SQL Server中聚合函数的用法
聚合函数对一组值执行计算,并返回单个值。
除了 COUNT 外,聚合函数都会忽略 Null 值。 聚合函数经常与 SELECT 语句的 GROUP BY 子句一起使用。
OVER 子句可以跟在除 STRING_AGG、GROUPING 或 GROUPING_ID 函数以外的所有聚合函数后面。
只能在以下位置将聚合函数作为表达式使用:
- SELECT 语句的选择列表(子查询或外部查询)。
- HAVING 子句。
T-SQL提供的聚合函数一共有13个之多。
1、avg:平均值
avg( [ all | distinct ] expression )
AVG函数用于计算精确型或近似型数据类型的平均值,bit类型除外,忽略null值。AVG函数计算时将计算一组数的总和,然后除以为null的个数,得到平均值
select avg(distinct age) from person -- 查询person表里的年龄的平均值,相同值只计算一次
2、min:最小值
MIN函数用于计算最小值,MIN函数可以适用于numeric、char、varchar或datetime、money或smallmoney列,但不能用于bit列。不允许使用聚合函数和子查询,忽略null值。
3、max:最大值
MAX函数用于计算最大值,忽略null值。max函数可以使用于numeric、char、varchar、money、smallmoney、或datetime列,但不能用于bit列。不允许使用聚合函数和子查询。
4、sum:求和值
SUM函数用于求和,只能用于精确或近似数字类型列(bit类型除外),忽略null值,不允许使用聚合函数和子查询。
5、count:统计项数值
count函数用于计算满足条件的数据项数,返回int数据类型的值。这里的表达式是除text、image或ntext以外任何数据类型的表达式。但不允许使用聚合函数和子查询。
- count(*) : 返回所有的项数,包括null值和重复项。而除了count(*)外,其他任何形式的count()函数都会忽略Null行。
- count(all 表达式):返回非空的项数。
- count(distinct 表达式):返回唯一非空的项数
注意:count(字段名),如果字段名为NULL,则count函数不会统计。例如count(name),如果name为空,则不会统计到结果
select count(distinct age) from person -- 查询person表里的年龄唯一且非空的项数
6、count_big:统计项数量
返回组中的项数。 COUNT_BIG 的用法与 COUNT 函数类似。 两个函数唯一的差别是它们的返回值。 COUNT_BIG 始终返回 bigint 数据类型值。 COUNT 始终返回 int 数据类型值。
7、差值函数
1、stdev:计算标准偏差值
这里的expression必须是一个数值表达式,不允许使用聚合函数和子查询。表达式的值是精确或近似数值类型,但不包括bit数据类型。将忽略null值。
2、stdevp:计算总体标准偏差
返回指定表达式中所有值的总体标准偏差。
3、var:计算方差
VAR函数用于计算指定表达式中所有值的方差。 这里的expression表达式必须是一个数值表达式,不允许使用聚合函数和子查询。表达式的值是精确或近似数值类型,但不包括bit数据类型,将忽略null值。
4、varp:计算总体统计方差
返回指定表达式中所有值的总体统计方差。
8、checksum_agg:计算组中各值的校验和
返回组中各值的校验和。 将忽略 Null 值。CHECKSUM_AGG 可用于检测表中的更改。表中行的顺序不影响 CHECKSUM_AGG 的结果。此外,CHECKSUM_AGG 函数还可与 DISTINCT 关键字和 GROUP BY 子句一起使用。如果表达式列表中的某个值发生更改,则列表的校验和通常也会更改。但只在极少数情况下,校验值会保持不变。
CHECKSUM_AGG ( [ ALL | DISTINCT ] expression )
参数说明:
- ALL:对所有的值进行聚合函数运算。 ALL 为默认值。
