python数据可视化 – 利用Bokeh和Bottle.py在网页上展示你的数据
目录
- 1. 文章重点和项目介绍
- 2. 数据集研究和图表准备
- 2.1 导入数据集
- 2.2 绘制图表
- 图表1:2019年上海,北京,深圳三地的每天AQI变化曲线
- 图表2:2019年上海,北京,深圳三地的每月平均AQI对比
- 图表3:2017年到2019年北京每月平均AQI对比
- 3. Bottle网页应用
- 3.1 文件夹结构
- 3.2 路由
- 3.3 模板实现
- 3.4 启动网页服务
- 4. 将Bokeh和Bottle集成在一起
- 4.1 模板修改
- 4.2 Python代码集成
- 5. 部署应用到Heroku
- 6. 参考文档
在数据科学中,通过图表将数据可视化是一个很重要的工作,在开始数据分析之前,通过数据可视化可以帮助我们理解数据,而更重要的是,在完成分析、预测等等过程之后,我们需要通过数据可视化讲结论展示出来。通过网页创建可以交互的图表是展示数据的一个重要手段。
1. 文章重点和项目介绍
本文的重点将是展示如何将bokeh和bottle集成在一起,并部署到服务器上,供他人访问查阅,因此不会在bokeh和bottle,以及pandas的相关代码具体实现细节上面面俱到,但是对于我们实现的代码,还是会进行讲解(可能不会那么深入)。本文将选取中国2017到2019年的AQI数据作为项目的数据集,然后利用这些数据绘制3张表格(一张折线图和两张带分组的柱状图),然后通过bottle和bootstrap前端模板建立一个展示网页,最后会将这个网页应用部署到Heroku上边(这一步作为参考,你可以通过localhost访问本机服务,或者选取其他云服务商的服务器)。
本文使用的数据集和代码实现都可以在下边这个github仓库中找到:
https://github.com/pythonlibrary/bokeh-bottlepy
我已经将数据集进行过清理,数据集中包含规整的从2017年到2019年的各个城市的日AQI平均值。
2. 数据集研究和图表准备
在本节中,和大多数数据分析项目一样,我们将使用jupyter notebook作为我们的环境,因为这个工具能够方便的实现代码修改和及时的代码结果展示。
首先完成最重要的事情,导入必要的python库
import numpy as np import pandas as pd from bokeh.plotting import figure, show from bokeh.models import ColumnDataSource, HoverTool from bokeh.transform import dodge from bokeh.io import output_notebook
然后在notebook中运行,下边代码来初始化bokeh,bokeh可以将图标输出成不同的格式文件,如html等,但是要在notebook中显示,则需要在最开始的时候指明。
output_notebook()
成功执行完以后,notebook会提示成功加载bokeh环境,如下:
2.1 导入数据集
我们使用pandas的read_csv方法读入数据集,并将一些城市的数据拿出来,因为读入以后date一列的数据格式不是pandas datatime,我们在这里做一个转换,方便后边绘图使用,因为数据集中还有一些其他空气质量指标例如PM2.5等,我们仅仅选取AQI作为关注重点形成新的数据帧 df
cities = ['上海', '北京', '杭州', '宁波', '保定', '南京', '苏州', '深圳', '厦门', '广州']
df = pd.read_csv('AQI_merged.csv')
df['date'] = pd.to_datetime(df['date'])
df = df.sort_values(by='date').reset_index(drop=True)
df = df[df['type']=='AQI']
我们的基础数据帧(Dataframe)创建好以后,让我们来看一下它里边包含了什么数据,我们使用如下代码提取2019年的数据,并且在notebook中展示前5条记录。
df_2019_day = df[df['date']>='2019-01-01'] df_2019_day.head()

可以看出,在数据帧中,按照每一天为行,记录了当天几个城市的AQI值。
2.2 绘制图表
利用导入的数据,我们将绘制3张图表:
2019年上海,北京,深圳三地的每天AQI变化曲线(曲线图)
2019年上海,北京,深圳三地的每月平均AQI对比(柱状图)
2017年到2019年北京每月平均AQI对比(柱状图)
图表1:2019年上海,北京,深圳三地的每天AQI变化曲线
利用刚刚我们创建的df_2019_day数据帧,使用如下代码绘制图表,注意,我们使用了Bokeh提供的ColumnDataSource的方式来给bokeh图表传递数据。
简单说明一下:我们先使用figure创建了一个空的图画,然后用line方法画了上海的数据,然后重复line方法两次在图画上添加了另外两个城市的数据,最后,通过add_tools方法添加了一个鼠标悬停提示,用于显示鼠标位置的AQI值。
