详解RIFF和WAVE音频文件格式
RIFF file format
RIFF全称为资源互换文件格式(Resources Interchange File Format),是Windows下大部分多媒体文件遵循的一种文件结构。RIFF文件所包含的数据类型由该文件的扩展名来标识,能以RIFF格式存储的数据有:
- 音频视频交错格式数据 .AVI
- 波形格式数据 .WAV
- 位图数据格式 .RDI
- MIDI格式数据 .RMI
- 调色板格式 .PAL
- 多媒体电影 .RMN
- 动画光标 .ANI
- 其他的RIFF文件 .BND
CHUNK
chunk是RIFF文件的基本单元,其基本结构如下:
struct chunk
{
uint32_t id; // 块标志
uint32_t size; // 块大小
uint8_t data[size]; // 块数据
};
- id 4字节,用以标识块中所包含的数据。如:RIFF,LIST,fmt,data,WAV,AVI等,由于这种文件结构 最初是由Microsoft和IBM为PC机所定义,RIFF文件是按照小端 little-endian字节顺序写入的。
- size 块大小 存储在data域中的数据长度,不包含id和size的大小
- data 包含数据,数据以字为单位存放,如果数据长度为奇数(字节为单位),则最后添加一个空字节。
chunk是可以嵌套的,但是只有块标志为RIFF或者LIST的chunk才能包含其他的chunk。
RIFF chunk
标志为RIFF的chunk是比较特殊的,每一个RIFF文件首先存放的必须是一个RIFF chunk,并且只能有这一个标志为RIFF的chunk。RIFF的数据域的起始位置是一个4字节码(FOURCC),用于标识其数据域中chunk的数据类型;紧接着数据域的内容则是包含的subchunk,如下图
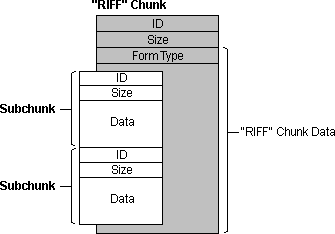
这是一个RIFF chunk中包含有两个subchunk,可以看出RIFF chunk的数据域首先是是4字节的 Form Type,接着是两个subchunk,每一个subchun有包含有自己的标识、数据域的大小以及数据域。
除了RIFF cunk可以嵌套其他的chunk外,另一个可以有subchunk的就是LIST chunk。

上图中,首先是RIFF文件必须的RIFF chunk,其数据域又包含有两个subchunk,其中一个subchunk的类型为LIST,该LIST chunk又包含了两个subchunk。
FourCC
FourCC 全称为Four-Character Codes,是一个4字节32位的标识符,通常用来标识文件的数据格式。例如,在音视频播放器中,可以通过 文件的FourCC来决定调用那种CODEC进行视音频的解码。例如:DIV3,DIV4,DIVX,H264等,对于音频则有:WAV,MP3等。对于上面的RIFF文件,则有:RIFF,WAVE,fmt,data等。FourCC是4个ASCII字符,不足四个字符的则在最后补充空格(不是空字符)。比如,FourCC fmt,实际上是'f' 'm' 't' ' '。
FourCC的生成通常可以使用如下宏:
#define MAKE_FOURCC(a,b,c,d) \ ( ((uint32_t)d) | ( ((uint32_t)c) << 8 ) | ( ((uint32_t)b) << 16 ) | ( ((uint32_t)a) << 24 ) )
在程序 中还是不要使用太长的宏为好,在C++中可以使用模板和enum结合的方式。来保证在编译时期就能够将FourCC生成出来。
#define FOURCC uint32_t
template <char ch0, char ch1, char ch2, char ch3> struct MakeFOURCC{ enum { value = (ch0 << 0) + (ch1 << 8) + (ch2 << 16) + (ch3 << 24) }; };
FOURCC fourcc_fmt = MakeFOURCC<'f', 'm', 't', ' '>::value;
将字符常量传入模板,在结构体中声明一个enum,编译器会在编译时期确定枚举值,这样就能给保证FOURCC在编译就能生成出来。
