用Python爬取2022春节档电影信息
目录
- 前提条件
- 相关介绍
- 实验环境
- 具体步骤
- 目标网站
- 分析网站
- 代码实现
- 输出结果
- 总结
前提条件
熟悉HTML基础语句
熟悉Xpath基础语句
相关介绍
Python是一种跨平台的计算机程序设计语言。是一个高层次的结合了解释性、编译性、互动性和面向对象的脚本语言。最初被设计用于编写自动化脚本(shell),随着版本的不断更新和语言新功能的添加,越多被用于独立的、大型项目的开发。Requests是一个很实用的Python HTTP客户端库。Pandas是一个Python软件包,提供快速,灵活和可表达的数据结构,旨在使结构化(表格,多维,潜在异构)和时间序列数据的处理既简单又直观。Time是python标准库,无需额外下载,主要用于处理时间问题。Lxml是XML和HTML的解析器,其主要功能是解析和提取XML和HTML中的数据;lxml和正则一样,也是用C语言实现的,是一款高性能的python HTML、XML解析器,也可以利用XPath语法,来定位特定的元素及节点信息。
HTML是超文本标记语言,主要用于显示数据,他的焦点是数据的外观XML是可扩展标记语言,主要用于传输和存储数据,他的焦点是数据的内容
实验目标:Python爬取2022春节档电影信息
实验环境
Python 3.x (面向对象的高级语言)
Resquest 2.14.2 (python第三方库)
Pandas 1.1.0(python第三方库)
Time (python标准库)
Lxml(python第三方库)
具体步骤
目标网站
https://movie.douban.com/cinema/later/shenzhen/

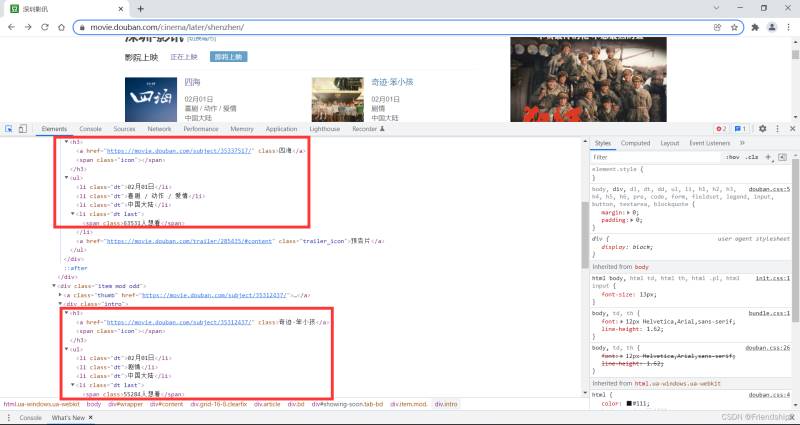
分析网站
按F12打开浏览器操作台

按Ctrl+Shift+C快捷键

按Ctrl+F快捷键,控制台出现搜索框

复制Xpath
Xpath为//*[@id=“showing-soon”]/div[1]/div/h3/a

粘贴到搜索框,验证Xpath

查看HTML,寻找共性

发现目标元素都在一个div框里,修改Xpath
Xpath修改为//*[@id=“showing-soon”]/div/div/h3/a

其余目标元素,以此类推
最后,用Pandas保存为CSV文件
# 利用pandas保存文件 df = pd.DataFrame() df['上映日期'] = Ondate df['片名'] = name df['类型'] = movie_class df['制片国家/地区'] = area df['想看人数'] = num df['超链接'] = href