source = ColumnDataSource(df_2019_day)
p = figure(x_axis_type="datetime", title="2019年AQI日均平均变化曲线", plot_width=900, plot_height=400)
p.line('date', '上海', line_color='blue', legend_label='上海', source=source)
p.line('date', '北京', line_color='green', legend_label='北京', source=source)
p.line('date', '深圳', line_color='orange', legend_label='深圳', source=source)
p.legend.location = "top_right"
p.add_tools(HoverTool(tooltips=[("AQI", "$y")]))
show(p)

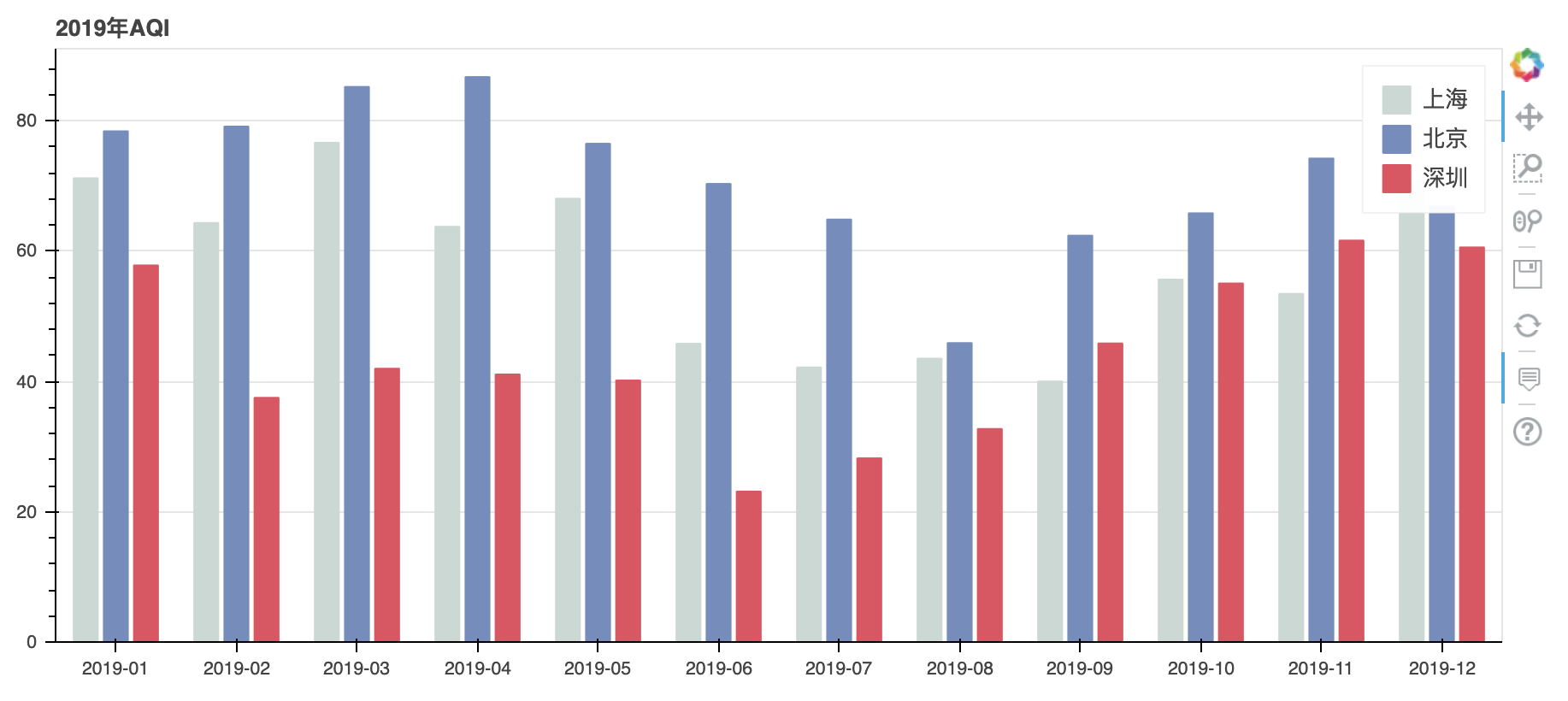
图表2:2019年上海,北京,深圳三地的每月平均AQI对比
我们想要画出每月平均AQI,而数据帧中包含的是每日的AQI,因此,利用dataframe的groupby方法,可以求得每月的平均值。并新建了一列month来存放月信息。最后通过head方法查看下我们获得的新的数据帧是否包含了按月平均的AQI信息。
pd.options.mode.chained_assignment = None
df_2019_day['month'] = df_2019_day['date'].apply(lambda x: x.strftime('%Y-%m'))
df_2019_month = df_2019_day.groupby(by='month').mean().reset_index()
df_2019_month.head()
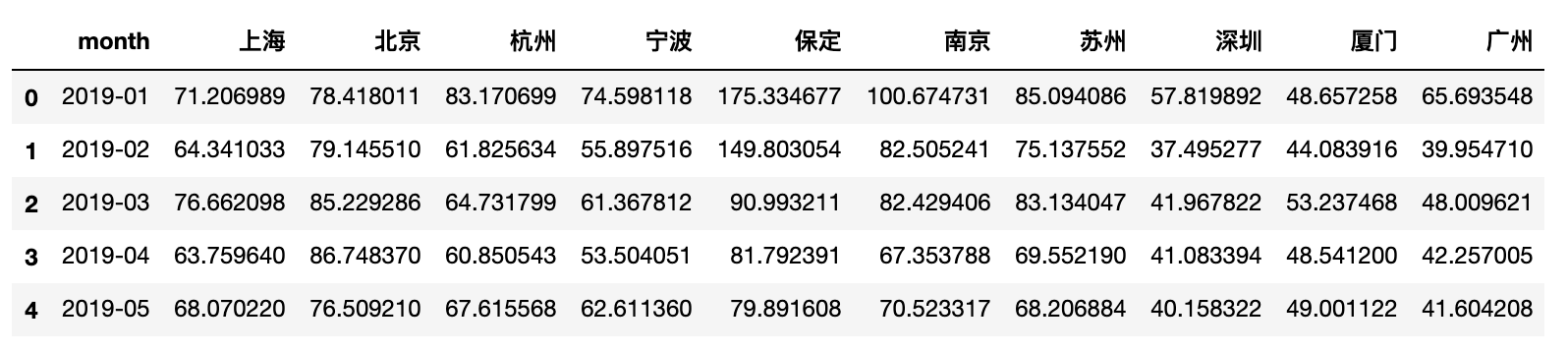
数据集处理结果符合我们的预期,接下来使用这个数据集绘制第二张图表。因为我们想要比较不同城市同一个月的AQI,因此我们的柱状图需要分组显示,这里使用了bokeh中的dodge方式,每一个dodge为一个城市的数据,并指明了在图表上的相对位置。
source = ColumnDataSource(df_2019_month)
p = figure(x_range=list(df_2019_month['month']), title="2019年AQI", plot_width=900, plot_height=400)
p.vbar(x=dodge('month', -0.25, range=p.x_range), top='上海', width=0.2, color="#c9d9d3", legend_label="上海", source=source)
p.vbar(x=dodge('month', 0, range=p.x_range), top='北京', width=0.2, color="#718dbf", legend_label="北京", source=source)
p.vbar(x=dodge('month', 0.25, range=p.x_range), top='深圳', width=0.2, color="#e84d60", legend_label="深圳", source=source)
p.xgrid.grid_line_color = None
p.y_range.start = 0
p.add_tools(HoverTool(tooltips=[("时间", "@month"), ("上海平均AQI", "@{上海}"), ("北京平均AQI", "@{北京}"), ("深圳平均AQI", "@{深圳}")]))
show(p)
图表3:2017年到2019年北京每月平均AQI对比
跟图表2 类似我们对数据帧进行必要的处理,同时因为我们要显示不同的年月的对比,所以讲年份和月份单独放置到year和month列中。
df['date_ym'] = df['date'].apply(lambda x: x.strftime('%Y-%m'))
df_month = df.groupby(by='date_ym').mean().reset_index()
df_month['month'] = df_month['date_ym'].apply(lambda x: x.split('-')[-1])
df_month['year'] = df_month['date_ym'].apply(lambda x: x.split('-')[0])
df_month.head()

然后创建3个数据帧,每个仅包含一年的数据
df_2017 = df_month[df_month['year']=='2017'][['month', '北京']] df_2018 = df_month[df_month['year']=='2018'][['month', '北京']] df_2019 = df_month[df_month['year']=='2019'][['month', '北京']]