- DISTINCT :指定 CHECKSUM_AGG 返回唯一校验值。
- expression :一个整数表达式。 不允许使用聚合函数和子查询。
SELECT CHECKSUM_AGG(Account_Age) FROM Account GO UPDATE Account SET Account_Age = 30 WHERE Account_Id = 6 GO SELECT CHECKSUM_AGG(Account_Age) FROM Account
显示结果如下:

可见随着表的更改,该系统函数返回的值也变了。此函数的作用正在于此,检测表的更改。
9、string_agg:串联字符串
MS SQL Server的2017新增了STRING_AGG()是一个聚合函数,它将由指定的分隔符分隔将字符串行连接成一个字符串。 它不会在结果字符串的末尾添加分隔符。
以下是STRING_AGG()函数的语法:
STRING_AGG ( input_string, separator ) [ order_clause ]
在这个语法中:
input_string是串联时可以转换为VARCHAR和NVARCHAR的类型。separator是结果字符串的分隔符。它可以是文字或变量。order_clause使用WITHIN GROUP子句指定连接结果的排序顺序:
WITHIN GROUP ( ORDER BY expression [ ASC | DESC ] )
STRING_AGG()忽略NULL,并且在执行连接时不会为NULL添加分隔符。
下面将使用示例数据库中的sales.customers表进行演示:

此示例使用STRING_AGG()函数生成城市客户的电子邮件列表:
SELECT city, STRING_AGG(email,';') email_list FROM sales.customers GROUP BY city;
执行上面查询语句,得到以下结果:
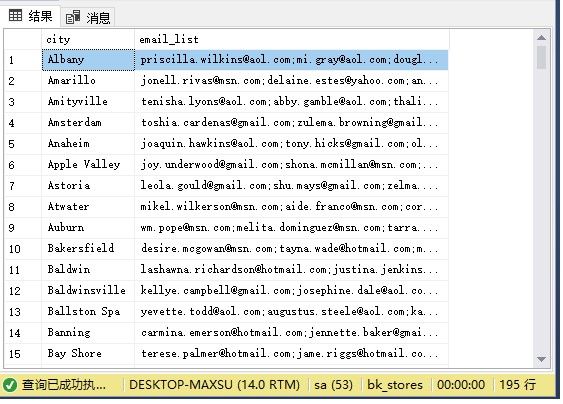
要对email列表进行排序,请使用WITHIN GROUP子句:
SELECT city, STRING_AGG(email,';') WITHIN GROUP (ORDER BY email) email_list FROM sales.customers GROUP BY city;
执行上面查询语句,得到以下结果:
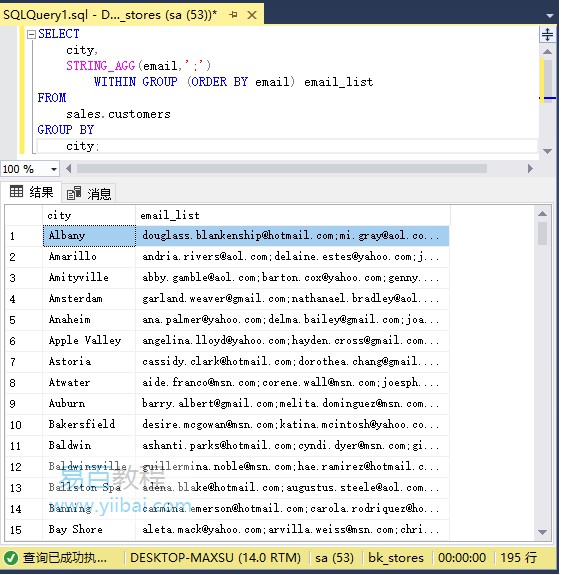
注意:STRING_SPLIT()函数:一个表值函数,它根据指定的分隔符将字符串拆分为子字符串行。
SELECT value FROM STRING_SPLIT('Lorem ipsum dolor sit amet.', ' ');
10、approx_count_distinct:唯一非空值的近似数
SQL Server 2019引入了新函数Approx_Count_distinct以提供行的近似计数。Count(distinct())函数提供实际的行数。
该函数APPROX_COUNT_DISTINCT应该使用较少的内存和CPU资源,以便可以获取数据结果而不会出现任何问题,例如溢出到磁盘或CPU峰值。这对于数十亿行的需求很有用。
11、cube或 rollup 汇总运算符
- CUBE 生成的结果集显示了所选列中值的所有组合的聚合。
- ROLLUP 生成的结果集显示了所选列中值的某一层次结构的聚合。
查询出插入的全部数据:
select * from dbo.PeopleInfo

select [name],numb,sum(fenshu) from dbo.PeopleInfo group by [name],numb //用group by select [name],numb,sum(fenshu) from dbo.PeopleInfo group by [name],numb with cube; //用with cube select [name],numb,sum(fenshu) from dbo.PeopleInfo group by [name],numb with rollup //用with rollup
