pandas的排序、分组groupby及cumsum累计求和方式
目录
- 生成一列sum_age 对age 进行累加
- 生成一列sum_age_new 按照 gender和is_good 对age进行累加
- 根据不同的性别对年龄进行 等级 排序
- 对数据排序之后,分组,并累计求和
- pandas分组排序功能
生成一列sum_age 对age 进行累加
df['sum_age'] = df['age'].cumsum() print(df)

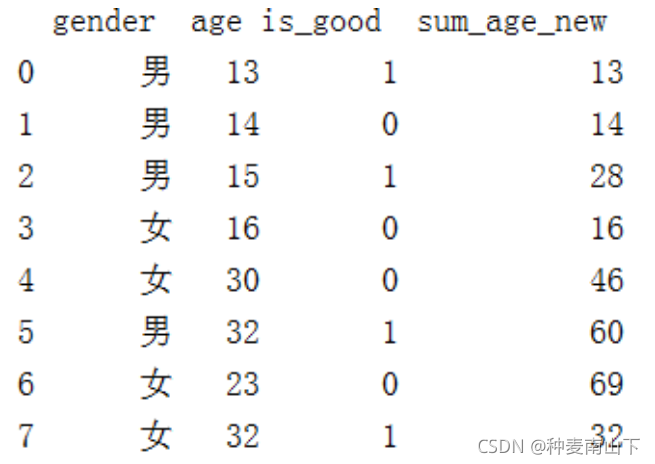
生成一列sum_age_new 按照 gender和is_good 对age进行累加
df['sum_age_new'] = df.groupby(['gender','is_good'])['age'].cumsum() print(df)
根据不同的性别对年龄进行 等级 排序
df['rank_g'] = df.groupby(['gender'])['age'].rank() print(df)
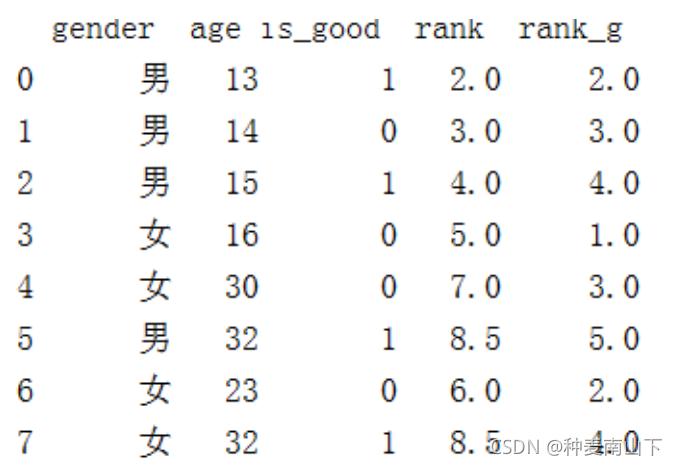
这里的 rank( ) 即 'rank_g' ,并不是按照1、2、3、4、、依次排
按照官方文档的意思,该函数是沿着某个轴来计算数值数据等级(1到n)。默认情况下,为相等的值分配同一个等级,该等级是这些值的等级的平均值。
例子:
import pandas as pd obj = pd.Series([7,-5,7,4,2,0,4]) print(obj.rank())
代码对 [7, -5, 7, 4, 2, 0, 4] 进行从小到大地排序,很明显地,可以排成 [-5, 0, 2 ,4, 4, 7, 7],数值7有第6和第7两个位置,那应该排序应该排到第几级?根据官方文档,取平均值,(6+7)/2=6.5,所以两个7的等级都为6.5,同理可得两个4的等级都为(4+5)/2=4.5。
输出:
0 6.5
1 1.0
2 6.5
3 4.5
4 3.0
5 2.0
6 4.5
dtype: float64
对数据排序之后,分组,并累计求和
# 对Start Time进行排序,Connection Type分组,temp进行累计求和cumsum wsw_1 = wsw.sort_values(['Start Time']) wsw_1.loc[:, 'Connection Number'] = wsw_1.groupby(['Connection Type'])['temp'].cumsum()
这里如果不对start time排序,Connection Number不会按时间顺序,统计drilling、tripping 的number数

pandas分组排序功能
在一个班级里,学生考试科目有语文、数学、英语,分别有对应的成绩。
现在,想要列出每个科目班级的前五名的情况,要求包含科目、姓名、成绩、名次。
通过以下代码实现:
import pandas as pd
a=['小红','小绿','小蓝','小白','小青','小紫','小粉','小傻','小红','小绿','小蓝','小白','小青','小紫','小粉','小傻','小红','小绿','小蓝','小白','小青','小紫','小粉','小傻']
b=['语文','语文','语文','语文','语文','语文','语文','语文','数学','数学','数学','数学','数学','数学','数学','数学','英语','英语','英语','英语','英语','英语','英语','英语']
c=[97,65,23,43,67,23,55,98,56,45,67,78,98,45,87,65,67,23,55,98,56,45,67,78]
len(a),len(b),len(c)
df=pd.DataFrame({'name':a,'kemu':b,'score':c})
df2=df.sort_values(['kemu','score','name'], ascending=[1, 0,1])
df2['rn']=df2.groupby(['kemu']).rank(method='first',ascending =0)['score']
df2[df2['rn']<=5]
''''
以上为个人经验,希望能给大家一个参考,也希望大家多多支持我们。
相关推荐
-
