python灰色预测法的具体使用
目录
- 1.简介
- 2.算法详解
- 2.1生成累加数据
- 2.2 累加后的数据表达式
- 2.3 求解2.2的未知参数
- 3.实例分析
- 3.1导入数据
- 3.2进行累加数据
- 3.3求解系数
- 3.4预测数据及对比
1.简介
灰色系统理论认为对既含有已知信息又含有未知或非确定信息的系统进行预测,就是对在一定方位内变化的、与时间有关的灰色过程的预测。尽管过程中所显示的现象是随机的、杂乱无章的,但毕竟是有序的、有界的,因此这一数据集合具备潜在的规律,灰色预测就是利用这种规律建立灰色模型对灰色系统进行预测。
灰色预测通过鉴别系统因素之间发展趋势的相异程度,即进行关联分析,并对原始数据进行生成处理来寻找系统变动的规律,生成有较强规律性的数据序列,然后建立相应的微分方程模型,从而预测事物未来发展趋势的状况。其用等时距观测到的反应预测对象特征的一系列数量值构造灰色预测模型,预测未来某一时刻的特征量,或达到某一特征量的时间。
2.算法详解
2.1 生成累加数据

2.2 累加后的数据表达式

2.3 求解2.2的未知参数

3.实例分析
现有1997—2002年各项指标相关统计数据如下表:
|
年份 |
第一产业 GDP |
消费 价格指数 |
第三产业 GDP |
|
1997 |
72.03 |
241.2 |
1592.74 |
|
1998 |
73.84 |
241.2 |
1855.36 |
|
1999 |
74.49 |
244.8 |
2129.60 |
|
2000 |
76.68 |
250.9 |
2486.86 |
|
2001 |
78.00 |
250.9 |
2728.94 |
|
2002 |
79.68 |
252.2 |
3038.90 |
用灰色预测方法预测2003—2009年各项指标的数据。且已知实际的预测数据如下:将预测数据与实际数据进行比较
|
年份 |
第一产业GDP |
居民消费价格指数 |
第三产业GDP |
|
2003 |
81.21 |
256.5 |
3458.05 |
|
2004 |
82.84 |
259.4 |
3900.27 |
|
2005 |
84.5 |
262.4 |
4399.06 |
|
2006 |
86.19 |
265.3 |
4961.62 |
|
2007 |
87.92 |
268.3 |
5596.13 |
|
2008 |
89.69 |
271.4 |
6311.79 |
|
2009 |
91.49 |
274.5 |
7118.96 |
3.1 导入数据
#原数据 data=np.array([[72.03,241.2,1592.74],[73.84,241.2,1855.36],[74.49,244.8,2129.60],[76.68,250.9,2486.86],[78.00,250.9,2728.94],[79.68,252.2,3038.90]]) #要预测数据的真实值 data_T=np.array([[81.21,256.5,3458.05],[82.84,259.4,3900.27],[84.5,262.4,4399.06],[86.19,265.3,4961.62],[87.92,268.3,5596.1],[89.69,271.4, 6311.79],[91.49,274.5,7118.96]])
返回结果,请自行打印查看
3.2 进行累加数据
#累加数据 data1=np.cumsum(data.T,1) #按列相加 print(data1)
返回:

3.3 求解系数
[m,n]=data1.shape #得到行数和列数 m=3,n=6
#对这三列分别进行预测
X=[i for i in range(1997,2003)]#已知年份数据
X=np.array(X)
X_p=[i for i in range(2003,2010)]#预测年份数据
X_p=np.array(X_p)
X_sta=X[0]-1#最开始参考数据
#求解未知数
for j in range(3):
B=np.zeros((n-1,2))
for i in range(n-1):
B[i,0]=-1/2*(data1[j,i]+data1[j,i+1])
B[i,1]=1
Y=data.T[j,1:7]
a_u=np.dot(np.dot(np.linalg.inv(np.dot(B.T,B)),B.T),Y.T)
print(a_u)
#进行数据预测
a=a_u[0]
u=a_u[1]
返回:

得到3对 a和u
3.4 预测数据及对比
需在3.3的基础上进行预测
[m,n]=data1.shape #得到行数和列数 m=3,n=6
#对这三列分别进行预测
X=[i for i in range(1997,2003)]#已知年份数据
X=np.array(X)
X_p=[i for i in range(2003,2010)]#预测年份数据
X_p=np.array(X_p)
X_sta=X[0]-1#最开始参考数据
#求解未知数
for j in range(3):
B=np.zeros((n-1,2))
for i in range(n-1):
B[i,0]=-1/2*(data1[j,i]+data1[j,i+1])
B[i,1]=1
Y=data.T[j,1:7]
a_u=np.dot(np.dot(np.linalg.inv(np.dot(B.T,B)),B.T),Y.T)
# print(a_u)
#进行数据预测
a=a_u[0]
u=a_u[1]
T=[i for i in range(1997,2010)]
T=np.array(T)
