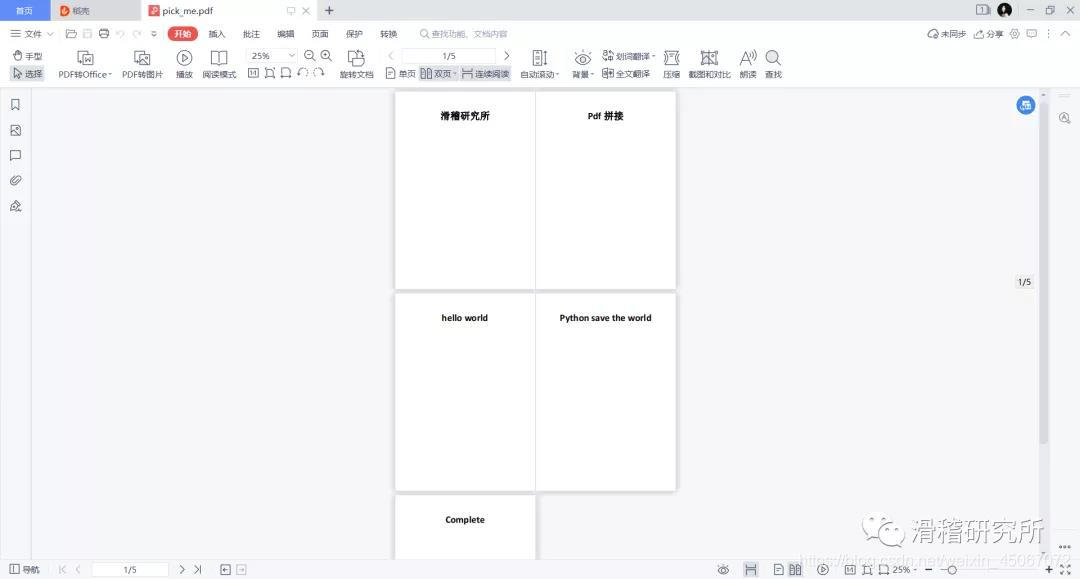
可以看到5个PDF文件合并到了一起,那么到这里就结束了吗?当然不是,代码运行遇到PDF文件中文件格式较多时,比如多图,word格式等,会出现以下报错。
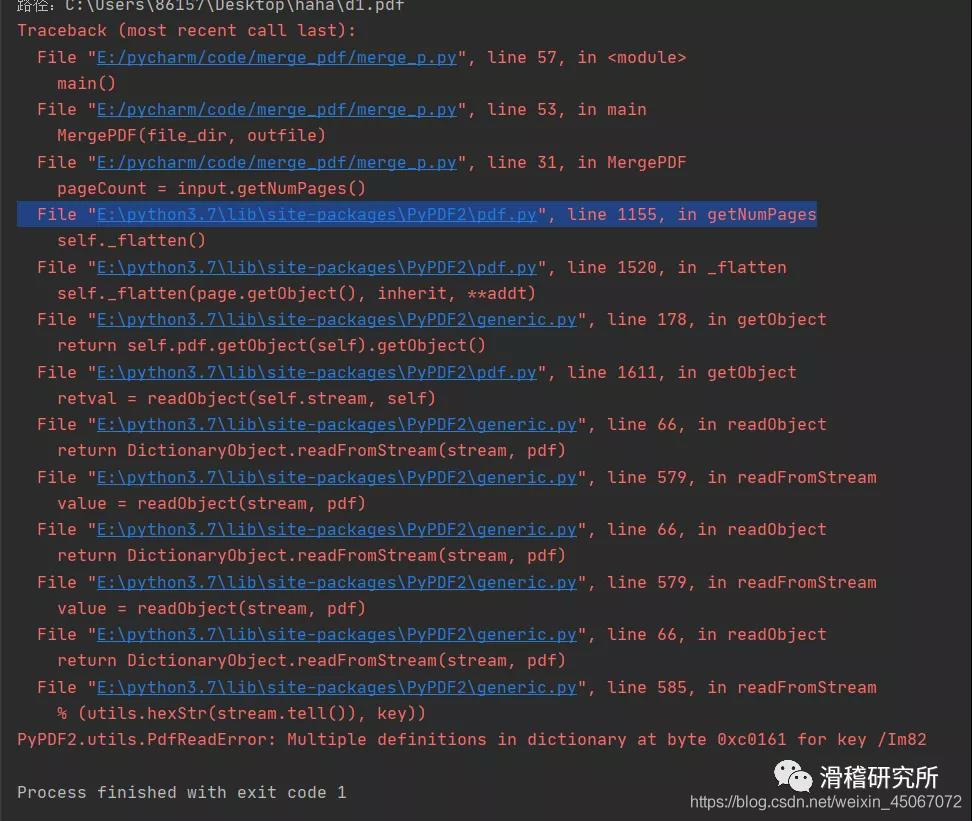
最后一行报错的意思为:
PyPDF2。utils.PdfReadError:对于键/Im82,字典中字节0xc0161处有多个定义
通俗一点就是说遇到了一个多义词,程序不知道该取哪个意思了。我们点进pdf.py文件里,找到下图位置。
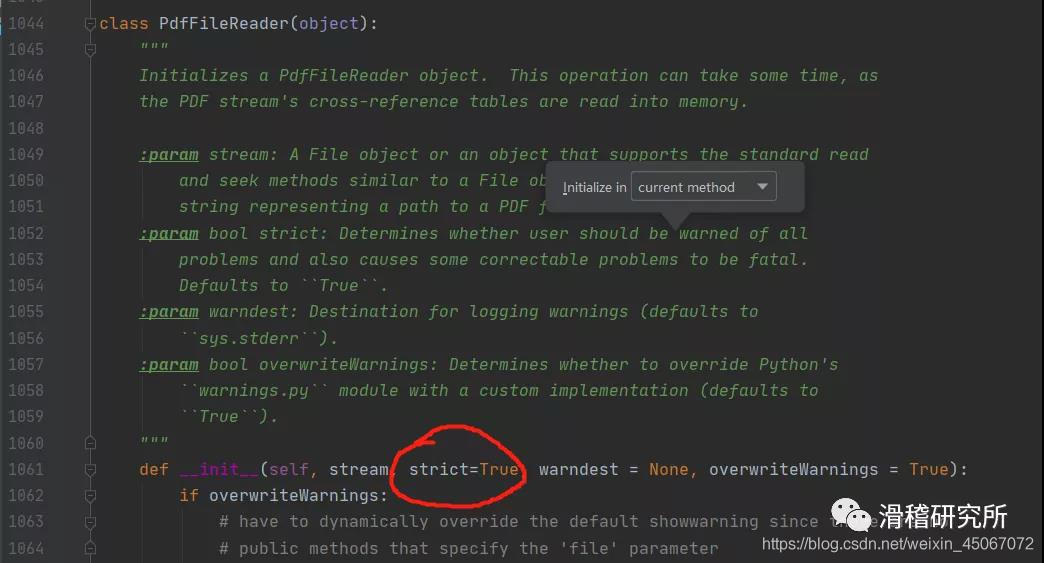
严格模式默认是打开的,我们改成False。
构造方法:
PyPDF2.PdfFileReader(stream,strict = True,warndest = None,overwriteWarnings = True)