pandas分组排序 如何获取第二大的数据
Python用来做数据分析很方便,网上很多关于找数据中第二大的方法,但是大多数都是关于SQL的,于是我挑战一下用Python来做这件事(主要是SQL写的不好>_<),上代码. 1.数据我是自己编的 在实际工作中应该从数据库中导入数据,如何从数据库导出数据,我之后会补充. import pandas as pd df = pd.DataFrame([ {"class": 1, "name": "aa", "english&qu
-

pandas数值排序的实现实例
目录 1.按照一列数值进行排序 1.1按照五缺失值的一列进行排序 1.1.1升序排列 1.1.2 降序排列 1.2按照有缺失值的一列进行排序 1.2.1 缺失值显示在最后 1.2.2 缺失值显示在最前面 2.按照多列数值进行排序 本文用到的表格内容如下: 排序前先来看一下原始情形: import pandas as pd df = pd.read_excel(r'C:\Users\admin\Desktop\测试.xlsx') print(df) result: 姓名 年龄
-
Python数据分析Pandas Dataframe排序操作
目录 1.索引的排序 2.值的排序 前言: 数据的排序是比较常用的操作,DataFrame 的排序分为两种,一种是对索引进行排序,另一种是对值进行排序,接下来就分别介绍一下. 1.索引的排序 DataFrame 提供了sort_index()方法来进行索引的排序,通过axis参数指定对行索引排序还是对列索引排序,默认为0,表示对行索引排序,设置为1表示对列索引进行排序:ascending参数指定升序还是降序,默认为True表示升序,设置为False表示降序, 具体使用方法如下: 对行索引进行降序
-
Pandas实现DataFrame的简单运算、统计与排序
目录 一.运算 二.统计 三.排序 在前面的章节中,我们讨论了Series的计算方法与Pandas的自动对齐功能.不光是Series,DataFrame也是支持运算的,而且还是经常被使用的功能之一. 由于DataFrame的数据结构中包含了多行.多列,所以DataFrame的计算与统计可以是用行数据或者用列数据.为了更方便我们的使用,Pandas为我们提供了常用的计算与统计方法: 操作 方法 操作 方法 求和 sum 最大值 max 求均值 mean 最小值 min 求方差 var 标准差 st
-
pandas按照列的值排序(某一列或者多列)
按照某一列排序 d = {'A': [3, 6, 6, 7, 9], 'B': [2, 5, 8, 0, 0]} df = pd.DataFrame(data=d) print('排序前:\n', df) ''' 排序前: A B 0 3 2 1 6 5 2 6 8 3 7 0 4 9 0 ''' res = df.sort_values(by='A', ascending=False) print('按照A列的值排序:\n', res) ''' 按照A列的值排序: A B 4 9 0 3 7
-
pandas实现按照多列排序-ascending
目录 pandas按照多列排序ascending pandas排序.排名函数的使用 排序 排名 pandas按照多列排序ascending 代码示例: import pandas as pd #读取文件 df = pd.read_csv('./TianQi.csv') #字符串替换和类型转换 df['最高温度'] = df['最高温度'].str.replace('℃','').astype('int32') df.loc[:,'最低温度'] = df['最低温度'].str.replace('
-
pandas的排序、分组groupby及cumsum累计求和方式
目录 生成一列sum_age 对age 进行累加 生成一列sum_age_new 按照 gender和is_good 对age进行累加 根据不同的性别对年龄进行 等级 排序 对数据排序之后,分组,并累计求和 pandas分组排序功能 生成一列sum_age 对age 进行累加 df['sum_age'] = df['age'].cumsum() print(df) 生成一列sum_age_new 按照 gender和is_good 对age进行累加 df['sum_age_new'] = df.