data_p=(data1[0,j]-u/a)*np.exp(-a*(T-X_sta-1))+u/a #累加数据
# print(data_p)
data_p1=data_p
data_p1[1:len(data_p)]=data_p1[1:len(data_p)]-data_p1[0:len(data_p)-1]
# print(data_p1)
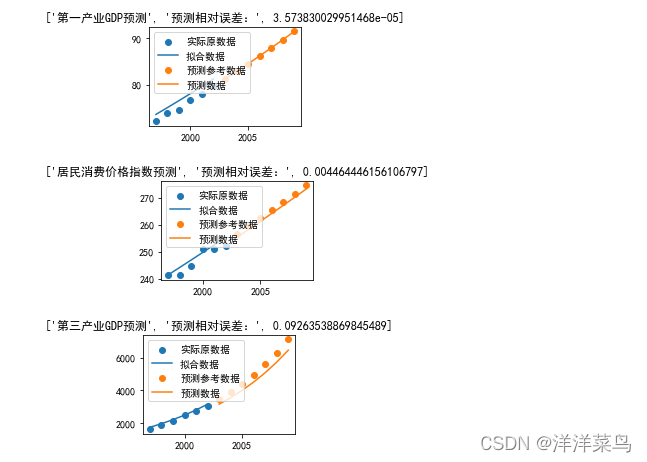
title_str=['第一产业GDP预测','居民消费价格指数预测','第三产业GDP预测']
plt.subplot(221+j)
data_n=data_p1
plt.scatter(range(1997,2003),data[:,j])
plt.plot(range(1997,2003),data_n[X-X_sta])
plt.scatter(range(2003,2010),data_T[:,j])
plt. plot(range(2003,2010),data_n[X_p-X_sta-1])
# plt.title(title_str[j])
plt.legend(['实际原数据','拟合数据','预测参考数据','预测数据'])
y_n=data_n[X_p-X_sta-1].T
y=data_T[:,j]
wucha=sum(abs(y_n-y)/y)/len(y)
titlestr1=[title_str[j],'预测相对误差:',wucha]
plt.title(titlestr1)
plt.show()
返回:
完整代码
import numpy as np
import matplotlib.pyplot as plt
import math
# 解决图标题中文乱码问题
import matplotlib as mpl
mpl.rcParams['font.sans-serif'] = ['SimHei'] # 指定默认字体
mpl.rcParams['axes.unicode_minus'] = False # 解决保存图像是负号'-'显示为方块的问题
#原数据
data=np.array([[72.03,241.2,1592.74],[73.84,241.2,1855.36],[74.49,244.8,2129.60],[76.68,250.9,2486.86],[78.00,250.9,2728.94],[79.68,252.2,3038.90]])
#要预测数据的真实值
data_T=np.array([[81.21,256.5,3458.05],[82.84,259.4,3900.27],[84.5,262.4,4399.06],[86.19,265.3,4961.62],[87.92,268.3,5596.1],[89.69,271.4, 6311.79],[91.49,274.5,7118.96]])
#累加数据
data1=np.cumsum(data.T,1)
print(data1)
[m,n]=data1.shape #得到行数和列数 m=3,n=6
#对这三列分别进行预测
X=[i for i in range(1997,2003)]#已知年份数据
X=np.array(X)
X_p=[i for i in range(2003,2010)]#预测年份数据
X_p=np.array(X_p)
X_sta=X[0]-1#最开始参考数据
#求解未知数
for j in range(3):
B=np.zeros((n-1,2))
for i in range(n-1):
B[i,0]=-1/2*(data1[j,i]+data1[j,i+1])
B[i,1]=1
Y=data.T[j,1:7]
a_u=np.dot(np.dot(np.linalg.inv(np.dot(B.T,B)),B.T),Y.T)
# print(a_u)
#进行数据预测
a=a_u[0]
u=a_u[1]
T=[i for i in range(1997,2010)]
T=np.array(T)
data_p=(data1[0,j]-u/a)*np.exp(-a*(T-X_sta-1))+u/a #累加数据
# print(data_p)
data_p1=data_p
data_p1[1:len(data_p)]=data_p1[1:len(data_p)]-data_p1[0:len(data_p)-1]
# print(data_p1)
title_str=['第一产业GDP预测','居民消费价格指数预测','第三产业GDP预测']
plt.subplot(221+j)
data_n=data_p1
plt.scatter(range(1997,2003),data[:,j])
plt.plot(range(1997,2003),data_n[X-X_sta])
plt.scatter(range(2003,2010),data_T[:,j])
plt. plot(range(2003,2010),data_n[X_p-X_sta-1])
# plt.title(title_str[j])
plt.legend(['实际原数据','拟合数据','预测参考数据','预测数据'])
y_n=data_n[X_p-X_sta-1].T
y=data_T[:,j]
wucha=sum(abs(y_n-y)/y)/len(y)
titlestr1=[title_str[j],'预测相对误差:',wucha]
plt.title(titlestr1)
plt.show()
到此这篇关于python灰色预测法的具体使用的文章就介绍到这了,更多相关python灰色预测法内容请搜索我们以前的文章或继续浏览下面的相关文章希望大家以后多多支持我们!
