pyTorch深入学习梯度和Linear Regression实现
目录
- 梯度
- 线性回归(linear regression)
- 模拟数据集
- 加载数据集
- 定义loss_function
梯度
PyTorch的数据结构是tensor,它有个属性叫做requires_grad,设置为True以后,就开始track在其上的所有操作,前向计算完成后,可以通过backward来进行梯度回传。
评估模型的时候我们并不需要梯度回传,使用with torch.no_grad() 将不需要梯度的代码段包裹起来。每个Tensor都有一个.grad_fn属性,该属性即创建该Tensor的Function,直接用构造的tensor返回None,否则是生成该tensor的操作。
tensor(data, *, dtype=None, device=None, requires_grad=False, pin_memory=False) -> Tensor #require_grad默认是false,下面我们将显式的开启 x = torch.tensor([1,2,3],requires_grad=True,dtype=torch.float)
注意只有数据类型是浮点型和complex类型才能require梯度,所以这里显示指定dtype为torch.float32
x = torch.tensor([1,2,3],requires_grad=True,dtype=torch.float32) > tensor([1.,2.,3.],grad_fn=None) y = x + 2 > tensor([3.,4.,5.],grad_fn=<AddBackward0>) z = y * y * 3 > tensor([3.,4.,5.],grad_fn=<MulBackward0>)
像x这种直接创建的,没有grad_fn,被称为叶子结点。grad_fn记录了一个个基本操作用来进行梯度计算的。
关于梯度回传计算看下面一个例子
x = torch.ones((2,2),requires_grad=True) > tensor([[1.,1.], > [1.,1.]],requires_grad=True) y = x + 2 z = y * y * 3 out = z.mean() #out是一个标量,无需指定求偏导的变量 out.backward() x.grad > tensor([[4.500,4.500], > [4.500,4.500]]) #每次计算梯度前,需要将梯度清零,否则会累加 x.grad.data.zero_()

值得注意的是只有叶子节点的梯度在回传时才会被计算,也就是说,上面的例子中拿不到y和z的grad。
来看一个中断求导的例子
x = torch.tensor(1.,requires_grad=True) y1 = x ** 2 with torch.no_grad() y2 = x ** 3 y3 = y1 + y2 y3.backward() print(x.grad) > 2
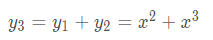
本来梯度应该为5的,但是由于y2被with torch.no_grad()包裹,在梯度计算的时候不会被追踪。
如果我们想要修改某个tensor的数值但是又不想被autograd记录,那么需要使用对x.data进行操作就行这也是一个张量。
线性回归(linear regression)
利用线性回归来预测一栋房屋的价格,价格取决于很多feature,这里简化问题,假设价格只取决于两个因素,面积(平方米)和房龄(年)
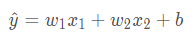
x1代表面积,x2代表房龄,售出价格为y
模拟数据集
假设我们的样本数量为1000个,每个数据包括两个features,则数据为1000 * 2的2-d张量,用正太分布来随机取值。
labels是房屋的价格,长度为1000的一维张量。
真实w和b提前把值定好,然后再取一个干扰量 δ \delta δ(也用高斯分布取值,用来模拟真实数据集中的偏差)
num_features = 2#两个特征 num_examples = 1000 #样本个数 w = torch.normal(0,1,(num_features,1)) b = torch.tensor(4.2) samples = torch.normal(0,1,(num_examples,num_features)) labels = samples.matmul(w) + b noise = torch.normal(0,.01,labels.shape) labels += noise
加载数据集
import random def data_iter(samples,labels,batch_size): num_samples = samples.shape[0] #获得batch轴的长度 indices = [i for i in range(num_samples)] random.shuffle(indices)#将索引数组原地打乱 for i in range(0,num_samples,batch_size): j = torch.LongTensor(indices[i:min(i+batch_size,num_samples)]) yield samples.index_select(0,j),labels(0,j)
torch.index_select(dim,index)
dim表示tensor的轴,index是一个tensor,里面包含的是索引。
定义loss_function
def loss_function(predict,labels): loss = (predict,labels)** 2 / 2 return loss.mean()
定义优化器
def loss_function(predict,labels): loss = (predict,labels)** 2 / 2 return loss.mean()
开始训练
w = torch.normal(0.,1.,(num_features,1),requires_grad=True) b = torch.zero(0.,dtype=torch.float32,requires_grad=True) batch_size = 100 for epoch in range(10): for data, label in data_iter(samples,labels,batch_size): predict = data.matmul(w) + b loss = loss_function(predict,label) loss.backward() optimizer([w,b],0.05) w.grad.data.zero_() b.grad.data.zero_()
以上就是pyTorch深入学习梯度和Linear Regression实现的详细内容,更多关于pyTorch实现梯度和Linear Regression的资料请关注我们其它相关文章!