stream:File 对象或支持与 File 对象类似的标准读取和查找方法的对象,也可以是表示 PDF 文件路径的字符串。
strict(bool):确定是否应该警告用户所用的问题,也导致一些可纠正的问题是致命的,默认是 True
warndest : 记录警告的目标(默认是 sys.stderr)
overwriteWarnings(bool):确定是否 warnings.py 用自定义实现覆盖 Python 模块(默认为 True)
我们重新运行程序.

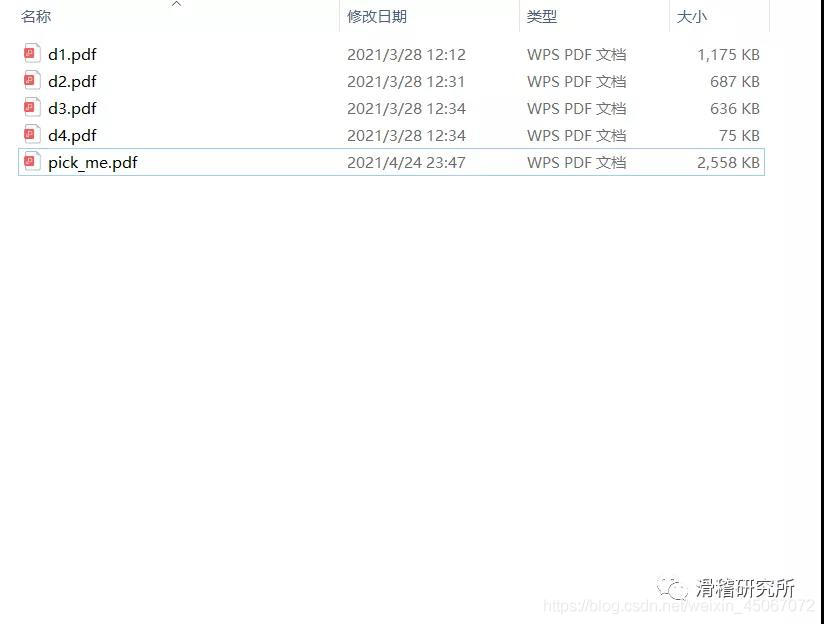
打开文件夹,可以看到我们的文件已经合并好了,打开之后的格式也是没有错误的。
那么,问题解决。
如果你只是需要应该PDF合并工具代码直接拿走用即可,如果你想学习pypdf2这个实用的库,并且希望对这段代码进行改进来适配自己的情况
到此这篇关于Python合并pdf文件的文章就介绍到这了,更多相关Python合并pdf文件内容请搜索我们以前的文章或继续浏览下面的相关文章希望大家以后多多支持我们!