WAV file
WAV 是Microsoft开发的一种音频文件格式,它符合上面提到的RIFF文件格式标准,可以看作是RIFF文件的一个具体实例。既然WAV符合RIFF规范,其基本的组成单元也是chunk。一个WAV文件通常有三个chunk以及一个可选chunk,其在文件中的排列方式依次是:RIFF chunk,Format chunk,Fact chunk(附加块,可选),Data chunk。
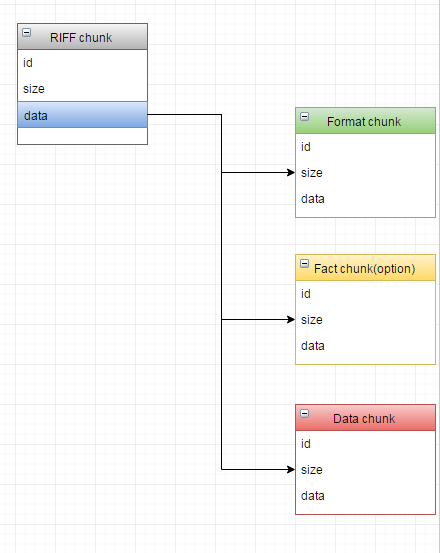
一个WAV文件,首先是一个RIFF chunk;RIFF chunk又包含有Format chunk,Data chunk以及可选的Fact chunk。各个chunk中字段的意义如下:
- RIFF chunk
- id
- FOURCC 值为'R' 'I' 'F' 'F'
- size
- 其data字段中数据的大小 字节数
- data
- 包含其他的chunk
- Format chunk
- id
- FOURCC 值为 'f' 'm' 't' ' '
- size
- 数据字段包含数据的大小。如无扩展块,则值为16;有扩展块,则值为= 16 + 2字节扩展块长度 + 扩展块长度或者值为18(只有扩展块的长度为2字节,值为0)
- data
存放音频格式、声道数、采样率等信息
format_tag
2字节,表示音频数据的格式。如值为1,表示使用PCM格式。
channels
2字节,声道数。值为1则为单声道,为2则是双声道。
samples_per_sec
采样率,主要有22.05KHz,44.1kHz和48KHz。
bytes_per sec
音频的码率,每秒播放的字节数。samples_per_sec * channels * bits_per_sample / 8,可以估算出使用缓冲区的大小
block_align
数据块对齐单位,一次采样的大小,值为声道数 * 量化位数 / 8,在播放时需要一次处理多个该值大小的字节数据。
bits_per_sample
音频sample的量化位数,有16位,24位和32位等。
cbSize
扩展区的长度
扩展块内容
22字节,具体介绍,后面补充。
- Fact chunk(option)
- id
- FOURCC 值为 'f' 'a' 'c' 't'
- size
- 数据域的长度,4(最小值为4)
- 采样总数 4字节
- Data chunk
- id
FOURCC 值为'd' 'a' 't' 'a'
- size
数据域的长度
- data
具体的音频数据存放在这里
采用压缩编码的WAV文件,必须要有Fact chunk,该块中只有一个数据,为每个声道的采样总数。
Format chunk 中的编码方式
在Format chunk中,除了有音频的数据的采样率、声道等音频的属性外,另一个比较主要的字段就是format_tag,该字段表示音频数据是以何种方式编码存放的。其具体的取值可以为以下:
- 0x0001
WAVE_FORMAT_PCM,采用PCM格式
- 0x0003
WAVE_FORMAT_IEEE_FLOAT,存放的值为IEEE float,范围为[-1.0f,1.0f]
- 0x0006
WAVE_FORMAT_ALAW , 8bit ITU-T G.711 A-law
- 0x0007
WAVE_FORMAT_MULAW,8bit ITU-T G.711 μ-law
- 0XFFFE
WAVE_FORMAT_EXTENSIBLE,具体的编码方式有扩展区的 sub_format字段决定
关于扩展格式块
当WAV文件使用的不是PCM编码方式是,就需要扩展格式块,它是在基本的Format chunk又添加一段数据。该数据的前两个字节,表示的扩展块的长度。紧接其后的是扩展的数据区,含有扩展的格式信息,其具体的长度取决于压缩编码的类型。当某种编码方式(如 ITU G.711 a-law)使扩展区的长度为0,扩展区的长度字段还必须保留,只是其值设置为0。
扩展区的各个字节的含义如下:
size 2字节
扩展区的数据长度 ,可以为0或22
- valid_bits_per_sample 2字节
有效的采样位数,最大值为采样字节数 * 8。可以使用更灵活的量化位数,通常音频sample的量化位数为8的倍数,但是使用了WAVE_FORMAT_EXTENSIBLE时,量化的位数有扩展区中的valid bits per sample来描述,可以小于Format chunk中制定的bits per sample。