代码实现
# -*- coding: utf-8 -*-
"""
Created on Tue Jan 25 10:07:11 2022
@author: TFX
"""
import time
import requests # 请求库
import pandas as pd
from lxml import etree# 提取信息库
# 日期
today = time.strftime('%Y{y}%m{m}%d{d}',time.localtime()).format(y='年',m='月',d='日')
# 网址
url = 'https://movie.douban.com/cinema/later/shenzhen/'
# 请求头
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/80.0.3987.163 Safari/537.36'
}
# 发送请求
response = requests.get(url=url,headers=headers)
# 数据解析,xpath可以用浏览器检查元素获得
html = etree.HTML(response.text) #类型变换
# 电影详细超链接
href = html.xpath('//*[@id="showing-soon"]/div/div/h3/a/@href')
# 上映日期
Ondate = html.xpath('//*[@id="showing-soon"]/div/div/ul/li[1]/text()')
# 片名
name = html.xpath('//*[@id="showing-soon"]/div/div/h3/a/text()')
# 类型
movie_class = html.xpath('//*[@id="showing-soon"]/div/div/ul/li[2]/text()')
# 制片国家 / 地区
area = html.xpath('//*[@id="showing-soon"]/div/div/ul/li[3]/text()')
# 想看人数
num = html.xpath('//*[@id="showing-soon"]/div/div/ul/li[4]/span/text()')
# 利用pandas保存文件
df = pd.DataFrame()
df['上映日期'] = Ondate
df['片名'] = name
df['类型'] = movie_class
df['制片国家/地区'] = area
df['想看人数'] = num
df['超链接'] = href
df.to_csv('2022春节档电影_'+today+'.csv',mode='w',index=None,encoding='gbk')
print('保存完成!')
输出结果



总结
到此这篇关于用Python爬取2022春节档电影信息的文章就介绍到这了,更多相关Python春节档电影信息内容请搜索我们以前的文章或继续浏览下面的相关文章希望大家以后多多支持我们!
相关推荐
-