相关推荐
-
python如何将多个PDF进行合并
背景 由于工作性质,经常面对不同的问题,某些场景下SQL+Excel.常用办公软件不能处理,这时到网上找一些案例,自己动手用python处理.后续,借此博客记录比较典型的处理过程. 后续,陆续实际处理的问题,如 1. 合并PDF 2. 拆分PDF 3. 敏感字段MD5脱敏 4. 从非架构化的大文本文件中提取指定条件的记录 需求 工作和生活中有时会遇到将多个pdf文件,合并成一个大文件的情况.例如,扫描时,普通扫描仪或打印机一页生成一个PDF,而一份资料实际多页.Adobe的收费版有合并功能,我们
-

Python实现合并同一个文件夹下所有PDF文件的方法示例
本文实例讲述了Python实现合并同一个文件夹下所有PDF文件的方法.分享给大家供大家参考,具体如下: 一.需求说明 下载了网易云课堂的吴恩达免费的深度学习的pdf文档,但是每一节是一个pdf,我把这些PDF文档放在一个文件夹下,希望合并成一个PDF文件.于是写了一个python程序,很好的解决了这个问题. 二.数据形式 三.合并效果 四.python代码实现 # -*- coding:utf-8*- import sys reload(sys) sys.setdefaultencoding('
-
Python合并同一个文件夹下所有PDF文件的方法
一.需求说明 下载了网易云课堂的吴恩达免费的深度学习的pdf文档,但是每一节是一个pdf,我把这些PDF文档放在一个文件夹下,希望合并成一个PDF文件.于是写了一个python程序,很好的解决了这个问题. 二.数据形式 三.合并效果 四.python代码实现 # -*- coding:utf-8*- import sys reload(sys) sys.setdefaultencoding('utf-8') import os import os.path from pyPdf import P
-
Python多图片合并PDF的方法
python多图片合并pdf 起因 一个做美工的朋友需要将多个图片jpg .png 合并起来,PS操作太慢了所以用了python进行完成这个任务 代码 #!/usr/bin/env python # -*- coding: utf-8 -*- # @File : 2.py # @Author: huifer # @Date : 2018/12/20 from PIL import Image import os def rea(pdf_name): file_list = os.listdir(
-
Python中使用pypdf2合并、分割、加密pdf文件的代码详解
朋友需要对一个pdf文件进行分割,在网上查了查发现这个pypdf2可以完成这些操作,所以就研究了下这个库,并做一些记录.首先pypdf2是python3版本的,在之前的2版本有一个对应pypdf库. 可以使用pip直接安装: pip install pypdf2 官方文档: pythonhosted.org/PyPDF2/ 里面主要有这几个类: PdfFileReader . 该类主要提供了对pdf文件的读操作,其构造方法为: PdfFileReader(stream, strict=True,
-
Python结合ImageMagick实现多张图片合并为一个pdf文件的方法
本文实例讲述了Python结合ImageMagick实现多张图片合并为一个pdf文件的方法.分享给大家供大家参考,具体如下: 前段时间买了不少书,现在手头的书籍积累的越来越多,北京这边租住的小屋子空间越来越满了.自从习惯了笔记本触摸板的手势操作之后,我偶觉得使用电脑看电子文档也挺享受的.于是想把自己的部分书籍使用手机拍照,然后合并成一个pdf文件. 最初尝试过找成熟的Windows软件,但是始终没有找到一个好用的软件.想写脚本处理,一直也没有实现.偶然查看ImageMagick软件的说明,找到了
-
Python合并pdf文件的工具
如果你需要一个PDF文件合并工具,那么本文章完全可以满足您的要求.哈喽,大家好呀,这里是滑稽研究所.不多废话,本期我们利用Python合并把多个pdf文件合并为一个.我们提前准备了5个pdf文件,来验证代码. 源代码: import os from PyPDF2 import PdfFileReader, PdfFileWriter # 使用os模块的walk函数,搜索出指定目录下的全部PDF文件 # 获取同一目录下的所有PDF文件的绝对路径 def getFileName(filedi
-
Python对PDF文件的常用操作方法详解
目录 工具 从PDF中提取文本 旋转和叠加页面 加密PDF文件 创建PDF文件 补充 工具 python3.7 Pycharm PDF PyPDF2 reportlab 从PDF中提取文本 PyPDF2没有办法从PDF文档中提取图像.图表或其他媒体,但它可以提取文本,并将其返回为Python字符串. import PyPDF2 reader = PyPDF2.PdfFileReader('test.pdf') page = reader.getPage(0) print(page.extract