最后,还是通过相同的bokeh方法,绘制新的柱状图。
source_2017 = ColumnDataSource(df_2017)
source_2018 = ColumnDataSource(df_2018)
source_2019 = ColumnDataSource(df_2019)
p = figure(x_range=list(df_2017['month']), title="2017-2019年北京AQI对比", plot_width=900, plot_height=400)
p.vbar(x=dodge('month', -0.25, range=p.x_range), top='北京', width=0.2, color="#c9d9d3", legend_label="2017", source=source_2017)
p.vbar(x=dodge('month', 0, range=p.x_range), top='北京', width=0.2, color="#718dbf", legend_label="2018", source=source_2018)
p.vbar(x=dodge('month', 0.25, range=p.x_range), top='北京', width=0.2, color="#e84d60", legend_label="2019", source=source_2019)
p.xgrid.grid_line_color = None
p.y_range.start = 0
p.add_tools(HoverTool(tooltips=[("时间", "@month"), ("AQI", "@{北京}")]))
show(p)

到这里我们的3张图表已经准备好了,但是他们都是在notebook中运行的,后边我们将对这些代码进行简单的转化,并嵌入到bottle网页应用中。
3. Bottle网页应用
bottle是一个超轻量级的python web框架,我们在本文中选择了bottle而没有选择flask或者Django的原因就在于它的超轻量级,可以快速的搭建网页应用,对于以仅仅做数据展示为目的的网页应用,使用bottle可以让你快速上手,让你更专注于数据分析。
我们将采用bootstrap前端模板加bottle内置的模板引擎的方式来实现这个应用,为了快速实现这个目标,我们选取了https://github.com/arsho/bottle-bootstrap这个项目作为我们的初始代码,所以,本文项目中使用到的网页应用代码99%的实现来自于这个项目,我们仅仅做了一点改动。在本节内容中,我们会讲解一下bottle应用的重点代码和概念。
本文对应的代码可以在 https://github.com/pythonlibrary/bokeh-bottlepy 这个仓库中找到。
3.1 文件夹结构
我们的bokeh-bottlepy项目目录结构如下,其中
dataset文件夹:包含了数据集csv文件
static文件夹:包含了bootstrap前端框架代码,包括css,JavaScript,以及fonts等,用于以bootstrap的主题来展现html页面
views文件夹中:包含我们要如何展示数据的模板,本项目作为入门项目,其中仅仅包含了一个index.tpl文件,作为我们仅有的一个单页面网页的模板,该模板会由bottle应用导入数据来渲染,最总形成用户看到的页面
app.py:为我们的入口文件,我们所有的python代码将在这个里边实现,最终运行也是通过:python app.py来启动服务
Procfile:涉及到Heroku部署,后边我们会提到

3.2 路由
用python web框架实现的是动态的网页,也就是说网页是在用户访问的时候生成的,路由这个概念对于第一次接触网页应用的人比较陌生,不过其实很简单,通俗的讲,用户在点击一个网页上的链接或按钮,或在浏览器地址栏中访问一个链接的时候,网页服务器端会根据链接的不同做不同的动作,并将结果组织成html并呈现给用户,这一个过程就是路由。
在bottle中实现路由其实就是给每一个url实现一个对应的处理方法。下边的代码就是本项目用到的所有相关的部分
dirname = '.'
app = Bottle()
debug(True)
@app.route('/static/<filename:re:.*\.css>')
def send_css(filename):
return static_file(filename, root=dirname+'/static/asset/css')
@app.route('/static/<filename:re:.*\.js>')
def send_js(filename):
return static_file(filename, root=dirname+'/static/asset/js')
@app.route('/')
def index():
data = {
"developer_organization":"pythonlibrary.net"}
return template('index', data = data)