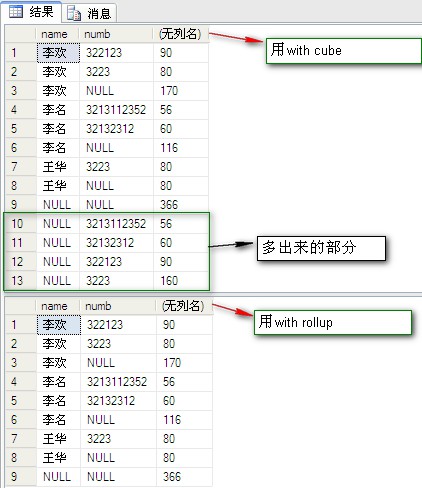
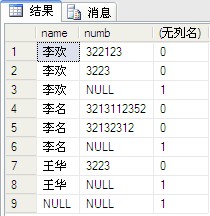
12、grouping:指示是否聚合GROUP BY 列:
当行由 CUBE 或 ROLLUP 运算符添加时,该函数将导致附加列的输出值为 1;当行不由 CUBE 或 ROLLUP 运算符添加时,该函数将导致附加列的输出值为 0。
仅在与包含 CUBE 或 ROLLUP 运算符的 GROUP BY 子句相关联的选择列表中才允许分组。
select [name],numb,grouping(numb) from dbo.PeopleInfo group by [name],numb with rollup
13、grouping_id:计算分组级别
仅当指定了 GROUP BY 时,GROUPING_ID 才能在 SELECT 列表、HAVING 或 ORDER BY 子句中使用。 使用 GROUPING_ID 标识分组级别下面的示例返回按 AdventureWorks2012 数据库的 Name 和 Title 汇总的雇员计数以及 Name, 和公司总计。 GROUPING_ID() 用于为 Title 列中的每行创建一个值以标识聚合级别。
SELECT D.Name
,CASE
WHEN GROUPING_ID(D.Name, E.JobTitle) = 0 THEN E.JobTitle
WHEN GROUPING_ID(D.Name, E.JobTitle) = 1 THEN N'Total: ' + D.Name
WHEN GROUPING_ID(D.Name, E.JobTitle) = 3 THEN N'Company Total:'
ELSE N'Unknown'
END AS N'Job Title'
,COUNT(E.BusinessEntityID) AS N'Employee Count'
FROM HumanResources.Employee E
INNER JOIN HumanResources.EmployeeDepartmentHistory DH
ON E.BusinessEntityID = DH.BusinessEntityID
INNER JOIN HumanResources.Department D
ON D.DepartmentID = DH.DepartmentID
WHERE DH.EndDate IS NULL
AND D.DepartmentID IN (12,14)
GROUP BY ROLLUP(D.Name, E.JobTitle);
14、partition by :聚合开窗函数
很多聚合函数都可以用作窗口函数的运算,如SUM,AVG,MAX,MIN。聚合开窗函数只能使用PARTITION BY子句或都不带任何语句,ORDER BY不能与聚合开窗函数一同使用。例如,查询雇员的定单总数及定单信息。
WITH OrderInfo AS
(
SELECT COUNT(OrderID) OVER(PARTITION BY EmployeeID) AS TotalCount,OrderID,CustomerID, EmployeeID,OrderDate FROM Orders (NOLOCK)
)
SELECT OrderID,CustomerID, EmployeeID ,OrderDate,TotalCount From OrderInfo ORDER BY EmployeeID
如果窗口函数不使用PARTITION BY 语句的话,那么就是不对数据进行分组,聚合函数计算所有的行的值。
WITH OrderInfo AS ( SELECT COUNT(OrderID) OVER() AS Count,OrderID,CustomerID, EmployeeID,OrderDate FROM Orders (NOLOCK) )
到此这篇关于SQL Server聚合函数的文章就介绍到这了。希望对大家的学习有所帮助,也希望大家多多支持我们。
相关推荐
-