-
Python合并ts文件至mp4格式及解密教程详解
m3u8是什么格式?m3u8是苹果公司推出的视频播放标准,是m3u的一种,只是编码格式采用的是UTF-8. 使用m3u8格式文件主要因为可以实现多码率视频的适配,视频网站可以根据用户的网络带宽情况,自动为客户端匹配一个合适的码率文件进行播放,从而保证视频的流畅度. m3u8准确来说是一种索引文件,使用m3u8文件实际上是通过它来解析对应的放在服务器上的视频网络地址,从而实现在线播放. 它将视频切割成一小段一小段的ts格式的视频文件,然后存在服务器中(现在为了减少I/o访问次数,一般存在服务器的内
-
一文教会你用Python读取PDF文件
目录 实战场景 Python PDF 实战编码 补充 实战场景 Python 工程师在日常的工作中,经常会碰到解析和处理PDF文件的情况,实战中需求主要分为如下情况: 提取 PDF 中的文字 将 PDF 中每页转换为图片 word 转换为PDF PDF生成,编辑,导入导出 PDF在线渲染 除了最后一项需要前端配合以外,其余内容都可以直接在 python 端进行实现. 本次实战选择 pdfplumber 库进行学习,可以提前安装该库,不过有一点需要注意,该库主要用于读取 PDF 进行操作,写入和编
-
Python操作PDF文件之实现A3页面转A4
目录 1. 需求概述 2. 代码实现 1. 需求概述 最近接到一份PDF资料需要打印,奈何页面是如图所示的A3格式的,奈何目前条件只支持打印A4. 我想要把每页的一个大页面裁成两个小的页面,以便打印工作的顺利进行. 遂决定写一段python代码,来实现该功能. 2. 代码实现 首先在当前目录下创建一个python文件,并编辑以下代码. 导入相关库后,代码共定义三个函数, 第一个函数将pdf拆分为多个图片,放在自动新建的images1文件夹中. 第二个函数则将每个图片进行切割,切割后的图片放在自动
-
Python生成pdf文件的方法
本文实例演示了Python生成pdf文件的方法,是比较实用的功能,主要包含2个文件.具体实现方法如下: pdf.py文件如下: #!/usr/bin/python from reportlab.pdfgen import canvas def hello(): c = canvas.Canvas("helloworld.pdf") c.drawString(100,100,"Hello,World") c.showPage() c.save() hello() di
-
如何用Python合并lmdb文件
由于Caffe使用的存储图像的数据库是lmdb,因此有时候需要对lmdb文件进行操作,本文主要讲解如何用Python合并lmdb文件.没有lmdb支持的,需要用pip命令安装. pip install lmdb 代码及注释如下: # coding=utf-8 # filename: merge_lmdb.py import lmdb # 将两个lmdb文件合并成一个新的lmdb def merge_lmdb(lmdb1, lmdb2, result_lmdb): print 'Merge sta
-
如何使用python进行pdf文件分割
这篇文章主要介绍了如何使用python进行pdf文件分割,文中通过示例代码介绍的非常详细,对大家的学习或者工作具有一定的参考学习价值,需要的朋友可以参考下 代码如下 import os from pyPdf import PdfFileWriter, PdfFileReader def split(pdf_file, delta, output_dir): if not os.path.exists(output_dir): os.makedirs(output_dir) if not os.p
-
基于Python制作一个文件解压缩工具
经常由于各种压缩格式的不一样用到文件的解压缩时就需要下载不同的解压缩工具去处理不同的文件,以至于桌面上的压缩工具就有三四种,于是使用python做了一个包含各种常见格式的文件解压缩的小工具. 常见的压缩格式主要是下面的四种格式: zip 格式的压缩文件,一般使用360压缩软件进行解压缩. tar.gz 格式的压缩文件,一般是在linux系统上面使用tar命令进行解压缩. rar 格式的压缩文件,一般使用rar压缩软件进行解压缩. 7z 格式的压缩文件,一般使用7-zip压缩软件进行解压缩. 导入
-
使用Python操作PDF文件
从PDF读取文本内容和从已经有的文档生成新的PDF. 需要用到的模块是PyPDF2. mstamy2/PyPDF2: A utility to read and write PDFs with Python (github.com) 同时,还要关注较新的PyPDF4包,因为它很快就会取代PyPDF2. claird/PyPDF4: A utility to read and write PDFs with Python (github.com) 也可以看看pdfrw包,它也可以执行许多与PyPD