所有bottle网页应用需要实例化一个Bottle对像,作为服务本身,这里我们起名叫app,同时打开了debug模式,即当访问url的时候,Bottle应用会打印一些调试信息辅助开发人员定位问题。
路由函数的指定是通过@app.route装饰器实现的,这个装饰器的参数就是相对url,例如index函数的路由地址为/,如果本地服务端口为8080,则绝对url为:http://localhost:8080/,用户在访问这个地址的时候index函数将会被调用,而它的返回值就是用户看到的页面,这里是使用了template方法来使用data数据渲染模板,模板的概念我们下一章节会进行介绍。
要做出一个漂亮的页面,需要使用到复杂的JavaScript和css,所幸的是我们选择的bootstrap框架为我们实现了这些复杂部分,我们只需要应用它提供的模组就可以搭建出一个漂亮的网站。
在html中,JavaScript和css也是通过url来访问到的,因此如果要使模板生效,需要告知bottle这些JavaScript和css需要从本地哪个路径中去找,代码中的send_css和send_js函数就是利用bottle 中的static_file函数来通知应用本地的资源在什么位置,而上边的路由地址则是用户访问网页的时候再html中的地址,因此这两个函数实现了,url和本地资源的连接。
3.3 模板实现
所有的Python网页框架,在不使用前后端分离的方式开发网页应用的时候,都会包含一个模板的概念,这些框架大部分都继承了自己的模板引擎,bottle中也集成了一个他们称为SimpleTemplate的简单模板引擎,当然你可以选择使用其他第三方的模板引擎,如nijia2,mako等。
所谓模板引擎其实即使基于模板关键字的替换,引擎提供了一系列的语法,引擎可以解析这些语法,做出相应的动作,例如根据不同的情况填入不同的数据,做循环,判断等等,然后其余的内容将保持不变的放到输出中,可以通过python的stringtemplate来类比。
我们这个项目中,index.tpl就是模板,里边包含了SimpleTemplate可以识别的语法以及其他内容,当SimpleTemplate解析index.tpl总的语法,并填入合适的数据,则最终会得到完整的html内容,因此模板是 html + 引擎语法的集合,至于文件后缀tpl则无关紧要,可以使任何你定义的后缀,只是一般tpl代表template。
我们对原始代码的该文件进行一些修改:将head标签中的信息,按照我们的项目进行修改
<meta name="description" content="Deploy Bokeh Data Visualization with Bottlepy"> <title>China AQI</title>
然后将导航条 navbar div按照我们的要求修改成我们自己的链接,将网页主体container中最上边的文字框改成我们的项目描述。
<div id="navbar" class="navbar-collapse collapse"> <ul class="nav navbar-nav navbar-right"> <li><a href="../" rel="external nofollow" >Home</a></li> <li><a href="https://github.com/pythonlibrary/bokeh-bottlepy" rel="external nofollow" rel="external nofollow" rel="external nofollow" >On Github</a></li> </ul> </div><!--/.nav-collapse -->
<div class="row"> <div class="jumbotron"> <h2>中国AQI数据可视化</h2> <p>这是一个基于bottlepy, bokeh和Bootstrap的一个数据可视化部署的示例项目,采用了中国从2017年到2019年的AQI信息数据作为项目的演示数据。</p> </div> </div>
回到app.py中,在这个文件中下边这段代码,通过template方法实现了对index模板的渲染,这个方法的参数data,将作为数据动态的传入到模板中,相对应的模板中有一个 {{data[“developer_organization”]}} 的语句,这就是模板语法,跟python语法类似,通过dict的方式访问了data变量中的developer_organization键对应的值。
@app.route('/')
def index():
data = {
"developer_organization":"pythonlibrary.net"}
return template('index', data = data)
3.4 启动网页服务
我们在app.py实现了类似下边这样的入口,如果在终端中运行python app.py,这段代码将被执行,也就可以启动网页服务,服务的端口为8080,同时将host设置为0.0.0.0意思是其他电脑可以访问这台电脑上的服务,如果仅想本机本地访问可以设置为localhost