-
pandas数据分组groupby()和统计函数agg()的使用
数据分组 使用 groupby() 方法进行分组 group.size()查看分组后每组的数量 group.groups 查看分组情况 group.get_group('名字') 根据分组后的名字选择分组数据 准备数据 # 一个Series其实就是一条数据,Series方法的第一个参数是data,第二个参数是index(索引),如果没有传值会使用默认值(0-N) # index参数是我们自定义的索引值,注意:参数值的个数一定要相同. # 在创建Series时数据并不一定要是列表,也可以将一个字典
-
pandas之分组groupby()的使用整理与总结
前言 在使用pandas的时候,有些场景需要对数据内部进行分组处理,如一组全校学生成绩的数据,我们想通过班级进行分组,或者再对班级分组后的性别进行分组来进行分析,这时通过pandas下的groupby()函数就可以解决.在使用pandas进行数据分析时,groupby()函数将会是一个数据分析辅助的利器. groupby的作用可以参考 超好用的 pandas 之 groupby 中作者的插图进行直观的理解: 准备 读入的数据是一段学生信息的数据,下面将以这个数据为例进行整理grouby()函数的
-
Python Pandas实现数据分组求平均值并填充nan的示例
Python实现按某一列关键字分组,并计算各列的平均值,并用该值填充该分类该列的nan值. DataFrame数据格式 fillna方式实现 groupby方式实现 DataFrame数据格式 以下是数据存储形式: fillna方式实现 1.按照industryName1列,筛选出业绩 2.筛选出相同行业的Series 3.计算平均值mean,采用fillna函数填充 4.append到新DataFrame中 5.循环遍历行业名称,完成2,3,4步骤 factordatafillna = pd.
-
pandas数据清洗,排序,索引设置,数据选取方法
此教程适合有pandas基础的童鞋来看,很多知识点会一笔带过,不做详细解释 Pandas数据格式 Series DataFrame:每个column就是一个Series 基础属性shape,index,columns,values,dtypes,describe(),head(),tail() 统计属性Series: count(),value_counts(),前者是统计总数,后者统计各自value的总数 df.isnull() df的空值为True df.notnull() df的非空值为T
-
Pandas对每个分组应用apply函数的实现
Pandas的apply函数概念(图解) 实例1:怎样对数值按分组的归一化 实例2:怎样取每个分组的TOPN数据 到此这篇关于Pandas对每个分组应用apply函数的实现的文章就介绍到这了,更多相关Pandas 应用apply函数内容请搜索我们以前的文章或继续浏览下面的相关文章希望大家以后多多支持我们!
-
Python pandas 计算每行的增长率与累计增长率
读取数据: FacebookDf=pd.read_excel(r'D:\jupyter\Untitled Folder\Facebook2017年股票数据.xlsx',index_col='Date') FacebookDf.tail() 计算当前行比上一行增长的百分比(每行的增长率) # .pct_change()返回变化百分比,第一行因没有可对比的,返回Nan,填充为0 # apply(lambda x: format(x, '.2%'))将小数点转换为百分数 FacebookDf['pct
-
Pandas索引排序 df.sort_index()的实现
df.sort_index()实现按索引排序,默认以从小到大的升序方式排列,如希望按降序排列,传入ascending = False import pandas as pd df = pd.DataFrame([['liver','E',89,21,24,64], ['Arry','C',36,37,37,57], ['Ack','A',57,60,18,84], ['Eorge','C',93,96,71,78], ['Oah','D',65,49,61,86] ], columns = ['