深入学习SQL Server聚合函数算法优化技巧
Sql server聚合函数在实际工作中应对各种需求使用的还是很广泛的,对于聚合函数的优化自然也就成为了一个重点,一个程序优化的好不好直接决定了这个程序的声明周期.Sql server聚合函数对一组值执行计算并返回单一的值.聚合函数对一组值执行计算,并返回单个值.除了 COUNT 以外,聚合函数都会忽略空值. 聚合函数经常与 SELECT 语句的 GROUP BY 子句一起使用. 一.写在前面 如果有对Sql server聚合函数不熟或者忘记了的可以看我之前的一片博客. 本文中所有数据演示都是用
-
SQLServer行列互转实现思路(聚合函数)
有时候会碰到行转列的需求(也就是将列的值作为列名称),通常我都是用 CASE END + 聚合函数来实现的. 如下: declare @t table (StudentName nvarchar(20), Subject nvarchar(20), Score int) Insert into @t (StudentName,Subject,Score) values ( '学生A', '中文', 80 ); Insert into @t (StudentName,Subject,Score)
-
Sql Server 字符串聚合函数
如下表:AggregationTable Id Name 1 赵 2 钱 1 孙 1 李 2 周 如果想得到下图的聚合结果 Id Name 1 赵孙李 2 钱周 利用SUM.AVG.COUNT.COUNT(*).MAX 和 MIN是无法做到的.因为这些都是对数值的聚合.不过我们可以通过自定义函数的方式来解决这个问题.1.首先建立测试表,并插入测试数据: 复制代码 代码如下: create table AggregationTable(Id int, [Name] varchar(10)) go
-
SQL Server中聚合函数的用法
聚合函数对一组值执行计算,并返回单个值. 除了 COUNT 外,聚合函数都会忽略 Null 值. 聚合函数经常与 SELECT 语句的 GROUP BY 子句一起使用. OVER 子句可以跟在除 STRING_AGG.GROUPING 或 GROUPING_ID 函数以外的所有聚合函数后面. 只能在以下位置将聚合函数作为表达式使用: SELECT 语句的选择列表(子查询或外部查询). HAVING 子句. T-SQL提供的聚合函数一共有13个之多. 1.avg:平均值 avg( [ all |
-
Sql Server中Substring函数的用法实例解析
SQL 中的 substring 函数是用来抓出一个栏位资料中的其中一部分.这个函数的名称在不同的资料库中不完全一样: MySQL: SUBSTR( ), SUBSTRING( ) Oracle: SUBSTR( ) SQL Server: SUBSTRING( ) SQL 中的 substring 函数是用来截取一个栏位资料中的其中一部分. 例如,我们需要将字符串'abdcsef'中的'abd'给提取出来,则可用substring 来实现: select substring('abdcsef'
-
SQL Server中JSON函数的用法详解
目录 一. 将查询结果输出JSON格式 1.FOR JSON AUTO:SELECT语句的结果以JSON输出. 2.FOR JSON AUTO,Root(’’) :为JOSN加上根节点 3.FOR JSON PATH输出:可通过列别名来定义JSON对象的层次结构 4.FOR JSON PATH+ROOT输出:为JOSN加上根节点 5.INCLUDE_NULL_VALUES:值null的字段需要显示出现. 6.列的别名,可以增加带有层级关系的节点. 二. 解析JSON格式的数据 1.使用OPENJ
-
SQL Server中字符串函数的用法详解