if __name__ == "__main__":
port = 8080
app.run(host="0.0.0.0", port=port, debug=True)
4. 将Bokeh和Bottle集成在一起
4.1 模板修改
首先我们想要在html中显示bokeh生成的图表,需要加载bokeh的JavaScript,通过在index.tpl中添加下边几个CDN的方式来导入。
<script src="https://cdn.bokeh.org/bokeh/release/bokeh-1.4.0.min.js"></script> <script src="https://cdn.bokeh.org/bokeh/release/bokeh-widgets-1.4.0.min.js"></script> <script src="https://cdn.bokeh.org/bokeh/release/bokeh-tables-1.4.0.min.js"></script>
然后我们要添加数据图表的占位符(相关的引擎语法代码),当进行模板渲染的时候,会被动态的替换为python代码中提供的内容。
在页面主体container中添加三个图表的占位符
注意:有别于其他数据传入语法,这里在data[“lot1_div”]前边有一个感叹号(!),这个非常重要,如果没有感叹号意味着,传入的数据将被认为是字符串,在渲染的时候会被引号括起来,而我们实际想要填充在这里的是html代码,而不是被双引号括起来的html代码,感叹号就是告知引擎,我们传入是的浏览器可以处理的html或者JavaScript或者css代码。
<div class="row">
{{!data["plot1_div"]}}
</div>
</br></br></br></br>
<div class="row">
{{!data["plot2_div"]}}
</div>
</br></br></br></br>
<div class="row">
{{!data["plot3_div"]}}
</div>
在body标签后边添加绘制图表使用的JavaScript脚本占位符
{{!data["plot_script"]}}
这里模板中未来用到的图表div和JavaScript脚本将会由bokeh生成,并有bottle渲染,我们会在加下来这一章节说明。
4.2 Python代码集成
将 2.2 章节中在notebook中调试成功的代码转换为函数,并实现到app.py中,注意原本在notebook中显示图表我们使用了show(p)的方法,在网页应用中我们仅仅是通过return p将图表对象返回,返回值将通过bottle提供的方法进行处理。
def get_df_from_source():
''' get dataframes from the source dataset, only take the data of some big cities
'''
cities = ['上海', '北京', '杭州', '宁波', '保定', '南京', '苏州', '深圳', '厦门', '广州']
df = pd.read_csv(dirname+'/dataset/AQI_merged.csv')
df['date'] = pd.to_datetime(df['date'])
df = df.sort_values(by='date').reset_index(drop=True)
df = df[df['type']=='AQI']
return df
def draw_daily_AQI(mini_date, df):
year = mini_date.split('-')[0]
df_day = df[df['date']>=mini_date]
source = ColumnDataSource(df_day)
p = figure(x_axis_type="datetime", title="{}年AQI日均平均变化曲线".format(year), plot_width=1150, plot_height=400)
p.line('date', '上海', line_color='blue', legend_label='上海', source=source)
p.line('date', '北京', line_color='green', legend_label='北京', source=source)
p.line('date', '深圳', line_color='orange', legend_label='深圳', source=source)
p.legend.location = "top_right"
p.add_tools(HoverTool(tooltips=[("AQI", "$y")]))
return p
def draw_month_AQI(mini_date, df):
year = mini_date.split('-')[0]
df_day = df[df['date']>=mini_date]
df_day['month'] = df_day['date'].apply(lambda x: x.strftime('%Y-%m'))