- channle mask 4字节
声道掩码
- sub format 16字节
GUID,include the data format code,数据格式码。
在Format chunk中的format_tag设置为0xFFFE时,表示使用扩展区中的sub_format来决定音频的数据的编码方式。在以下几种情况下必须要使用WAVE_FORMAT_EXTENSIBLE
- PCM数据的量化位数大于16
- 音频的采样声道大于2
- 实际的量化位数不是8的倍数
- 存储顺序和播放顺序不一致,需要指定从声道顺序到声卡播放顺序的映射情况。
Data chunk
Data块中存放的是音频的采样数据。每个sample按照采样的时间顺序写入,对于使用多个字节的sample,使用小端模式存放(低位字节存放在低地址,高位字节存放在高地址)。对于多声道的sample采用交叉存放的方式。例如:立体双声道的sample存储顺序为:声道1的第一个sample,声道2的第一个sample;声道1的第二个sample,声道2的第二个sample;依次类推....。对于PCM数据,有以下两种的存储方式:
- 单声道,量化位数为8,使用偏移二进制码
- 除上面之外的,使用补码方式存储。
总结
本文主要介绍了RIFF文件的格式和WAV音频文件格式,为后面实现对WAVE文件的读写打一个理论基础。后面打算使用C++标准库,实现对WAV文件的读写。
到此这篇关于RIFF和WAVE音频文件格式的文章就介绍到这了,更多相关RIFF和WAVE音频格式内容请搜索我们以前的文章或继续浏览下面的相关文章希望大家以后多多支持我们!
相关推荐
-

wavesurfer.js绘制音频波形图的实现
1.查看效果图 向前选中: 向后选中: 代码如下(示例): <template> <div class="waveSurfer"> <div class="top"> <span @click="leftSelect">向前选中</span> <span @click="rightSelect">向后选中</span> <span @cl
-
详解RIFF和WAVE音频文件格式
RIFF file format RIFF全称为资源互换文件格式(Resources Interchange File Format),是Windows下大部分多媒体文件遵循的一种文件结构.RIFF文件所包含的数据类型由该文件的扩展名来标识,能以RIFF格式存储的数据有: 音频视频交错格式数据 .AVI 波形格式数据 .WAV 位图数据格式 .RDI MIDI格式数据 .RMI 调色板格式 .PAL 多媒体电影 .RMN 动画光标 .ANI 其他的RIFF文件 .BND CHUNK chunk是
-
详解Howler.js Web音频播放终极解决方案
前言 相信有很多人在写移动端音频播放的时候都踩过不少坑,特别是复杂音频项目在兼容多种设备的时候更是让你抓狂,比如ios端不能一开始就播放音频,必须要用户进行了操作.... 偶然间了解到了一个兼容所有设备和浏览器的音频引擎Howler.js 使用了一下非常完美 Howler.js 是一个新的 JavaScript 库用于处理 Web 中的音频,该库最初是为一个 HTML5 游戏引擎所开发,但也可用于其他的 Web 项目,Howler.js 基于 Google 的 Web Audio API,能够帮
-
Python用sndhdr模块识别音频格式详解
本文主要介绍了Python编程中,用sndhdr模块识别音频格式的相关内容,具体如下. sndhdr模块 功能描述:sndhdr模块提供检测音频类型的接口. 唯一一个API sndhdr模块提供了sndhdr.what(filename)和sndhdr.whathdr(filename)两个函数.但实际上它们的功能是一样的.(不知道多写一个的意义何在,what函数在内部调用了whathdr函数并把数据完完整整地返回) 在之前的版本,whathdr函数返回元组类型的数据,在Python3.5版本之
-
Python音频操作工具PyAudio上手教程详解