基于Python实现一个春节倒计时脚本
目录 前言 环境安装 效果展示 代码展示 补充 前言 春节对于中国人民群众来说,是一个意义非凡的节日,它意味着一年的结束和新年的开始,很多人为了表达自己的期盼,都会进行倒计时. “在春节即将到来之际: 如果有人能提醒我还有几天的话那就好了!” 小编答应你了就问你贴不贴心 今天教大家编写一款简单的新年倒计时小脚本,时刻提醒大家距离过年还有多久啦——顺便在这里提前祝大家虎年吉祥,万事如意哦~ 环境安装 Python3. Pycharm (如需安装包.激活码等直接私信我即可安装问题解答都可以的哈~
-
python通过安装itchat包实现微信自动回复收到的春节祝福
itchat是一个开源的微信个人号接口,使用python调用微信从未如此简单. 开源地址 https://github.com/littlecodersh/ItChat 文档: https://itchat.readthedocs.io/zh/latest/ 安装: pip3 install itchat 好了,本文重点内容开始. 一.准备工作 安装itchat包,持有可在网页版扫码登陆的微信账号 pip3 install itchat 二.功能实现 import itchat from itc
-
Python爬取百度春节祝福语并生成心形词云
目录 前言 环境 思路 源代码 前言 最近刚好在看爬虫,就爬取一下春节祝福语,生成个词云玩一玩,大家有兴趣可以试试,会奉上源代码,很简单.效果图如下: 环境 环境:windows, 语言:python,python版本是3.7 所依赖的第三方包: selenium----爬取网站,收集祝福语,这个库做UI自动化测试的估计会比较常见,我这里没采用使用requests库去爬取,用这个库的好处是爬取的过程中页面是实时可见的 wordcloud---用来生成词云 PIL---使词云生成想要的轮廓, 这里
-
用Python爬取2022春节档电影信息
目录 前提条件 相关介绍 实验环境 具体步骤 目标网站 分析网站 代码实现 输出结果 总结 前提条件 熟悉HTML基础语句 熟悉Xpath基础语句 相关介绍 Python是一种跨平台的计算机程序设计语言.是一个高层次的结合了解释性.编译性.互动性和面向对象的脚本语言.最初被设计用于编写自动化脚本(shell),随着版本的不断更新和语言新功能的添加,越多被用于独立的.大型项目的开发.Requests是一个很实用的Python HTTP客户端库.Pandas是一个Python软件包,提供快速,灵活和
-
Python爬取爱奇艺电影信息代码实例
这篇文章主要介绍了Python爬取爱奇艺电影信息代码实例,文中通过示例代码介绍的非常详细,对大家的学习或者工作具有一定的参考学习价值,需要的朋友可以参考下 一,使用库 1.requests 2.re 3.json 二,抓取html文件 def get_page(url): response = requests.get(url) if response.status_code == 200: return response.text return None 三,解析html文件 我们需要的电影信
-
详解Python爬取并下载《电影天堂》3千多部电影
不知不觉,玩爬虫玩了一个多月了. 我愈发觉得,爬虫其实并不是什么特别高深的技术,它的价值不在于你使用了什么特别牛的框架,用了多么了不起的技术,它不需要.它只是以一种自动化搜集数据的小工具,能够获取到想要的数据,就是它最大的价值. 我的爬虫课老师也常跟我们强调,学习爬虫最重要的,不是学习里面的技术,因为前端技术在不断的发展,爬虫的技术便会随着改变.学习爬虫最重要的是,学习它的原理,万变不离其宗. 爬虫说白了是为了解决需要,方便生活的.如果能够在日常生活中,想到并应用爬虫去解决实际的问题,那么爬虫的
-
用python爬取豆瓣前一百电影
目录 实现代码: 代码分析: 运行结果: 总结 网站爬取的流程图: 实现项目我们需要运用以下几个知识点 一.获取网页1.找网页规律:2.使用 for 循环语句获得网站前4页的网页链接:3.使用 Network 选项卡查找Headers信息:4.使用 requests.get() 函数带着 Headers 请求网页. 二.解析网页1.使用 BeautifulSoup 解析网页:2.使用 BeautifulSoup 对象调用 find_all() 方法定位包含单部电影全部信息的标签:3.使用 Tag
-
python爬取亚马逊书籍信息代码分享
我有个需求就是抓取一些简单的书籍信息存储到mysql数据库,例如,封面图片,书名,类型,作者,简历,出版社,语种. 我比较之后,决定在亚马逊来实现我的需求. 我分析网站后发现,亚马逊有个高级搜索的功能,我就通过该搜索结果来获取书籍的详情URL. 由于亚马逊的高级搜索是用get方法的,所以通过分析,搜索结果的URL,可得到node参数是代表书籍类型的.field-binding_browse-bin是代表书籍装饰. 所以我固定了书籍装饰为平装,而书籍的类型,只能每次运行的时候,爬取一种类型的书籍难
-
使用python爬取抖音视频列表信息
如果看到特别感兴趣的抖音vlogger的视频,想全部dump下来,如何操作呢?下面介绍介绍如何使用python导出特定用户所有视频信息 抓包分析 Chrome Deveploer Tools Chrome 浏览器开发者工具 在抖音APP端,复制vlogger主页地址, 比如: http://v.douyin.com/kGcU4y/ , 在PC端用chrome浏览器打卡,并模拟手机,这里选择iPhone, 然后把复制的主页地址,放到浏览器进行访问,页面跳转到 https://www.iesdouy
-
用python爬取分析淘宝商品信息详解技术篇
目录 背景介绍 一.模拟登陆 二.爬取商品信息 1. 定义相关参数 2. 分析并定义正则 3. 数据爬取 三.简单数据分析 1.导入库 2.中文显示 3.读取数据 4.分析价格分布 5.分析销售地分布 6.词云分析 写在最后 Tip:本文仅供学习与交流,切勿用于非法用途!!! 背景介绍 有个同学问我:"XXX,有没有办法搜集一下淘宝的商品信息啊,我想要做个统计".于是乎,闲来无事的我,又开始琢磨起这事- 一.模拟登陆 兴致勃勃的我,冲进淘宝就准备一顿乱搜: 在搜索栏里填好关键词:&qu
-
python爬取各类文档方法归类汇总
HTML文档是互联网上的主要文档类型,但还存在如TXT.WORD.Excel.PDF.csv等多种类型的文档.网络爬虫不仅需要能够抓取HTML中的敏感信息,也需要有抓取其他类型文档的能力.下面简要记录一些个人已知的基于python3的抓取方法,以备查阅. 1.抓取TXT文档 在python3下,常用方法是使用urllib.request.urlopen方法直接获取.之后利用正则表达式等方式进行敏感词检索. ### Reading TXT doc ### from urllib.request i
-
python爬取淘宝商品销量信息
python爬取淘宝商品销量的程序,运行程序,输入想要爬取的商品关键词,在代码中的'###'可以进一步约束商品的属性,比如某某作者的书籍,可以在###处输入作者名字,以及时期等等.最后可以得到所要商品的总销量 import requests import bs4 import re import json def open(keywords, page): headers={"User-Agent":"Mozilla/5.0 (Windows NT 10.0; WOW64)