相关推荐
-
python构建指数平滑预测模型示例
指数平滑法 其实我想说自己百度的- 只有懂的人才会找到这篇文章- 不懂的人-看了我的文章-还是不懂哈哈哈 指数平滑法相比于移动平均法,它是一种特殊的加权平均方法.简单移动平均法用的是算术平均数,近期数据对预测值的影响比远期数据要大一些,而且越近的数据影响越大.指数平滑法正是考虑了这一点,并将其权值按指数递减的规律进行分配,越接近当前的数据,权重越大:反之,远离当前的数据,其权重越小.指数平滑法按照平滑的次数,一般可分为一次指数平滑法.二次指数平滑法和三次指数平滑法等.然而一次指数平滑法适用于无趋
-
Python分析彩票记录并预测中奖号码过程详解
0 引言 上周被一则新闻震惊到了,<2454万元大奖无人认领!福彩史上第二大弃奖在广东中山产生 >,在2019年5月2日开奖的双色球中,广东中山一位彩民博中2454万元,兑奖时间截至2019年7月1日. 令人遗憾的是,中奖者最终未现身领奖,2454万元大奖成为弃奖.经中山市福彩中心查证,这是中国福彩史上金额第二大的弃奖.根据<彩票管理条例实施细则>的有关规定,这次的2454万元弃奖奖金将被纳入彩票公益金. 一直在为福彩做贡献的我,啥时候能摊上这样的好事啊.于是我用Python生成了
-

python实现BP神经网络回归预测模型
神经网络模型一般用来做分类,回归预测模型不常见,本文基于一个用来分类的BP神经网络,对它进行修改,实现了一个回归模型,用来做室内定位.模型主要变化是去掉了第三层的非线性转换,或者说把非线性激活函数Sigmoid换成f(x)=x函数.这样做的主要原因是Sigmoid函数的输出范围太小,在0-1之间,而回归模型的输出范围较大.模型修改如下: 代码如下: #coding: utf8 '''' author: Huangyuliang ''' import json import random impo
-
python数据分析之用sklearn预测糖尿病
一.数据集描述 本数据集内含十个属性列 Pergnancies: 怀孕次数 Glucose:血糖浓度 BloodPressure:舒张压(毫米汞柱) SkinThickness:肱三头肌皮肤褶皱厚度(毫米) Insulin:两个小时血清胰岛素(μU/毫升) BMI:身体质量指数,体重除以身高的平方 Diabets Pedigree Function: 疾病血统指数 是否和遗传相关,Height:身高(厘米) Age:年龄 Outcome:0表示不患病,1表示患病. 任务:建立机器学习模型以准确预
-
Python编程实现使用线性回归预测数据
本文中,我们将进行大量的编程--但在这之前,我们先介绍一下我们今天要解决的实例问题. 1) 预测房子价格 房价大概是我们中国每一个普通老百姓比较关心的问题,最近几年保障啊,小编这点微末工资着实有点受不了. 我们想预测特定房子的价值,预测依据是房屋面积. 2) 预测下周哪个电视节目会有更多的观众 闪电侠和绿箭侠是我最喜欢的电视节目,特别是绿箭侠,当初追的昏天黑地的,不过后来由于一些原因,没有接着往下看.我想看看下周哪个节目会有更多的观众. 3) 替换数据集中的缺失值 我们经常要和带有缺失值的数据集
-
使用Python进行体育竞技分析(预测球队成绩)
今天我们用python进行体育竞技分析,预测球队成绩 一. 体育竞技分析的IPO模式 : 输入I(input):两个球员的能力值,模拟比赛的次数(其中,运动员的能力值,可以通过发球方赢得本回合的概率来表示, 一个能力值为0.8的球员,在他发球时,有80%的可能性赢得1分) 处理P(process):模拟比赛过程 输出O(output):两个球员获胜的概率 该体育竞技程序,我们采用自顶向下的设计方法. 自顶向下的设计是一种解决复杂问题的行之有效的方法.其步骤如下 自顶向下设计的基本思想,如下图:
-
使用python进行广告点击率的预测的实现
当前在线广告服务中,广告的点击率(CTR)是评估广告效果的一个非常重要的指标. 因此,点击率预测系统是必不可少的,并广泛用于赞助搜索和实时出价.那么如何计算广告的点击率呢? 广告的点击率 = 广告点击量/广告的展现量 如果一个广告被展现了100次,其中被点击了20次,那么点击率就是20%. 今天我们就来动手开发一个移动广告点击率的预测系统,我们数据来自于kaggle,数据包含了10天的Avazu的广告点击数据. 数据 你可以在这里下载移动广告点击数据,由于总数据量达到了4千多万条,数据量过于庞大
-
详解用Python进行时间序列预测的7种方法
数据准备 数据集(JetRail高铁的乘客数量)下载. 假设要解决一个时序问题:根据过往两年的数据(2012 年 8 月至 2014 年 8月),需要用这些数据预测接下来 7 个月的乘客数量. import pandas as pd import numpy as np import matplotlib.pyplot as plt df = pd.read_csv('train.csv') df.head() df.shape 依照上面的代码,我们获得了 2012-2014 年两年每个小时的乘
-
python灰色预测法的具体使用
目录 1.简介 2.算法详解 2.1生成累加数据 2.2 累加后的数据表达式 2.3 求解2.2的未知参数 3.实例分析 3.1导入数据 3.2进行累加数据 3.3求解系数 3.4预测数据及对比 1.简介 灰色系统理论认为对既含有已知信息又含有未知或非确定信息的系统进行预测,就是对在一定方位内变化的.与时间有关的灰色过程的预测.尽管过程中所显示的现象是随机的.杂乱无章的,但毕竟是有序的.有界的,因此这一数据集合具备潜在的规律,灰色预测就是利用这种规律建立灰色模型对灰色系统进行预测. 灰色预测通
-
python模拟预测一下新型冠状病毒肺炎的数据
大家还好吗? 背景就不用多说了吧?本来我是初四上班的,现在延长到2月10日了.这是我工作以来时间最长的一个假期了.可惜哪也去不了.待在家里,没啥事,就用python模拟预测一下新冠病毒肺炎的数据吧.要声明的是本文纯属个人自娱自乐,不代表真实情况. 采用SIR模型,S代表易感者,I表示感染者,R表示恢复者.染病人群为传染源,通过一定几率把传染病传给易感人群,ta自己也有一定的几率被治愈并免疫,或死亡.易感人群一旦感染即成为新的传染源. 模型假设: ①不考虑人口出生.死亡.流动等情况,即人口数量保持
-
一文详解Python灰色预测模型实现示例
目录 前言 一.模型理论 特点 二.模型场景 1.预测种类 2.适用条件 三.建模流程 1.级比校验 3.系数求解 4.残差检验与级比偏差检验 四.Python实例实现 总结 前言 博主参与过大大小小十次数学建模比赛,也获得了不少建模奖项.对于一些小批量样本数据去做预测或者是评估其规律性的话,比较适合的模型一般都是选择灰色预测模型.该模型解释性强而且易于理解,建模手段也比较简单.在一些不确定是否存在相关标量或者是存在位置特征的时候,用灰色预测模型尤为明显,牵扯太多变量时候可以以量曾量减的方式显现
-
Python基于回溯法子集树模板实现8皇后问题
本文实例讲述了Python基于回溯法子集树模板实现8皇后问题.分享给大家供大家参考,具体如下: 问题 8×8格的国际象棋上摆放八个皇后,使其不能互相攻击,即任意两个皇后都不能处于同一行.同一列或同一斜线上,问有多少种摆法. 分析 为了简化问题,考虑到8个皇后不同行,则每一行放置一个皇后,每一行的皇后可以放置于第0.1.2.....7列,我们认为每一行的皇后有8种状态.那么,我们只要套用子集树模板,从第0行开始,自上而下,对每一行的皇后,遍历它的8个状态即可. 代码: ''' 8皇后问题 '''
-