0.引子 当需要使用Python处理音频数据时,使用python读取与播放声音必不可少,下面介绍一个好用的处理音频PyAudio工具包. PyAudio是Python开源工具包,由名思义,是提供对语音操作的工具包.提供录音播放处理等功能,可以视作语音领域的OpenCv. 1.简介 PyAudio为跨平台音频I / O库 PortAudio 提供 Python 绑定.使用PyAudio,您可以轻松地使用Python在各种平台上播放和录制音频,例如GNU / Linux,Microsoft Wi
-
python音频处理的示例详解
准备工作: 首先,我们需要 import 几个工具包,一个是 python 标准库中的 wave 模块,用于音频处理操作,另外两个是 numpy 和 matplot,提供数据处理函数. 一:读取本地音频数据 处理音频第一步是需要从让计算机"听到"声音,这里我们使用 python 标准库中自带的 wave模块进行音频参数的获取. (1) 导入 wave 模块 (2) 使用 wave 中的函数 open 打开音频文件,wave.open(file,mode)函数带有两个参数, 第一个 fi
-
Python+pyaudio实现音频控制示例详解
简介 PyAudio是一个跨平台的音频处理工具包,使用该工具包可以在Python程序中播放和录制音频,也可以产生wav文件等 安装 pip install PyAudio 注意:使用该命令安装时可能会报错,报错内容如下: 针对该问题,我们使用whl文件进行安装,首先在网址下面找到以下文件并下载,根据自己的python版本及计算机系统下载相应文件即可. 下载完成后,切换到文件所在目录,使用如下命令安装即可 pip3 install PyAudio-0.2.11-cp38-cp38-win_amd6
-
java使用FFmpeg合成视频和音频并获取视频中的音频等操作(实例代码详解)
FFmpeg是一套可以用来记录.转换数字音频.视频,并能将其转化为流的开源计算机程序. ffmpeg命令参数如下: 通用选项 -L license -h 帮助 -fromats 显示可用的格式,编解码的,协议的... -f fmt 强迫采用格式fmt -I filename 输入文件 -y 覆盖输出文件 -t duration 设置纪录时间 hh:mm:ss[.xxx]格式的记录时间也支持 -ss position 搜索到指定的时间 [-]hh:mm:ss[.xxx]的格式也支持 -title
-
Python中操作各种多媒体,视频、音频到图片的代码详解
我们经常会遇到一些对于多媒体文件修改的操作,像是对视频文件的操作:视频剪辑.字幕编辑.分离音频.视频音频混流等.又比如对音频文件的操作:音频剪辑,音频格式转换.再比如我们最常用的图片文件,格式转换.各个属性的编辑等.因为多媒体文件的操作众多,本文选取一些极具代表性的操作,以代码的形式实现各个操作. 一.图片操作 操作图片的模块有许多,其中比较常用的两个就是 Pillow 和 opencv ,两个模块各有优势.其中 opencv 是计算机视觉处理的开源模块,应用的范围更加广泛,从图像处理到视频处理
-
Python爬虫实战案例之爬取喜马拉雅音频数据详解
前言 喜马拉雅是专业的音频分享平台,汇集了有声小说,有声读物,有声书,FM电台,儿童睡前故事,相声小品,鬼故事等数亿条音频,我最喜欢听民间故事和德云社相声集,你呢? 今天带大家爬取喜马拉雅音频数据,一起期待吧!! 这个案例的视频地址在这里 https://v.douyu.com/show/a2JEMJj3e3mMNxml 项目目标 爬取喜马拉雅音频数据 受害者地址 https://www.ximalaya.com/ 本文知识点: 1.系统分析网页性质 2.多层数据解析 3.海量音频数据保存 环境
-
详解python日志输出使用配置文件格式
python脚本日志输出使用配置文件的形式,不需要在每个脚本里面配置日志. 需求简述: 如我要写2个脚本(a.py和b.py),a.py日志输出到/var/log/a.log,b.py日志输出到/var/log/b.log,并且日志按日期切割.如果每个脚本都去配置一遍日志的话,浪费时间也不利于后期维护. 现在我要使用配置文件的格式去统一管理python脚本的代码日志输出,后续所有python脚本日志都在这个配置文件里面配置,脚本读取.方便后续维护和增加脚本的可读性. 需求实现: 我配置文件路径及