相关推荐
-

pyTorch深入学习梯度和Linear Regression实现
目录 梯度 线性回归(linear regression) 模拟数据集 加载数据集 定义loss_function 梯度 PyTorch的数据结构是tensor,它有个属性叫做requires_grad,设置为True以后,就开始track在其上的所有操作,前向计算完成后,可以通过backward来进行梯度回传. 评估模型的时候我们并不需要梯度回传,使用with torch.no_grad() 将不需要梯度的代码段包裹起来.每个Tensor都有一个.grad_fn属性,该属性即创建该Tensor
-
pyTorch深度学习多层感知机的实现
目录 激活函数 多层感知机的PyTorch实现 激活函数 前两节实现的传送门 pyTorch深度学习softmax实现解析 pyTorch深入学习梯度和Linear Regression实现析 前两节实现的linear model 和 softmax model 是单层神经网络,只包含一个输入层和一个输出层,因为输入层不对数据进行transformation,所以只算一层输出层. 多层感知机(mutilayer preceptron)加入了隐藏层,将神经网络的层级加深,因为线性层的串联结果还是线
-
PyTorch深度学习LSTM从input输入到Linear输出
目录 LSTM介绍 LSTM参数 Inputs Outputs batch_first 案例 LSTM介绍 关于LSTM的具体原理,可以参考: https://www.jb51.net/article/178582.htm https://www.jb51.net/article/178423.htm 系列文章: PyTorch搭建双向LSTM实现时间序列负荷预测 PyTorch搭建LSTM实现多变量多步长时序负荷预测 PyTorch搭建LSTM实现多变量时序负荷预测 PyTorch搭建LSTM
-
pyTorch深度学习softmax实现解析
目录 用PyTorch实现linear模型 模拟数据集 定义模型 加载数据集 optimizer 模型训练 softmax回归模型 Fashion-MNIST cross_entropy 模型的实现 利用PyTorch简易实现softmax 用PyTorch实现linear模型 模拟数据集 num_inputs = 2 #feature number num_examples = 1000 #训练样本个数 true_w = torch.tensor([[2],[-3.4]]) #真实的权重值 t
-
PyTorch 迁移学习实践(几分钟即可训练好自己的模型)
前言 如果你认为深度学习非常的吃GPU,或者说非常的耗时间,训练一个模型要非常久,但是你如果了解了迁移学习那你的模型可能只需要几分钟,而且准确率不比你自己训练的模型准确率低,本节我们将会介绍两种方法来实现迁移学习 迁移学习方法介绍 微调网络的方法实现迁移学习,更改最后一层全连接,并且微调训练网络 将模型看成特征提取器,如果一个模型的预训练模型非常的好,那完全就把前面的层看成特征提取器,冻结所有层并且更改最后一层,只训练最后一层,这样我们只训练了最后一层,训练会非常的快速 迁移基本步骤 数据的准备
-
PyTorch 如何自动计算梯度
在PyTorch中,torch.Tensor类是存储和变换数据的重要工具,相比于Numpy,Tensor提供GPU计算和自动求梯度等更多功能,在深度学习中,我们经常需要对函数求梯度(gradient). PyTorch提供的autograd包能够根据输入和前向传播过程自动构建计算图,并执行反向传播. 本篇将介绍和总结如何使用autograd包来进行自动求梯度的有关操作. 1. 概念 Tensor是这个pytorch的自动求导部分的核心类,如果将其属性.requires_grad=True,它将开
-
Pytorch深度学习之实现病虫害图像分类
目录 一.pytorch框架 1.1.概念 1.2.机器学习与深度学习的区别 1.3.在python中导入pytorch成功截图 二.数据集 三.代码复现 3.1.导入第三方库 3.2.CNN代码 3.3.测试代码 四.训练结果 4.1.LOSS损失函数 4.2. ACC 4.3.单张图片识别准确率 四.小结 一.pytorch框架 1.1.概念 PyTorch是一个开源的Python机器学习库,基于Torch,用于自然语言处理等应用程序. 2017年1月,由Facebook人工智能研究院(FA
-
Pytorch深度学习经典卷积神经网络resnet模块训练
目录 前言 一.resnet 二.resnet网络结构 三.resnet18 1.导包 2.残差模块 2.通道数翻倍残差模块 3.rensnet18模块 4.数据测试 5.损失函数,优化器 6.加载数据集,数据增强 7.训练数据 8.保存模型 9.加载测试集数据,进行模型测试 四.resnet深层对比 前言 随着深度学习的不断发展,从开山之作Alexnet到VGG,网络结构不断优化,但是在VGG网络研究过程中,人们发现随着网络深度的不断提高,准确率却没有得到提高,如图所示: 人们觉得深度学习到此
-
对pytorch中的梯度更新方法详解
背景 使用pytorch时,有一个yolov3的bug,我认为涉及到学习率的调整.收集到tencent yolov3和mxnet开源的yolov3,两个优化器中的学习率设置不一样,而且使用GPU数目和batch的更新也不太一样.据此,我简单的了解了下pytorch的权重梯度的更新策略,看看能否一窥究竟. 对代码说明 共三个实验,分布写在代码中的(一)(二)(三)三个地方.运行实验时注释掉其他两个 实验及其结果 实验(三): 不使用zero_grad()时,grad累加在一起,官网是使用accum
-
Python 实现3种回归模型(Linear Regression,Lasso,Ridge)的示例
公共的抽象基类 import numpy as np from abc import ABCMeta, abstractmethod class LinearModel(metaclass=ABCMeta): """ Abstract base class of Linear Model. """ def __init__(self): # Before fit or predict, please transform samples' mean