在开发T-SQL时,经常会需要对字符串进行各种各样的操作,下面介绍常用的字符串函数. 一.编码转换 1.获取字符的ASCII码:ascii ASCII(espression) 这里的expression是一个返回char或varchar数据类型的表达式,ASCII函数仅对表达式最左侧的字符返回ASCII码值. 返回值:int数据类型. 注意:如果是多个字符的字符串,也只是返回第一个字符的ASCII码值. select ASCII('f') --输出 102 2.获取ASCII码对应的字符:cha
-
SQL Server中数学函数的用法
1.计算绝对值ABS ABS函数对一个数值表达式结果计算绝对值(bit数据类型除外),返回整数. 语法格式: ABS(数值表达式) 返回值:与数值表达式类型一致的数据 示例: SELECT ABS(-1) --输出 1 2.获取大于等于最小整数值Celling CEILING函数返回大于等于数值表达式(bit数据类型除外)的最小整数值.俗称天花板函数,尽量往大的取整. 语法格式: CEILING(数值表达式) 返回值:与数值表达式类型一致的数据. 示例: SELECT Celling(123.1
-
SQL Server中元数据函数的用法
1.获取数据库标识符:DB_ID DB_ID函数用于获取当前数据库的唯一ID(int数据类型),数据库ID用于服务器上唯一区分书库. 语法格式: DB_ID (['database_name']) 参数中的database_name是sysname类型的数据库名称,为可选参数.如果没有指定则返回当前工作数据库的ID. 返回值: int数据类型的数据库标识符. 示例: select DB_ID() --输出 8 2.获取数据库名称:DB_NAME DB_NAME函数用于红区当前数据库的名称(nva
-
SQL Server中row_number函数的常见用法示例详解
一.SQL Server Row_number函数简介 ROW_NUMBER()是一个Window函数,它为结果集的分区中的每一行分配一个连续的整数. 行号以每个分区中第一行的行号开头. 以下是ROW_NUMBER()函数的语法实例: select *,row_number() over(partition by column1 order by column2) as n from tablename 在上面语法中: PARTITION BY子句将结果集划分为分区. ROW_NUMBER()函
-
SQL Server中row_number函数用法入门介绍
目录 一.SQL Server Row_number函数简介 二.Row_number函数的具体用法 1.使用row_number()函数对结果集进行编号 2.对结果集按照指定列进行分组,并在组内按照指定列排序 3.对结果集按照指定列去重 总结 一.SQL Server Row_number函数简介 ROW_NUMBER()是一个Window函数,它为结果集的分区中的每一行分配一个连续的整数. 行号以每个分区中第一行的行号开头. 语法实例: select *,row_number() over(
-
SQL Server中交叉联接的用法详解
目录 1.交叉联接(cross join)的概念 2.交叉联接的语法格式 3.交叉查询的使用场景 3.1 交叉联接可以查询全部数据 3.2 交叉联接优化查询性能 4.总结 今天给大家介绍SQLServer中交叉联接的用法,希望对大家能有所帮助! 1.交叉联接(cross join)的概念 交叉联接是联接查询的第一个阶段,它对两个数据表进行笛卡尔积.即第一张数据表每一行与第二张表的所有行进行联接,生成结果集的大小等于T1*T2. select * from t1 cross join t2 2.交
-
SQL Server中聚合历史备份信息对比数据库增长的方法
很多时候,在我们规划SQL Server数据库的空间,或向存储方面要空间时,都需要估算所需申请数据库空间的大小,估计未来最简单的办法就是看过去的趋势,这通常也是最合理的方式. 通常来讲,一个运维良好的数据库都需要做定期基线(baseline),有了基线才会知道什么是正常.一个简单的例子例如,一些人的血压平常偏低,那么80的低压对他来说就是不正常了.但现实情况是大多数系统并没有采集基线的习惯,因此在需要规划空间想要看历史增长时,就没有过去精确的数据了. 一个解决办法就是通过查看历史备份的大小来看过