Python基于回溯法子集树模板解决0-1背包问题实例
本文实例讲述了Python基于回溯法子集树模板解决0-1背包问题.分享给大家供大家参考,具体如下: 问题 给定N个物品和一个背包.物品i的重量是Wi,其价值位Vi ,背包的容量为C.问应该如何选择装入背包的物品,使得放入背包的物品的总价值为最大? 分析 显然,放入背包的物品,是N个物品的所有子集的其中之一.N个物品中每一个物品,都有选择.不选择两种状态.因此,只需要对每一个物品的这两种状态进行遍历. 解是一个长度固定的N元0,1数组. 套用回溯法子集树模板,做起来不要太爽!!! 代码 '''0-
-
Python基于回溯法子集树模板解决取物搭配问题实例
本文实例讲述了Python基于回溯法子集树模板解决取物搭配问题.分享给大家供大家参考,具体如下: 问题 有5件不同的上衣,3条不同的裤子,4顶不同的帽子,从中取出一顶帽子.一件上衣和一条裤子作为一种搭配,问有多少种不同的搭配? 分析 换个角度看,现有头.身.腿三个元素,每个元素都有各自的几种状态. 头元素有['帽1', '帽2', '帽3', '帽4']共4种状态,身元素有['衣1', '衣2', '衣3', '衣4', '衣5']共5种状态,腿元素有['裤1', '裤2', '裤3']共3种状
-
Python基于回溯法子集树模板解决数字组合问题实例
本文实例讲述了Python基于回溯法子集树模板解决数字组合问题.分享给大家供大家参考,具体如下: 问题 找出从自然数1.2.3.....n中任取r个数的所有组合. 例如,n=5,r=3的所有组合为: 1,2,3 1,2,4 1,2,5 1,3,4 1,3,5 1,4,5 2,3,4 2,3,5 2,4,5 3,4,5 分析 换个角度,r=3的所有组合,相当于元素个数为3的所有子集.因此,在遍历子集树的时候,对元素个数不为3的子树剪枝即可. 注意,这里不妨使用固定长度的解. 直接套用子集树模板.
-
Python使用回溯法子集树模板解决迷宫问题示例
本文实例讲述了Python使用回溯法解决迷宫问题.分享给大家供大家参考,具体如下: 问题 给定一个迷宫,入口已知.问是否有路径从入口到出口,若有则输出一条这样的路径.注意移动可以从上.下.左.右.上左.上右.下左.下右八个方向进行.迷宫输入0表示可走,输入1表示墙.为方便起见,用1将迷宫围起来避免边界问题. 分析 考虑到左.右是相对的,因此修改为:北.东北.东.东南.南.西南.西.西北八个方向.在任意一格内,有8个方向可以选择,亦即8种状态可选.因此从入口格子开始,每进入一格都要遍历这8种状态.
-
Python基于回溯法子集树模板实现图的遍历功能示例
本文实例讲述了Python基于回溯法子集树模板实现图的遍历功能.分享给大家供大家参考,具体如下: 问题 一个图: A --> B A --> C B --> C B --> D B --> E C --> A C --> D D --> C E --> F F --> C F --> D 从图中的一个节点E出发,不重复地经过所有其它节点后,回到出发节点E,称为一条路径.请找出所有可能的路径. 分析 将这个图可视化如下: 本问题涉及到图,那首
-
Python使用回溯法子集树模板获取最长公共子序列(LCS)的方法
本文实例讲述了Python使用回溯法子集树模板获取最长公共子序列(LCS)的方法.分享给大家供大家参考,具体如下: 问题 输入 第1行:字符串A 第2行:字符串B (A,B的长度 <= 1000) 输出 输出最长的子序列,如果有多个,随意输出1个. 输入示例 belong cnblogs 输出示例 blog 分析 既然打算套用回溯法子集树模板,那就要祭出元素-状态空间分析大法. 以长度较小的字符串中的字符作为元素,以长度较大的字符串中的字符作为状态空间,对每一个元素,遍历它的状态空间,其它的事情