df_month = df_day.groupby(by='month').mean().reset_index()
source = ColumnDataSource(df_month)
p = figure(x_range=list(df_month['month']), title="2019年AQI", plot_width=1150, plot_height=400)
p.vbar(x=dodge('month', -0.25, range=p.x_range), top='上海', width=0.2, color="#c9d9d3", legend_label="上海", source=source)
p.vbar(x=dodge('month', 0, range=p.x_range), top='北京', width=0.2, color="#718dbf", legend_label="北京", source=source)
p.vbar(x=dodge('month', 0.25, range=p.x_range), top='深圳', width=0.2, color="#e84d60", legend_label="深圳", source=source)
p.xgrid.grid_line_color = None
p.y_range.start = 0
p.add_tools(HoverTool(tooltips=[("时间", "@month"), ("上海平均AQI", "@{上海}"), ("北京平均AQI", "@{北京}"), ("深圳平均AQI", "@{深圳}")]))
return p
def draw_year_AQI(df):
df['date_ym'] = df['date'].apply(lambda x: x.strftime('%Y-%m'))
df_month = df.groupby(by='date_ym').mean().reset_index()
df_month['month'] = df_month['date_ym'].apply(lambda x: x.split('-')[-1])
df_month['year'] = df_month['date_ym'].apply(lambda x: x.split('-')[0])
df_2017 = df_month[df_month['year']=='2017'][['month', '北京']]
df_2018 = df_month[df_month['year']=='2018'][['month', '北京']]
df_2019 = df_month[df_month['year']=='2019'][['month', '北京']]
source_2017 = ColumnDataSource(df_2017)
source_2018 = ColumnDataSource(df_2018)
source_2019 = ColumnDataSource(df_2019)
p = figure(x_range=list(df_2017['month']), title="2017-2019年北京AQI对比", plot_width=1150, plot_height=400)
p.vbar(x=dodge('month', -0.25, range=p.x_range), top='北京', width=0.2, color="#c9d9d3", legend_label="2017", source=source_2017)
p.vbar(x=dodge('month', 0, range=p.x_range), top='北京', width=0.2, color="#718dbf", legend_label="2018", source=source_2018)
p.vbar(x=dodge('month', 0.25, range=p.x_range), top='北京', width=0.2, color="#e84d60", legend_label="2019", source=source_2019)
p.xgrid.grid_line_color = None
p.y_range.start = 0
p.add_tools(HoverTool(tooltips=[("时间", "@month"), ("AQI", "@{北京}")]))
return p
三个绘图函数返回了图表对象p,我们如果能够让bottle来渲染图表对象,从而实现在网页中的图表展示呢?bokeh提供了一个components方法,可以接收图表对象作为参数,而返回绘图使用的JavaScript脚本和图表div,因此修改我们的index路由函数为:
@app.route('/')
def index():
df = get_df_from_source()
plot1 = draw_daily_AQI('2019-01-01', df=df)
plot2 = draw_month_AQI('2019-01-01', df=df)
plot3 = draw_year_AQI(df=df)
plots_data = components((plot1, plot2, plot3))
data = {
"plot_script":plots_data[0],
"plot1_div":plots_data[1][0],
"plot2_div":plots_data[1][1],
"plot3_div":plots_data[1][2],
"developer_organization":"pythonlibrary.net"}
return template('index', data = data)
在这里,index.tpl模板中的data字典中的plot1_div,plot2_div,plot3_div以及plot_script将被动态的渲染替换。最终实现了将图表展示在网页上的目的。
你可以clone本项目的仓库来尝试运行,或者直接访问http://china-aqi-data-visulazition.herokuapp.com/来查看效果

5. 部署应用到Heroku
这部分内容跟怎么将数据图表展示在网页上没有直接的关系,仅仅是一种可选的免费云服务,可以供你来共享你的页面,或者了解网页部署。但其实不同的服务可能部署的方式并不相同,因此如果你要部署你的网页到其他服务提供商,可能这里的知识完全不适用。
在Heroku上用户可以免费部署有限的网络应用,同时过程也非常的简单,只需要实现一个Procfile文件,Heroku系统就知道怎么运行你的服务了。我们的项目中Procfile使用如下代码,跟我们本地运行服务类似。
web: python app.py
而针对app.py的入口代码,需要将port改为从环境变量读取,因为Heroku会动态的为应用分配端口,如果指定一个固定值,则会因为Heroku没有打开其的对外访问,而导致用户无法访问该服务。
if __name__ == "__main__":
port=int(os.environ.get("PORT", 8080))
app.run(host="0.0.0.0", port=port, debug=True
最后用户可以在Heroku页面上选择将github仓库和应用连接在一起,那么系统会自动的从github拉取最新代码然后启动服务。
6. 参考文档
https://docs.bokeh.org/en/latest/docs/reference/models/plots.html
https://docs.bokeh.org/en/latest/docs/reference/embed.html
https://bottlepy.org/docs/dev/
更多关于python数据可视化的教程请查看下面的相关文章
相关推荐
-

学会Python数据可视化必须尝试这7个库
目录 一.Seaborn 二.Plotly 三.Geoplotlib 四.Gleam 五.ggplot 六.Bokeh 七.Missingo 一.Seaborn Seaborn 建于 matplotlib 库的之上.它有许多内置函数,使用这些函数,只需简单的代码行就可以创建漂亮的绘图.它提供了多种高级的可视化绘图和简单的语法,如方框图.小提琴图.距离图.关节图.成对图.热图等. 安装 ip install seaborn 主要特征: 可用于确定两个变量之间的关系. 在分析单变量或双变量分布时进行
-
Python数据可视化之用Matplotlib绘制常用图形
一.散点图 散点图用两组数据构成多个坐标点,考察坐标点的分布,判断两变量之间是否存在某种关联或总结坐标点的分布模式. 特点:判断变量之间是否存在数量关联趋势,表示离群点的分布规律. 散点图绘制: plt.scatter(x,y) # 以默认的形状颜色绘制散点图 实例: 假设我们获取到了上海2020年5,10月份每天白天的最高气温(分别位于列表a.b),那么此时如何观察气温和随时间变化的某种规律. # 绘制图形所需的数据 y_5 = [11,17,16,11,12,11,12,13,10,14,8
-
python数据可视化之matplotlib.pyplot基础以及折线图
不论是数据挖掘还是数据建模,都免不了数据可视化的问题.对于Python来说,Matplotlib是最著名的绘图库,它主要用于二维绘图,当然它也可以进行简单的三维绘图(基于spyder). - 模块引用 import matplotlib.pyplot as plt #引用画图库中的pyplot模块 -折线条图 语法 import matplotlib.pyplot as plt data=[1,2,3,4,5,4,2,4,6,7] #随便创建了一个数据 plt.plot(data) #引用画图库
-
利用Python进行数据可视化的实例代码
目录 前言 首先搭建环境 实例代码 例子1: 例子2: 例子3: 例子4: 例子5: 例子6: 总结 前言 前面写过一篇用Python制作PPT的博客,感兴趣的可以参考 用Python制作PPT 这篇是关于用Python进行数据可视化的,准备作为一个长贴,随时更新有价值的Python可视化用例,都是网上搜集来的,与君共享,本文所有测试均基于Python3. 首先搭建环境 $pip install pyecharts -U $pip install echarts-themes-pypkg $pi
-
python实现股票历史数据可视化分析案例
投资有风险,选择需谨慎. 股票交易数据分析可直观股市走向,对于如何把握股票行情,快速解读股票交易数据有不可替代的作用! 1 数据预处理 1.1 股票历史数据csv文件读取 import pandas as pd import csv df = pd.read_csv("/home/kesci/input/maotai4154/maotai.csv") 1.2 关键数据--在csv文件中选择性提取"列" df_high_low = df[['date','high',
-
Python爬虫实战之爬取京东商品数据并实实现数据可视化
一.开发工具 Python版本:3.6.4 相关模块: DecryptLogin模块: argparse模块: 以及一些python自带的模块. 二.环境搭建 安装Python并添加到环境变量,pip安装需要的相关模块即可. 三.原理简介 原理其实挺简单的,首先,我们利用之前开源的DecryptLogin库来实现一下微博的模拟登录操作: '''模拟登录京东''' @staticmethod def login(): lg = login.Login() infos_return, session
-
Python中seaborn库之countplot的数据可视化使用
在Python数据可视化中,seaborn较好的提供了图形的一些可视化功效. seaborn官方文档见链接:http://seaborn.pydata.org/api.html countplot是seaborn库中分类图的一种,作用是使用条形显示每个分箱器中的观察计数.接下来,对seaborn中的countplot方法进行详细的一个讲解,希望可以帮助到刚入门的同行. 导入seaborn库 import seaborn as sns 使用countplot sns.countplot() cou
-
Python数据可视化之绘制柱状图和条形图
一.实验目的: 1.掌握Python中柱状图.条形图绘图函数的使用 2.利用上述绘图函数实现数据可视化 二.实验内容: 1.练习python中柱状图.条形图绘图函数的用法,掌握相关参数的概念 2.根据步骤一绘图函数要求,处理实验数据 3.根据步骤二得到的实验数据,绘制柱状图.条形图 4.练习如何通过调整参数使图片呈现不同效果,例如颜色.图例位置.背景网格.坐标轴刻度和标记等 三.实验过程(附结果截图): 1. 练习python中柱状图.条形图绘图函数的用法,掌握相关参数的概念 (1)练习绘制条形
-
浅谈哪个Python库才最适合做数据可视化
数据可视化是任何探索性数据分析或报告的关键步骤,它可以让我们一眼就能洞察数据集.目前有许多非常好的商业智能工具,比如Tableau.googledatastudio和PowerBI,它们可以让我们轻松地创建图形. 然而,数据分析师或数据科学家还是习惯使用 Python 在 Jupyter notebook 上创建可视化效果.目前最流行的用于数据可视化的 Python 库:Matplotlib.Seaborn.plotlyexpress和Altair.每个可视化库都有自己的特点,没有完美的可视化库
-
python用pyecharts实现地图数据可视化
有的时候,我们需要对不同国家或地区的某项指标进行比较,可简单通过直方图加以比较.但直方图在视觉上并不能很好突出地区间的差异,因此考虑地理可视化,通过地图上位置(地理位置)和颜色(颜色深浅代表数值差异)两个元素加以体现.在本文案例中,基于第三方库pyecharts,对中国各省2010-2019年的GDP进行绘制. 我们先来看看最终效果: 关于绘图数据 基于时间和截面两个维度,可把数据分为截面数据.时间序列及面板数据.在本文案例中,某一年各省的GDP属于截面数据,多年各省的GDP属于面板数据.因此,
-
python数据可视化plt库实例详解
先看下jupyter和pycharm环境的差别 左边是jupyter----------------------------------------------------------右边是pycharm 以下都是使用pycharm环境 1.一个窗口画出一个线性方程 import numpy as np import matplotlib.pyplot as plt x = np.linspace(0,1,11)# 从0到1,个数为11的等差数列 print(x) y = 2*x plt.plo
-
Python数据可视化之基于pyecharts实现的地理图表的绘制
一.例子:百度迁徙 百度地图春节人口迁徙大数据(简称百度迁徙),是百度在2014年春运期间推出的一项技术项目.百度迁徙利用大数据,对其拥有的LBS(基于地理位置的服务)大数据进行计算分析,采用的可视化呈现方式,动态.即时.直观地展现中国春节前后人口大迁徙的轨迹与特征. 网址:https://qianxi.baidu.com/2021/ 二.基础语法介绍 语法 说明 from pyecharts.charts import Geo 导入地图库 Geo() Pyecharts地理图表绘制 .add_